📚博客主页:knighthood2001
✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下)
🎃知识星球:【认知up吧|成长|副业】介绍
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏笔者水平有限,欢迎各位大佬指点,相互学习进步!
引言
如果你有这样的一个json文件,保存在2.png.json文件中,我需要将其中的文本text读取出来。并将结果保存在txt文件中,如何操作呢。
{
"taskId": 2,
"ocrResult": [
{
"text": "// ocr回调函数,第一个参数是request id,第二个参数是数据,第三个参数是ocrmanage类",
"location": {
"left": 3.7124999,
"top": 1.2375,
"right": 542.02496,
"bottom": 16.0875
},
"pos": {
"x": 3.7124999,
"y": 1.2375
}
},
{
"text": "intcdecl 0cRReadonPush(int al,int a2,int a3)",
"location": {
"left": 3.09375,
"top": 17.943748,
"right": 347.7374,
"bottom": 30.937498
},
"pos": {
"x": 3.09375,
"y": 17.94375
}
}
]
}
实现过程
import json
json_file = r"G:\Desktop\python小项目\调用微信ocr进行识别文字\12.png.json"
save_file = "save.txt"
首先导入json库以及定义好读取json以及保存txt文件的路径。
# 打开 JSON 文件
with open(json_file, 'r', encoding='utf-8') as file:
# 从文件中加载 JSON 数据
data = json.load(file)
接下来就是加载json数据,其中'r'表示read读取,此外,encoding='utf-8'必须需要,否则对中文就会有如下报错。
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x80 in position 71: illegal multibyte sequence
可以打印一下数据以及数据类型:
# 打印读取的 JSON 数据
print(data)
print(type(data))

可以看到这时候的数据类型就是字典,对于字典就可以通过键值对进行查找。
如果你需要打印text内容
# 提取每个对象的 text 字段
for item in data['ocrResult']:
print(item['text'])
如果需要将其保存到txt文件中,你可以通过下面的代码实现
with open(save_file, 'w', encoding='utf-8') as f:
# 提取每个对象的 text 字段
for item in data['ocrResult']:
print(item['text'])
f.write(item['text'] + '\n')
# f.write(item['text'])
首先这里的'w'指的是write写入,encoding='utf-8'这里也不能省,否则写入中文的时候会出现乱码。
然后我们先将item进入到json文件中的'ocrResult'中,然后我们可以通过item['text']获取到对应的文本。
最后通过write写入文本到txt中,这里注意一下,如果不手动添加'\n',则只是保存文本到同一行中。如果需要分行保存,则需要添加一下。
封装一下
这里考虑到有时候我们需要将保存的内容分行保存,有时候又不需要分行保存,所以这里我通过设置一个mode进行分模式保存。
def save_text(json_file, save_file, mode=1):
# 打开 JSON 文件
with open(json_file, 'r', encoding='utf-8') as file:
# 从文件中加载 JSON 数据
data = json.load(file)
# 换行保存
if mode == 1:
with open(save_file, 'w', encoding='utf-8') as f:
# 提取每个对象的 text 字段
for item in data['ocrResult']:
print(item['text'])
f.write(item['text'] + '\n')
if mode == 2:
with open(save_file, 'w', encoding='utf-8') as f:
# 提取每个对象的 text 字段
for item in data['ocrResult']:
print(item['text'])
f.write(item['text'])
save_text(json_file, save_file, mode=2)
此时你可以通过选择mode的参数进行选择是否按行保存,默认按行保存。
全部代码
import json
json_file = r"G:\Desktop\python小项目\调用微信ocr进行识别文字\2.png.json"
save_file = "save.txt"
def save_text(json_file, save_file, mode=1):
# 打开 JSON 文件
with open(json_file, 'r', encoding='utf-8') as file:
# 从文件中加载 JSON 数据
data = json.load(file)
# 换行保存
if mode == 1:
with open(save_file, 'w', encoding='utf-8') as f:
# 提取每个对象的 text 字段
for item in data['ocrResult']:
print(item['text'])
f.write(item['text'] + '\n')
# 不换行保存
if mode == 2:
with open(save_file, 'w', encoding='utf-8') as f:
# 提取每个对象的 text 字段
for item in data['ocrResult']:
print(item['text'])
f.write(item['text'])
save_text(json_file, save_file, mode=2)
结论
json格式文件的读取的内容相对来说还是挺重要的,希望读者朋友们能看懂。



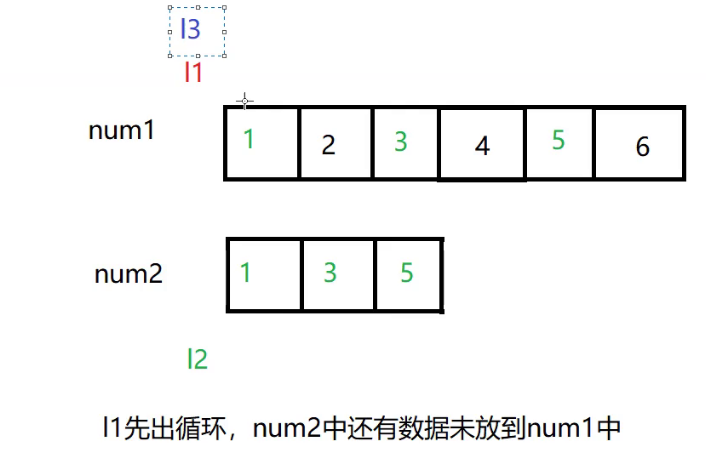

![[数据结构]———归并排序](https://img-blog.csdnimg.cn/direct/c6d4a450684449d0ac5cf1e14e89cca7.png)