目录
数据收集
设置
定义超参数
数据准备
构建基于变换器的模型
培训的效用函数
模型训练和推理
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
本文目标:用混合变压器训练视频分类器。
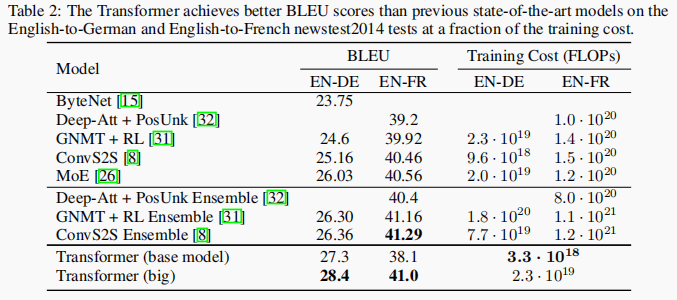
本示例是使用 CNN-RNN 架构(卷积神经网络-循环神经网络)进行视频分类示例的后续。这一次,我们将使用基于变换器的模型(Vaswani 等人)对视频进行分类。阅读本示例后,您将了解如何开发基于变换器的混合模型,用于在 CNN 特征图上运行的视频分类。
数据收集
与本例的前身一样,我们将使用 UCF101 数据集的子样本,这是一个著名的基准数据集。如果您想对更大的子样本甚至整个数据集进行操作,请参考下面这个Notebook。
!wget -q https://github.com/sayakpaul/Action-Recognition-in-TensorFlow/releases/download/v1.0.0/ucf101_top5.tar.gz
!tar -xf ucf101_top5.tar.gz设置
import os
import keras
from keras import layers
from keras.applications.densenet import DenseNet121
from tensorflow_docs.vis import embed
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import imageio
import cv2定义超参数
MAX_SEQ_LENGTH = 20
NUM_FEATURES = 1024
IMG_SIZE = 128
EPOCHS = 5数据准备
在本例中,除了以下改动外,我们将主要沿用相同的数据准备步骤:
我们将图像大小从 224x224 缩小到 128x128,以加快计算速度。
我们不再使用预先训练好的 InceptionV3 网络,而是使用预先训练好的 DenseNet121 进行特征提取。
我们直接将较短的视频填充到 MAX_SEQ_LENGTH 长度。
首先,让我们加载 DataFrames。
train_df = pd.read_csv("train.csv")
test_df = pd.read_csv("test.csv")
print(f"Total videos for training: {len(train_df)}")
print(f"Total videos for testing: {len(test_df)}")
center_crop_layer = layers.CenterCrop(IMG_SIZE, IMG_SIZE)
def crop_center(frame):
cropped = center_crop_layer(frame[None, ...])
cropped = keras.ops.convert_to_numpy(cropped)
cropped = keras.ops.squeeze(cropped)
return cropped
# Following method is modified from this tutorial:
# https://www.tensorflow.org/hub/tutorials/action_recognition_with_tf_hub
def load_video(path, max_frames=0, offload_to_cpu=False):
cap = cv2.VideoCapture(path)
frames = []
try:
while True:
ret, frame = cap.read()
if not ret:
break
frame = frame[:, :, [2, 1, 0]]
frame = crop_center(frame)
if offload_to_cpu and keras.backend.backend() == "torch":
frame = frame.to("cpu")
frames.append(frame)
if len(frames) == max_frames:
break
finally:
cap.release()
if offload_to_cpu and keras.backend.backend() == "torch":
return np.array([frame.to("cpu").numpy() for frame in frames])
return np.array(frames)
def build_feature_extractor():
feature_extractor = DenseNet121(
weights="imagenet",
include_top=False,
pooling="avg",
input_shape=(IMG_SIZE, IMG_SIZE, 3),
)
preprocess_input = keras.applications.densenet.preprocess_input
inputs = keras.Input((IMG_SIZE, IMG_SIZE, 3))
preprocessed = preprocess_input(inputs)
outputs = feature_extractor(preprocessed)
return keras.Model(inputs, outputs, name="feature_extractor")
feature_extractor = build_feature_extractor()
# Label preprocessing with StringLookup.
label_processor = keras.layers.StringLookup(
num_oov_indices=0, vocabulary=np.unique(train_df["tag"]), mask_token=None
)
print(label_processor.get_vocabulary())
def prepare_all_videos(df, root_dir):
num_samples = len(df)
video_paths = df["video_name"].values.tolist()
labels = df["tag"].values
labels = label_processor(labels[..., None]).numpy()
# `frame_features` are what we will feed to our sequence model.
frame_features = np.zeros(
shape=(num_samples, MAX_SEQ_LENGTH, NUM_FEATURES), dtype="float32"
)
# For each video.
for idx, path in enumerate(video_paths):
# Gather all its frames and add a batch dimension.
frames = load_video(os.path.join(root_dir, path))
# Pad shorter videos.
if len(frames) < MAX_SEQ_LENGTH:
diff = MAX_SEQ_LENGTH - len(frames)
padding = np.zeros((diff, IMG_SIZE, IMG_SIZE, 3))
frames = np.concatenate(frames, padding)
frames = frames[None, ...]
# Initialize placeholder to store the features of the current video.
temp_frame_features = np.zeros(
shape=(1, MAX_SEQ_LENGTH, NUM_FEATURES), dtype="float32"
)
# Extract features from the frames of the current video.
for i, batch in enumerate(frames):
video_length = batch.shape[0]
length = min(MAX_SEQ_LENGTH, video_length)
for j in range(length):
if np.mean(batch[j, :]) > 0.0:
temp_frame_features[i, j, :] = feature_extractor.predict(
batch[None, j, :]
)
else:
temp_frame_features[i, j, :] = 0.0
frame_features[idx,] = temp_frame_features.squeeze()
return frame_features, labelsTotal videos for training: 594
Total videos for testing: 224
['CricketShot', 'PlayingCello', 'Punch', 'ShavingBeard', 'TennisSwing']
在 train_df 和 test_df 上调用 prepare_all_videos() 需要约 20 分钟才能完成。因此,为了节省时间,我们在这里下载已经预处理过的 NumPy 数组:
!!wget -q https://git.io/JZmf4 -O top5_data_prepared.tar.gz
!!tar -xf top5_data_prepared.tar.gztrain_data, train_labels = np.load("train_data.npy"), np.load("train_labels.npy")
test_data, test_labels = np.load("test_data.npy"), np.load("test_labels.npy")
print(f"Frame features in train set: {train_data.shape}")[]
Frame features in train set: (594, 20, 1024)构建基于变换器的模型
我们将在弗朗索瓦-乔莱(François Chollet)所著《深度学习与 Python》(第二版)一书这一章中分享的代码基础上构建模型。
首先,构成 Transformer 基本模块的自我注意层是不分顺序的。
由于视频是有序的帧序列,我们需要我们的变换器模型考虑到顺序信息。我们通过位置编码来实现这一点。我们只需用嵌入层嵌入视频中帧的位置。然后,我们将这些位置嵌入添加到预先计算的 CNN 特征图中。
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, output_dim, **kwargs):
super().__init__(**kwargs)
self.position_embeddings = layers.Embedding(
input_dim=sequence_length, output_dim=output_dim
)
self.sequence_length = sequence_length
self.output_dim = output_dim
def build(self, input_shape):
self.position_embeddings.build(input_shape)
def call(self, inputs):
# The inputs are of shape: `(batch_size, frames, num_features)`
inputs = keras.ops.cast(inputs, self.compute_dtype)
length = keras.ops.shape(inputs)[1]
positions = keras.ops.arange(start=0, stop=length, step=1)
embedded_positions = self.position_embeddings(positions)
return inputs + embedded_positions现在,我们可以为变换器创建一个子类层。
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim, dropout=0.3
)
self.dense_proj = keras.Sequential(
[
layers.Dense(dense_dim, activation=keras.activations.gelu),
layers.Dense(embed_dim),
]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs, mask=None):
attention_output = self.attention(inputs, inputs, attention_mask=mask)
proj_input = self.layernorm_1(inputs + attention_output)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)培训的效用函数
def get_compiled_model(shape):
sequence_length = MAX_SEQ_LENGTH
embed_dim = NUM_FEATURES
dense_dim = 4
num_heads = 1
classes = len(label_processor.get_vocabulary())
inputs = keras.Input(shape=shape)
x = PositionalEmbedding(
sequence_length, embed_dim, name="frame_position_embedding"
)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads, name="transformer_layer")(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(classes, activation="softmax")(x)
model = keras.Model(inputs, outputs)
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
return model
def run_experiment():
filepath = "/tmp/video_classifier.weights.h5"
checkpoint = keras.callbacks.ModelCheckpoint(
filepath, save_weights_only=True, save_best_only=True, verbose=1
)
model = get_compiled_model(train_data.shape[1:])
history = model.fit(
train_data,
train_labels,
validation_split=0.15,
epochs=EPOCHS,
callbacks=[checkpoint],
)
model.load_weights(filepath)
_, accuracy = model.evaluate(test_data, test_labels)
print(f"Test accuracy: {round(accuracy * 100, 2)}%")
return model模型训练和推理
trained_model = run_experiment()Epoch 1/5
16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 160ms/step - accuracy: 0.5286 - loss: 2.6762
Epoch 1: val_loss improved from inf to 7.75026, saving model to /tmp/video_classifier.weights.h5
16/16 ━━━━━━━━━━━━━━━━━━━━ 7s 272ms/step - accuracy: 0.5387 - loss: 2.6139 - val_accuracy: 0.0000e+00 - val_loss: 7.7503
Epoch 2/5
15/16 ━━━━━━━━━━━━━━━━━━[37m━━ 0s 4ms/step - accuracy: 0.9396 - loss: 0.2264
Epoch 2: val_loss improved from 7.75026 to 1.96635, saving model to /tmp/video_classifier.weights.h5
16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 20ms/step - accuracy: 0.9406 - loss: 0.2186 - val_accuracy: 0.4000 - val_loss: 1.9664
Epoch 3/5
14/16 ━━━━━━━━━━━━━━━━━[37m━━━ 0s 4ms/step - accuracy: 0.9823 - loss: 0.0384
Epoch 3: val_loss did not improve from 1.96635
16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step - accuracy: 0.9822 - loss: 0.0391 - val_accuracy: 0.3667 - val_loss: 3.7076
Epoch 4/5
15/16 ━━━━━━━━━━━━━━━━━━[37m━━ 0s 4ms/step - accuracy: 0.9825 - loss: 0.0681
Epoch 4: val_loss did not improve from 1.96635
16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step - accuracy: 0.9831 - loss: 0.0674 - val_accuracy: 0.4222 - val_loss: 3.7957
Epoch 5/5
15/16 ━━━━━━━━━━━━━━━━━━[37m━━ 0s 4ms/step - accuracy: 1.0000 - loss: 0.0035
Epoch 5: val_loss improved from 1.96635 to 1.56071, saving model to /tmp/video_classifier.weights.h5
16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - accuracy: 1.0000 - loss: 0.0033 - val_accuracy: 0.6333 - val_loss: 1.5607
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9286 - loss: 0.4434
Test accuracy: 89.29%注:该模型有 ~423 万个参数,远远多于我们在本例前传中所使用的序列模型(99918 个参数)。这种 Transformer 模型最好使用更大的数据集和更长的预训练时间。
def prepare_single_video(frames):
frame_features = np.zeros(shape=(1, MAX_SEQ_LENGTH, NUM_FEATURES), dtype="float32")
# Pad shorter videos.
if len(frames) < MAX_SEQ_LENGTH:
diff = MAX_SEQ_LENGTH - len(frames)
padding = np.zeros((diff, IMG_SIZE, IMG_SIZE, 3))
frames = np.concatenate(frames, padding)
frames = frames[None, ...]
# Extract features from the frames of the current video.
for i, batch in enumerate(frames):
video_length = batch.shape[0]
length = min(MAX_SEQ_LENGTH, video_length)
for j in range(length):
if np.mean(batch[j, :]) > 0.0:
frame_features[i, j, :] = feature_extractor.predict(batch[None, j, :])
else:
frame_features[i, j, :] = 0.0
return frame_features
def predict_action(path):
class_vocab = label_processor.get_vocabulary()
frames = load_video(os.path.join("test", path), offload_to_cpu=True)
frame_features = prepare_single_video(frames)
probabilities = trained_model.predict(frame_features)[0]
plot_x_axis, plot_y_axis = [], []
for i in np.argsort(probabilities)[::-1]:
plot_x_axis.append(class_vocab[i])
plot_y_axis.append(probabilities[i])
print(f" {class_vocab[i]}: {probabilities[i] * 100:5.2f}%")
plt.bar(plot_x_axis, plot_y_axis, label=plot_x_axis)
plt.xlabel("class_label")
plt.xlabel("Probability")
plt.show()
return frames
# This utility is for visualization.
# Referenced from:
# https://www.tensorflow.org/hub/tutorials/action_recognition_with_tf_hub
def to_gif(images):
converted_images = images.astype(np.uint8)
imageio.mimsave("animation.gif", converted_images, fps=10)
return embed.embed_file("animation.gif")
test_video = np.random.choice(test_df["video_name"].values.tolist())
print(f"Test video path: {test_video}")
test_frames = predict_action(test_video)
to_gif(test_frames[:MAX_SEQ_LENGTH])Test video path: v_ShavingBeard_g03_c02.avi
1/1 ━━━━━━━━━━━━━━━━━━━━ 20s 20s/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 10ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 557ms/step
ShavingBeard: 100.00%
Punch: 0.00%
CricketShot: 0.00%
TennisSwing: 0.00%
PlayingCello: 0.00%
我们的模型性能远未达到最佳,因为它是在一个小数据集上训练出来的。