小文件是 Hadoop 集群运维中的常见挑战,尤其对于大规模运行的集群来说可谓至关重要。如果处理不好,可能会导致许多并发症。Hadoop集群本质是为了TB,PB规模的数据存储和计算因运而生的。为啥大数据开发都说小文件的治理重要,说HDFS 存储小文件效率低下,比如增加namenode负载等,降低访问效率等?究竟本质上为什么重要?以及如何从本质上剖析小文件,治理小文件呢?今天就带你走进小文件的世界。
1. 什么是小文件?
日常生产中HDFS上小文件产生是一个很正常的事情,有些甚至是不可避免,比如jar,xml配置文件,tmp临时文件,流式任务等都是小文件的组成部分。当然更多的是因为集群设置不合理,造成一些意料之外的小文件产生。实际公司生产中对于小文件的大小没有一个统一的定义。一般公司集群的blocksize的大小在128/256两者居多。首先小文件大小肯定是要远小于blocksize的文件。一般公司小文件的大小定义如1Mb,8Mb,甚至16Mb,32Mb更大。根据公司实际集群状态定义,因为有些情况合并小文件需要消耗额外的资源。
既然剖析小文件,那么不可避免的要先剖析hdfs的存储原理。众多周知了,HDFS上文件的数据存储分为namenode元数据管理和实际数据文件。hdfs上的数据文件被拆分成块block,这些块block在整个集群中的datanode的本地文件系统上存储和复制,每个块也维护者自己的blockmeta信息。namenode主要维护这些文件的元数据信息,具体namenode的解析参考我的其他博客。
如下一个某个文件的某个block在data上存储的情况。

2.小文件的危害
2.1 小文件对namenod的影响
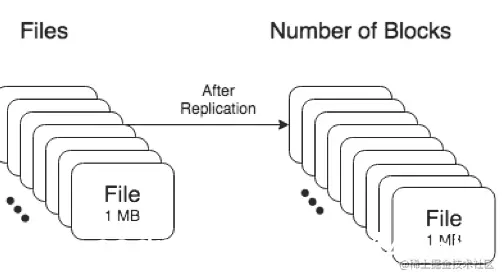
如下图1,一个文件192Mb,默认blocksize=128Mb,副本个数为3,存储为2个block。

如下图2,同样一个文件192Mb,默认blocksize=128Mb,副本个数为3,存储为192个block
namenode的namespace中主要占存储对象是文件的目录个数,文件(文件名长度)以及文件block数。根据namenode实际使用经验来看,一个存储对象大概占用150字节的空间。HDFS上存储文件占用的namenode内存计算公式如下:
Memory=150bytes*(1个文件inode+(文件的块数*副本个数))
如上图1 , 一个文件192Mb,默认blocksize=128Mb,副本个数为3,存储为2个block,需要namenode内存=150*(1+2*3)=1050 Bytes
同理图2, 一个文件192Mb,默认blocksize=128Mb,副本个数为3,存储为192个block,需要namenode内存=150 x (192 + (192 x 3)) = 115200 Bytes
总结
-
从上面可以看出,同样的一个文件,大小不同形态的存储占用namenode的内存之比相差了109倍之多。所以如果对于单namenode的集群来说,大量的小文件的会占用大量的namenode堆内存空间,给集群的存储造成瓶颈。有些人可能会说我们联邦,多组namenode不就没有这个问题了,其实不然,且往下看
-
当 NameNode 重新启动时(虽然生产上这种情况很少),它必须将文件系统元数据fsimage从本地磁盘加载到内存中。这意味着如果 namenode 元数据很大,重启会更慢(以我们公司3亿block,5万多个文件对象来说,重启一次1.5小时,期间应用不可用)其次,datanode 还通过网络向 NameNode 报告块更改;更多的块意味着要通过网络报告更多的变化,等待时间更长。
-
更多的文件,更多的block,意味着更多的读取请求需要由 NameNode 提供服务,这将增加 RPC 队列和处理延迟,进而导致namenode性能和响应能力下降。官方介绍说接近 40K~50K RPCs/s 人为是极高的负载。实际使用来看比这低时对于namenode来说性能都会打很大的折扣。
2.2 小文件对datanode影响
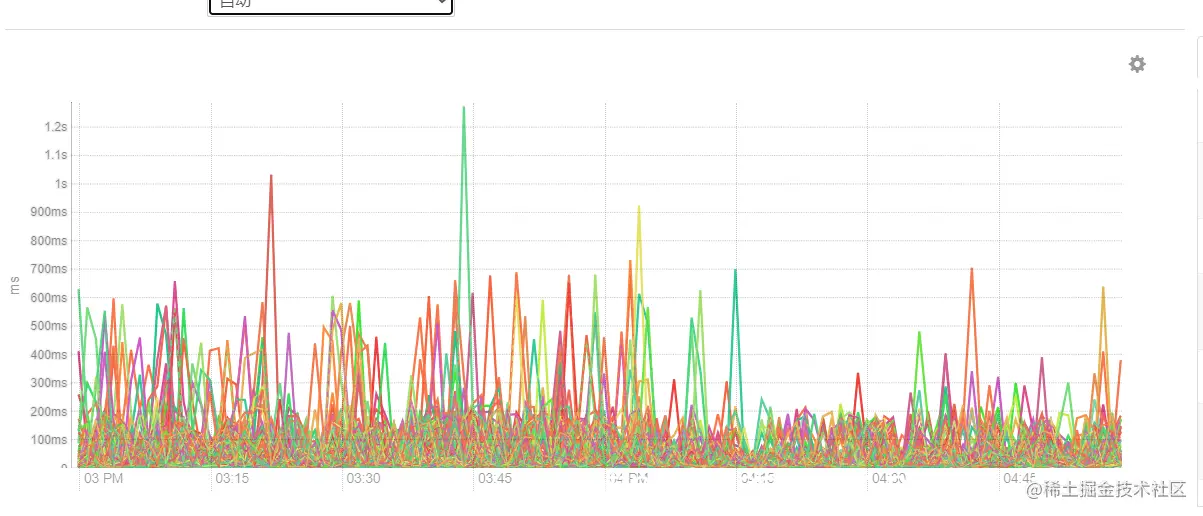
文件的block存储是存储在datanode本地系统上,底层的磁盘上,甚至不同的挂载目录,不同的磁盘上。大量的小文件,意味着数据着寻址需要花费很多时间,尤其对于高负载的集群来说,磁盘使用率50%以上的集群,花费在寻址的时间比文件读取写入的时间更多。这种就违背了blocksize大小设计的初衷(实践显示最佳效果是:寻址时间仅占传输时间的1%)。这样会造成磁盘的读写会很慢,拥有大量小文件会导致更多的磁盘搜索。如下磁盘延迟:
2.3 小文件对计算的影响
基于HDFS文件系统的计算,blokc块是最小粒度的数据处理单元。块的多少往往影响应用程序的吞吐量。更多的文件,意味着更多的块,以及更多的节点分布。
比如以MapReduce任务为例(hive等),在 MapReduce 中,会为每个读取的块生成一个单独的 Map 任务,如果大量小文件,大量的块,意味着着更多任务调度,任务创建开销,以及更多的任务管理开销(MapReduce 作业的 application master 是一个 Java 应用,它的主类是 MRAppMaster。它通过创建一定数量的bookkeeping object跟踪作业进度来初始化作业,该对象接受任务报告的进度和完成情况)。虽然可以开启map前文件合并,但是这也需要不停地从不同节点建立连接,数据读取,网络传输,然后进行合并,同样会增加消耗资源和增加计算时间,成本也很高。
同样,如果是spark计算引擎,executor的一次读取和处理一个分区,默认情况下,每个分区是一个 HDFS 块,如果大量的小文件,每个文件都在不同的分区中读取,这将导致大量的任务调度开销,同时每个 CPU 内核的吞吐量降低。
3. 小文件的产生
-
流式数据,如flume,kafak,sparkstreaming,storm,flink等,流式增量文件,小窗口文件,如几分钟一次等。
-
MapReduce引擎任务:如果纯map任务,大量的map;如果mapreduce任务,大量的reduce;两者都会造成大量的文件。出现这种情况的原因很多,果分布表的过度分区,输入大量的小文件,参数设置的不合理等,输出没有文件合并等。
-
spark任务过度并行化,Spark 分区越多,写入的文件就越多。
-
文件的压缩与存储格式不合理;一般生产公司很少使用textfile这种低效的文件格式了。
使用压缩,降低文件的大小,同时也会降低文件的总块数。注意文件存储格式和压缩不合理只是加剧小文件问题,不是产生小文件的本质。
4. HDFS小文件监控
HDFS的fsimage是HDFS文件系统的一个重要组成部分,记录了HDFS文件系统的元数据信息,包括文件、目录、权限、块等信息。通过监控HDFS的fsimage,可以了解HDFS文件系统的整体情况,包括文件数量、文件大小、文件类型等信息,进而实现对HDFS小文件的监控和治理。
具体来说,可以通过以下步骤对HDFS小文件进行监控:
-
获取HDFS的fsimage:使用Hadoop自带的命令
hdfs oiv -p XML -i fsimage命令获取HDFS的fsimage文件。该命令会将HDFS的fsimage文件以XML格式输出,包括HDFS中所有文件和目录的元数据信息; -
解析fsimage文件:使用Python等脚本语言解析获取到的fsimage文件,提取其中的文件、目录、块等信息。可以使用Python的ElementTree模块等工具对XML文件进行解析,提取需要的信息;
-
统计文件数量和文件大小:根据解析后的文件信息,统计HDFS中小文件的数量和大小。通常可以根据文件大小和文件数量的阈值来定义小文件,例如文件大小小于128MB或文件数量小于1000个等;
-
可视化展示:使用可视化工具,如Grafana、Kibana等将统计结果进行可视化展示,以便于对HDFS小文件的监控和管理。
解析fsimage文件为txt文件
hdfs oiv -i fsimage_0000000192578352133 -o /data2/data/fsimage/$day/fsimage.txt -p Delimited -t /data2/data/fsimage/$day/tmp1.fsimage文件重要的字段释义
INODE_ID:文件或目录的唯一标识符;
NAME:文件或目录的名称;
PARENT_ID:父目录的INODE_ID;
MODIFICATION_TIME:最后修改时间;
ACCESS_TIME:最后访问时间;
BLOCK_IDS:文件的数据块ID列表;
BLOCK_SIZE:数据块大小;
NUM_BLOCKS:数据块数量;
PERMISSIONS:文件或目录的权限信息;
USER_NAME:文件或目录所属用户;
GROUP_NAME:文件或目录所属用户组;
SYMLINK:如果是符号链接,则包含符号链接的目标路径;
UNDER_CONSTRUCTION:如果文件正在写入中,则为true;
UNDER_RECOVERY:如果文件正在恢复中,则为true;
FILE_LENGTH:文件长度;
NS_QUOTA:命名空间配额;
DS_QUOTA:磁盘配额;
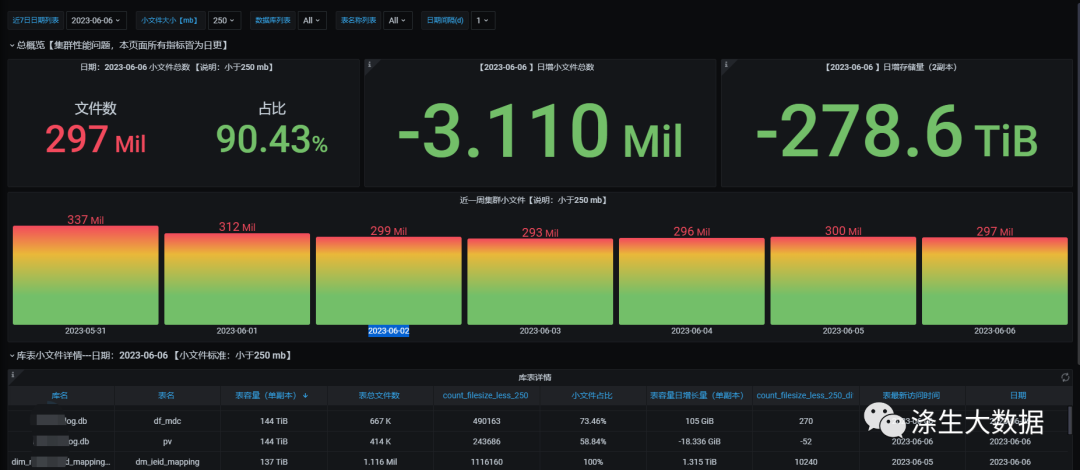
STORAGE_POLICY:存储策略。通过编写脚本采集相关指标,并存入相关数据库,能够进行绘制可观测图,便于监控小文件的状态,便于后续进行小文件治理
5. HDFS小文件的治理方法
针对HDFS小文件的问题,有以下几种治理方法:
-
合并小文件:将多个小文件合并为一个大文件,减少文件数量。这种方法需要注意文件的内容和格式,以免合并后的文件无法使用或者存在数据丢失等问题;
-
压缩文件:将多个小文件压缩为一个压缩包,减少存储空间。这种方法可以使用Hadoop自带的压缩工具,如gzip、bzip2等;
-
删除无用文件:删除不再需要的小文件,释放存储空间;
-
设置文件过期时间:对于不再需要的文件,可以设置其过期时间,自动删除过期文件;
-
使用SequenceFile:使用Hadoop自带的SequenceFile格式存储小文件,将多个小文件合并到一个SequenceFile中,以减少文件数量,提高处理效率。
通常可以通过应用层,进行合并小文件、删除过期无用文件、转移小文件到其他存储媒介等方式,减少和治理hdfs中的小文件,以提升hdfs集群的稳定性。
针对如上办法进行治理方法如下
-
合并小文件:对于日志文件等大量的小文件,可以使用Hadoop自带的合并工具将多个小文件合并为一个大文件。下面是通过hive的重写方式合并小文件,核心参数如下;
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
set hive.merge.mapfiles = true;
set hive.merge.mapredfiles = true;
set hive.merge.smallfiles.avgsize=256000000;
set hive.merge.size.per.task=12800000;
set mapred.max.split.size=256000000;
set mapred.min.split.size=64000000;
set mapred.min.split.size.per.node=64000000;
set mapred.min.split.size.per.rack=64000000;1.2.3.4.5.6.7.8.9.-
压缩文件:对于大量的小文件,可以使用压缩工具将多个小文件压缩为一个压缩包,以减少存储空间。例如,使用gzip或bzip2压缩工具压缩文件,在HDFS上存储压缩文件,以减少存储空间和文件数量;
-
删除无用文件:对于不再需要的小文件,可以使用Hadoop自带的命令hadoop fs -rm命令删除文件,或者使用定时任务脚本定期删除过期文件;
-
设置文件过期时间:使用hadoop fs -touchz命令设置文件的过期时间,当文件过期后,自动删除文件。例如,使用hadoop fs -touchz命令设置文件的过期时间为30天,当文件超过30天未被访问时,自动删除文件;
-
使用SequenceFile:对于大量的小文件,可以使用SequenceFile格式存储文件,将多个小文件合并成一个SequenceFile文件。例如,使用Hadoop自带的SequenceFile.Writer类将多个小文件写入SequenceFile文件中,以减少存储空间和文件数量。
6. 疑问和思考
暂无
7. 参考文档
暂无