redisObject
Redis 中的数据对象 server/redisObject.h 是 Redis 对内部存储的数据定义的抽象类型其定义如下:
typedef struct redisObject {
unsigned type:4; // 数据类型,字符串,哈希表,列表等等
unsigned encoding:4; // 数据类型的编码方式,字符串有 EMBSTR RAW INT 啥的
unsigned lru:LRU_BITS; // LRU 时间戳 或 LFU 计数
int refcount; // 引用计数,与 redisObject 的释放密切相关
void *ptr; // 指向实际的数据结构,如 sds,真正的数据结构存储在该数据结构中
} robj;
sds
我们知道,C 语言中将空字符结尾的字符数组作为字符串,而 Redis 对此做了扩展, 定义了字符串类型 sds (Simple Dynamic String)。、
Redis 中的键都是字符串类型, Redis 中最简单的值类型也是字符串类型。
定义
对于不同的字符串,Redis 定义了不同的 sds 结构体。
Redis 定义不同的 sdshdr 结构体是为了针对不同长度的字符串,使用适合 len alloc 属性类型,最大限度地节省内存。
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
__attribute__ ((__packed__))在gcc下,表示不使用结构体的内存对齐规则。len:已使用字节长度,即字符串长度。sdshdr5可存放的字符串长度小于 32 ( 2 5 2^5 25),sdshdr8可存放的字符串长度小于 256 ( 2 8 2^8 28), 以此类推。由于该属性记录了字符串长度, 所以sds可以在常数时间内获取字符串长度。Redis限制了字符串的最大长度不能超过 512MBalloc:已申请字节长度,即sds总长度。alloc-len为sds中的可用(空闲)空间。flag:低 3 位代表sdshdr的类型,高 5 位只在sdshdr5中使用,表示字符串的长度,所以sdshdr5中没有len属性。 另外,由于Redis对sdshdr5的定义是常量字符串,不支持扩容,所以不存在alloc属性。buf:字符串内容,sds遵循 C 语言字符串的规范,保存一个空字符串作为buf的结尾,并且不计入lenalloc属性。这样可以直接使用 C 语言strcmpstrcpy等函数直接操作sds。
sdsnew
调用 sdsnewlen 根据 init 字符串来创建 sds。可以先看看 sdsnewlen 函数哈!在 目录 里面找找哈!
跳转到 sdsnewlen
sds sdsnew(const char *init) {
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}
sdsempty
创建一个没有数据的 sds。
sds sdsempty(void) {
return sdsnewlen("",0);
}
sdsfree
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1])); // 找到 sdsdhr 结构体的首地址,释放内存!因为柔性数组会随着结构体的释放而被释放嘛!
}
sdsHdrSize
根据传入的 type 获取 sdshdr 结构体的大小并返回。
static inline int sdsHdrSize(char type) {
switch(type&SDS_TYPE_MASK) { // SDS_TYPE_MASK 就是 00000111 即 flags&SDS_TYPE_MASK 就是取flags 的低三位,低三位存储的是结构体的类型嘛!
case SDS_TYPE_5:
return sizeof(struct sdshdr5);
case SDS_TYPE_8:
return sizeof(struct sdshdr8);
case SDS_TYPE_16:
return sizeof(struct sdshdr16);
case SDS_TYPE_32:
return sizeof(struct sdshdr32);
case SDS_TYPE_64:
return sizeof(struct sdshdr64);
}
return 0;
}
sdsclear
这个函数用来清除 sds 存储的数据哈!
void sdsclear(sds s) {
sdssetlen(s, 0); // 修改 s 对应数组的结构体的 len 属性,修改为 0
s[0] = '\0'; // 清除数据
}
sdsRemoveFreeSpace
这个函数用于去除 sds 的空闲空间。即,我们想让实际的字符串长度 + 1 就是柔性数组的大小!(有个 ‘\0’),所以是加 1。
sds sdsRemoveFreeSpace(sds s) {
void *sh, *newsh;
char type, oldtype = s[-1] & SDS_TYPE_MASK; // 新的 sdshdr 类型和原 sdshdr 类型
int hdrlen;
size_t len = sdslen(s); // 获取存储字符串的长度
sh = (char*)s-sdsHdrSize(oldtype); // 根据柔性数组找到他的结构体的首地址
type = sdsReqType(len); // 当前存储字符串的长度需要的最小 sdshdr 类型
hdrlen = sdsHdrSize(type); // 该类型结构体的大小
if (oldtype==type) { // 如果两者类型相等
newsh = s_realloc(sh, hdrlen+len+1); // realloc 即可,可以看到 realloc 是可以缩容的
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
newsh = s_malloc(hdrlen+len+1); // 如果类型不匹配,就需要 malloc 了
if (newsh == NULL) return NULL; // 扩容失败
memcpy((char*)newsh+hdrlen, s, len+1); // 拷贝数据
s_free(sh); // 释放原来的空间
s = (char*)newsh+hdrlen; // 准备返回值
s[-1] = type; // 给 flag 字段赋值
sdssetlen(s, len); // 给 len 字段赋值
}
sdssetalloc(s, len); // 修改 alloc 字段
return s; // 返回新的 sds
}
sdsavail
sdsavail 函数是用来获取一个 SDS(简单动态字符串,Simple Dynamic String)字符串的未使用(剩余)空间的大小的。
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1]; // s[-1] 就是获取到 sdshdr 结构体中的 flsgs 字段嘛
switch(flags&SDS_TYPE_MASK) { // SDS_TYPE_MASK 就是 00000111 嘛,flags 的低三位用来存储 sdshdr 的类型的嘛
case SDS_TYPE_5: {
return 0; // sdshdr5 没有 alloc 字段,不支持动态扩容的
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s); // 这个宏就是通过 s 找到 sdshdr 结构体的首地址,将首地址赋值给 sh 变量
return sh->alloc - sh->len; // 返回空闲的空间(剩余的空间)
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}
SDS_HDR_VAR
这个 ## 就是简单的拼接哈!
可以看到这个宏就是通过 s 找到 sdshdr 结构体的首地址,并且赋值给 sh 变量哈!方便后续访问 sdshdr 结构体的成员哈!
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
sdslen
这个函数用来获取一个 sds 存储的字符串的长度!不可以对 s 直接使用 strlen 因为字符串中可能保存的是二进制的数据,可能会提前遇到 \0 导致长度计算错误!
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1]; // 通过 s 找到结构体中的 flag 字段
switch(flags&SDS_TYPE_MASK) { // SDS_TYPE_MASK 就是 00000111 即 flags&SDS_TYPE_MASK 就是取flags 的低三位,低三位存储的是结构体的类型嘛!
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags); // 这个宏就是将 flags 的高 5 位取出来,即得到字符串长度
case SDS_TYPE_8:
return SDS_HDR(8,s)->len; // 这个宏就是通过 s - sizeof(sdshdr) 找到结构体的首地址,然后进行一个强制类型转换,就可以访问结构体的成员啦
case SDS_TYPE_16:
return SDS_HDR(16,s)->len; // 这下面几个和上面的这个是一样的
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
// #define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
// 我们观察 SDS_HDR 这个宏,可以看到就是将参数 T 拼接到了 struct sdshdr 这个字符串的后面
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
sdsdup
可以理解为 C++ 的拷贝构造函数!深拷贝嘛!
sds sdsdup(const sds s) {
return sdsnewlen(s, sdslen(s));
}
sdscat
这个函数可以在一个 sds 后面拼接上一个字符串!仅限字符串,因为用的是 strlen 嘛!
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s); // 获取 s 当前存储字符串的长度
s = sdsMakeRoomFor(s,len); // 扩容逻辑,使得结构体能存下 sdslen(s) + len 这么长的字符串
if (s == NULL) return NULL; // 扩容失败
memcpy(s+curlen, t, len); // 拷贝数据,将 t 拼接到 s 的末尾
sdssetlen(s, curlen+len); // 修改 len 字段
s[curlen+len] = '\0'; // 添加 '\0'
return s; // 返回新的 s
}
sdscmp
比较两个 sds 存储的字符串的大小!下面的 memcmp 不能换成 strcmp,因为 sds 里面存储的可能是二进制的数据,不一定是字符串。
// 返回值就跟 memcmp 一样的哈,相等返回 0,s1 < s2 返回一个负数,s1 > s2 返回一个正数
int sdscmp(const sds s1, const sds s2) {
size_t l1, l2, minlen;
int cmp;
l1 = sdslen(s1);
l2 = sdslen(s2);
minlen = (l1 < l2) ? l1 : l2;
cmp = memcmp(s1,s2,minlen); // memcmp 的第三个参数表示要比较的字节数
if (cmp == 0) return l1-l2;
return cmp;
}
sdsrange
将 sds 中存储的字符串修改为,[start, end] 这个子串。
void sdsrange(sds s, int start, int end) {
size_t newlen, len = sdslen(s); // len: s 中存储数据的字节数
if (len == 0) return; // 如果源 sds 中没有存储数据结束函数调用
// 下面的很长一段代码都是对 start 和 end 的修正哈
if (start < 0) { // 根据这个 start 和 end 的判断来看,是支持负的 start 和 end 呢!类似于负的下标吧
start = len+start;
if (start < 0) start = 0;
}
if (end < 0) {
end = len+end;
if (end < 0) end = 0;
}
// 子串的长度,要求 start <= end
newlen = (start > end) ? 0 : (end-start)+1;
// 修正 newlen
if (newlen != 0) {
if (start >= (signed)len) {
newlen = 0;
} else if (end >= (signed)len) {
end = len-1;
newlen = (start > end) ? 0 : (end-start)+1;
}
} else {
start = 0;
}
// 只有当 start != 0 并且 newlen != 0 的时候才需要挪动数据
// 可以使用 memcpy 吗?这个问题不好说哈,因为在发现 memcpy 的问题之后,memcpy 的底层实现应该就是修改成了 memmove 了吧!
if (start && newlen) memmove(s, s+start, newlen);
s[newlen] = 0; // 在字符串的末尾提那集 '\0'
// 修改 sds 的 len 属性
sdssetlen(s,newlen);
}
sdsnewlen
这个是 sds 的构建函数哈!
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen); // 根据 initlen 获取存储 initlen 至少需要那个结构体
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8; //长度为 0 的字符串后续通常都需要家进行扩容,因此不应该使用不能扩容的 SDS_TYPE_5
int hdrlen = sdsHdrSize(type); // 根据结构体的类型获取结构体的大小
unsigned char *fp;
sh = s_malloc(hdrlen+initlen+1); // #define s_malloc malloc 哈!开辟 sdshdr 结构体 + buf + '\0' 的空间
if (sh == NULL) return NULL; // 空间开辟失败
if (!init) // 如果 init 没有指定初始化的字符串
memset(sh, 0, hdrlen+initlen+1); // 初始化为 '\0'
s = (char*)sh+hdrlen; // 让 s 指向 buf 柔性数组的首地址
fp = ((unsigned char*)s)-1; // 找到 sdshdr 结构体中的 flags 字段,赋值给 fp,方便后续初始化 flags 字段
switch(type) { // 根据 type 进行 sdshdr 结构体的初始化
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS); // 低三位存储 type,高 5 位存储字符串长度,SDS_TYPE_BITS 就是 3 哈!
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s); // 这个宏就是通过 s 找到 sdshdr 结构体的首地址,将首地址赋值给 sh 变量, SDS_HDR_VAR 这个宏讲过啦
sh->len = initlen; // 初始化 sdshdr 结构体的 len 字段
sh->alloc = initlen; // 初始化 sdshdr 结构体的 alloc字段
*fp = type; // 初始化 sdshdr 结构体的 flags 字段
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init) // 如果 init 指向了一个字符串 并且 initlen 不为 0
memcpy(s, init, initlen); // 将 init 字符串中的 initlen 个字符拷贝到 s 中去
s[initlen] = '\0'; // 附上一个 '\0'
return s; // 返回构建好的 s
}
sdsReqType
这个函数的实现直接根据 string_size 来判断就行,因为不同的结构体他能存储的最大长度是固定的嘛!从小到大判断哦!
static inline char sdsReqType(size_t string_size) {
if (string_size < 32) // 2^5 -> sdshdr5
return SDS_TYPE_5;
if (string_size < 0xff) // 2^8 -> sdshdr8
return SDS_TYPE_8;
if (string_size < 0xffff) // 2^16 -> sdshdr16
return SDS_TYPE_16;
if (string_size < 0xffffffff) // 2^32 -> sdshdr32
return SDS_TYPE_32;
return SDS_TYPE_64;
}
sdsMakeRoomFor
这个函数实现的是 sds 的扩容逻辑!
- 参数 1:原
sds。 - 参数 2:在
len的基础上增加多少空间。就有点C++中的resize函数的感觉吧!
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s); // 获取剩余空间,alloc-len 这个函数讲过了哦!
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK; // 扩容之前的类型是 oldtype
int hdrlen;
if (avail >= addlen) return s; // 如果剩余的空间足够,直接返回
len = sdslen(s); // 当前 sds 存储的字符串的长度
sh = (char*)s-sdsHdrSize(oldtype); // 找到 sdshdr 结构体的起始地址,并赋值给 sh
newlen = (len+addlen); // 新的 len ,走到这里已经确定需要对 buf 柔性数组进行扩容啦
if (newlen < SDS_MAX_PREALLOC) // #define SDS_MAX_PREALLOC (1024*1024) ,如果新的 len 小于 1MB 那么二倍扩容
newlen *= 2;
else // 如果新的 len 大于等于 1MB 那么每次增加 1MB
newlen += SDS_MAX_PREALLOC;
// 为什么不刚刚好扩容到 len + addlen 呢?这样做主要是为了避免频繁地进行小规模的内存扩容,因为频繁的小扩容会导致内存碎片问题和频繁的内存分配与释放,影响性能。
type = sdsReqType(newlen); // newlen 需要的最小的 sdshdr 类型,这个函数我们也讲过哈!
if (type == SDS_TYPE_5) type = SDS_TYPE_8; // SDS_TYPE_5 这种类型的结构体没有 alloc 字段,不能进行扩容,需要转换成能扩容的类型哈
hdrlen = sdsHdrSize(type); // type 类型对应的结构体的大小 这个函数我们也是讲过了的哈
if (oldtype==type) { // 如果 newlen 对应的结构体类型和原类型对应的结构体相同
newsh = s_realloc(sh, hdrlen+newlen+1); // 进行 realloc 即可 #define s_realloc realloc
if (newsh == NULL) { // realloc 失败啦
s_free(sh); // free 掉原来的 sdshdr 结构体 因为 relloc 失败了的话,原来的空间还是存在的
return NULL;
}
s = (char*)newsh+hdrlen; // 让 s 指向新的 buf 柔性数组的首地址 (这个新不一定新哈,因为 realloc 有两种情况嘛!)
} else { // 如果 newlen 对应的结构体类型和原类型对应的结构体不相同
newsh = s_malloc(hdrlen+newlen+1); // 开辟空间:sdshdr 结构体 + newlen + '\0'
if (newsh == NULL) return NULL; // 空间开辟失败
memcpy((char*)newsh+hdrlen, s, len+1); // 拷贝数据,拷贝了 '\0' 哦
s_free(sh); // 释放原来的 sdshdr 空间
s = (char*)newsh+hdrlen; // 让 s 指向新的 buf 柔性数组的首地址,这个新就是真的新啦!
s[-1] = type; // 初始化 sdshdr 结构体的 flags 字段
sdssetlen(s, len); // 修改 sdshdr 结构体的 len 字段
}
sdssetalloc(s, newlen); // 修改 sdshdr 结构体的 alloc 字段
return s;
}
sdssetlen
根据 sds 找到对应的 sdshdr 结构体,然后设置 len 字段为传入的参数 newlen。
static inline void sdssetlen(sds s, size_t newlen) {
unsigned char flags = s[-1]; // 找到 flags 确定 sdshdr 结构体的类型
switch(flags&SDS_TYPE_MASK) { // SDS_TYPE_MASK 就是 00000111 即 flags&SDS_TYPE_MASK 就是取flags 的低三位,低三位存储的是结构体的类型嘛!
case SDS_TYPE_5:
{
unsigned char *fp = ((unsigned char*)s)-1; // 找到 flags 赋值给 fp
*fp = (unsigned char)(SDS_TYPE_5 | (newlen << SDS_TYPE_BITS)); // 高 5 位存储的是大小,低 3 位存类型
}
break;
case SDS_TYPE_8:
SDS_HDR(8,s)->len = (uint8_t)newlen; // 通过 s 找到 sdshdr 结构体首地址,然后访问成员 len 进行赋值
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->len = (uint16_t)newlen;
break;
case SDS_TYPE_32:
SDS_HDR(32,s)->len = (uint32_t)newlen;
break;
case SDS_TYPE_64:
SDS_HDR(64,s)->len = (uint64_t)newlen;
break;
}
}
SDS_HDR
这个宏和 SDS_HDR_VAR 还有点区别的哈,有没有定义变量来存储转换为结构体首地址的结果!
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
sdssetalloc
根据 sds 找到对应的 sdshdr 结构体,然后设置 alloc 字段为传入的参数 newlen。
static inline void sdssetalloc(sds s, size_t newlen) {
unsigned char flags = s[-1]; // 找到 flags 确定 sdshdr 结构体的类型
switch(flags&SDS_TYPE_MASK) { // SDS_TYPE_MASK 就是 00000111 即 flags&SDS_TYPE_MASK 就是取flags 的低三位,低三位存储的是结构体的类型嘛!
case SDS_TYPE_5:
// 这个类型没有 alloc 字段
break;
case SDS_TYPE_8:
SDS_HDR(8,s)->alloc = (uint8_t)newlen; // 通过 s 找到 sdshdr 结构体首地址,然后访问成员 进行赋值
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->alloc = (uint16_t)newlen;
break;
case SDS_TYPE_32:
SDS_HDR(32,s)->alloc = (uint32_t)newlen;
break;
case SDS_TYPE_64:
SDS_HDR(64,s)->alloc = (uint64_t)newlen;
break;
}
}
createStringObject
在 Redis 源码中,lru 字段是 robj 结构体中的一个成员,用于实现对象的最近最少使用(LRU)策略或者最少频繁使用(LFU)策略。具体来说,它用于存储对象的 LRU 时间戳或者 LFU 计数,取决于 Redis 配置中所选择的是哪种淘汰策略。指定在达到最大内存限制时 Redis 服务器应该采取的数据淘汰策略。
- LRU(Least Recently Used)策略:当启用 LRU 策略时,lru 字段存储的是对象最近一次被访问的时间戳。Redis 使用 LRU 策略来淘汰长时间未被访问的对象,以释放内存空间。
- LFU(Least Frequently Used)策略:当启用 LFU 策略时,lru 字段则存储的是对象的 LFU 计数值。LFU 策略会根据对象被访问的频率来判断对象的热度,并淘汰使用频率较低的对象
// redis-6.0.9 object.c
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
跳转到 createEmbeddedStringObject
跳转到 createRawStringObject
createEmbeddedStringObject
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1); // 因为是 embstr 嘛,sdshdr8 就已经足够了! robj 就是 redisObject 哈,zmalloc 就是开辟空间,开辟了 redisObject,sdshdr8,sds,'\0' 的空间,我们查看 zmalloc 函数可以看到在 redisObject 的前面还开辟了 sizeof(size_t) 的空间用来存放整个 EMBSTR 的大小,返回值是 redisObject 的起始地址。。在 zmalloc 函数内部,会对一个全局变量 used_memory 进行修改,值为整个 used_memory += malloc 的空间大小, used_memory 记录了 Redis 服务器在运行过程中使用的内存大小。这包括数据结构、缓存、连接等所有组成部分占用的内存。通过监控 used_memory 的变化,可以及时发现内存占用异常或者内存泄漏的问题,帮助开发者优化 Redis 的内存使用情况,提升系统的稳定性和性能。
struct sdshdr8 *sh = (void*)(o+1); // 拿到 sdshdr8 结构体的首地址
o->type = OBJ_STRING; // 给 redisObject.type 赋值
o->encoding = OBJ_ENCODING_EMBSTR; // 给 redisObject.encoding 赋值
o->ptr = sh+1; // 给 redisObject.ptr 赋值,这里指向的就是 sds,也就是那个柔性数组的首地址
o->refcount = 1; // 给 redisObject.refcount 赋值
// 给 sdshdr8.lru 赋值
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { // 如果达到内存限制了采用 LFU 淘汰策略 这个宏就是淘汰类型的宏定义哈
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL; // 将得到的分钟时间戳左移 8 位,低 8 位放入 LFU 计数的初始值
} else {
o->lru = LRU_CLOCK(); // LRU 淘汰策略,初始化 lru 字段为最近访问的时间
}
sh->len = len; // 给 sdshdr8.len 赋值
sh->alloc = len; // 给 sdshdr8.alloc 赋值
sh->flags = SDS_TYPE_8; // 给 sdshdr8.flags 赋值
if (ptr == SDS_NOINIT) // 如果 sds 不需要初始化, 直接添加 '\0' 即可
sh->buf[len] = '\0';
else if (ptr) { // 如果 ptr 中有数据,拷贝数据到 sds 中
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else { // 如果 ptr 中没有数据,默认初始化为 '\0'
memset(sh->buf,0,len+1);
}
return o; // 返回 redisObject 的起始地址!
}
zmalloc
void *zmalloc(size_t size) {
void *ptr = malloc(size+PREFIX_SIZE); // 多开了一个 sizeof(size_t) 的空间用来存储总大小
if (!ptr) zmalloc_oom_handler(size); // 空间开辟失败的话,会直接终止掉程序啊
#ifdef HAVE_MALLOC_SIZE // 我的系统上是不会走这段逻辑的
update_zmalloc_stat_alloc(zmalloc_size(ptr));
return ptr;
#else
*((size_t*)ptr) = size; // 初始化 redisObject 的 PREFIX 吧
update_zmalloc_stat_alloc(size+PREFIX_SIZE); // 更新 used_memory 字段
return (char*)ptr+PREFIX_SIZE; // 返回 redisObject 结构体的起始地址
#endif
}
跳转到 createEmbeddedStringObject
跳转到 update_zmalloc_stat_alloc
update_zmalloc_stat_alloc
#define update_zmalloc_stat_alloc(__n) do { \
size_t _n = (__n); \
if (_n&(sizeof(long)-1)) _n += sizeof(long)-(_n&(sizeof(long)-1)); // 这个代码是一个内存对齐的代码,对齐到 sizeof(long) 的整数倍,但是对齐的结果 _n 没有被用到哈,所以不清楚这个代码有什么用,不过内存对齐的代码我倒是学会了! \
atomicIncr(used_memory,__n); // 这是一个原子操作,将 used_memory 这个全局变量增加 __n 里面是加锁实现的! \
} while(0)
跳转到 zmalloc
atomicIncr
#define atomicIncr(var,count) do { \
pthread_mutex_lock(&var ## _mutex); \
var += (count); \
pthread_mutex_unlock(&var ## _mutex); \
} while(0)
跳转到 update_zmalloc_stat_alloc
LFUGetTimeInMinutes
unsigned long LFUGetTimeInMinutes(void) {
return (server.unixtime/60) & 65535; // server.unixtime 表示 1970 年 1 月 1 日 00:00:00 UTC 到当前时间的秒数,就是时间戳嘛
// 转换成分钟数,并且保留低 16 位,2 个字节嘛
// 2024 年 4 月 26 日对应的时间戳转换成分钟就是 28,568,238 三千万的水平嘛
// 看来是截取了低位的一部分!
}
跳转到 createEmbeddedStringObject
LRU_CLOCK
unsigned int LRU_CLOCK(void) {
unsigned int lruclock;
// server.hz 表示服务器每秒执行的时钟周期数,默认初始化为 CONFIG_DEFAULT_HZ 即是 10
// 1000 / server.hz 就是服务器执行一个时钟周期需要的毫秒数,
if (1000/server.hz <= LRU_CLOCK_RESOLUTION) { // 根据 LRU_CLOCK_RESOLUTION 定义为 1000 来看,这个判断条件恒为 true 哈
lruclock = server.lruclock; // server.lrulock 记录对象的最近访问时间,因为 EMBSTR 才被创建出来嘛。那么 EMBSTR 的最近访问时间就可以用服务器的 lrulock 来进行初始化!
} else {
lruclock = getLRUClock(); // 这个分支似乎不会进入,这里就不做分析了!
}
return lruclock; // 返回对象的最近返回时间
}
跳转到 createEmbeddedStringObject
createRawStringObject
robj *createRawStringObject(const char *ptr, size_t len) {
return createObject(OBJ_STRING, sdsnewlen(ptr,len));
}
createObject
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o)); // 开辟 redisObject 的空间
o->type = type; // 给 redisObject.type 赋值
o->encoding = OBJ_ENCODING_RAW; // 给 redisObject.encoding 赋值
o->ptr = ptr; // 给 redisObject.ptr 赋值
o->refcount = 1; // 给 redisObject.refcount 赋值
// 给 redisObject.lru 赋值
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}
server.hz 和 server.maxmemory_policy
关于 server.hz 与 server.maxmemory_policy 的初始化。
// redis-6.0.9 server.c
void initServerConfig(void) {
// ······
server.hz = CONFIG_DEFAULT_HZ; // 初始化 redis 服务器每秒执行的时钟周期数,CONFIG_DEFAULT_HZ 是 10 哈
// ······
}
// redis-6.0.9 server.c
void initServer(void) {
if (server.arch_bits == 32 && server.maxmemory == 0) {
// ···
server.maxmemory_policy = MAXMEMORY_NO_EVICTION;
// 因为 server 是一个全局变量嘛,配置文件中没有指定 maxmemory-policy 就会 初始化为 MAXMEMORY_NO_EVICTION 表示达到最大内存的时候直接报错哈!
}
// ···
}
跳转到 createEmbeddedStringObject
淘汰类型的宏定义
淘汰策略的类型:
MAXMEMORY_FLAG_LRU (1<<0): 表示 LRU(最近最少使用)淘汰策略的标志位。MAXMEMORY_FLAG_LFU (1<<1): 表示 LFU(最少频繁使用)淘汰策略的标志位。MAXMEMORY_FLAG_ALLKEYS (1<<2): 表示对所有键进行操作的标志位。MAXMEMORY_FLAG_NO_SHARED_INTEGERS: 表示不使用共享整数的标志位,采用 LRU 或 LFU 淘汰策略。
具体的淘汰策略:
MAXMEMORY_VOLATILE_LRU ((0<<8)|MAXMEMORY_FLAG_LRU): 表示对设置了过期时间的键采用 LRU 淘汰策略。MAXMEMORY_VOLATILE_LFU ((1<<8)|MAXMEMORY_FLAG_LFU): 表示对设置了过期时间的键采用 LFU 淘汰策略。MAXMEMORY_VOLATILE_TTL (2<<8): 表示根据键的过期时间进行淘汰。MAXMEMORY_VOLATILE_RANDOM (3<<8): 表示对设置了过期时间的键采用随机淘汰策略。MAXMEMORY_ALLKEYS_LRU ((4<<8)|MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_ALLKEYS): 表示对所有键采用 LRU 淘汰策略。MAXMEMORY_ALLKEYS_LFU ((5<<8)|MAXMEMORY_FLAG_LFU|MAXMEMORY_FLAG_ALLKEYS): 表示对所有键采用 LFU 淘汰策略。MAXMEMORY_ALLKEYS_RANDOM ((6<<8)|MAXMEMORY_FLAG_ALLKEYS): 表示对所有键采用随机淘汰策略。MAXMEMORY_NO_EVICTION (7<<8): 表示不进行淘汰操作,超过内存限制后拒绝写入。
//if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
// o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
//} else {
// o->lru = LRU_CLOCK();
//}
//通过 MAXMEMORY_FLAG_LFU 这个宏跳转就行啦
#define MAXMEMORY_FLAG_LRU (1<<0)
#define MAXMEMORY_FLAG_LFU (1<<1)
#define MAXMEMORY_FLAG_ALLKEYS (1<<2)
#define MAXMEMORY_FLAG_NO_SHARED_INTEGERS \
(MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU)
#define MAXMEMORY_VOLATILE_LRU ((0<<8)|MAXMEMORY_FLAG_LRU)
#define MAXMEMORY_VOLATILE_LFU ((1<<8)|MAXMEMORY_FLAG_LFU)
#define MAXMEMORY_VOLATILE_TTL (2<<8)
#define MAXMEMORY_VOLATILE_RANDOM (3<<8)
#define MAXMEMORY_ALLKEYS_LRU ((4<<8)|MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_ALLKEYS)
#define MAXMEMORY_ALLKEYS_LFU ((5<<8)|MAXMEMORY_FLAG_LFU|MAXMEMORY_FLAG_ALLKEYS)
#define MAXMEMORY_ALLKEYS_RANDOM ((6<<8)|MAXMEMORY_FLAG_ALLKEYS)
#define MAXMEMORY_NO_EVICTION (7<<8)
关于 server.maxmemory_policy 的初始化:
-
redis启动的时候会先在/etc/redis/redis.conf查找,看配置文件中是否设置了maxmemory_policy,如果有这个字段就会使用配置文件中设置的值进行初始化!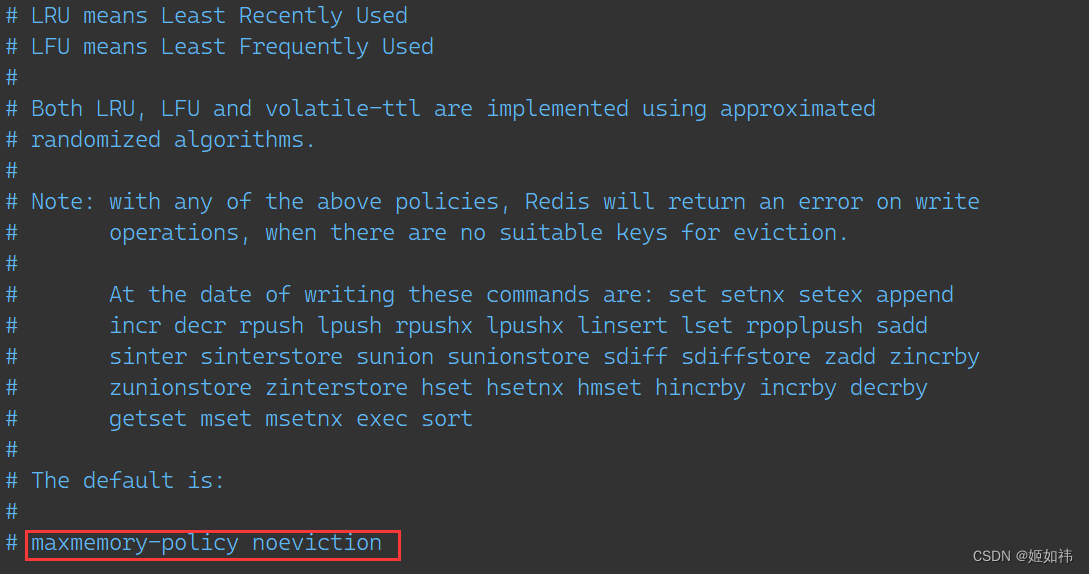
-
如果配置文件中没有这个字段的话,
redis就会默认初始化为MAXMEMORY_NO_EVICTIONvoid initServer(void) { if (server.arch_bits == 32 && server.maxmemory == 0) { // ··· server.maxmemory_policy = MAXMEMORY_NO_EVICTION; // 因为 server 是一个全局变量嘛,配置文件中没有指定 maxmemory-policy 就会 初始化为 MAXMEMORY_NO_EVICTION 表示达到最大内存的时候直接报错哈! } // ··· } -
配置文件中的
maxmemory_policy可以设置为什么呢?配置文件里面其实写得很清楚哈!这个其实就和上面讲到的宏对应的哈!volatile-lru:根据 LRU(Least Recently Used,最近最少使用)算法淘汰具有过期时间的键。allkeys-lru:根据 LRU 算法淘汰任意键。volatile-lfu:根据 LFU(Least Frequently Used,最近最少使用)算法淘汰具有过期时间的键。allkeys-lfu:根据 LFU 算法淘汰任意键。volatile-random:随机淘汰具有过期时间的键。allkeys-random:随机淘汰任意键。volatile-ttl:根据键的过期时间淘汰最近过期的键。noeviction:当达到最大内存限制时,拒绝写操作,不进行任何淘汰操作。
总结
我们来看看 EMBSTR 和 RAW的区别吧!
-
redisObject.encoding字段不同:EMBSTR是OBJ_ENCODING_EMBSTR。RAW是:OBJ_ENCODING_RAW。
-
存储数据所用到的结构体不同:
EMBSTR是固定的sdshdr8结构体。RAQ会根据存储数据的字节数使用不同的结构体。
-
存储的数据与
redisObject的物理空间关系不同:-
EMBSTR:redisObject结构体后面紧跟着sdshdr8结构体: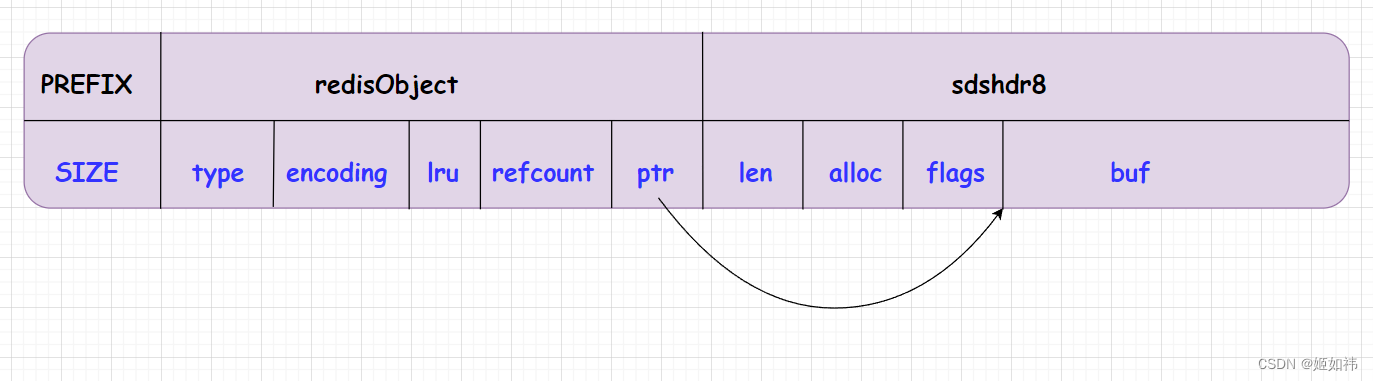
物理空间连续有如下优点:
- 内存的申请和释放只需要调用一次内存操作函数。
redisObject和sdshdr8结构体保存在一块连续的内存中,减少了内存碎片。
-
RAW:redisObject结构体与sdshdr结构体的物理空间并不连续。
-
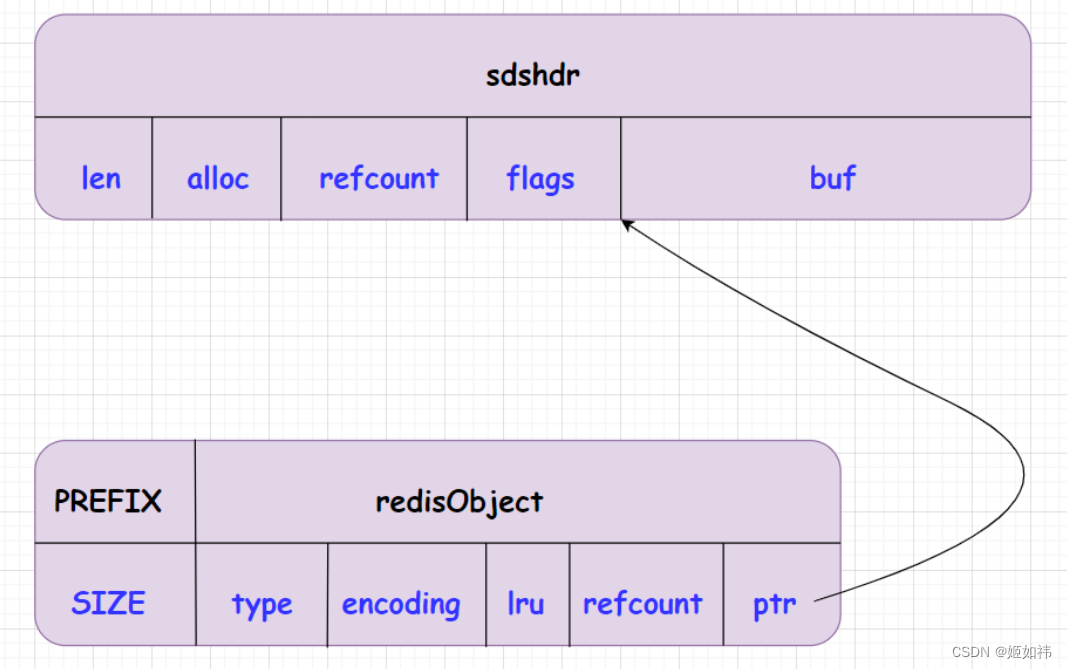
redisObject的前缀所表示的意义不同:EMBSTR:PREFIX存储的是PREFIX自身,redisObject,sdshdr8和buf的总大小。RAW:PREFIX存储的是PREFIX自身和redisObject的总大小。
tryObjectEncoding
Redis 中的键都是字符串类型,并使用 OBJ_ENCODING_RAW 或 OBJ_ENCODING_EMBSTR 编码,而 Redis 还会尝试将字符串类型的值转换为 OBJ_ENCODING_INT 编码
跳转到 serverAssertWithInfo
跳转到 sdsEncodedObject
跳转到 string2l
// redis-6.0.9 object.c
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING); // 对类型做检查,确保类型是 OBJ_STRING
if (!sdsEncodedObject(o)) return o; // 对 encoding 做判断如果 encoding 是 OBJ_ENCODING_RAW 或 OBJ_ENCODING_EMBSTR 才继续向下执行
if (o->refcount > 1) return o; // 如果当前的 redisObject 的引用计数大于 1 直接返回,因为如果改变编码方式可能会影响其他地方的运行
len = sdslen(s); // 获取 buf 柔性数组中存储的数据字节数
// 为什么是 len <= 20 呢?因为 long long 不是 8 字节嘛,2^64 计算出来的结果的位数就是 19 位,加上符号位也就是 20 位啦!当 len > 20 的话 long long 肯定存不下
if (len <= 20 && string2l(s,len,&value)) {
// 走到这里说明能转换成 long
// server.maxmemory == 0 说明没有内存限制,这个 maxmemory 也是可以通过配置文件来设置的
// MAXMEMORY_FLAG_NO_SHARED_INTEGERS 表示不使用共享整数的策略,取反就代表可以使用共享整数的策略 OBJ_SHARED_INTEGERS 表示的是共享整数的最大范围,OBJ_SHARED_INTEGERS 定义为 10000,共享整数的范围:[0, 9999]
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
// 走到这里表示使用共享整数哈
decrRefCount(o); // 将当前的 redisObject 的引用计数减一,如果减一之后的引用计数为 0 并且编码的方式还是 OBJ_ENCODING_RAW 那么就会释放 sdshdr 的空间,实际数据结构体的空间。释放完 sdshdr 之后就会释放 redisObject。其实就是直接将原 redisObject 释放啦,因为之前就进行过 refcount 的判断嘛
incrRefCount(shared.integers[value]); // 增加引用计数 value 对应的 redisObject 的引用计数 见 sharedObjectsStruct
return shared.integers[value]; // 返回 integers[value] 对应的 redisObject
} else { // 走到这里表示不能使用共享整数 redisObject
if (o->encoding == OBJ_ENCODING_RAW) {
sdsfree(o->ptr); // 释放 sdshdr 结构体
o->encoding = OBJ_ENCODING_INT; // 修改 redisObject 的 encoding
o->ptr = (void*) value; // 修改存储的实际值,用 ptr 本身的值代表存储的数据, void* 负数也能存
return o; // 返回转换为 OBJ_ENCODING_INT 编码的 redisObject
} else if (o->encoding == OBJ_ENCODING_EMBSTR) {
decrRefCount(o); // 引用计数减减,其实就是直接将原 redisObject 释放啦,因为之前就进行过 refcount 的判断嘛
// 不能像 OBJ_ENCODING_RAW 这么搞,因为 redisObject 和 sdshdr8 是一起开辟出来的,不可能像 OBJ_ENCODING_RAW 那样单独释放 sdshdr 结构体
return createStringObjectFromLongLongForValue(value); // 这里可以明确 value 的范围就是在 long 的存储范围内的,所以该函数中只会开辟一个 redisObject 并且用 ptr 来存储 value
}
}
}
// 根据上面的逻辑,存储的数据如果超过 long 的存储范围没有进行 OBJ_ENCODING_INT 的转换
// 下面的这个逻辑是:如果 redisObject 是 OBJ_ENCODING_RAW 编码,并且存储的数据的字节数少于等于 OBJ_ENCODING_EMBSTR_SIZE_LIMIT(44) 就进行编码的转换
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o; // 目的编码方式和当前编码方式相等,直接返回即可
emb = createEmbeddedStringObject(s,sdslen(s)); // 这个函数在上面已经讲过了
decrRefCount(o); // 引用计数减一,实际上就是释放原 redisObject 了!
return emb;
}
// 检查是否能够缩容,详见这个函数的详解
trimStringObjectIfNeeded(o);
return o;
}
serverAssertWithInfo
// 如果 _e 是 false,就会打印日志之后退出程序
#define serverAssertWithInfo(_c,_o,_e) ((_e)?(void)0 : (_serverAssertWithInfo(_c,_o,#_e,__FILE__,__LINE__),_exit(1)))
跳转到 tryObjectEncoding
sdsEncodedObject
// 判断 redisObject 的编码是否是 OBJ_ENCODING_RAW OBJ_ENCODING_EMBSTR 中的一个
#define sdsEncodedObject(objptr) (objptr->encoding == OBJ_ENCODING_RAW || objptr->encoding == OBJ_ENCODING_EMBSTR)
跳转到 tryObjectEncoding
string2l
// 1:尝试转换编码的字符串 2:该字符串的长度 3:输出型参数,若能转换成功,则转换成功的结果
// 返回值 0:转换失败 1:转换成功
int string2l(const char *s, size_t slen, long *lval) {
long long llval;
if (!string2ll(s,slen,&llval)) // 如果转换成 long long 失败了,那么转换成 long 一定失败
return 0;
if (llval < LONG_MIN || llval > LONG_MAX) // 如果转换成 long long 的结果超出了 long 的范围,那么转换成 long 必定失败
return 0;
*lval = (long)llval; // 存储转换成 long 的结果
return 1; // 转换成功
}
跳转到 tryObjectEncoding
string2ll
// 1:尝试转换编码的字符串 2:该字符串的长度 3:输出型参数,若能转换成功,则转换成功的结果
// 返回值 0:转换失败 1:转换成功
int string2ll(const char *s, size_t slen, long long *value) {
const char *p = s; // 当前需要转换的字符
size_t plen = 0; // 结束标记,当 plen >= slen 转换完成
int negative = 0; // 是否为负数的标志位
unsigned long long v;
// 字符串长度为 0 不能进行转换
if (plen == slen)
return 0;
// 字符串长度为 1 且该字符为 '0'
if (slen == 1 && p[0] == '0') {
if (value != NULL) *value = 0;
return 1;
}
// 如果字符串的第一个字符是 '-'
if (p[0] == '-') {
negative = 1; // 是负数
p++; plen++;
// 如果字符串长度为 1 且 该字符是 '-'
if (plen == slen)
return 0;
}
// 处理完负数的情况,第一个字符应该是属于 '1' ~ '9'
if (p[0] >= '1' && p[0] <= '9') {
v = p[0]-'0';
p++; plen++;
} else {
return 0;
}
// 开始进行转换,只有数字字符才能进行转换
while (plen < slen && p[0] >= '0' && p[0] <= '9') {
if (v > (ULLONG_MAX / 10)) // 如果条件成立后续将超过 unsigned long long 能存储的最大范围
return 0;
v *= 10;
if (v > (ULLONG_MAX - (p[0]-'0'))) // 如果条件成立后续将超过 unsigned long long 能存储的最大范围
return 0;
v += p[0]-'0';
p++; plen++;
}
// 说明在转换的过程中遇到了非数字字符
if (plen < slen)
return 0;
if (negative) { // 如果负数标志为 1
if (v > ((unsigned long long)(-(LLONG_MIN+1))+1)) // 这个判断其实就是 if(v > LLONG_MAX) 不信的话你可以将括号展开瞅瞅,如果条件成立说明 long long 无法存下这个负数
return 0;
if (value != NULL) *value = -v; // 存储转换后的结果
} else {
if (v > LLONG_MAX) // 正数,但是大于了 LLONG_MAX 也转换失败
return 0;
if (value != NULL) *value = v;
}
return 1; // 转换成功
}
跳转到 tryObjectEncoding
decrRefCount
void decrRefCount(robj *o) {
if (o->refcount == 1) {
switch(o->type) { // 根据不同的类型来选择释放
case OBJ_STRING: freeStringObject(o); break;
case OBJ_LIST: freeListObject(o); break;
case OBJ_SET: freeSetObject(o); break;
case OBJ_ZSET: freeZsetObject(o); break;
case OBJ_HASH: freeHashObject(o); break;
case OBJ_MODULE: freeModuleObject(o); break;
case OBJ_STREAM: freeStreamObject(o); break;
default: serverPanic("Unknown object type"); break;
}
zfree(o); // 释放 redisObject
} else {
if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
if (o->refcount != OBJ_SHARED_REFCOUNT) o->refcount--;
}
}
跳转到 tryObjectEncoding
freeStringObject
void freeStringObject(robj *o) {
if (o->encoding == OBJ_ENCODING_RAW) { // 为啥只有当 encoding 是 OBJ_ENCODING_RAW 菜释放 sdshdr 呢?因为 OBJ_ENCODING_EMRSTR 的 sdshdr8 是和 redisObject 一起开辟的,见createEmbeddedStringObject 这个函数
sdsfree(o->ptr); // 释放 sdshdr
}
}
跳转到 tryObjectEncoding
zfree
void zfree(void *ptr) {
#ifndef HAVE_MALLOC_SIZE
void *realptr;
size_t oldsize;
#endif
if (ptr == NULL) return; // 不能释放 NULL
#ifdef HAVE_MALLOC_SIZE // 在我的系统上 不会走这个分支
update_zmalloc_stat_free(zmalloc_size(ptr));
free(ptr);
#else
realptr = (char*)ptr-PREFIX_SIZE; // 获取真正要释放空间的首地址,在 redisObject 的前面有一个 PREFIX_SIZE 嘛
oldsize = *((size_t*)realptr); // oldsize 就是 redisObject 的大小哈 (一些特殊情况除外,比如说 EMBSTR)
update_zmalloc_stat_free(oldsize+PREFIX_SIZE); // 之前记录堆上开辟空间大小的变量不是 used_memory 这里释放了空间就要减去释放空间的大小,最后就可以根据这个变量来判断是否有内存泄漏哈
free(realptr);
#endif
}
跳转到 tryObjectEncoding
update_zmalloc_stat_free
#define update_zmalloc_stat_free(__n) do { \
size_t _n = (__n); \
if (_n&(sizeof(long)-1)) _n += sizeof(long)-(_n&(sizeof(long)-1)); // 这也是那个内存对齐,只不过这个 _n 没用到,我也不清楚这个 _n 有什么用哈 \
atomicDecr(used_memory,__n); //原子的减法,减去 __n 内部是加锁实现的 \
} while(0)
跳转到 tryObjectEncoding
sharedObjectsStruct
刚才的 share 全局变量的类型就是 sharedObjectsStruct。
sharedObjectsStruct 是 Redis 源码中用于管理共享对象的结构体。它主要用于在 Redis 服务器启动时创建和管理一些常用的共享对象,这些对象在 Redis 中被广泛使用,比如 NULL 值、空字符串、整数 0 和 1 等。通过将这些对象预先创建并共享,可以节省内存并提高性能,因为这些对象的创建和销毁是相对频繁的操作。
struct sharedObjectsStruct {
robj *crlf, *ok, *err, *emptybulk, *czero, *cone, *pong, *space,
*colon, *queued, *null[4], *nullarray[4], *emptymap[4], *emptyset[4],
*emptyarray, *wrongtypeerr, *nokeyerr, *syntaxerr, *sameobjecterr,
*outofrangeerr, *noscripterr, *loadingerr, *slowscripterr, *bgsaveerr,
*masterdownerr, *roslaveerr, *execaborterr, *noautherr, *noreplicaserr,
*busykeyerr, *oomerr, *plus, *messagebulk, *pmessagebulk, *subscribebulk,
*unsubscribebulk, *psubscribebulk, *punsubscribebulk, *del, *unlink,
*rpop, *lpop, *lpush, *rpoplpush, *zpopmin, *zpopmax, *emptyscan,
*multi, *exec,
*select[PROTO_SHARED_SELECT_CMDS],
*integers[OBJ_SHARED_INTEGERS], // 这就是常用的整形 OBJ_SHARED_INTEGERS 就是 10000,所以说共享的整形就只有过 0-9999 嘛
*mbulkhdr[OBJ_SHARED_BULKHDR_LEN],
*bulkhdr[OBJ_SHARED_BULKHDR_LEN];
sds minstring, maxstring;
};
跳转到 tryObjectEncoding
createStringObjectFromLongLongForValue
robj *createStringObjectFromLongLongForValue(long long value) {
return createStringObjectFromLongLongWithOptions(value,1);
}
跳转到 tryObjectEncoding
createStringObjectFromLongLongWithOptions
robj *createStringObjectFromLongLongWithOptions(long long value, int valueobj) {
robj *o;
// 这个条件成立的话 ,表示可以使用共享池中的对象,但是因为调用这个函数所处的代码块已经提前经过判断不能使用共享池中的对象啦,所以说这个条件一定不成立
if (server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS))
{
valueobj = 0;
}
// valueobj 为 1 。 if 条件不成立
if (value >= 0 && value < OBJ_SHARED_INTEGERS && valueobj == 0) {
incrRefCount(shared.integers[value]);
o = shared.integers[value];
} else {
if (value >= LONG_MIN && value <= LONG_MAX) { // 如果 value 的范围是在 long 的存储范围
o = createObject(OBJ_STRING, NULL); // 创建一个 redisObject, 参二表示 redisObject->ptr 的初值哈,对于 OBJ_ENCODING_INT 编码来说 ptr 成员没有用嘛!
o->encoding = OBJ_ENCODING_INT; // 给 encoding 赋值
o->ptr = (void*)((long)value); // 同样用 ptr 本身存储 value 的值
} else { // 如果 value 的范围在 long long 的存储范围,那么我们就需要为 ptr 开辟空间啦!
o = createObject(OBJ_STRING,sdsfromlonglong(value));
}
}
return o; // 将创建好的 rediObject 返回
}
跳转到 createObject
sdsfromlonglong
sds sdsfromlonglong(long long value) {
char buf[SDS_LLSTR_SIZE]; // SDS_LLSTR_SIZE 这个宏是 21 哈,21 空间一定是足够的,请回忆 该函数调用的位置,进行了 len <= 20 的判断!
int len = sdsll2str(buf,value); // value 转换成字符串,将结果保存到 buf 数组中
return sdsnewlen(buf,len); // 根据字符串 buf 和 字符串的长度 len 创建一个 sdshdr 结构体之后将存储数据的指针返回
}
sdsll2str
int sdsll2str(char *s, long long value) {
char *p, aux;
unsigned long long v;
size_t l;
v = (value < 0) ? -value : value; // 将传入的 value 取绝对值赋值给 v
p = s;
do {
*p++ = '0'+(v%10);
v /= 10;
} while(v); // 将 value 的每一位转换成对应数字的字符,并且放入字符数组 s 中,例如:1234 -> "4321", -1234 -> "4321-"
if (value < 0) *p++ = '-'; // 负数的话需要在末尾加上 '-'
l = p-s; // 将 value 转换为字符串后的字符串长度
*p = '\0';
// 翻转字符串
p--;
while(s < p) {
aux = *s;
*s = *p;
*p = aux;
s++;
p--;
}
return l; // 返回值是将 value 转化成字符串的字符串长度
}
trimStringObjectIfNeeded
这个函数是缩容用的!
void trimStringObjectIfNeeded(robj *o) {
// 如果编码方式是 OBJ_ENCODING_RAW 并且 剩余的空间大于字符串长度的十分之一,进行缩容!
if (o->encoding == OBJ_ENCODING_RAW &&
sdsavail(o->ptr) > sdslen(o->ptr)/10) // sdsavail sdslen 这两个函数我们都讲过了哈
{
o->ptr = sdsRemoveFreeSpace(o->ptr); // 这个函数我们已经讲过了哈!
}
}