笔记来源《计算机体系结构 量化研究方法》。
接着向量体系结构(2)讲,解决最后留下的问题中的两个问题
向量体系结构:向量执行时间-CSDN博客
(1)向量处理器如何实现每个时钟周期处理多于一个元素的能力?
(2)讨论向量处理器在执行过程中对存储器带宽的需求,强调没有足够的内存访问速度,向量性能提升将受限。
多条车道:每个时钟周期超过一个元素
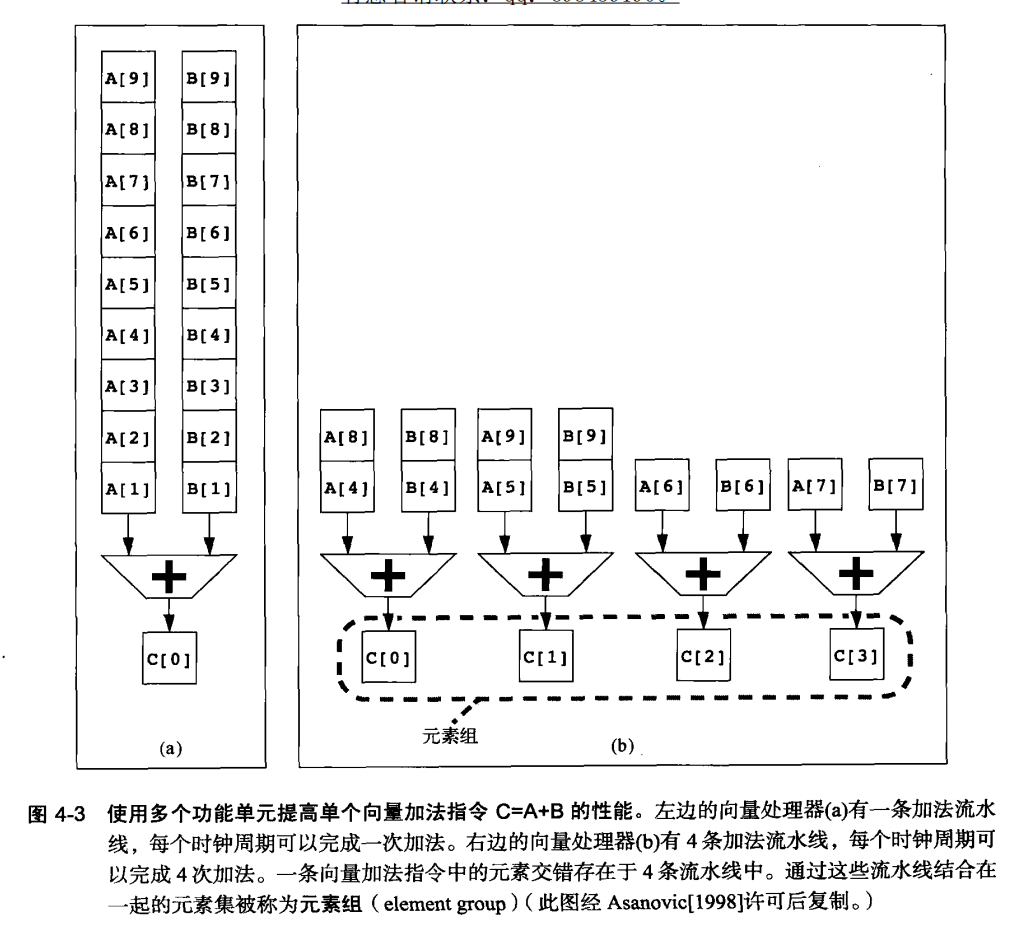
深度流水线、并行功能单元或二者的结合被用来执行这些向量操作,进一步加速了运算过程。例如,图4-3展示的并行流水线执行向量加法,就是通过多个步骤并行处理,减少每个操作的等待时间,从而提升整体性能。
VMIPS指令集要求向量运算中,一个向量寄存器的特定元素只能与另一个向量寄存器中相应位置的元素进行运算。这一限制简化了硬件设计,使得向量单元可以设计成多个独立工作的“车道”,每个车道负责处理不同元素的运算,无需跨车道通信,降低了设计复杂度。
类似于高速公路的多车道设计,向量单元通过增加车道数量来提升吞吐量。图4-4展示的四车道结构。
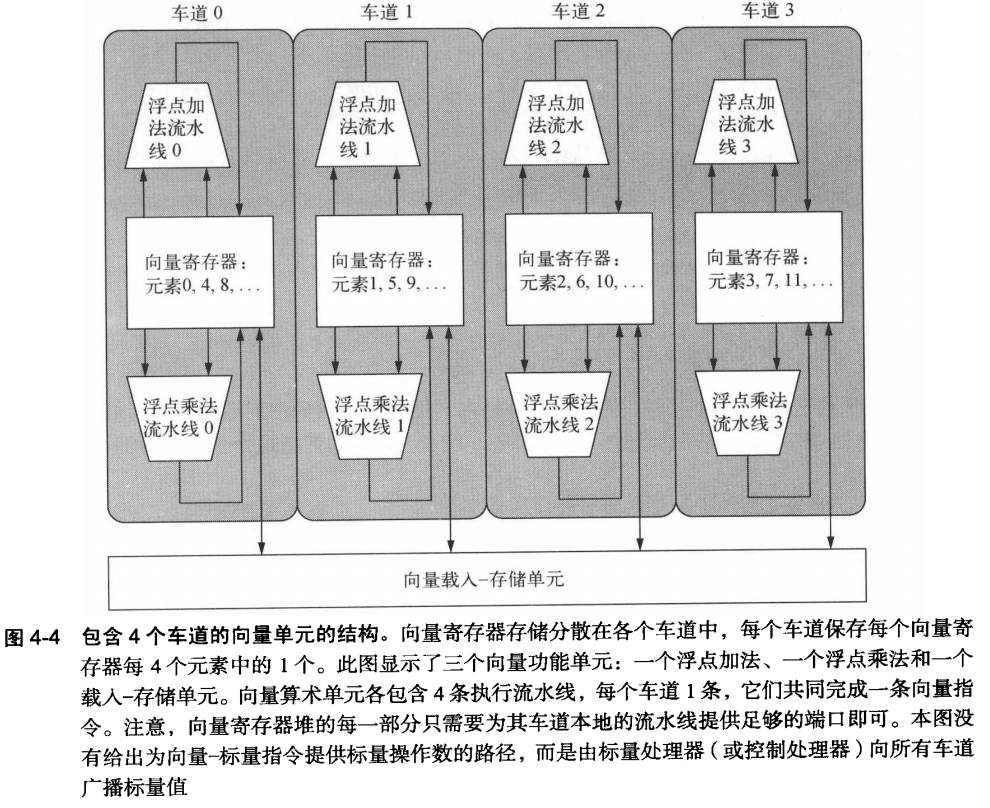
每个车道包含自己的向量寄存器部分和执行单元,使得运算可以在车道内部完成,无需跨车道通信。这不仅减少了延迟,也简化了内存访问路径,提升了执行效率。
增加车道数是一种直接且有效的提升向量性能的方法,而不会大幅增加控制逻辑的复杂度,也不影响现有的软件代码。这种扩展方式给予设计师灵活性,在芯片尺寸、运行频率、电压及能耗之间做出权衡,同时保持或提升系统峰值性能。
??这个地方不太懂。留到以后解答。
疑问:
车道数是什么?
向量处理器中的车道数和向量最大长度有什么关系?
为什么各车道之间互相可以不干扰?
内存组
向量处理器专注于高效处理大规模数据集,比如科学计算中的矩阵乘法。当需要从内存中读取或写入一组连续数据(即向量)时,载入/存储单元负责这项任务。由于数据量大,这些操作要求极高的数据传输速度。内存组的设计是为了提供足够的带宽来满足这种需求,即每个时钟周期至少能处理一个数据字(word)。虽然目标是每个周期处理一个字,但实际上可能“初始化速率” ,因为等待内存响应而变慢。
相比于执行简单算术操作的功能单元,载入和存储向量数据的开始成本更高,因为它们涉及到更复杂的内存交互。
所以引入内存组的概念
通过将内存分割成多个独立的组,可以同时处理多个访问请求,即使在不同组中的数据。这有助于维持高数据传输率,即使单个组可能无法达到这样的速率。
(1)支持非连续访问:向量操作可能涉及跳跃式访问(非连续地址),内存组允许独立寻址,适应这种访问模式,而不仅仅是简单的内存交错访问。
(2)多处理器支持:在多处理器系统中,每个处理器有自己的数据流,内存组设计允许这些处理器并行访问内存,减少争用,提升整体效率。
简单的内存交错技术可能不足以应对向量处理器的复杂需求,特别是当需要高度并发、灵活的寻址模式以及支持多处理器时。内存组提供了更高的灵活性和独立性,是满足这些需求的关键。
疑问:
什么是简单的内存交错技术?
简单的内存交错技术是一种内存管理策略,旨在通过将连续的内存地址映射到不同的内存模块(或内存bank)上,实现对内存的并行访问。
在最基本的实现形式中,内存交错通常按照固定的模式,比如字节、字或更大的块大小,交错分布数据,使得内存访问请求可以被分散到多个物理内存模块上。
例如,如果一个系统有两块内存条,简单的内存交错技术可能会让奇数地址的内存请求指向第一块内存,偶数地址的请求指向第二块内存。这样,当处理器发起连续的内存读写操作时,请求可以交替在两个内存模块之间进行,理论上可以近乎双倍地提升内存带宽,因为两个模块可以几乎同时响应不同的请求。
简单的交错方式有其局限性:
(1)并发性限制:它可能不足以应对高度并发的访问模式,尤其是向量处理器或多处理器系统中,这些系统往往需要同时处理大量数据元素,对内存带宽和并行访问能力有更高要求。
(2)寻址模式限制:简单的交错技术可能不支持复杂的寻址模式,比如非连续的大块数据传输,或特定的向量操作所需的特殊内存访问序列。
(3)灵活性不足:对于需要动态调整内存访问模式以优化性能的场景,简单的交错技术可能不够灵活。
在向量处理器和多核系统中,更复杂的内存管理技术,如内存组(Memory Banks)和更高级的交错策略,被用来提供更高的并行性、灵活性和独立性。
内存组内部构造是什么?
内存组(Memory Banks)是现代计算机系统中内存组织的一种方式,特别是在高性能计算和向量处理器设计中尤为重要。内存组的内部构造通常包括以下几个关键组成部分和特性:
物理存储阵列:每个内存组都包含一个物理存储阵列,这是实际存储数据的地方。存储阵列由许多DRAM(动态随机存取存储器)芯片或类似的存储元件组成,它们构成了内存组的基础存储容量。
控制逻辑:每个内存组都有相应的控制逻辑,负责管理读写请求、地址译码、数据缓冲、刷新操作等。控制逻辑确保数据能够正确、高效地在处理器和内存组之间传输。
数据缓冲区:为了提高效率,内存组通常配备有数据缓冲区,如读取缓存(Read Buffer)和写入缓存(Write Buffer),用来暂存即将读出或写入的数据,减少直接访问DRAM的延迟。
地址映射:内存组的地址映射机制决定了如何将逻辑地址转换为物理地址,并分配到具体的内存bank上。这通常涉及复杂的地址解码电路,确保数据均匀分布在各个bank中,避免访问冲突和提升并行性。
多端口设计:为了支持并行访问,内存组可能设计为多端口,即能够同时接受多个独立的读写请求,每个端口可以服务不同的处理器或计算单元,从而提高整体的内存访问带宽。
交错访问(Interleaving):内存组间可以实施交错访问策略,将连续的地址空间分散到不同bank中,这样在连续访问时,可以交替访问不同的bank,减少等待时间和提高数据传输速率。
错误检测与纠正(ECC):在一些内存组中,还可能集成错误检测与纠正功能,通过额外的校验位来检测和修复数据错误,提高数据的可靠性。
向量体系结构中的内存和CPU中的内存有什么区别?
在向量体系结构中提到的“内存组”(Memory Banks)概念,通常是指一种特殊的内存组织方式,旨在通过增加并行访问的能力来提升内存的带宽。内存组设计允许同时访问不同组内的内存位置,减少了访问冲突,提高了数据传输速率,这对于需要大量数据吞吐的向量运算至关重要。每个内存组都是一个独立的存储区域,有自己的地址空间和数据通路,可以并行工作。
相比之下,CPU中的内存(通常指的是高速缓存和主内存)更多是指CPU直接交互的数据存储资源。CPU内部有多个级别的缓存(如L1、L2、L3缓存),用于暂时存储频繁访问的数据和指令,以减少访问主内存的延迟。主内存(RAM)则是更大容量但访问速度较缓存慢的存储区域,存放程序运行时的数据和代码。CPU通过总线与主内存通信,进行数据的读取和写入。
总结:组织不一样,功能不一样。






![[数据结构]———归并排序](https://img-blog.csdnimg.cn/direct/c6d4a450684449d0ac5cf1e14e89cca7.png)