目录
一、ES简介
1. 数据库查询的问题
2. ES简介
1 ElasticSearch简介
2 ElasticSearch发展
3. 倒排索引【面试】
1 正向索引
2 倒排索引
4. ES和MySql
5. 小结
二、安装ES
1. 方式1:使用docker安装
1 准备工作
2 创建ElasticSearch容器
3 给ElasticSearch配置ik分词器
4 创建Kibana容器
5 访问测试
2. 方式2:本机直接安装
1. 安装ES
2. 安装Kibana
3. 安装IK分词器
4. 安装过程中可能出现的问题
3. ik分词器
ES标准分词器的问题
IK分词器的使用示例
4. 小结
三、操作索引
1. ES的核心概念
2. 操作索引库
3. 小结
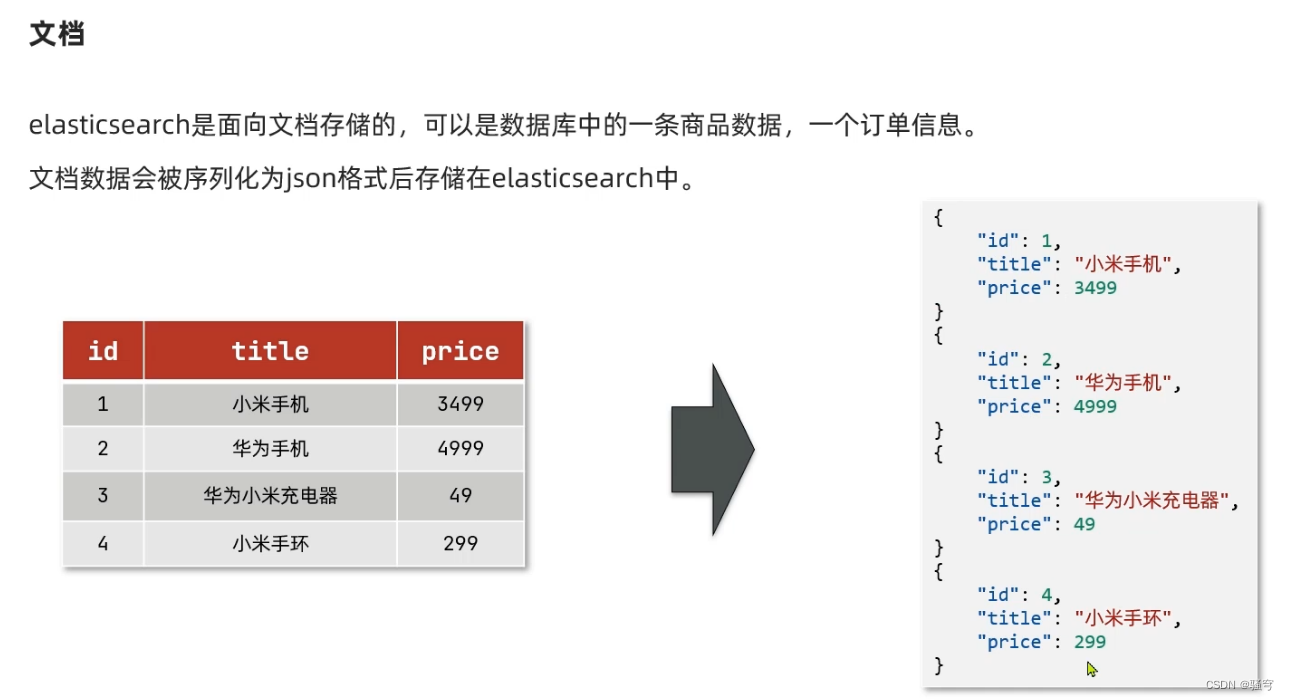
四、操作文档
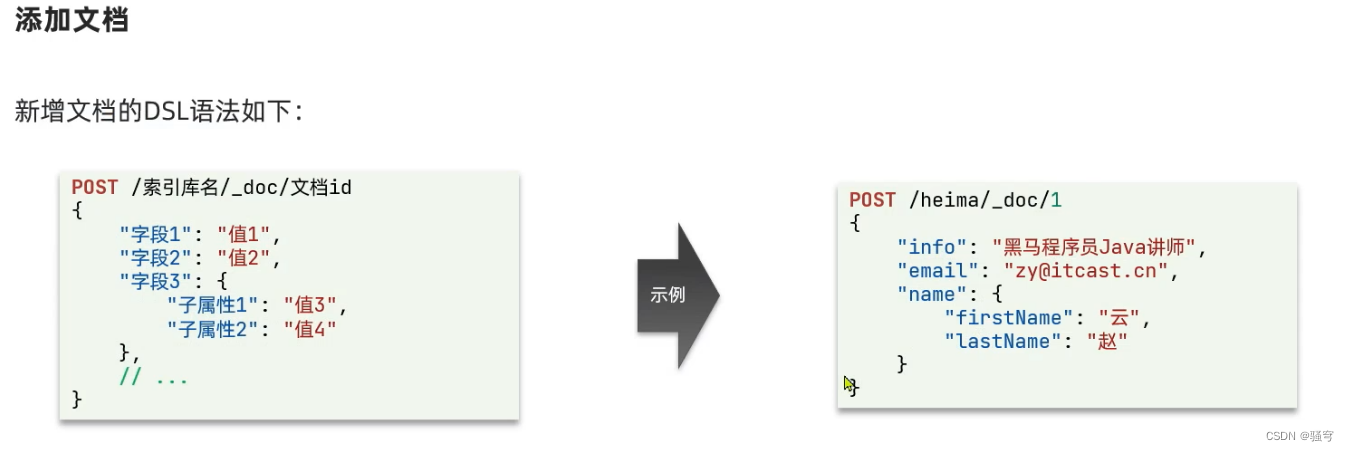
1. 语法
2. 示例
3. 课堂演示
4. 动态映射
5. 小结
五、RestAPI
1. 准备工作
1 创建project导入依赖
2 创建实体类
3 RestAPI的使用说明
2. 操作索引【了解】
1 API说明
2 使用示例
3. 操作文档【重点】
1 API说明
2 使用示例
4. 批量操作文档
1 说明
2 示例
5. 小结
六、练习
需求
步骤
实现
1. 创建索引库
2. 准备环境
3. 批量插入数据
大总结
一、ES简介
1. 数据库查询的问题
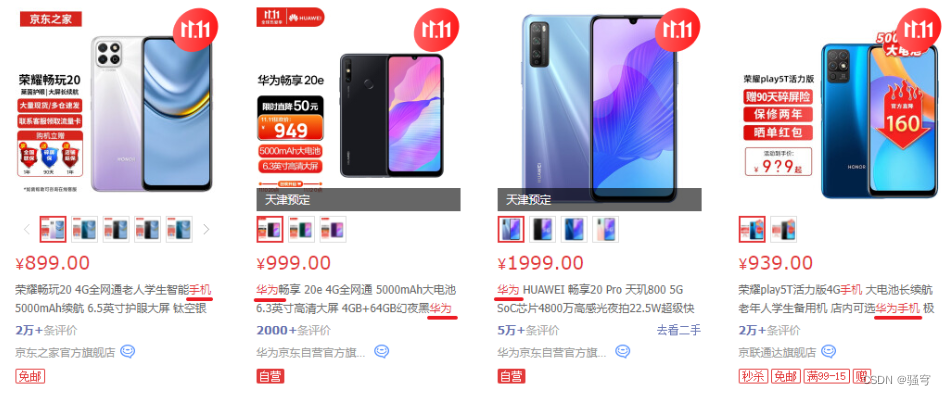
select * from 商品信息表 where name like '%华为Mate60%'
可以搜索到:华为手机Mate60, 华为手机Mate60 Pro, 白色 华为手机Mate60
但是不能搜索:华为 手机Mate60
假如我们有一个电商系统,需要查询商品。以前一直是直接从MySql数据库里用SQL语句模糊查询,例如:
select * from tb_product where pname like '%华为手机%' 华为手机Mate 50 Pro 华为畅享手机
但是这种查询检索数据的方式,有很大的问题:
-
查询性能很低
MySql可以通过索引的方式来提高查询的效率,但是像上边这种模糊查询以%开头,会导致索引失效,实际上执行的是全表扫描,效率非常低。
-
查询结果不准确
我们应当查询到与“手机”、“华为”等词条相关的所有商品,而不是 只包含“华为手机”的商品
而这些问题,都可以使用ElasticSearch轻易的解决掉:把数据存储到ElasticSearch里,由ElasticSearch提供高效的文档检索能力
2. ES简介
1 ElasticSearch简介
ElasticSearch,简称ES。ES是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。如百度搜索、京东商品搜索、打车软件中搜附近的车辆等等。
ES结合kibana、Logstash、Beats(也就是ELK技术栈,Elastic Stack),被广泛的用户在日志数据分析、实时监控等领域。ES是ELK的核心,负责存储、搜索、分析数据。
2 ElasticSearch发展
-
Doug Cutting于1999年研发了一个Java语言的搜索引擎类库(函数库):Lucene,目前已是Apache的顶级项目。
官网地址:Apache Lucene - Welcome to Apache Lucene
Lucene优势:易扩展、高性能(基于倒排索引)
Lucene缺点:只限于Java语言、学习曲线陡峭、不支持水平扩展
-
2004年Shay Banon基于Lucene开发了Compass,随后于2010年重写了Compass,取名为ElasticSearch。
官网地址:Elasticsearch 平台 — 大规模查找实时答案 | Elastic
相比于Lucene,ElasticSearch具备更多优势:
-
支持分布式,可水平扩展
-
提供RESTful接口(HTTP方式的请求),任何编程语言都可以使用。
-
-
到目前为止,ElasticSearch已经成为主流的搜索引擎
3. 倒排索引【面试】
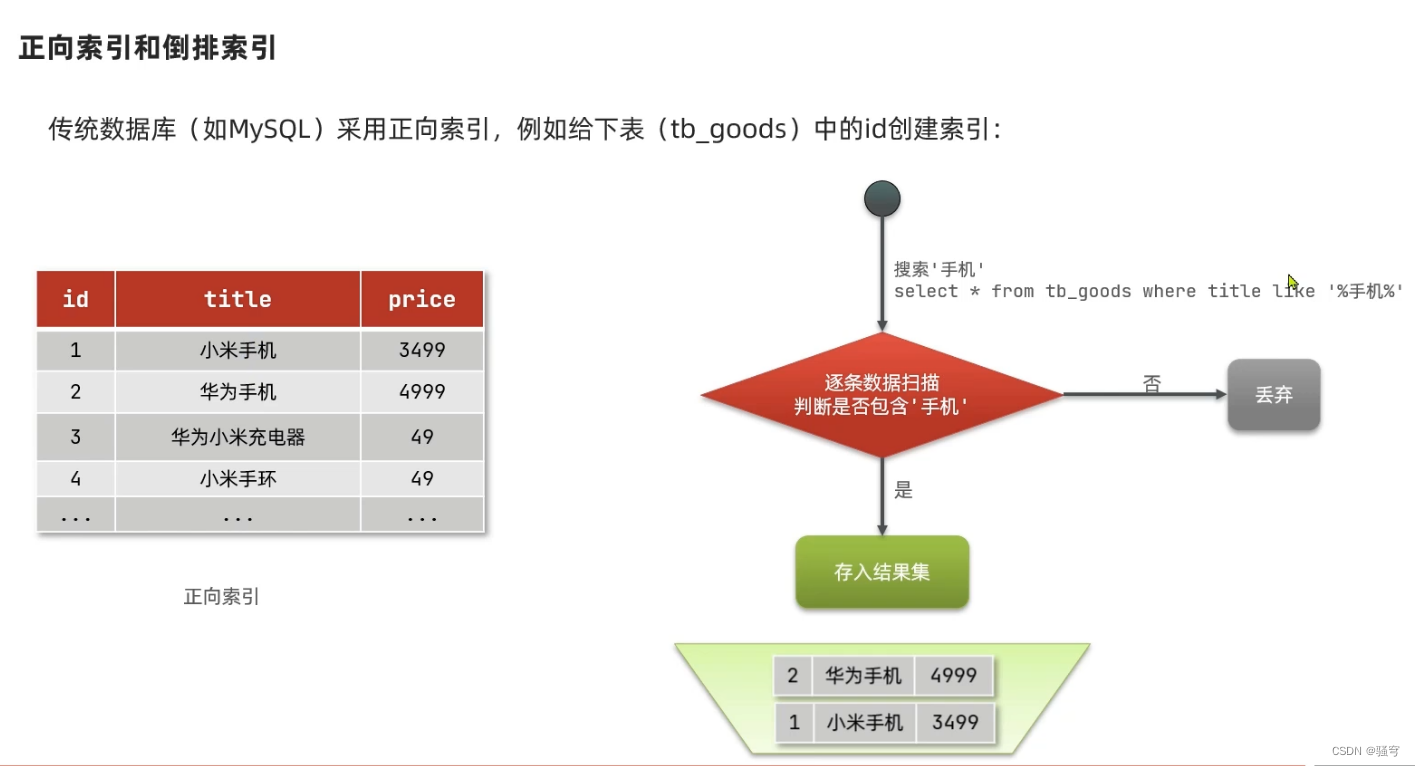
1 正向索引

说明
传统RDBMS(例如MySql)采用的是正向索引,即:根据表的主键字段构建索引,在查询时要扫描到每个索引值对应的数据,从中筛选出符合查询条件的记录。
这样的检索方式构建索引简单,但是不适合复杂的文档检索。复杂的文档检索时,索引会失效,变成全表扫描
示例
以商品表搜索为例,商品表tb_product如下:
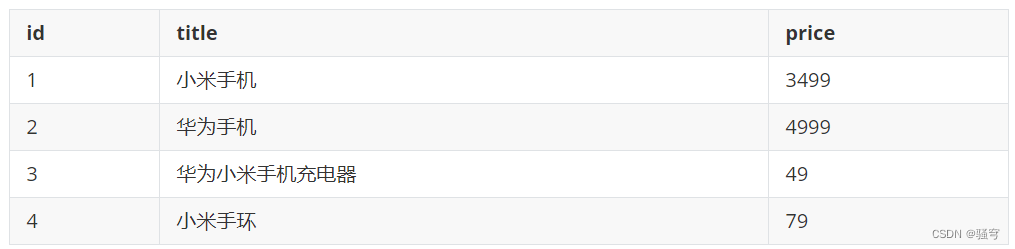
要搜索包含“手机”的商品,执行SQL:select * from tb_product where title like '%华为手机%'
MySql会扫描所有的数据记录,逐条判断 “title”的值是否包含“手机”,直到全表扫描,过滤出所有符合要求的结果
-
先找每条数据
-
再判断每条数据是否符合要求
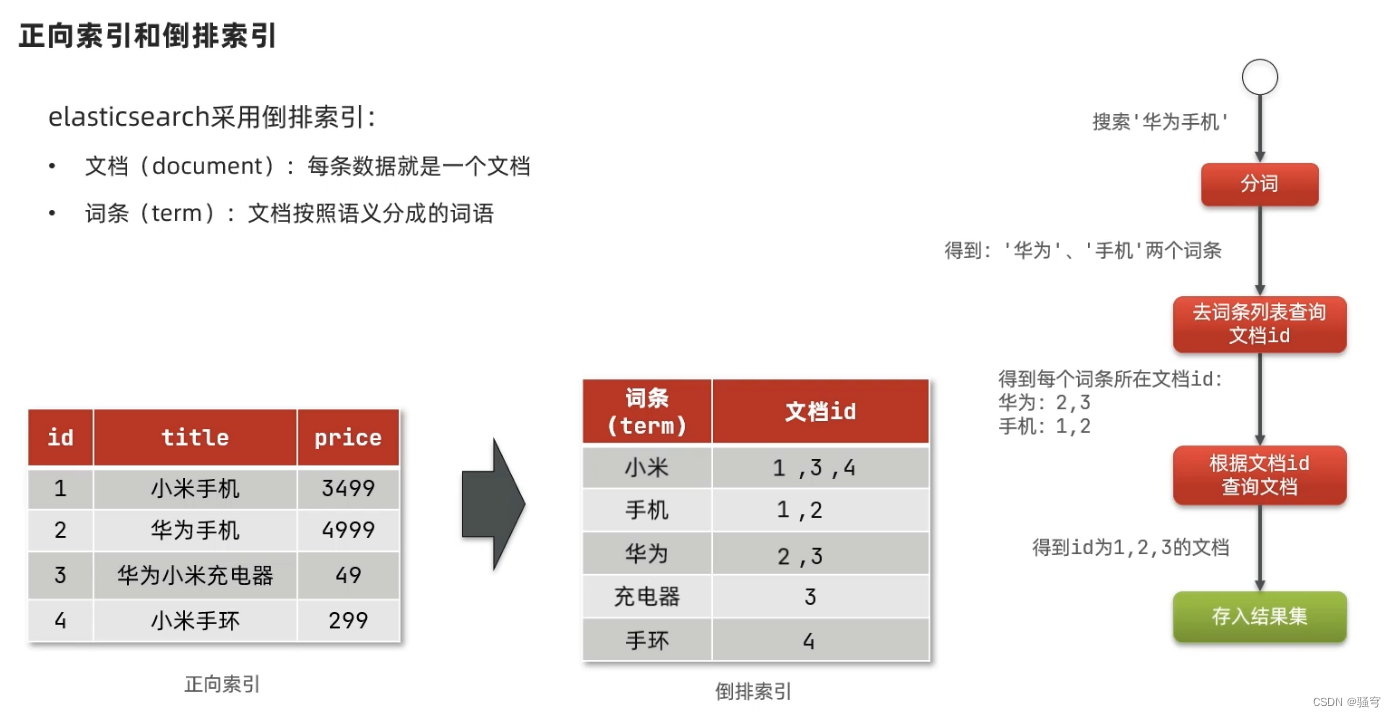
2 倒排索引
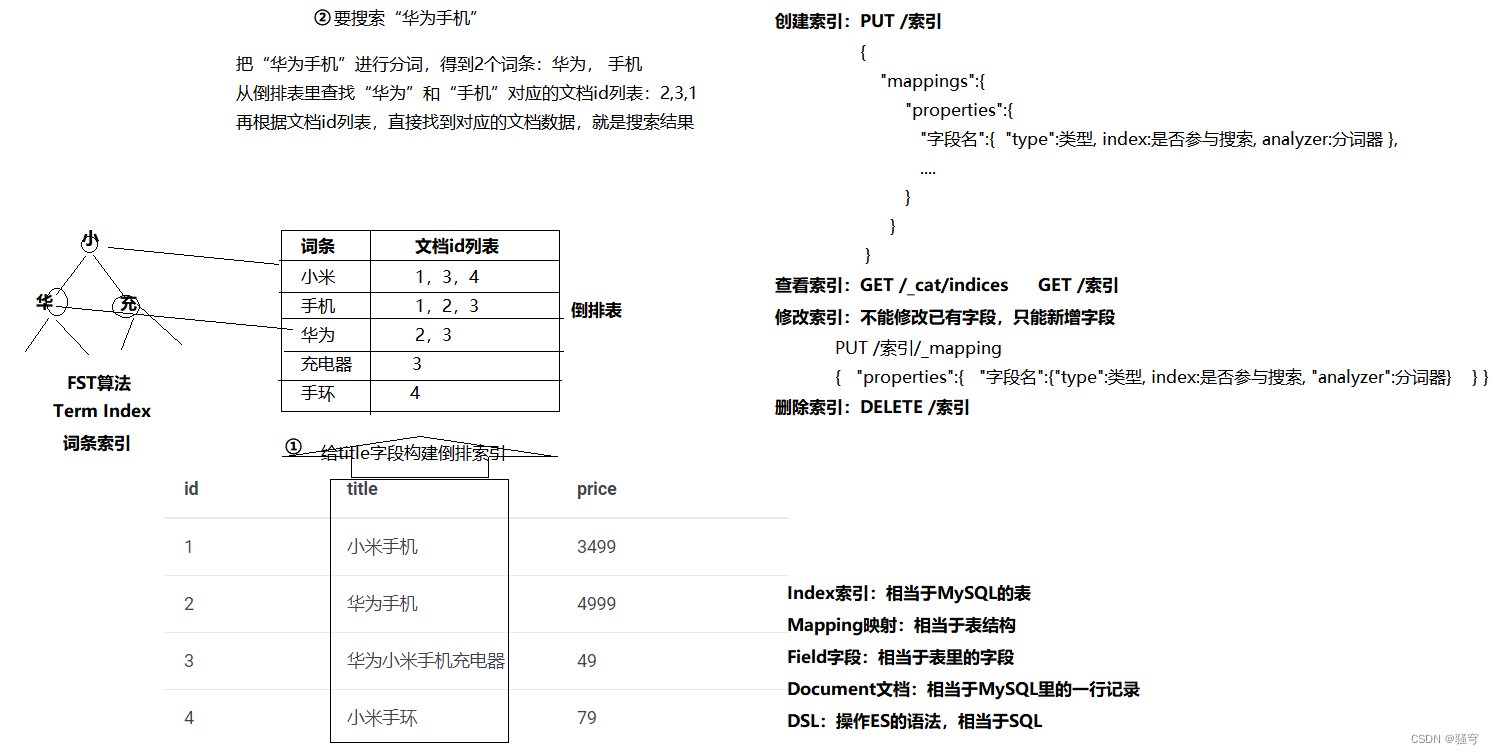
说明
ElasticSearch采用的是倒排索引,即:以字或词为关键字构建索引,保存每个关键字所在的记录。当需要查询时,根据词条匹配查询条件,直接找到关联的记录。
倒排索引的建立和维护都比较复杂,但是在查询时可以和查询关键字关联的所有结果,并快速响应。
示例
以商品表搜索为例,商品表略
构建倒排索引
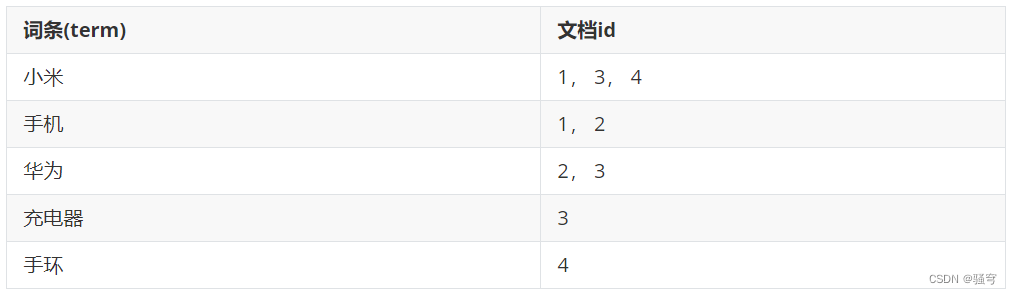
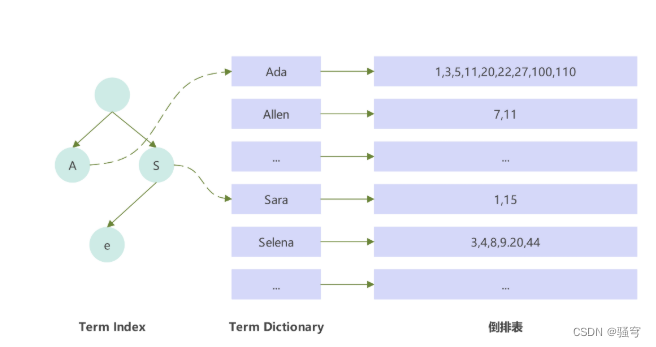
文档Document:每条数据就是一个文档
词条term:按照语义分成的词语
当搜索“华为手机”时:
-
把搜索条件进行分词,得到两个词条:“华为”, “手机”
-
根据词条,去倒排索引里查询相关的文档id,得到:
-
“华为”:2, 3
-
“手机”:1, 2
-
-
根据文档id,找到对应的文档数据,得到:id为1、2、3的文档
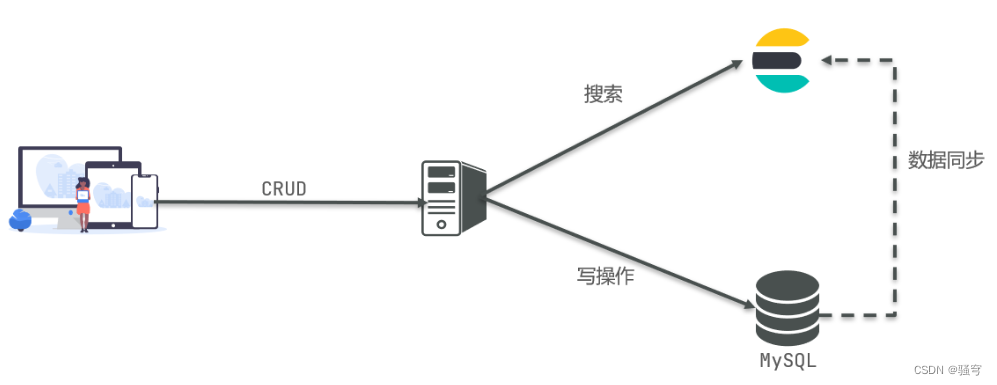
4. ES和MySql
传统的RDBMS和ElasticSearch都可以增删改查,并且各有所长:
-
MySQL:擅长事务类操作,可以确保数据的一致性和安全性
-
ES:擅长海量数据的搜索、分析、计算
在实际开发中,通常是结合使用
-
MySQL负责写操作
-
ES负责搜索操作
5. 小结

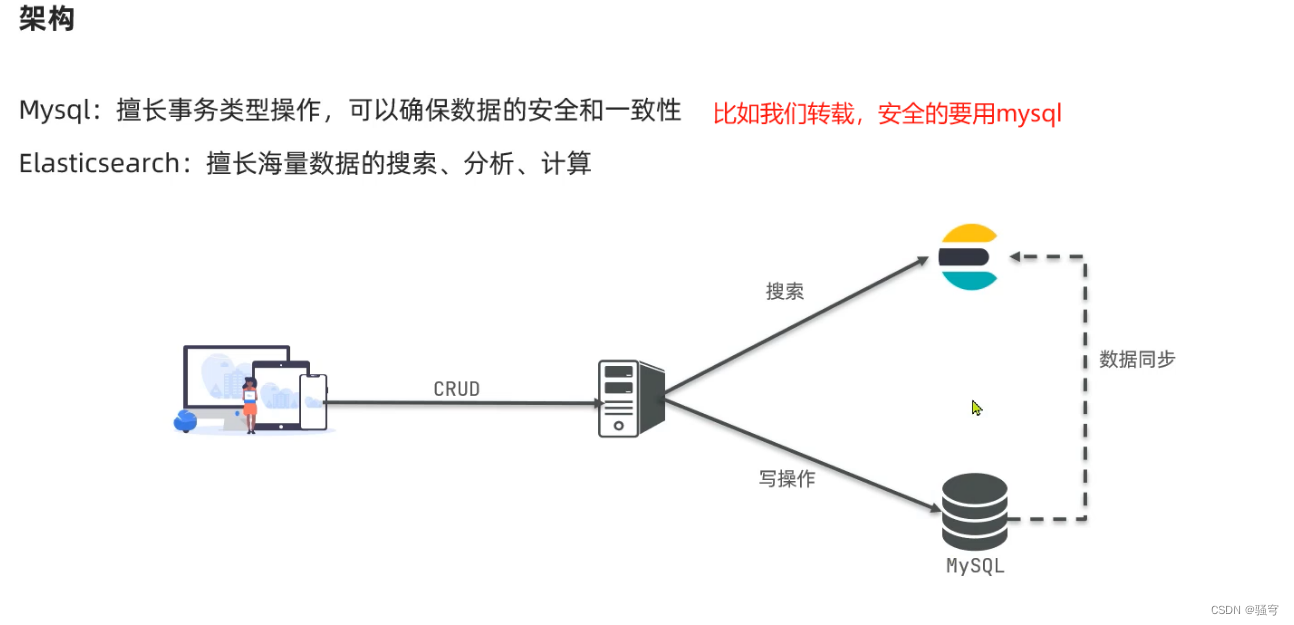
ES是什么?是一个开源的搜索引擎,可以快速从海量数据里查找目标数据
ES为什么快?其中一个原因是,ES使用了倒排索引,避免了全表扫描,所以速度快
-
ES会对所有的数据,进行分词构建倒排表和倒排索引。 是词条对应文档的id集合
-
当我们要搜索数据的时候,ES会先对搜索词进行分词,拿分词后的多个词条,直接去倒排索引里找到关联的文档id集合;从而找到关联的文档数据
ES和MySQL的对比:
-
共同点:都具备增删改查的能力
-
不同点:
-
MySQL擅长增删改 写操作。因为MySQL有事务,可以保证数据的一致性和完整性
-
ES擅长查询搜索。因为ES使用了倒排索引,可以快速从海量数据里查找目标数据
-
-
实际开发中的应用:
-
如果要增删改数据,找MySQL
-
再把MySQL里的数据同步给ES
-
我们再从ES里搜索查询数据
-
二、安装ES
1. 方式1:使用docker安装
1 准备工作
首先把《es7.4.0.tar》和《kibana7.4.0.tar》上传到CentOS的/root目录里
然后执行以下命令:
#创建文件夹。用于挂载到ElasticSearch容器上
mkdir -p /data/elasticsearch/config
mkdir -p /data/elasticsearch/data#创建es配置文件,设置允许任意主机访问ElasticSearch
echo "http.host: 0.0.0.0" >> /data/elasticsearch/config/elasticsearch.yml#设置文件夹的权限
chmod -R 777 /data/elasticsearch
2 创建ElasticSearch容器
#创建ElasticSearch容器并启动
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms512m -Xmx512m" \
-v /data/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /data/elasticsearch/data:/usr/share/elasticsearch/data \
-v /data/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.0#如果想要查看ElasticSearch是否启动成功,可以打开浏览器访问 http://ip地址:9200
3 给ElasticSearch配置ik分词器
可以之前去输入拉取镜像的命令,这里是直接加载准备好的包
把ik分词器插件文件夹上传到 CentOS的/data/elasticsearch/plubins文件夹里,重启ElasticSearch容器

重启es
#重启ElasticSearch
docker restart elasticsearch
4 创建Kibana容器
注意:一定要把命令里的ip地址,修改成ElasticSearch的访问ip
#安装Kibana:注意一定要把ip地址设置为ElasticSearch的ip
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.200.130:9200 -p 5601:5601 \
-d kibana:7.4.0
5 访问测试
打开浏览器访问:http://192.168.200.130:5601 如果能正常打开,说明已经完全启动成功了
注意:ElasticSearch和Kibana的启动,都需要花费一定时间,如果浏览器页面打不开,就耐心等待一会
2. 方式2:本机直接安装
1. 安装ES
目前我们安装的是ES的7.4.0版本,需要JDK8及以上
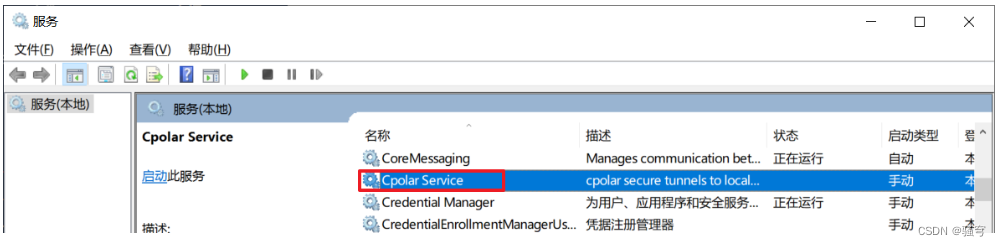
准备工作:Cpolar关闭或者卸载,因为它占用了9200端口。这个端口是ES使用的
关闭Cpolar的方式:
-
打开“服务”窗口,找到Cpolar Service
-
在服务上右键停止;
-
在服务上右键-属性-启动类型,修改为“手动”;确定并关闭
-
打开浏览器,输入地址 http://localhost:9200
-
如果显示出来了一个登录页面,就按 ctrl + shift + delete,清除浏览器缓存
-
再刷新页面,保证页面是不能访问的。(不能访问,说明Cpolar已经成功关闭了)
-
1 解压
把《elasticsearch-7.4.0-windows-x86_64.zip》解压到一个不含中文、空格、特殊字符的目录里
2 配置
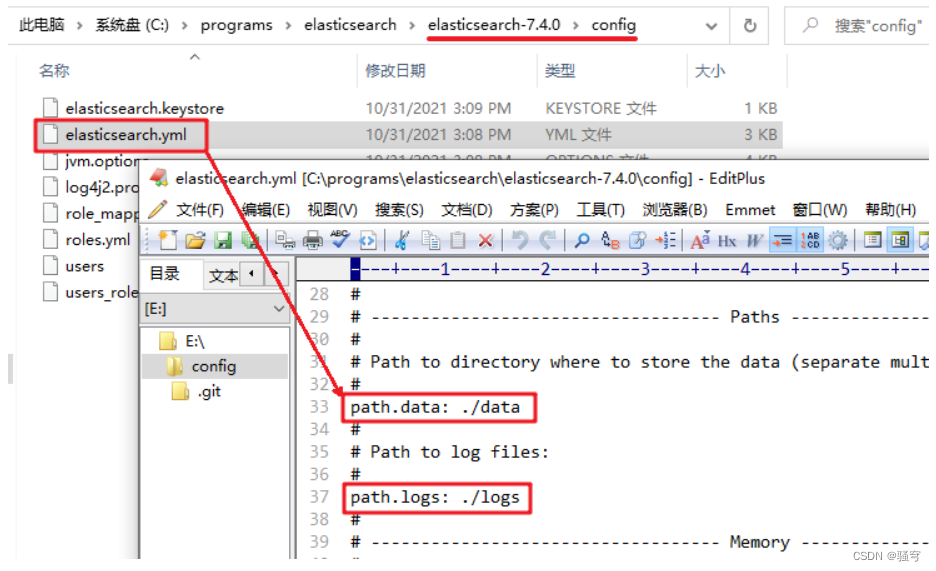
1) 配置存储路径
打开config/elasticsearch.yml文件,设置索引数据的存储路径,和日志的存储路径
2) 配置虚拟机参数
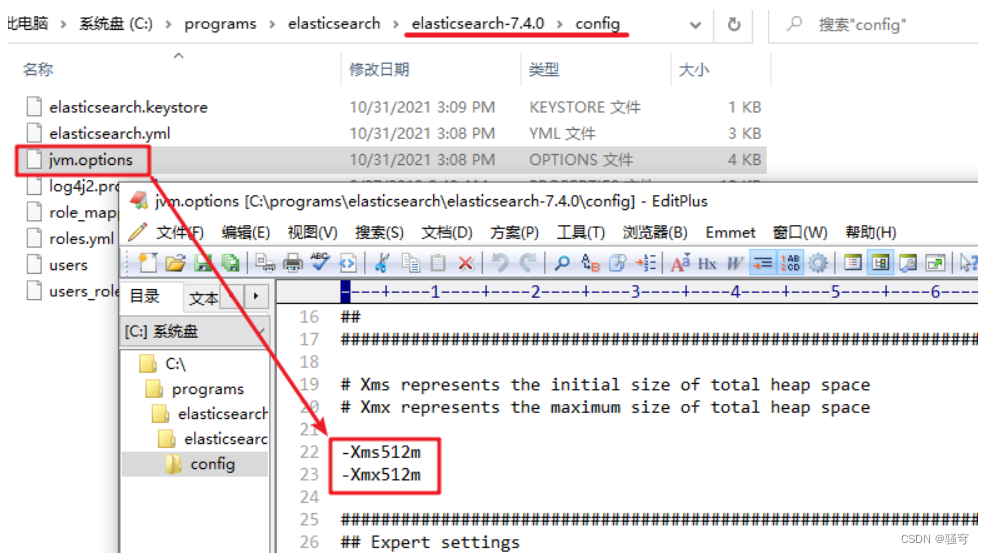
3 启动
进入es的bin目录,直接双击 elasticsearch.bat即可启动
es服务要占用两个端口:
-
9200:rest访问接口,我们稍后要通过这个端口连接es、操作es
-
9300:用于es集群间通信的接口
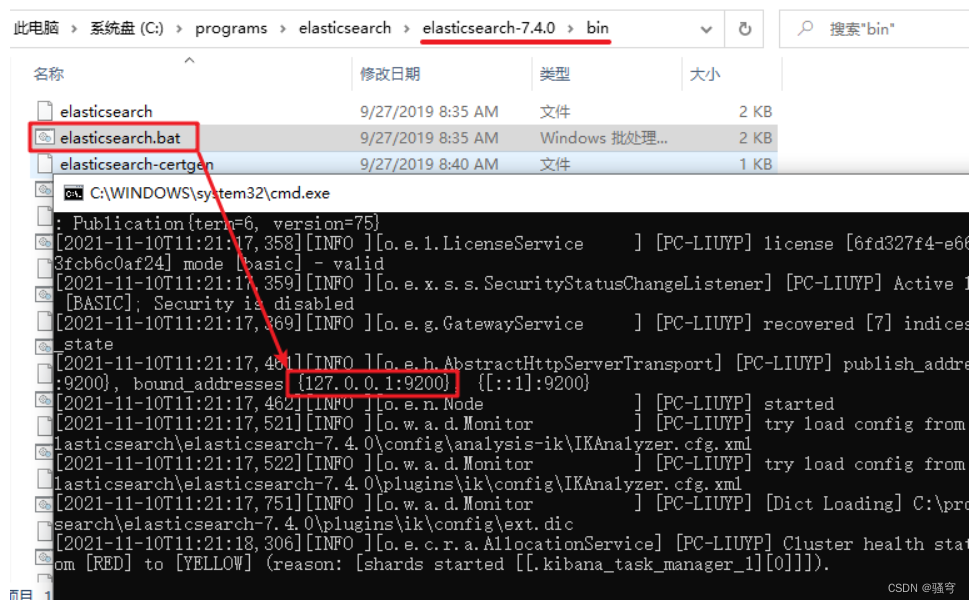
4 验证
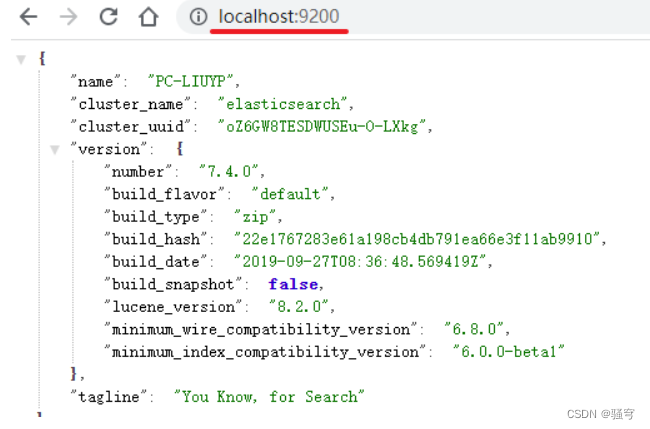
在浏览器上直接输入地址 http://localhost:9200/, 如果看到以下界面,说明es启动成功了
2. 安装Kibana
Kibana是一个ES索引库数据统计工具,可以利用ES的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
而且还提供了操作ES索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习ES的语法。
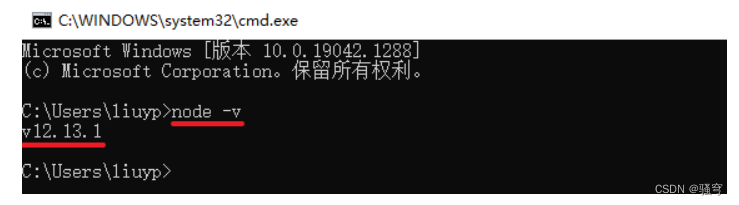
1 安装nodeJs
Kibana依赖于nodeJs,需要在windows下先安装Node.js,然后才能安装Kibana。
双击nodejs的安装包,按照提示一步步安装即可
安装成功后,打开cmd 输入:node -v,如果能看到版本号,说明node安装成功
2 安装Kibana
docker pull kibana:7.4.0 拉取kibana镜像,可以直接拉取
1) 解压
把《kibana-7.4.0-windows-x86_64.zip》解压到不含中文、空格、特殊字符的目录里
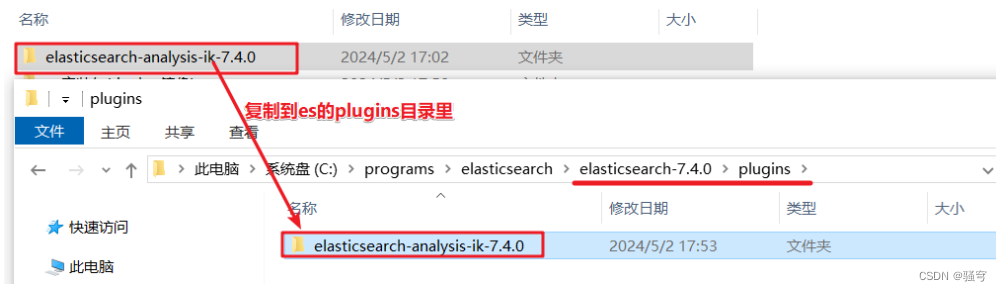
2) 配置
修改kibana的config/kibana.yml,配置es的地址 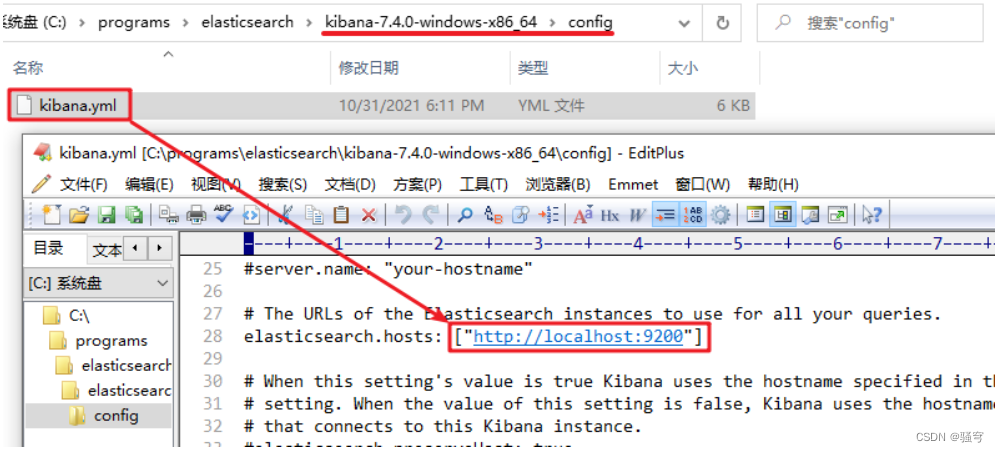
3) 启动
进入到kibana的bin目录,双击 kibana.bat 启动。启动稍微有些慢,耐心等待一会 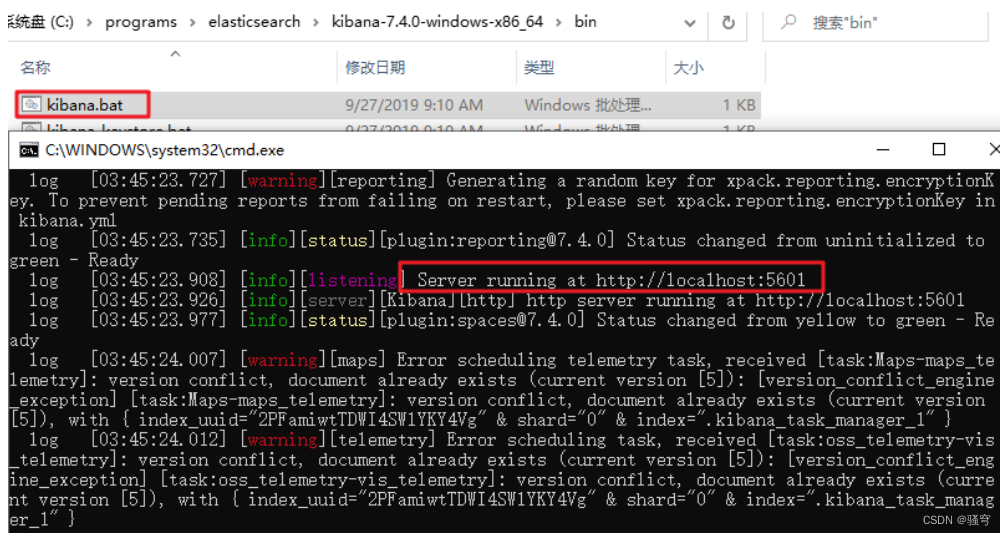
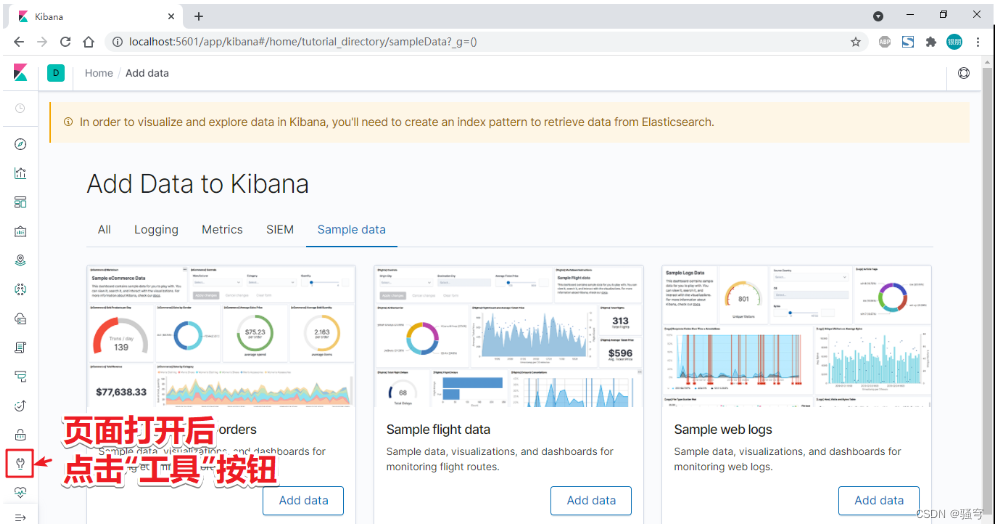
4) 访问
打开浏览器输入 http://localhost:5601/
3. 安装IK分词器
1 ES标准分词器的问题
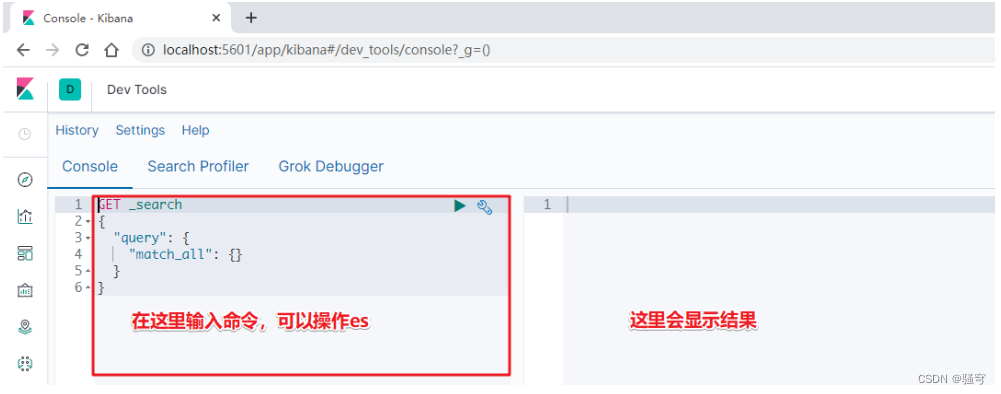
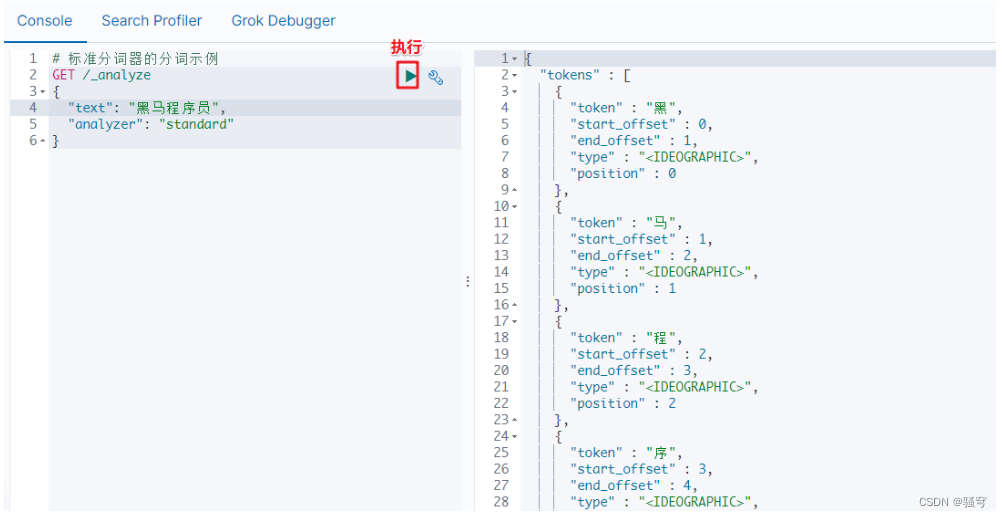
ES自带的分词器叫“Standard Analyzer”,它对中文的支持非常不友好,会将一个词语的每个字拆分成一个词条,和中文的语法是完全不符的。
例如,一个词语“黑马程序员”,按中文语法习惯可以拆分成“黑马”,“程序员”,“程序”等词条。但是标准分词器分拆分成“黑”,“马”,“程”,“序”,“员”
示例如下:
2 安装IK分词器
为了解决中文词语拆分的问题,可以安装一个IK分词器。IK分词器是一款适合于中文分词习惯的、优秀的中文分词器,具有60万字/秒的高速处理能力。
它支持两种粒度的拆分:
-
ik_smart:做粗粒度的拆分
-
ik_max_word:将文本做细粒度的拆分,拆分出尽可能多的词条(建议用这种)
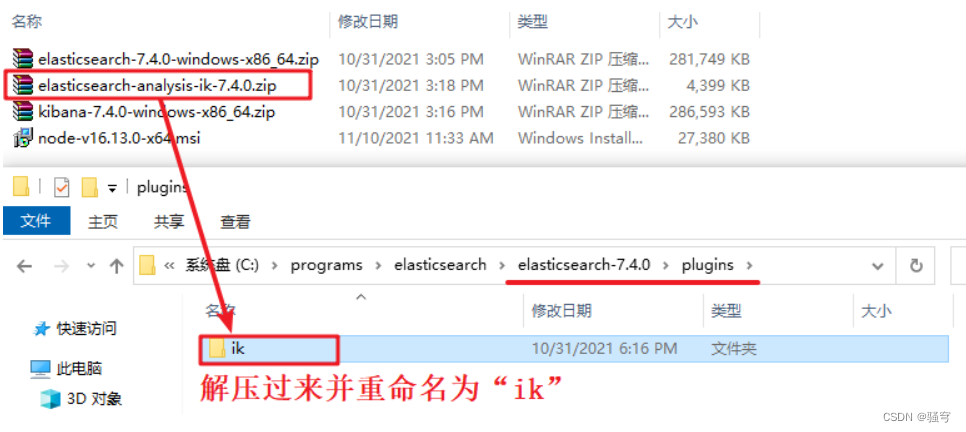
1) 解压
把分词器《elasticsearch-analysis-ik-7.4.0.zip》解压到es的plugins目录下,重命名为“ik”
2) 重启
-
重启es
-
重启kibana
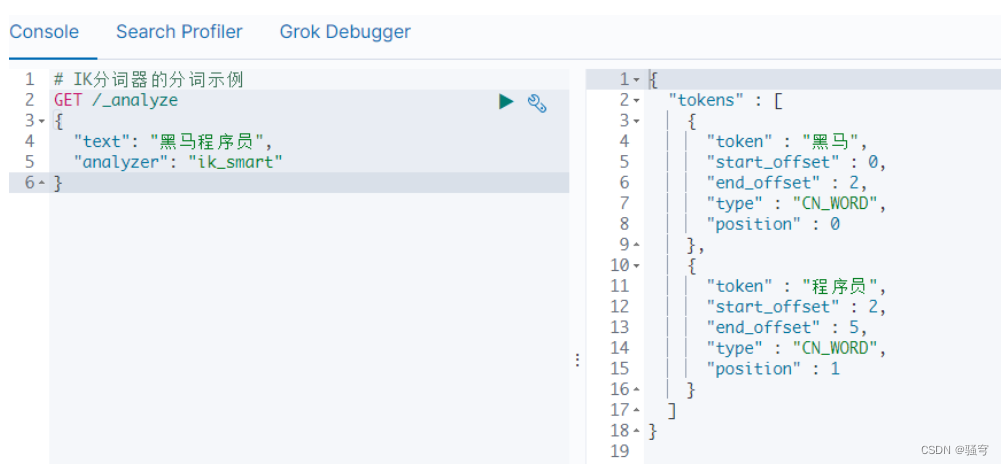
3) 测试
在浏览器的kibana开发工具界面,输入并执行
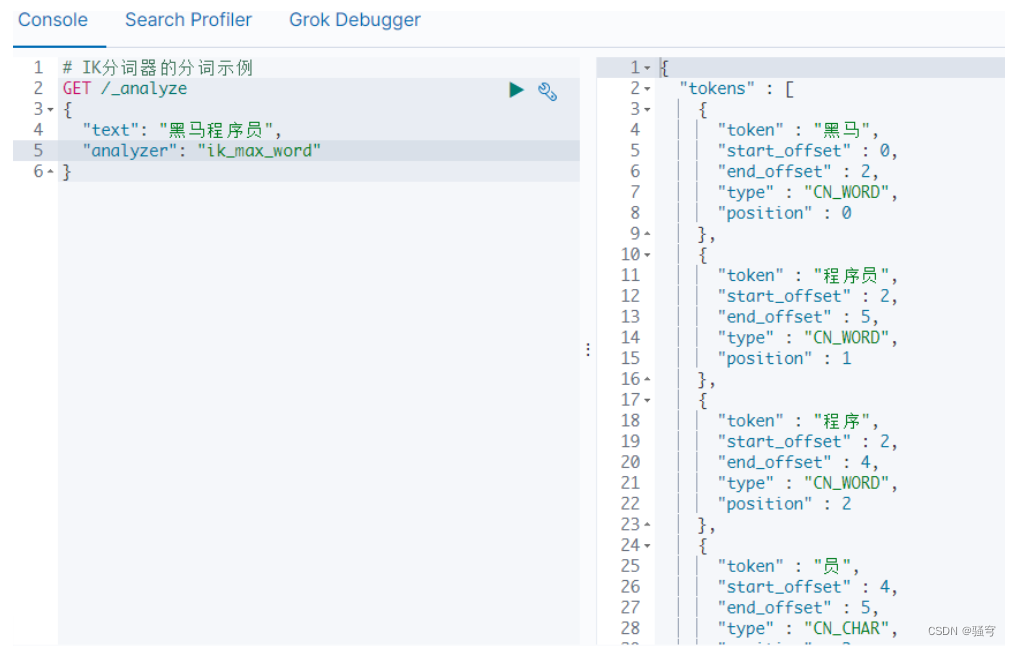
4. 安装过程中可能出现的问题
1 JDK环境变量问题
现象:启动ES时,黑窗口一闪而过
可能的原因:ElasticSearch7.4,要求使用jdk8或者jdk11。如果JDK版本不正确,启动es会报错(可能是JDK环境变量有问题)
验证方式:打开cmd,执行java -version,看一下JDK版本;再执行javac -version,看一下版本号
2 端口占用问题
现象:启动ES时,黑窗口运行着运行着就关了
可能的原因:苍穹外卖里内网穿透软件cpolar,占用的是9200端口,会导致使用es出问题
解决方式:
-
方式一:关掉cpolar服务或者卸载cpolar,然后重启电脑,再启动es,就没有端口冲突了。es会占用9200端口
关闭cpolar的方式:Windows+R,运行 services.msc,找到 Cpolar 服务,右键停止;然后右键属性,启动方式修改为手动
-
方式二:不管它,es发现9200被占用,它会自动改用其它端口。要看一下启动es的控制台,看它的端口是多少 (一般是9201)。
然后Kibana要配置连接ES时的地址,配置成 http://localhost:9201
3 操作系统权限问题
你的电脑当前用户权限不足,会导致启动es和Kibana会报错 “operate not promitted...”。解决方法是:
es文件夹和Kibana文件夹都需要设置:
-
在文件夹上右键-属性-安全-编辑-添加
-
在弹出的容器里,添加当前计算机用户名(可以在cmd里使用
net user查看)
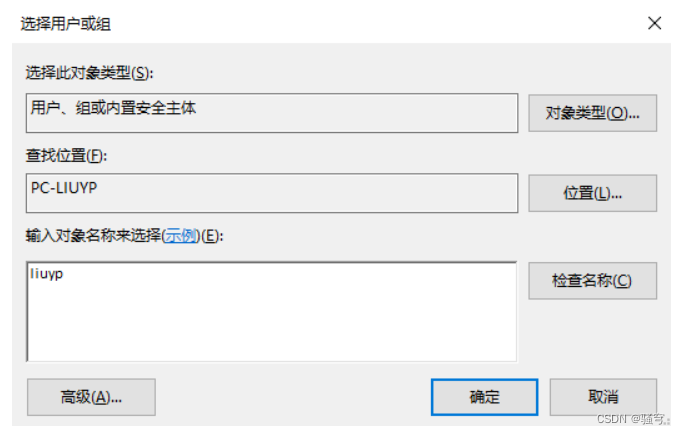
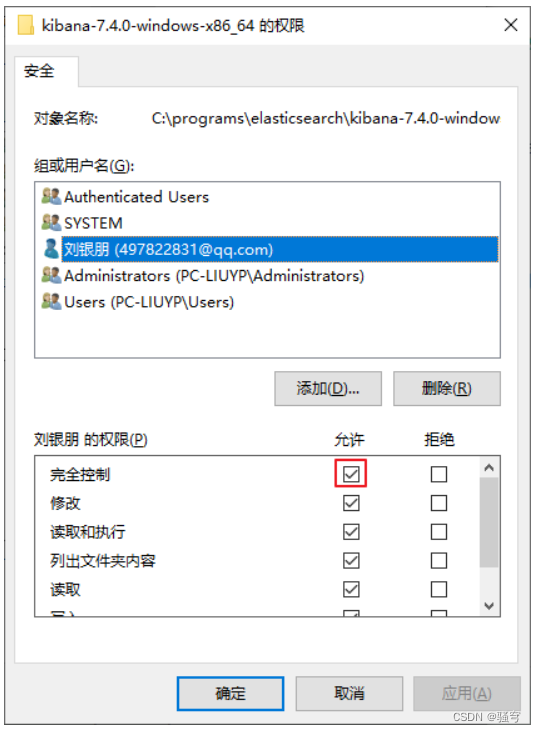
勾选中这个用户,点击下边的“完全控制”,再确定
3. ik分词器
ES标准分词器的问题
ES自带的分词器叫“Standard Analyzer”,它对中文的支持非常不友好,会将一个词语的每个字拆分成一个词条,和中文的语法是完全不符的。
例如,一个词语“黑马程序员”,按中文语法习惯可以拆分成“黑马”,“程序员”,“程序”等词条。但是标准分词器分拆分成“黑”,“马”,“程”,“序”,“员”
示例如下:
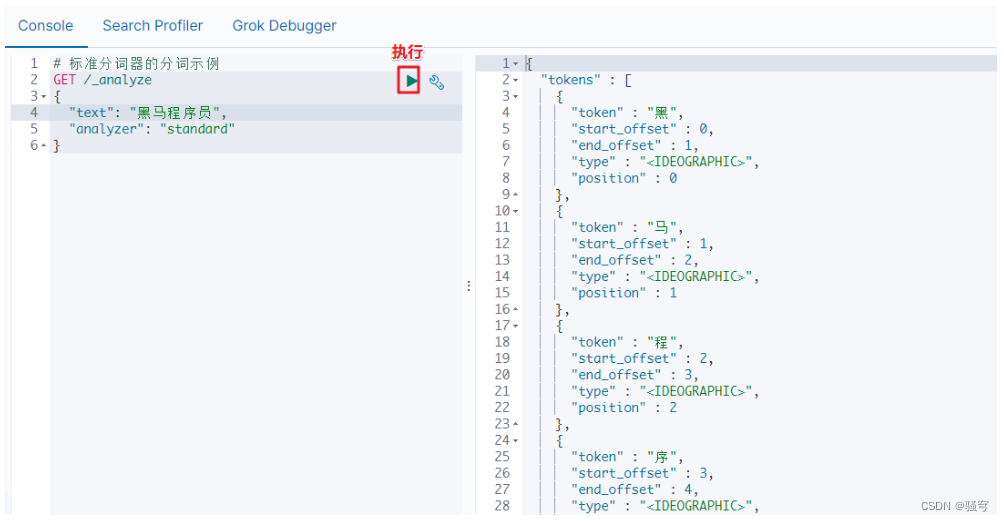
IK分词器的使用示例
在浏览器的kibana开发工具界面,输入并执行
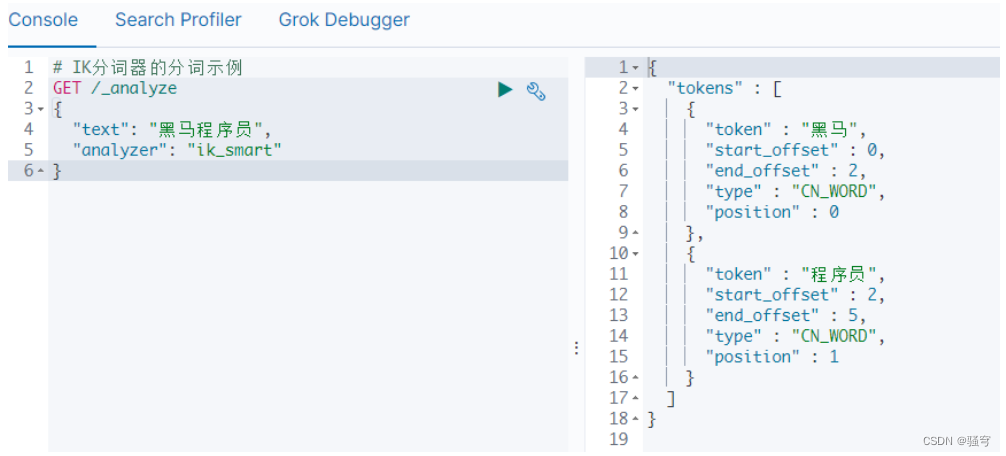
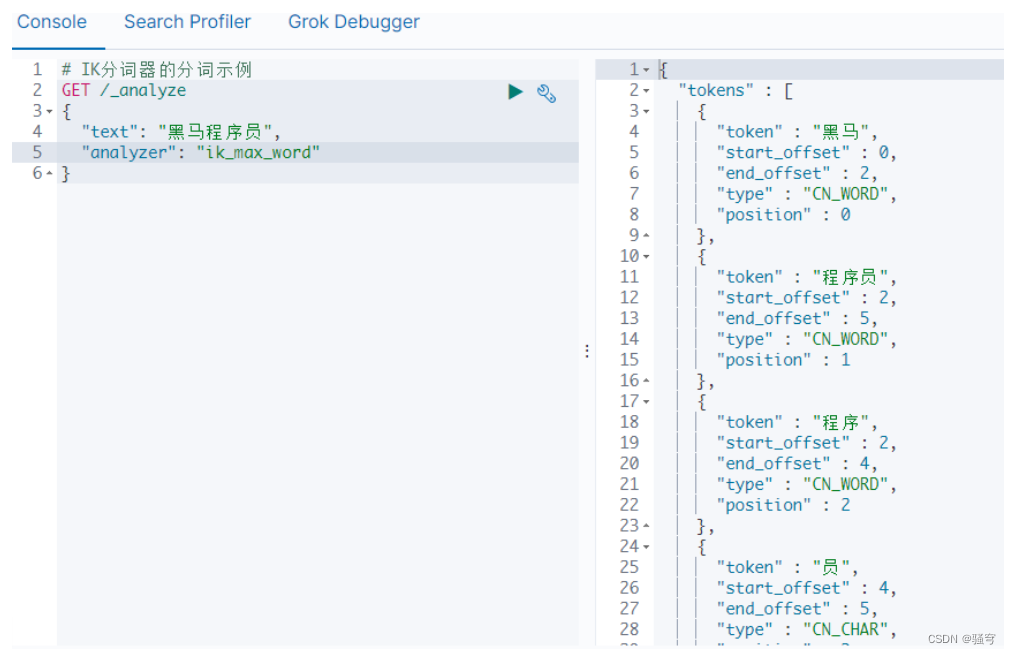
4. 小结


ES于客户端连接
安装ElasticSearch
-
准备工作
先把镜像文件上传到Linux里。加载镜像文件:docker load -i 文件名
准备文件夹和配置文件,稍后要用于跟es容器进行挂载
-
创建es容器。
-
把ik分词器上传到Linux里
-
创建Kibana容器
分词器:
-
es自带标准分词器:standard分词器,对中文分词效果不好
-
ik分词器:对中文分词效果好。分词粒度有:
ik_smart:智能分词
ik_max_word:尽可能拆分出更多的词条
三、操作索引
ES我们通常不用java去创建索引库,一般直接在kibana直接几行直接搞定
1. ES的核心概念
老版本(es7之前)结构:
Indices----->Type---->document----->field
Database-->Table--->row-------------->column
从es7开始,抛弃了type的概念:
Index(索引库)-->Document(json文档)-->Field(json里的key)
Table------------->Row------------------------->column


2. 操作索引库
1 索引库映射mapping(类似MySql的表结构)
说明
映射mapping:目的是为了给索引的每个Field设置类型(字符串,数字,日期,对象,数组……)
在MySql里,我们在插入一条记录之前,需要提前设置好表里每个每个字段的类型。
而类似的,在ES里,我们需要给每个索引库设置映射信息
参考:Put mapping API | Elasticsearch Guide [7.4] | Elastic
映射类型
每个字段field要设置的 常见的maping属性有:
-
type:字段的类型,常见的简单类型有
-
text:可分词的文本字符串。如果是text,需要设置
analyzer分词器 -
keyword:不分词的文本字符串。某些字符串一旦分词就失去意义了,例如品牌、国家、ip地址、url地址等
-
byte,short,integer,long,double,float等数值
-
boolean
-
date日期。ES可以把日期格式化为字符串存储,但是为了节省空间,建议使用long存储毫秒值
-
object对象。如果是object,需要设置
properties
-
-
index:是否创建索引,默认true。如果字段值不参与搜索,要设置为false。比如图片url
-
analyzer:使用哪种分词器。text类型时需要设置,其它类型的字段不需要设置
-
properties:字段的子字段。如果字段是object时,需要设置子字段
示例
有如下文档数据,分析该索引库的mapping映射
{
"age": 21, integer
"weight": 52.1, double
"isMarried": false, boolean
"info": "黑马程序员Java讲师", text,要分词;analyzer分词器
"email": "zy@itcast.cn", keyword, 不分词
"score": [99.1, 99.5, 98.9], double
"name": { object
"firstName": "云",
"lastName": "赵"
},
"avatar": "http://www.xx.com/xxx.jpg" keyword, index:false
}
2 索引库的CURD
1 语法
-
创建索引库
PUT /索引库名
{
"mappings":{
"properties":{
"字段名":{
"type": "类型",
"index": true,
"analyzer": "分词器",
...
},
"字段名":{
"type": "类型",
"index": true,
"analyzer": "分词器",
...
},
...
}
}
}
-
查看索引库
查看所有索引库:
GET /_cat/indices查看某个索引库:
GET /索引库名 -
修改索引库
注意:es里不能修改已有字段,可以给索引库添加字段
因为创建好索引库后,es会构建倒排索引,这个过程是比较消耗性能的。一旦索引库的某个字段被修改,可能会导致原本的倒排索引失效,影响太大,所以es不能修改索引库中已有的字段。
PUT /索引库名/_mapping
{
"properties":{
"新字段名":{
"type": "类型",
"index": true,
...
},
"新字段名":{
"type": "类型",
"index": true,
...
},
...
}
}
删除索引库:DELETE /索引库名
2 示例
要求:创建一个索引库,用于存储黑马讲师的信息
#1. 创建索引(相当于创建一张表)
PUT /heima
{
"mappings": {
"properties": {
"age":{
"type": "integer"
},
"weight":{
"type": "double"
},
"isMarried":{
"type": "boolean"
},
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"score":{
"type": "double",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName":{
"type":"keyword"
},
"lastName":{
"type":"keyword"
}
}
}
}
}
}#2. 查看索引
GET /heima
# 查看所有索引
GET /_cat/indices?v#3. 修改索引:给索引添加字段
PUT /heima/_mapping
{
"properties":{
"address":{
"type": "keyword"
}
}
}#删除heima索引库
DELETE /heima
3 课堂演示
#创建一个索引库(相当于建表)
PUT /product
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "integer"
},
"stock":{
"type": "integer"
},
"image":{
"type": "keyword",
"index": false
}
}
}
}
#查看索引库
# 查看某个索引库 GET /索引库名
GET /product
# 查看所有索引库 GET /_cat/indices
GET /_cat/indices
#修改索引库。
# 注意:不能修改已有字段,只能增加新字段
PUT /product/_mapping
{
"properties":{
"category":{
"type": "keyword"
}
}
}
#删除索引库 DELETE /索引库名
DELETE /product
3 练习
要求1:创建一个索引库itcast,用于存储商品信息。要有以下字段:
-
商品id id
-
商品名称 title
-
商品价格 price
-
所属品牌 brand
-
商品库存量 quantity
-
商品图片url地址 images
要求2:查看索引库itcast的信息
要求3:给索引库itcast增加一个字段“商品分类 category”
要求4:删除索引库itcast
#练习:
# 1. 创建索引库
PUT /itcast
{
"mappings": {
"properties": {
"id":{
"type": "integer"
},
"title":{
"type": "text",
"analyzer": "ik_smart"
},
"price":{
"type": "double"
},
"brand":{
"type": "keyword"
},
"quantity":{
"type": "integer"
},
"images":{
"type": "keyword",
"index": false
}
}
}
}
#2. 查询索引库
GET /_cat/indices
GET /itcast
#3. 增加一个字段
PUT /itcast/_mapping
{
"properties":{
"category":{
"type": "keyword"
}
}
}
#. 删除索引库
DELETE /itcast
3. 小结




ES的几个概念:
-
Index:索引。相当于MySQL里的表
-
Document:文档。相当于MySQL表里的一行数据。只不过是json格式
-
Field:字段。相当于MySQL表里的字段
-
Mapping:映射。相当于MySQL表的结构,包括有哪些字段、字段的类型、约束等等
索引的映射结构:创建索引时,每个字段需要设置
-
type类型:
-
字符串有2种
text:如果字段值是字符串,并且要分词,就使用text。如果是text,就必须给这个字段设置analyzer
keyword:如果字段值是字符串,并且不分词,就使用keyword
-
数字类型:byte, short, integer, long, double, float等等
-
布尔类型:boolean
-
日期类型:date
-
对象类型:object
-
-
index是否参与搜索:如果某个字段的值,不需要根据这个字段搜索数据,就给字段设置index值为false
-
analyzer:分词器。如果字段类型是text的时候,必须设置分词器。
standard 标准分词器
ik_smart ik智能分词
ik_max_word ik细粒度的分词
操作ES索引的语法:
#创建索引
PUT /索引库名
{
"mappings":{
"properties":{
"字段名":{
"type": 类型,
"index": 是否参与搜索 如果不参与搜索 设置为false,
"analyzer": 分词器 如果类型是text就必须设置分词器 通常用ik_smart或ik_max_word
},
"字段名":{
"type": 类型,
"index": 是否参与搜索 如果不参与搜索 设置为false,
"analyzer": 分词器 如果类型是text就必须设置分词器 通常用ik_smart或ik_max_word
},
"字段名":{
"type": 类型,
"index": 是否参与搜索 如果不参与搜索 设置为false,
"analyzer": 分词器 如果类型是text就必须设置分词器 通常用ik_smart或ik_max_word
},
....
}
}
}#查看索引库
# 查看某一名称的索引库结构
GET /索引库
# 查看所有索引库
GET /_cat/indices#修改索引。不能修改已有字段,只能 增加新字段
PUT /索引库名/_mapping
{
"properties":{
"字段名":{
"type": 类型,
"index": 是否参与搜索 如果不参与搜索 设置为false,
"analyzer": 分词器 如果类型是text就必须设置分词器 通常用ik_smart或ik_max_word
},
....
}
}
#删除索引
DELETE /索引库名
四、操作文档
本章节学习目标:
- 掌握文档的CURD
1. 语法
参考:Document APIs | Elasticsearch Guide [7.4] | Elastic
-
新增与修改文档
如果文档id不存在:是新增文档
如果文档id已存在:是修改文档,会直接覆盖掉原文档
PUT /索引库名/_doc/文档id
{
"key": value,
...
"key": value
}
-
查看文档:
GET /索引库名/_doc/id -
修改文档:增量修改。
在原文档基础上进行修改某些字段的值
POST /索引库名/_update/文档id
{
"doc":{
"字段1": 值1,
"字段2": 值2,
...
}
}
删除文档:DELETE /索引库名/_doc/id值
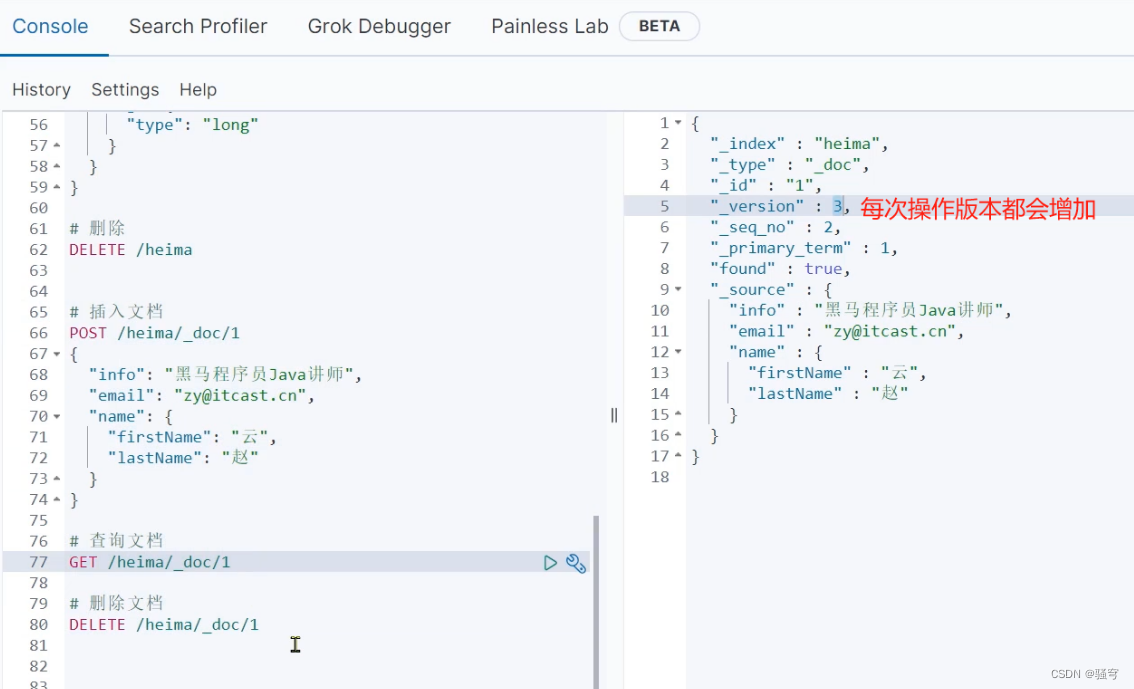
2. 示例
#1. 新增文档
PUT /itcast/_doc/1
{
"title":"小米手机",
"price":4999,
"brand":"小米",
"images":"http://www.mi.com/mi8.jpg"
}#2. 查看文档
GET /itcast/_doc/1#3. 修改文档
# 全量修改,相当于使用新文档把旧文档替换掉了
PUT /itcast/_doc/1
{
"price": 9999
}
# 增量修改,在原本文档基础上做修改
POST /itcast/_update/1
{
"doc": {
"price":9999
}
}#4. 删除文档
DELETE /itcast/_doc/1
3. 课堂演示
#-----文档的CURD-------------
#先准备一个索引(先准备一张表)
DELETE /product
PUT /product
{
"mappings": {
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "integer"
},
"stock":{
"type": "integer"
},
"image":{
"type": "keyword",
"index": false
}
}
}
}
#新增一条文档数据
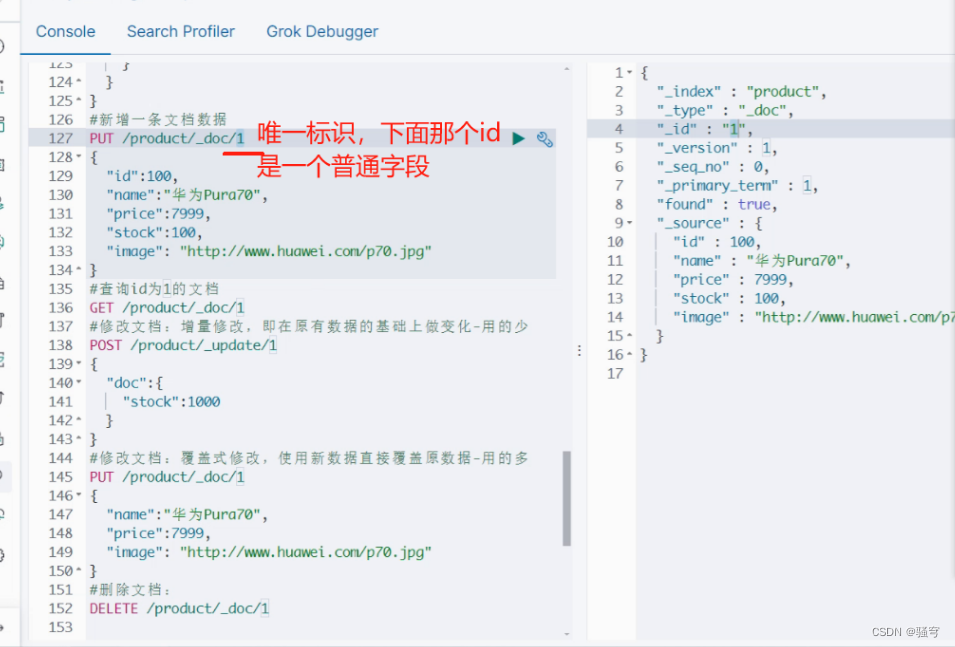
PUT /product/_doc/1
{
"id":100,
"name":"华为Pura70",
"price":7999,
"stock":100,
"image": "http://www.huawei.com/p70.jpg"
}
#查询id为1的文档
GET /product/_doc/1
#修改文档:增量修改,即在原有数据的基础上做变化-用的少
POST /product/_update/1
{
"doc":{
"stock":1000
}
}
#修改文档:覆盖式修改,使用新数据直接覆盖原数据-用的多
PUT /product/_doc/1
{
"name":"华为Pura70",
"price":7999,
"image": "http://www.huawei.com/p70.jpg"
}
#删除文档:
DELETE /product/_doc/1
#查询列表
POST /product/_search
4. 动态映射
思考
如果新增文档的结构,与mapping结构不一致,会出现什么结果
例如
#插入的文档结构,与mapping结构不符。itcast索引库中原本没有color、weight、stock、isSoldOut四个字段
PUT /itcast/_doc/2
{
"title": "罗技鼠标",
"price": 89,
"images": "http://www.jd.com/xxxx.jpg",
"quantity": 50,
"weight": 0.22,
"color": "black",
"isSoldOut": false
}
查询索引的映射:GET /itcast/_mapping
看到结果
{
"itcast" : {
"mappings" : {
"properties" : {
"color" : { #增加了color字段,是字符串。ES无法判断类型,因此存储了两种映射类型。color是text类型,color.keyword是keyword类型
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"images" : {
"type" : "keyword",
"index" : false
},
"isSoldOut" : { #增加了isSoldOut字段,类型boolean
"type" : "boolean"
},
"price" : {
"type" : "double"
},
"quantity" : {
"type" : "integer"
},
"title" : {
"type" : "text",
"analyzer" : "ik_smart"
},
"weight" : { #增加了weight字段,类型float
"type" : "float"
}
}
}
}
}
说明
插入文档时,es会检查文档中的字段是否有对应的mapping,如果没有,则按照默认的mapping规则来创建索引。
如果默认的mapping不符合你的要求,一定要自己设置字段的mapping
5. 小结




#新增一条文档。如果唯一标识对应的文档不存在,是新增。如果已存在,会覆盖掉
PUT /索引/_doc/唯一标识
{
"字段":值,
"字段":值,
...
}
#查看一条文档
GET /索引/_doc/唯一标识
#修改一条文档:增量修改,即在原本文档基础上做变更
POST /索引/_update/唯一标签
{
"doc":{
"字段":值,
"字段":值,
...
}
}
#修改一条文档:覆盖式修改,直接拿新的json文档,把旧的json文档覆盖掉
PUT /索引/_doc/唯一标识
{
"字段":值,
"字段":值,
...
}
#删除一条文档
DELETE /索引/_doc/唯一标识#查询列表
POST /product/_search
五、RestAPI
1. 准备工作
官方文档:Compatibility | Java REST Client [7.4] | Elastic
1 创建project导入依赖
导入es的客户端依赖坐标
注意:es客户端依赖的版本号,必须要和es的版本号一致
<dependencies>
<!--es客户端-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.0</version>
</dependency><!-- https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-api -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.8.2</version>
</dependency><dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
</dependencies>
2 创建实体类
商品Product,对应es里的product索引
package com.itheima.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
@AllArgsConstructor
public class Product {
private Long id;
/**标题*/
private String title;
/**分类*/
private String category;
/**品牌*/
private String brand;
/**价格*/
private Double price;
/**图片地址*/
private String images;
}
3 RestAPI的使用说明
要想操作es,需要按照如下步骤:
-
创建RestHighLevelClient对象
-
使用RestHighLevelClient操作es
-
关闭RestHighLevelClient
//1. 创建RestHighLevelClient客户端对象。
// 如果连接ES集群,就写多个地址;
// 如果是单ES实例,就只写一个地址
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("localhost", 9200)
));//2. 使用client操作es
//3. 关闭client
client.close();
2. 操作索引【了解】
1 API说明
RestHighLevelClient对象提供了操作索引库的API方法,常用的有:
-
创建:
restClient.indices().create(CreateIndexRequest request, RequestOptions options) -
删除:
restClient.indices().delete(DeleteIndexRequest request, RequestOptions options) -
是否存在:
restClient.indices().exists(GetIndexRequest request, RequestOptions options)
以上方法的参数:
-
CreateIndexRequest:创建索引库的请求对象 -
DeleteIndexRequest:删除索引库的请求对象 -
GetIndexRequest:查询索引库的请求对象 -
RequestOptions:创建索引库的请求选项,使用固定值RequestOptions.DEFAULT即可
注意事项:
-
使用RestAPI创建索引库非常繁琐,建议在Kibana里使用DSL语句执行操作,而不是用Java代码创建索引库
2 使用示例
索引库分析
要把一条商品信息存储到es,我们要先分析一下对应的索引库及映射该如何编写:
-
id: 商品id,可以使用long类型
-
title:商品名称,使用text类型,要分词并构建倒排索引进行搜索
-
category:商品分类,分类是整体,不进行分词,使用keyword
-
brand:品牌,和分类类似,不进行分词,使用keyword
-
price:价格,double类型
-
images:图片地址,用来展示的字段,不需要构建索引,不参与搜索;index设置为false,使用keyword类型
编辑DSL命令如下:
DELETE /product
PUT /product
{
"mappings":{
"properties":{
"id":{
"type": "long"
},
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"category":{
"type": "keyword"
},
"brand":{
"type": "keyword"
},
"price":{
"type": "double"
},
"images":{
"type": "keyword",
"index": false
}
}
}
}
操作示例
使用RestHighLevelClient操作的示例代码如下:
package com.itheima;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
public class Demo01Index {
private RestHighLevelClient client;
/**
* 创建索引库
*/
@Test
public void testCreateIndex() throws IOException {
String json = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"long\"\n" +
" },\n" +
" \"title\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"category\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"brand\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"price\": {\n" +
" \"type\": \"double\"\n" +
" },\n" +
" \"images\": {\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
CreateIndexRequest request = new CreateIndexRequest("itheima")
.source(json, XContentType.JSON);
client.indices().create(request, RequestOptions.DEFAULT);
}
/**
* 删除索引库
*/
@Test
public void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("itheima");
client.indices().delete(request, RequestOptions.DEFAULT);
}
/**
* 索引库是否存在
*/
@Test
public void testExistsIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("itheima");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
@BeforeEach
public void init(){
client = new RestHighLevelClient(RestClient.builder(
new HttpHost("localhost", 9200)
));
}
@AfterEach
public void destroy() throws IOException {
client.close();
}
}3. 操作文档【重点】
1 API说明
使用Java操作文档,和在kibana里编写DSl非常类似。只是由Java代码来执行相同的操作
RestHighLevelClient提供了操作文档的API如下:
-
新增与修改:
client.index(IndexRequest request, RequestOptions options) -
查看:
client.get(GetRequest request, RequestOptions options) -
删除:
client.delete(DeleteRequest request, RequestOptions options)
以上方法的参数:
-
IndexRequest:新增与修改文档的请求对象 -
GetRequest:查询文档的请求对象 -
DeleteRequest:删除文档的请求对象 -
RequestOptions:请求选项参数,使用固定值RequestOptions.DEFAULT即可
2 使用示例
package com.itheima;
import com.alibaba.fastjson.JSON;
import com.itheima.pojo.Product;
import org.apache.http.HttpHost;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
public class Demo02Document {
RestHighLevelClient client = null;
/**
* 保存文档
* 如果id不存在,是新增
* 如果id已存在,是修改
*/
@Test
public void testSaveDocument() throws IOException {
Product product = new Product(1L, "华为 Mate40 pro", "手机数码", "华为", 5200D, "http://images.huawei.com/pro40.jpg");
String productJson = JSON.toJSONString(product);
//1. 准备Request对象,设置索引库名称
IndexRequest indexRequest = new IndexRequest("product")
//设置文档id
.id(product.getId().toString())
//设置文档数据
.source(productJson, XContentType.JSON);
//2. 发送请求
client.index(indexRequest, RequestOptions.DEFAULT);
}
/**
* 查看文档
*/
@Test
public void testFindDocument() throws IOException {
//1. 准备Request
GetRequest getRequest = new GetRequest("product", "1");
//2. 发送请求
GetResponse response = client.get(getRequest, RequestOptions.DEFAULT);
//3. 处理响应结果
String docJson = response.getSourceAsString();
Product product = JSON.parseObject(docJson, Product.class);
System.out.println(product);
}
/**
* 删除文档
*/
@Test
public void testDeleteDocument() throws IOException {
//1. 准备Request
DeleteRequest deleteRequest = new DeleteRequest("product", "1");
//2. 发送请求
client.delete(deleteRequest, RequestOptions.DEFAULT);
}
@BeforeEach
public void init() {
client = new RestHighLevelClient(RestClient.builder(
new HttpHost("localhost", 9200)
));
}
@AfterEach
public void destroy() throws IOException {
client.close();
}
}4. 批量操作文档
1 说明
批量操作的核心在于将多个普通请求封装在一个批量请求中,一次性发送到服务器,下面仅仅演示批量新增(其他自己尝试)
操作的步骤:
-
准备BulkRequest对象
-
把每个文档数据,封装到一个IndexRequest对象里。把IndexRequest添加到BulkRequest对象中
-
使用client.bulk(bulkRequest对象, RequestOptions.DEFAULT)
2 示例
/**
* 批量操作文档
*/
@Test
public void testBulkDocument() throws IOException {
//0. 模拟数据
List<Product> list = new ArrayList<Product>();
list.add(new Product(11L, "小米手机", "手机数码", "小米", 3299.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(12L, "锤子手机", "手机数码", "锤子", 3699.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(13L, "联想手机", "手机数码", "联想", 4499.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(14L, "红米手机", "手机数码", "小米", 4299.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(15L, "iPhone X", "手机数码", "苹果", 8299.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(16L, "MacBook pro", "电脑", "苹果", 14999.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(17L, "AirPods", "手机数码", "苹果", 4299.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(18L, "外星人", "电脑", "DELL", 21299.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(19L, "联想小新", "电脑", "联想", 6299.00, "http://image.huawei.com/13123.jpg"));
//1. 创建Request
BulkRequest bulkRequest = new BulkRequest();
//2. 添加数据
for (Product product : list) {
//2.1 把一个Product对象,封装到一个IndexRequest对象里
IndexRequest indexRequest = new IndexRequest("product").id(product.getId().toString());
indexRequest.source(JSON.toJSONString(product), XContentType.JSON);
//2.2 把一个IndexRequest对象添加到BulkRequest对象里
bulkRequest.add(indexRequest);
}
//3. 发送请求
client.bulk(bulkRequest, RequestOptions.DEFAULT);
}5. 小结
使用Java操作ES,准备工作:
-
添加依赖坐标:关键是elasticsearch-rest-high-level-client。我们提供的工程里已经有了,不需要额外再添加
-
修改配置文件:没有 跟es相关的配置,但是为了防止启动连接数据库不存在,先执行SQL脚本
-
把客户端连接对象放到IoC容器里。把以下代码加到引导类里,或者加到一个配置类里
@Bean
public RestHighLevelClient esClient(){
return new RestHighLevelClient(RestClient.builder(
new HttpHost("192.168.200.130", 9200)
));
}
4. 创建单元测试类,添加@SpringBootTest,再注入RestHighLevelClient对象
操作索引的API
//1. 创建索引
CreateIndexRequest request = new CreateIndexRequest("索引名")
.source("json字符串", XContentType.JSON);
esClient.indices().create(request, RequestOptions.DEFAULT);
//2. 删除索引
DeleteIndexRequest request = new DeleteIndexRequest("索引名");
esClient.indices().delete(request, RequestOptions.DEFAULT);
//3. 判断索引是否存在
GetIndexRequest request = new GetIndexRequest("索引名")
boolean exists = esClient.indices().exists(request, RequestOptions.DEFAULT);操作文档的API
//1. 新增或修改
IndexRequest request = new IndexReuqest("索引名")
.id("文档唯一标识")
.source("文档json字符串", XContentType.JSON);
esClient.index(request, RequestOptions.DEFAULT);
//2. 查询
GetRequset request = new GetRequest("索引名").id("文档唯一标识");
GetResponse response = esClient.get(request, RequestOptions.DEFAULT);
String docJson = response.getSourceAsString();
//3. 删除
DeleteRequest request = new DeleteRequest("索引名").id("文档唯一标识");
esClient.delete(request, RequestOptions.DEFAULT);
//4. 批量操作:通常用于批量新增,也可以用于批量删除等写操作
BulkRequest bulkRequest = new BulkRequest("索引名");
for(Xxx xx: list){
//准备IndexRequest对象
IndexRequest request = new IndexRequest()
.id(xx.getId().toString())
.source(JSON.toJSONString(xx), XContentType.JSON);
//把IndexRequest添加到BulkRequest对象里
bulkRequest.add(request);
}
//最后一次性把BulkRequest里的数据存储到es里
esClient.bulk(bulkRequest, RequestOption.DEFAULT);六、练习
需求
执行SQL脚本《资料/tb_hotel.sql》,其中有tb_hotel表,存储了酒店的数据
利用BulkRequest批量将数据库数据导入到索引库中。
步骤
-
根据数据库表结构,在es里创建对应的索引库
-
使用Java程序读取MySQL数据,再使用RestHighLevelClient存储到es的索引库里
实现
1. 创建索引库
使用Kibana执行DSL语句创建索引库,DSL语句如下:
# 创建酒店索引
PUT /hotel
{
"mappings": {
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "text",
"analyzer": "ik_smart",
"copy_to": "all"
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword",
"copy_to": "all"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
2. 准备环境
创建一个新的project,执行以下步骤:
导入依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.9.RELEASE</version>
</parent><!--全局锁定ES客户端的版本号-->
<properties>
<elasticsearch.version>7.4.0</elasticsearch.version>
</properties><dependencies>
<!--es客户端-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
<!-- web起步依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- mp和mysql -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.33</version>
</dependency><!-- 单元测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency><!-- json转换 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
配置文件
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql:///es
username: root
password: root
引导类
@SpringBootApplication
@MapperScan("com.itheima.mapper")
public class HotelApplication {
public static void main(String[] args) {
SpringApplication.run(HotelApplication.class, args);
}
}
实体类Hotel
对应MySQL的tb_hotel表
package com.itheima.pojo;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName("tb_hotel")
public class Hotel {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String longitude;
private String latitude;
private String pic;
}实体类HotelDoc
对应ES的文档数据
package com.itheima.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}HotelMapper
public interface HotelMapper extends BaseMapper<Hotel> {
}3. 批量插入数据
package com.itheima;
import com.alibaba.fastjson.JSON;
import com.itheima.mapper.HotelMapper;
import com.itheima.pojo.Hotel;
import com.itheima.pojo.HotelDoc;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.List;
@SpringBootTest
public class HotelTest {
@Autowired
private HotelMapper hotelMapper;
@Test
public void test() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200)));
//1. 读取数据库里所有的酒店数据
List<Hotel> list = hotelMapper.selectList(null);
//2. 循环酒店列表,把每个酒店数据添加到BulkRequest对象里
BulkRequest bulkRequest = new BulkRequest();
for (Hotel hotel : list) {
//把每个Hotel对象转换成对应ES的HotelDoc对象
HotelDoc doc = new HotelDoc(hotel);
//创建IndexRequest对象
IndexRequest request = new IndexRequest("hotel").id(doc.getId().toString()).source(JSON.toJSONString(doc), XContentType.JSON);
bulkRequest.add(request);
}
//3. 执行批量插入
client.bulk(bulkRequest, RequestOptions.DEFAULT);
//4. 关闭连接
client.close();
}
}总结









大总结
ES是什么?是一个开源的搜索引擎,可以从海量数据里快速找到目标数据
ES为什么快?其中有一个原因就是使用了倒排索引
-
正向索引:找到一条数据记录,判断是否符合条件。可能会出现全表扫描
-
倒排索引:直接根据搜索条件,定位到符合条件的文档数据。不会有全表扫描,性能更高
ES和MySQL(关系型数据库)的对比
-
共同点:都可以增删改查数据
-
不同点:
MySQL或其它关系型数据库:擅长事务型的操作,增删改,因为有严谨的事务保证数据的一致性和完整性
ES搜索:擅长查询检索,因为ES有倒排索引,更适合于从海量数据里快速查询检索数据。特别是文本字符串的模糊匹配
-
实际使用时:两者配合使用
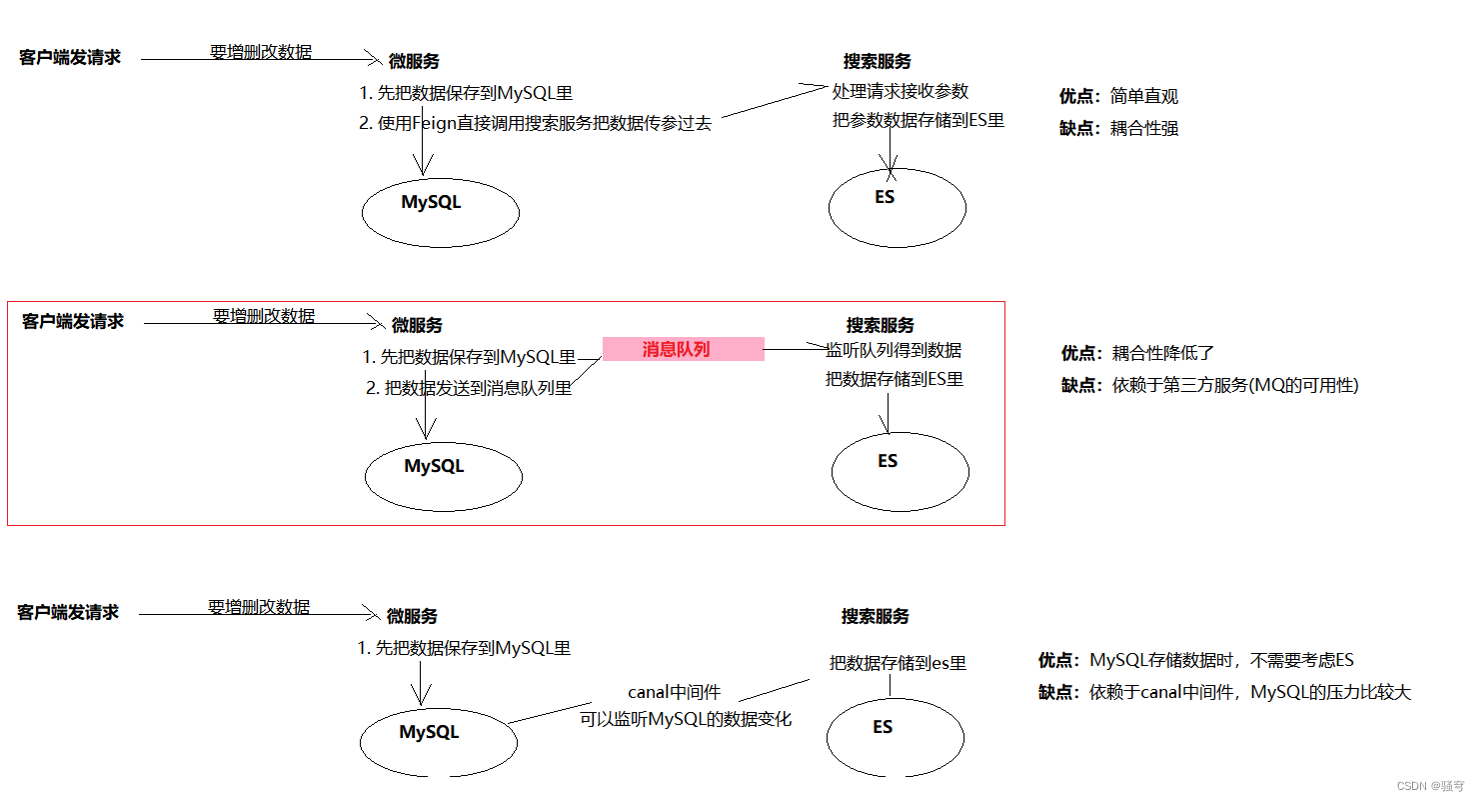
如果需要增删改数据,要操作MySQL
然后把MySQL里的数据同步到ES里
然后再从ES里查询检索数据
ES相关的几个概念:
-
Index:索引。相当于MySQL里的表
-
Mapping:映射。相当于MySQL里的表结构。即表里有什么字段、字段是什么类型、字段有什么其它限制约束等等
-
Field:字段。相当于MySQL表里的字段
-
Document:文档。是json格式的,相当于MySQL里的一行数据记录
-
DSL:用于操作ES的命令语法,相当于操作关系型数据库的SQL语句
DSL命令操作索引
#创建索引
PUT /索引名
{
"mappings":{
"properties":{
"字段名":{
"type": 类型, #类型常用的有:text,keyword,byte,short,integer,long,double,float, boolean, date, geo_point
"index": 是否参与搜索,
"analyzer": 分词器 如果类型是text,就需要设置分词器 #ik_smart, ik_max_word
},
....
}
}
}
#查询所有索引
GET /_cat/indices
#查看某一索引
GET /索引
#修改索引:不能修改已有字段,只能增加新字段
PUT /索引/_mapping
{
"properties":{
"字段名":{
"type": 类型, #类型常用的有:text,keyword,byte,short,integer,long,double,float, boolean, date, geo_point
"index": 是否参与搜索,
"analyzer": 分词器 如果类型是text,就需要设置分词器 #ik_smart, ik_max_word
},
....
}
}
#删除索引
DELETE /索引
DSL命令操作文档
#新增文档(覆盖式修改索引)
PUT /索引/_doc/唯一标识
{
"字段": 值,
"字段": 值,
...
}
#查看某一文档
GET /索引/_doc/唯一标识
#查看文档列表
POST /索引/_search
#增量修改
POST /索引/_update/唯一标识
{
"doc":{
"字段": 值,
"字段": 值,
...
}
}
#删除文档
DELETE /索引/_doc/唯一标识
Java操作索引
-
先添加依赖坐标:elasticsearch-rest-high-level-client
-
把RestHighLevelClient对象放到IoC容器里:在配置类里或者在引导类里添加
@Bean
public RestHighLevelClient esClient(){
return new RestHighLevelClient(RestClient.builder(
new HttpHost("ip地址", 端口)
));
}
操作索引的Api
esClient.indices().create(CreateIndexRequest request, RequestOptions options);
esClient.indices().delete(DeleteIndexRequest request, RequestOptions options);
esClient.indices().exists(GetIndexRequest request, RequestOptions options);
Java操作文档
esClient.index(IndexRequest request, RequestOptions options);
GetResponse response = esClient.get(GetRequest request, RequestOptions options);
esClient.delete(DeleteRequest request, RequestOptions options);esClient.bulk(BulkRequest request, RequestOptions options);