KMP算法优化
- 导读
- 一、C语言实现next数组
- 1.1 next数组的底层逻辑
- 1.2 串的数据类型的选择
- 1.3 函数三要素
- 1.3.1 查漏补缺——数组传参
- 1.3.2 小结
- 1.4 函数主体
- 1.4.1 通过模拟实现
- 1.4.1.1 算法思路
- 1.4.1.2 代码实现
- 1.4.1.3 算法测试
- 1.4.2 算法的缺陷
- 1.4.3 算法优化
- 1.4.3.1 算法思路
- 1.4.3.2 代码实现
- 1.4.3.3 算法测试
- 二、`KMP`算法的进一步优化
- 2.1 `KMP`算法存在的缺陷
- 2.2 `nextval`数组
- 三、KMP算法测试
- 四、模式匹配算法的对比
- 五、算法的C语言函数接口
- 总结

导读
大家好,很高兴又和大家见面啦!!!
在上一篇内容中我们详细介绍了KMP算法的基础知识点,相信大家在阅读完后应该对前缀、后缀、PM值、next数组这些基本概念有了一个初步的了解。但是在上一篇内容中我们对KMP算法的介绍还不够完整,遗留下来了两个问题:
- next数组的代码实现
- KMP算法的缺陷优化
在今天的内容中,我们将会围绕这两个问题,进一步的对KMP算法进行深入探讨。相信大家都很期待今天的内容了,下面我们就进入正题吧!!!
一、C语言实现next数组
在求解next数组之前,我们先思考一个问题——对于不同的模式串,当首字符失配时,会不会有不同的处理方式?
这个问题的答案显然是不会。对于任意长度为
n
(
n
>
=
1
)
n(n>=1)
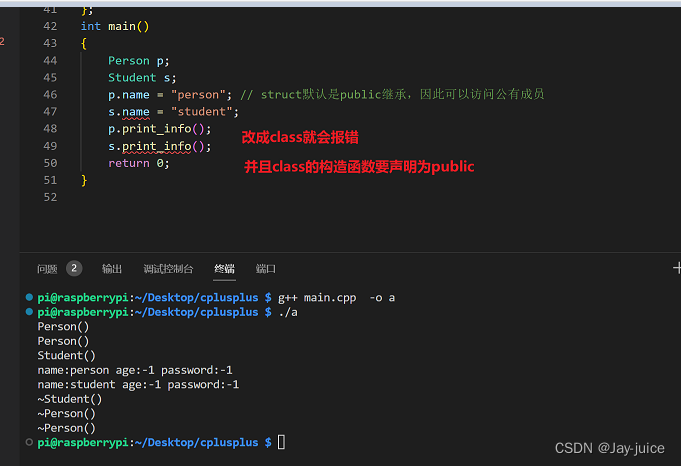
n(n>=1) 模式串,不管模式串怎么改变,只要首元素失配,那我们在下一次进行匹配时肯定是将模式串向右移动1位,因此,首元素失配时对应的next[j]肯定是
j
−
1
j-1
j−1。
!!!注意这里的j指的是元素在字符串中对应的数组下标。
也就是说当采用的存储方式是数组下标 = 位序 - 1时,那首元素的next[j]中j = 0,对应的值就为-1;
当采用的存储方式是数组下标 = 位序时,那首元素的next[j]中j = 1,对应的值就为0.
同样的对于任意长度为
n
(
n
>
=
2
)
n(n>=2)
n(n>=2) 的模式串,不管模式串怎么改变,当第二个字符失配时,在下一次匹配时肯定是将首元素与主串中当前失配元素进行匹配,因此第二个元素失配时对应的next[j]同样也是是
j
−
1
j-1
j−1。
因此对于任意串长为 n ( n > = 2 ) n(n>=2) n(n>=2) 的模式串,我们都能得到next数组中的前两个元素:
- 元素下标从0开始:
| 模式串 | x | x | x | …… | x | …… | x |
|---|---|---|---|---|---|---|---|
| 元素下标 j | 0 | 1 | 2 | …… | j | …… | n - 1 |
| next[j] | -1 | 0 | ? | …… | ? | …… | ? |
- 元素下标从1开始:
| 模式串 | x | x | x | …… | x | …… | x |
|---|---|---|---|---|---|---|---|
| 元素下标 j | 1 | 2 | 3 | …… | j | …… | n |
| next[j] | 0 | 1 | ? | …… | ? | …… | ? |
所以,当我们在进行手算next数组时,可以根据下标j的起点直接确定前两个元素的next[j]。
1.1 next数组的底层逻辑
在上一篇内容中,我们介绍了两种计算next数组的方法,不知道大家还有没有印象,现在我们一起来回忆一下:
- 通过PM值计算next数组——当第
j
j
j 个字符发生失配时,我们只需要计算第
j
−
1
j-1
j−1 个字符的PM值就可以获取第
j
j
j 个字符的
next[j],因为 n e x t [ j ] = = P M j − 1 next[j]==PM_{j-1} next[j]==PMj−1; - 通过移位模拟计算next数组——当第
j
j
j 个字符发生失配时,我们可以通过手动移位来模拟匹配过程,从而找到
next[j];
实际上不管是PM值也好还是移位模拟也好,我们都是在手动的进行由前面 j − 1 j-1 j−1 个字符组成的子串的前后缀匹配过程。也就是说求解next数组实际上就是求解失配字符的前一个字符的PM值,因此,我们想要通过代码来计算next数组,同样也是需要借助代码来实现子串前后缀的匹配。
1.2 串的数据类型的选择
为了减轻大家的阅读负担,并且能够将今天的内容与前面的内容联系起来,因此,在今天的内容介绍中,我们依旧采用的是定长顺序存储的数据类型:
//定长顺序存储
#define MAXSIZE 255//最大串长
typedef struct StackString {
char ch[MAXSIZE];//存储字符的字符数组
int length;//当前串长
}SString;//重命名后的数据类型名
1.3 函数三要素
next数组的求解我们同样是将其封装成一个函数,既然是函数,那就少不了函数的三要素:
- 函数名:对于一个函数而言,一个好的函数名可以展示出函数的具体功能,而我们要实现的是一个能够获取next数组的函数,因此我们不妨将函数名定位
get_next; - 函数参数:在获取next数组时,我们肯定是需要对模式串T进行操作的,因此,函数参数肯定有模式串T这个参数,模式串的参数类型我们还是以上一篇的模式串的类型为例进行介绍,因此这里我们选择采用
char*的类型; - 函数返回类型:函数返回类型的选择与函数的功能是有直接关系的:
- 如果我们是想通过函数来创建一个next数组,那我们就可以返回一个由
malloc/calloc创建的int*的值,因此函数返回类型就是int*; - 如果我们想要通过函数来获取next数组中的内容,那我们只需要将
int类型的数组作为函数参数传入函数,这时函数就不需要任何返回类型,因此函数的返回类型为void;
- 如果我们是想通过函数来创建一个next数组,那我们就可以返回一个由
通过第一种函数返回类型实现的函数大家应该都更容易理解,但是第二种返回类型的函数,可能会有朋友有疑问,我们在传入int型的数组时需不需要取地址?
这个问题的答案是不需要的。会有这个疑问是很正常的,这就说明我们在数组传参这个知识点上还存在知识漏洞,不过很幸运的是我们现在发现了这个漏洞,下面就需要将其填补起来。
1.3.1 查漏补缺——数组传参
数组名表示的是数组首元素的地址,同样也是数组空间的起始地址。
我们在进行数组名传参时实际上传入的是数组首元素地址,这时形参接收的内容也是数组的首元素地址,因此形参的参数类型可以是int*的类型也可以是int []类型;
当我们在函数中对形参进行操作时,实际上就是通过形参找到数组的起始地址进而对数组中的内容进行操作,因此我们只是想修改数组中的元素的话是不需要进行取地址传参,如下所示:

可以看到直接通过数组名进行传参,此时实参和形参的参数地址是同一个地址。
我们在进行取地址数组名传参时,实际上传入的是数组空间的起始地址,如下所示:

可以看到通过取地址数组名传参,此时的实参和形参的参数地址是同一个地址。
1.3.2 小结
现在我们就简单复习了一下一维数组传参的基础知识点,下面我们做个小结:
- 数组名表示的是数组的首元素地址,也是数组空间的起始地址;
- 一维数组在传参时,不管是直接通过数组名传参还是通过取地址数组名传参,形参都可以使用一级指针或者是一维数组进行接收,并且都能够正常对数组中的元素进行修改;
- 直接通过数组名进行传参,传入是实际上是数组首元素的地址;
- 通过取地址数组名进行传参,传入的实际上是数组空间的起始地址;
复习完了数组传参的内容,那么我们回到我们的正题——函数返回类型的选择。
正如前面所说,在实现next数组的函数中,函数的返回类型我们可以选择两种类型——int*和void。这两个类型的区别就是next数组的存在区域不同。
- int*型的函数创建的next数组是在堆区上,内存空间需要手动进行释放;
- void型的函数修改的next数组是在栈区上,内存空间在程序结束时自动回收;
因此我们可以根据自己的需求进行选择,这里我们还是简单一点,以void型的函数为例进行next数组的C语言实现。
//C语言实现next数组
void get_next(char* T, int* next) {
//函数实现
}
1.4 函数主体
按照next数组的底层逻辑,我们想要求解next数组中的next[j],实际上就是对前一个字符的PM值进行求解,而求解PM值就是求解字符串的前后缀相等的最长前后缀长度,因此,我们可以采用模拟的方式来求解next数组。
1.4.1 通过模拟实现
模拟指的就是通过代码模拟出前后缀比较从而进行PM值求解的方法。
1.4.1.1 算法思路
整个算法的实现肯定需要有以下流程:
- 获取模式串中的字符
- 获取模式串中当前字符的前一个字符的前缀与后缀
- 比较前缀和后缀,根据比较的结果进行相应的操作:
- 前缀后缀相等:获取当前的前后缀长度,之后继续获取下一个前后缀
- 前缀后缀不相等:继续获取下一个前后缀
在整个流程中,我们会遇到的问题有以下几点:
- 首字符没有前后缀应该如何处理
- 第二个字符应该如何处理
- 前后缀长度如何获取
第一个问题和第二个问题实际上都是与首字符相关的问题,而对于首字符的问题,这个我们只能单独进行处理。在前面也提到过对于任意长度为
n
(
n
>
=
2
)
n(n>=2)
n(n>=2) 的模式串而言,首字符和第二个字符的next[j]肯定是j - 1。因此我们可以直接根据首字符和第二个字符的下标来进行next[j]的求解;
第三个问题的处理方式我们主要介绍两种:
- 通过前缀子串的尾指针获取前缀长度:
- 下标从0开始的模式串,前缀串长 = 前缀子串的尾指针 + 1
- 下标从1开始的模式串,前缀串长 = 前缀子串的尾指针
- 通过后缀子串的头指针获取后缀长度:
- 借助求串长操作将后缀子串的头指针传入函数进行求解;
- 还可以通过下标之差获取后缀子串长度:后缀子串长度 = 当前字符的下标 - 后缀子串头指针指向的下标
为了方便大家理解整个过程,下面我们看一下该算法的演示:

从演示中我们不难推测,算法的实现依赖与两层循环,外层循环是来获取模式串的各个元素,内存循环则是用来获取各个元素的next[j];
为了保证前缀子串和后缀子串在每个字符中都能从单个字符开始增加,因此前缀字符数组和后缀字符数组肯定是定义在第一层循环内,第二层循环外;
在进行前后缀比较时,我们可以通过调用串比较操作来实现。从演示中可以看到,对于前缀子串而言,子串的起始点就是首元素地址,而后缀子串的起始点是后缀子串的头指针,因此传入的参数分别是前缀子串的数组名和后缀子串的串头指针;
在获取后缀子串的元素时,如果我们从后缀数组的首元素开始,那必然会出现数据移动的操作,为了规避这个步骤,我们可以如演示中一样从后往前向后缀数组中插入元素;
1.4.1.2 代码实现
理清了整体的实现思路,我们就可以顺着思路进行代码实现了,如下所示:
//C语言实现next数组
void get_next(char* T, int* next) {
//函数实现——模拟
//处理首字符
next[0] = -1;//字符下标从0开始
//处理其他字符
for (int i = 1; T[i]; i++) {
char prefix[MAXSIZE] = { 0 };//前缀子串
char suffix[MAXSIZE] = { 0 };//后缀子串
int p = 0;//前缀指针
int l = i - 1;//后缀指针
if (l == 0)//处理第二个字符
next[i] = p;
while (l > 0) {
prefix[p] = T[p];//获取前缀字符
suffix[l - 1] = T[l];//获取后缀字符
if (Compare(prefix, suffix + l - 1) == 0)//比较前后缀
next[i] = p + 1;//前后缀相等,则记录前缀尾字符下标
p++, l--;
}
}
}
有朋友可能好奇,为什么第二个字符的处理是放在循环内。我的考虑是可能遇到的模式串长度为1,因此将第二个字符的处理放入循环内会更保险一点。
还有朋友可能会问为什么在获取后缀字符时字符的位置放入的是l - 1,这是因为前后缀子串的长度是要小于对应子串的长度的,所以我通过将存入的位置往前移动来进行表示,当然也可以直接放入下标为l的位置,这个不影响算法的实现。
1.4.1.3 算法测试
接下来我们分别测试下面几个模式串:
"abcabc"——手算next数组为{-1, 0, 0, 0, 1, 2};"ababaaababaa"——手算next数组为{-1, 0, 0, 1, 2, 3, 1, 1, 2, 3, 4, 5};"aabaac"——手算next数组为{-1, 0, 1, 0, 1, 2};

可以看到,现在是能够正确获取模式串的next数组的。
1.4.2 算法的缺陷
在刚才实现的next数组求解的算法中,我们可以看到,对于串长为
n
(
n
>
=
1
)
n(n>=1)
n(n>=1) 的模式串来说,求解其next数组的时间复杂度为
O
(
N
2
)
O(N^2)
O(N2) 很显然这个时间复杂度会在一定程度上会增加KMP算法的时间开销,因此我们要对该算法进行优化。
在整个算法的实现中主要存在以下几个问题:
- 当我们在求PM值的时候是通过大量的获取前缀和后缀子串来进行求解,因此每一次获取前后缀都会消耗大量的时间;
- 在获取前后缀并进行匹配的过程中存在大量的无用匹配:

以上图为例,此时我们在求j = 3的next[3]之前,我们已经通过 j = 2 证明了K[0] != K[1],之后我们又证明了K[0] != K[2],也就是说此时从K[0]~K[3]元素之间的关系我们已经很明确它们互不相等了,因此上图所示的这一步就已经没有必要再来证明了。

在这一步中,此时我们可以很容易证明K[0] == K[3],在这之前我们已经证明了K[0]/K[1]/K[2]它们三个元素互不相等,因此由K[0]K[1]K[2]这三个元素组成的字符串肯定与K[1]K[2]K[3]组成的字符串不相等,因此后续获取前后缀的步骤也是没必要的;

在这一步中,我们已经证明了K[0] == K[3],因此由这两个元素开头的字符串我们只需要证明后续的元素是否相等,即我们要证明的是K[1] == K[4]?,因此在这之前证明K[0] == K[4]?这个步骤也是没必要的;
从上述分析中我们可以很直观的感受到,在整个求解的过程中,我们并不需要将每一个前缀都与后缀进行比较,相反,我们仅仅只需要比较单个元素,为什么会是这样的结论呢?如下图所示:

从图中我们可以很直观的看到,当第j个字符失配时,我们要求其next[j]的话,那对应的前缀则是由字符K[0]~K[j-3]这些字符组成的最长前缀;对应的后缀是由K[1]~K[j-2]这些字符组成的最长后缀;
在比较前后缀是否相等时,我们是从前后缀的首元素依次往后比较的。
- 当
K[0] != K[1]时,后面的内容我们就不需要继续比较了,这时可以直接将后缀往左移动或者前缀向右移动进而比较K[0]与K[2]的关系; - 当
K[0] == K[i]时,接下来我们才会继续比较K[1]与K[i+1]之间的关系
由此可以看到求解next[j]时,我们完全可以将寻找最长相等的前后缀长度转换成判断前后缀中的各个元素是否相等。
1.4.3 算法优化
1.4.3.1 算法思路
在明确了优化的方向后,下面我们就可以来理清整个算法的思路了。
同样的在优化的算法中,对于首元素我们依旧是进行单独处理,这里就不再展开赘述。我们现在要重点关注的是从第二个字符开始的算法优化。
在前面的分析中,我们不难发现,我们在进行字符比较时,是从K[0]和K[1]开始进行比较的,如果相等,则继续比较下一个元素;反之,则比较K[0]和K[2]。
因此在整个求解过程中,我们可以通过判断前缀的首元素K[p]与后缀的首元素K[l]是否相等将其分为两种情况:
- 若
K[p] == K[l],则我们需要将指针向后移动,即p++, l++; - 若
K[p] != K[l],则我们需要将指针p回溯,指针l不变,进而比较回溯后的K[p]与此时的K[l]之间的关系;
现在问题来了,在字符匹配失败时,我们应该将指针p回溯到哪里去呢?下面我们来简单的推导一下,以字符串"ababaaababaa"为例:

从演示中我们不难发现,当第j个元素发生失配时,前一个字符的next[j-1]就是我们下次需要进行匹配的对象,也就是说在next[j-1]之前的元素匹配肯定都是无效的。
可能有朋友对这个过程不太理解,为了帮助大家理解这个过程,下面请跟随我的思路来思考几个问题:
- next数组中存储的内容是用来做什么的?
这个问题相信大家都不陌生了,next数组中的next[j]的含义是:在子串的第 j 个字符与主串发生失配时,下一次进行匹配时需要跳转到子串的next[j]的位置重新与主串当前位置进行比较。
- 前后缀比较的本质是什么?
这个问题大家现在仔细回顾一下我们介绍next数组的整个过程就不难发现,其实前后缀的比较过程也是在进行模式匹配,如果将后缀作为主串的话,那前缀进行匹配的内容就是子串,只不过这里的主串长度是会发生变化的。
这时有朋友可能就会提出疑问了,对于这个匹配过程我们已经理解了,进行手算的话是完全没问题的,但是如何通过计算机来反映这一过程呢?
下面我们就需要探讨一下当第
k
k
k 个字符匹配成功时,第
k
+
1
k+1
k+1 个字符的next[k+1]与next[k]的关系。
在前后缀匹配的过程中第k个字符匹配成功时对应的next[k]就是从第1个字符到第
k
−
1
k-1
k−1 个字符组成的子串的前后缀匹配的最长相等长度,此时我们假设next[k] = x
(
0
<
=
x
<
=
k
)
(0<=x<=k)
(0<=x<=k)。
当第 k + 1 k+1 k+1 个字符失配时,那也就是说前面第 k k k 个字符是匹配成功的,而第 k k k 个字符失配时,根据我们的假设,第 k − 1 k-1 k−1 个字符总共有 x x x 个字符匹配成功,现在第 k k k 个字符也匹配成功,因此我们不难得出,此时匹配成功的字符总共有 x + 1 x+1 x+1 个。
因此当第
k
+
1
k+1
k+1 个字符失配时,对应的next[k+1] = x + 1。
有了上面的结论,现在我们再来分析从第二个字符开始的next[j]如何进行计算。
当我们在对长度为
n
(
n
>
=
1
)
n(n>=1)
n(n>=1) 的模式串进行next数组求解时,假设其元素下标从0开始,所有字符的next[j]的求解如下所示:
- 首字符的
next[0] = 0 -1 = -1; - 当下一个字符匹配成功时,对应的
next[j] = next[j-1] + 1,然后继续匹配下一个元素; - 当下一个字符匹配失败时,我们则需要将下标为
next[j - 1]的元素与元素 j j j 进行匹配; - 当
next[j-1] = -1时,说明此时前缀字符串中没有元素与元素j能够成功匹配,因此需要将前缀首元素与下一个元素 j + 1 j+1 j+1 进行匹配,第 j j j 个元素对应的next[j] = 0;
1.4.3.2 代码实现
有了具体的思路,接下来就是进行代码的编写了,如下所示:
//C语言实现next数组
void get_next(char* T, int* next) {
//函数实现——算法优化
//处理首字符
next[0] = -1;//字符下标从0开始
int p = 0, l = 1;//前缀指针和后缀指针
for (int i = 1; T[i];) {
//当匹配成功时
if (T[p] == T[l]) {
next[i] = next[i - 1] + 1;
p++, l++, i++;
}
//当匹配失败时
else {
p = next[i - 1];//前缀指针回溯到next[i-1]的位置
//处理无匹配字符的情况
if (p == -1) {
next[i] = 0;
p++, l++, i++;
}
}
}
}
现在我们已经根据上述思路成功编写了代码,但是这个代码看上去还是不够精简,下面我们需要思考一下如何简化该代码。
- 合并相同代码
从代码中我们可以看到,整个算法在p == -1和前后缀字符匹配成功时都有进行指针的后移,唯一不同的是next[i]的处理,因此如果要合并这两句代码的话我们则需要探讨一下next[i - 1] + 1与0的关系。
在代码中我们能够比较容易的得到当next[i -1] = -1时,这两个值是相等的;而当next[j-1] = -1时,并不会执行字符判断的操作,因此这两个if语句是可以进行合并的。
- 去掉无用代码
在整个算法中,我们不难发现,后缀指针l与指向模式串i的指针它们的操作是相同的,只会向后进行遍历,因此我们可以舍弃其中一个指针,为了方便理解,我们选择舍弃后缀指针,保留指向模式串的指针,这样整个匹配过程就变成了前缀子串与模式串进行模式匹配。
根据简化思路简化后的代码如下所示:
//C语言实现next数组
void get_next(char* T, int* next) {
//函数实现——算法优化——代码简化
//处理首字符
next[0] = -1;//字符下标从0开始
int p = 0;//前缀指针
for (int j = 1; T[j];) {
//当匹配成功时
if (p == -1 || T[p] == T[j]) {
next[j] = next[j - 1] + 1;
p++, j++;
}
//当匹配失败时
else {
p = next[j - 1];//前缀指针回溯到next[j-1]的位置
}
}
}
那现在是不是就完成了next数组的求解算法了呢?其实仔细思考一下我们会发现这个代码存在一个问题,如下所示:

在这个用例中可以看到,当j == 5, p == 3时,元素发生了失配,下面我们继续按照代码执行:

可以看到,此时如果按照代码的步骤进行执行,那我们求出来的next[j+1] = 3。为什么会出现这种错误呢?
产生这个错误的原因其实有两个:1. 回溯对象有误,2. 赋值对象有误。如下图所示:

可以看到,此时p指向的元素是K[3],并不是K[4],而且失配的元素是K[3]与K[5]发生的失配,因此我们要回溯的对象应该是K[1],而且下一次匹配是通过K[1]与K[5]进行匹配。
在KMP算法中我们是通过找到子串失配元素的next[j]所指向的下一个元素进行匹配,而在模式串中,前缀才是子串,因此这里的next[j]实际上指的是next[p]。所以算法的正确思路应该是:
- 首字符的
next[0] = 0 -1 = -1; - 通过前缀指针
p指向前缀子串中的元素,通过模式串指针j指向模式串中的元素; - 通过指针
p和指针j匹配获取的数据为元素j+1所对应的next数组下标; - 当指针p指向的元素与指针j指向的元素匹配成功时,
next[j+1] = next[p -1] + 1; - 当指针p指向的元素与指针j指向的元素匹配失败时,则将指针p回溯到next[p]的位置进行匹配;
- 当
p = -1时,说明此时前缀字符串中没有元素与元素j能够成功匹配,因此需要将前缀首元素与下一个元素 j + 1 j+1 j+1 进行匹配,第j+1个元素的next数组下标为next[j+1] = p + 1;
在这个思路中有一个点大家可能容易忽视——前缀指针p = next[p-1]。
这个结论的证明并不困难,如下所示:
- 在长度为
n
(
n
>
=
1
)
n(n>=1)
n(n>=1)的字符串中,第
j个字符的的 n e x t [ j ] = P M j − 1 next[j] = PM_{j-1} next[j]=PMj−1 而从第1个字符到j-1个字符的长度为 j − 1 j-1 j−1。 - 在模式串中,由前缀指针p指向的前缀子串串尾元素与第
j-1匹配成功时,其对应的PM值就是前缀子串的长度,此时指针p指向的元素下标与j-1相同,即p = j-1; - 对前缀子串而言,对应的子串长度为
p
+
1
p+1
p+1 ,因此我们不难得到
next[j] = p + 1; - 同理,对应的第
j-1个元素的next[j-1] = p,第j - 2个元素的next[j -2] = p -1; - 下标为
j - 2的元素与指针p指向的前一个元素为同一个元素,因此我们可以得到j - 2 = p - 1; - 同理,下标为
j - 2的元素的next[j-2]还可以表示为next[p-1],因此我们就可以得到next[p-1] = p - 1,将等式移项就能得到p = next[p - 1] + 1;
这个等式的实际意义是在前缀子串中下标为p的元素的长度为下标为p - 1的元素的长度加1。
现在我们就可以根据改进后的思路进行代码编写了,如下所示:
//C语言实现next数组
void get_next(char* T, int* next) {
//函数实现——算法优化
//处理首字符
next[0] = -1;//字符下标从0开始
int p = -1;//前缀指针
int j = 0;//指向模式串的指针
while (T[j]) {
//当匹配成功时
if (p == -1 || T[p] == T[j])
next[++j] = ++p;//先移动指针,再获取next下标
//当匹配失败时
else
p = next[p];//前缀指针回溯到next[p]的位置
}
}
1.4.3.3 算法测试
现在我们已经成功的实现了求解next数组的最佳算法,下面我们还是来测试一下算法的正确性:

可以看到,此时实现的算法也是没有任何问题的。从时间复杂度上分析,我们可以看到优化后的算法的时间复杂度可以近似的视作
O
(
N
+
M
)
O(N + M)
O(N+M)相比于之前的
O
(
N
2
)
O(N^2)
O(N2)有了大幅度的提升。
二、KMP算法的进一步优化
介绍完了next数组C语言实现,不知道朋友们有没有一种熟悉的感觉,算法从 O ( N 2 ) O(N^2) O(N2)进行优化提升至 O ( N + M ) O(N + M) O(N+M)整个算法的提升思路与模式匹配算法的提升思路如出一辙。
在我看来其实next数组作为KMP算法的核心,它的求解算法也是通过KMP算法才得以实现,因此对KMP算法的优化世界上就是对next数组的进一步优化。
2.1 KMP算法存在的缺陷
目前我们求解的next数组在实际使用中还是会存在进行无意义匹配的问题,如下所示:

在这个例子中,根据KMP算法的求解过程,当元素失配时,下一次匹配的对象为next[j]。
从图中我们可以看到当T[j] == T[next[j]]时,下一次匹配的结果肯定也是不匹配,因此我们需要找到next[next[j]]。在这个例子中我们会发现,此时next[next[j]]是能够与K[i]成功匹配的,再如下一个例子:

在这个例子中,因为模式串中的元素都是相等的因此,当最后一个元素失配时那就代表前面所有的元素都肯定是失配的,因此我们根据next数组进行匹配的话则会进行5次毫无意义的匹配。
这两个例子都是在说明目前我们求解的next数组并不是KMP算法中最佳的next数组,为了优化KMP算法,接下来我们就需要从next数组上进行优化。
2.2 nextval数组
当前的next数组中存在的缺陷是当第j个字符失配时,其对应的next[j]指向的元素如果与j相等,那么下一次匹配就相当于使用元素j再与当前元素进行了一次匹配,结果可想而知肯定会失配。因此我们就需要找到与元素j不相等的next[j]。
为了找到这个与元素j不相等的next[j],我们不妨对模式串的next数组进一步求解得到一个新的next数组——nextval数组。现在如何求解nextval数组则变成了我们现在需要关心的问题。
我们先介绍手算的方式,在进行手算nextval数组时,我们只需要通过判断第j个元素与其next[j]所对应的元素是否相等,相等则继续递归找到下一个next[next[j]],直到找到不相等的元素为止,因此模式串"abcabc"的next数组以及nextval数组如下表所示:
| 模式串T | a | b | c | a | b | c | \0 |
|---|---|---|---|---|---|---|---|
| 下标j | 0 | 1 | 2 | 3 | 4 | 5 | ^ |
| next[j] | -1 | 0 | 0 | 0 | 1 | 2 | ^ |
| nextval[j] | -1 | 0 | 0 | -1 | 0 | 0 | ^ |
下面我们可以尝试着将该思路用代码表示:
//nextval数组
void nextval(char* T,int* next) {
for (int i = 1; T[i]; i++) //从头开始遍历next数组
if (T[i] == T[next[i]])//当前元素与对应的next[i]相等时
next[i] = next[next[i]];//对该元素进行一次递归
}
接下来我们来简单测试一下该算法的正确性:

可以看到此时我们是能够很好的实现nextval数组求解的。
现在有朋友可能会说,我这写个KMP算法还需要额外写两个函数,感觉好麻烦,我们能不能在求解next数组时直接求解nextval数组呢?
这个想法我觉得非常棒,下面我们就需要分析一下目前我们求解next数组的算法,看看应该如何改进。
在前面实现的get_next算法中,我们在整个求解过程只进行了字符匹配的判断,而nextval数组是在字符匹配成功的基础上对字符j与next[j]进行进一步匹配。
在get_next算法中,元素j所对应的next[j] = p,因此我们不妨直接在匹配成功时直接对字符j与字符p进行匹配,从而直接求得nextval数组,如下所示:
//C语言实现nextval数组
void get_nextval(char* T, int* nextval) {
//函数实现——算法优化
//处理首字符
nextval[0] = -1;//字符下标从0开始
int p = -1;//前缀指针
int j = 0;//指向模式串的指针
while (T[j]) {
//当匹配成功时
if (p == -1 || T[p] == T[j]) {
j++, p++;//移动指针
if (T[p] == T[j])//当需要求解的元素j与指针p指向的元素相匹配时
nextval[j] = nextval[p];//将元素p的nextval赋值给元素j
else
nextval[j] = p;//当元素p与next[p]不相等时,直接获取next[j]
}
//当匹配失败时
else
p = nextval[p];//前缀指针回溯到next[p]的位置
}
}
下面我们同样还是以刚才的例子进行测试,结果如下所示:

可以看到,此时同样也能求得正确的nextval数组。
三、KMP算法测试
现在我们就完成完整的KMP算法,接下来我们就来测试一下完善后的KMP算法是否能够正常运行,如下所示:

从测试结果中可以看到,现在不管是nextval数组还是串定位都是能够正常运行。
四、模式匹配算法的对比
下面我们简单的分析一下KMP算法和朴素模式算法。
在朴素模式匹配算法中,算法的实现是通过指向主串的指针与指向模式串的指针的不断回溯,从而完全主串中所有的子串与模式串的匹配,因此朴素模式匹配算法也可以称为双指针算法。当我们从时间复杂度上来分析该算法时,就主串而言算法的最坏时间复杂度可以达到 O ( N 2 ) O(N^2) O(N2);
在KMP算法中,算法的实现是通过nextval数组完成指向模式串的指针的有效回溯,从而快速完成主串与模式串的匹配。就主串而言KMP算法的最坏时间复杂度只有
O
(
N
)
O(N)
O(N);
两种算法从时间复杂度上来看KMP算法是明显优于朴素模式匹配算法的,但是在我们遇到的实际问题中,朴素模式匹配算法的时间复杂度在一定程度上也是能够达到
O
(
N
)
O(N)
O(N)级别,因此朴素模式匹配算法至今任被采用。
五、算法的C语言函数接口
下面给大家附上KMP算法和nextval数组以及头文件和测试文件的相关代码:
//头文件
#include <stdio.h>
//定长顺序存储
#define MAXSIZE 255//最大串长
typedef struct StackString {
char ch[MAXSIZE];//存储字符的字符数组
int length;//当前串长
}SString;//重命名后的数据类型名
//nextval数组
void get_nextval(char* T, int* nextval) {
//函数实现——算法优化
//处理首字符
nextval[0] = -1;//字符下标从0开始
int p = -1;//前缀指针
int j = 0;//指向模式串的指针
while (T[j]) {
//当匹配成功时
if (p == -1 || T[p] == T[j]) {
j++, p++;//移动指针
if (T[p] == T[j])//当需要求解的元素j与指针p指向的元素相匹配时
nextval[j] = nextval[p];//将元素p的nextval赋值给元素j
else
nextval[j] = p;//当元素p与next[p]不相等时,直接获取next[j]
}
//当匹配失败时
else
p = nextval[p];//前缀指针回溯到next[p]的位置
}
}
//串定位
int Index_kmp(SString T, char* S) {
if (!S)
return -1;
int nextval[MAXSIZE] = { 0 };
get_nextval(S, nextval);//获取nextval数组
int i = 0, j = 0;
while (T.ch[i] && S[j]) {
if (j == -1 || T.ch[i] == S[j])//匹配成功
i++, j++;//继续匹配下一个元素
else//匹配失败
j = nextval[j];//模式串回溯到nextval[j]
}
return !S[j] ? i - j : -2;
}
//KMP算法测试
void test4() {
SString T = { 0 };
while (scanf("%s", T.ch) == 1) {
T.length = Strlen(T.ch);//获取主串串长
char S[MAXSIZE] = { 0 };//模式串
scanf("%s", S);//获取模式串
int index = Index_kmp(T, S);
if (index >= 0) {
printf("模式串%s在主串%s的位序为%d\n", S, T.ch, index + 1);
printf("模式串%s在主串%s的下标为%d\n", S, T.ch, index);
}
else if(index==-1)
printf("定位操作传参有误,参数为空指针\n");
else
printf("模式串%s不在主串%s中\n", S, T.ch);
}
}
int main() {
test4();
return 0;
}
总结
在今天的内容中我们详细介绍了next数组的C语言实现的过程。
在这个过程中我们分析了next数组的底层逻辑;
在进行算法实现时,我们首先通过模拟的方式实现了next数组求解的算法,之后通过对算法的详细剖析,我们完成了对算法从 O ( N 2 ) O(N^2) O(N2)到 O ( N ) O(N) O(N)的一个优化;
接下来我们通过对KMP算法存在的缺陷的分析,了解到了next数组还能进一步优化得到nextval数组,并且我们很好的完成了nextval数组的求解;
最后我们将朴素模式匹配算法和KMP算法进行了时间复杂度上的对比,我们发现KMP算法是原优于朴素模式匹配算法的,但是在实际问题中,朴素模式匹配算法也是能够达到与KMP算法同级别的时间复杂度,因此至今任被采用。
今天的内容到这里就全部结束了,如果大家喜欢博主的作品,大家可以点赞、评论加收藏支持一下博主,当然也可以转发给身边需要的朋友。最后感谢大家的支持,咱们下一篇再见!!!




![[leetcode] B树是不是A树的子结构](https://img-blog.csdnimg.cn/img_convert/5d907e1e251a46dbafa9872f71142948.png)