大家好,随着大型语言模型(LLM)驱动的聊天机器人逐渐普及,给人们的工作和生活带来了前所未有的便利。然而,这种便捷性背后潜藏着个人隐私信息被泄露的风险,例如AI公司会收集聊天记录和元数据来优化模型,从而提升服务,这不禁让用户担忧。
对于注重隐私的用户而言,本地部署这些模型,可以有效保护个人隐私,同时也能更自主地管理自己的数据。本文将介绍5个在本地使用大型语言模型(LLM)的工具,这些工具不仅兼容主流操作系统,而且安装过程快捷简便。
1 GPT4All
安装链接:https://gpt4all.io/index.html
GPT4All是开源软件,可从网站下载GPT4ALL并将其安装在你的系统上。
安装后从面板中选择适合需求的模型开始使用,如果电脑装有CUDA(Nvidia的GPU驱动),GPT4ALL软件会自动利用GPU加速,快速生成回复,速度可达每秒30个令牌。
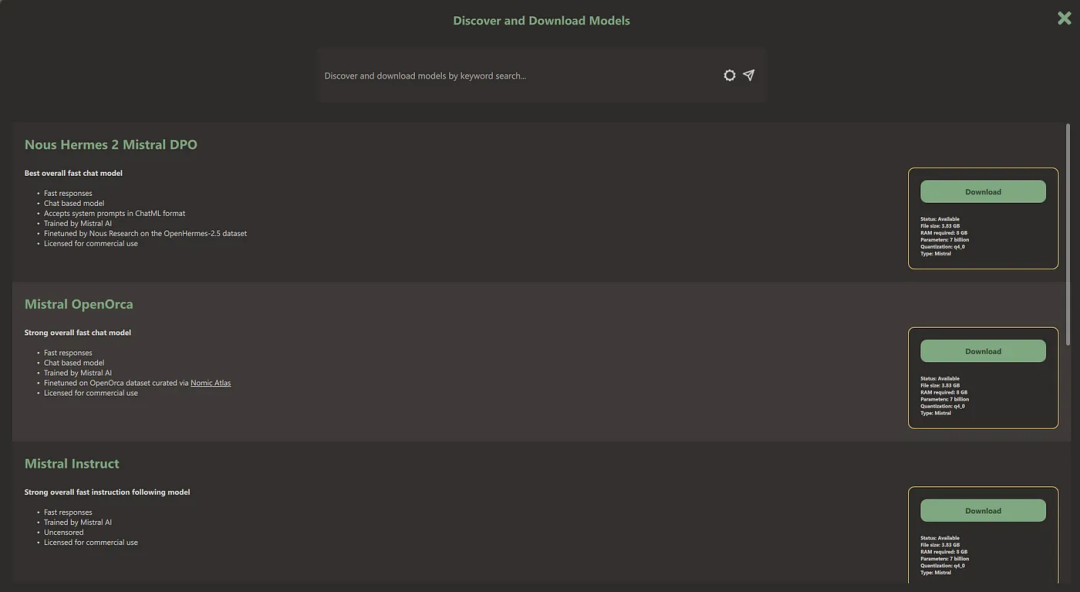
只需授权GPT4ALL访问存放重要文件和代码的文件夹,GPT4ALL就能利用检索增强生成技术,迅速生成精准的回复。
这款软件用户界面友好,响应迅速,在人工智能领域备受推崇。
2 LM Studio
安装链接:https://lmstudio.ai/
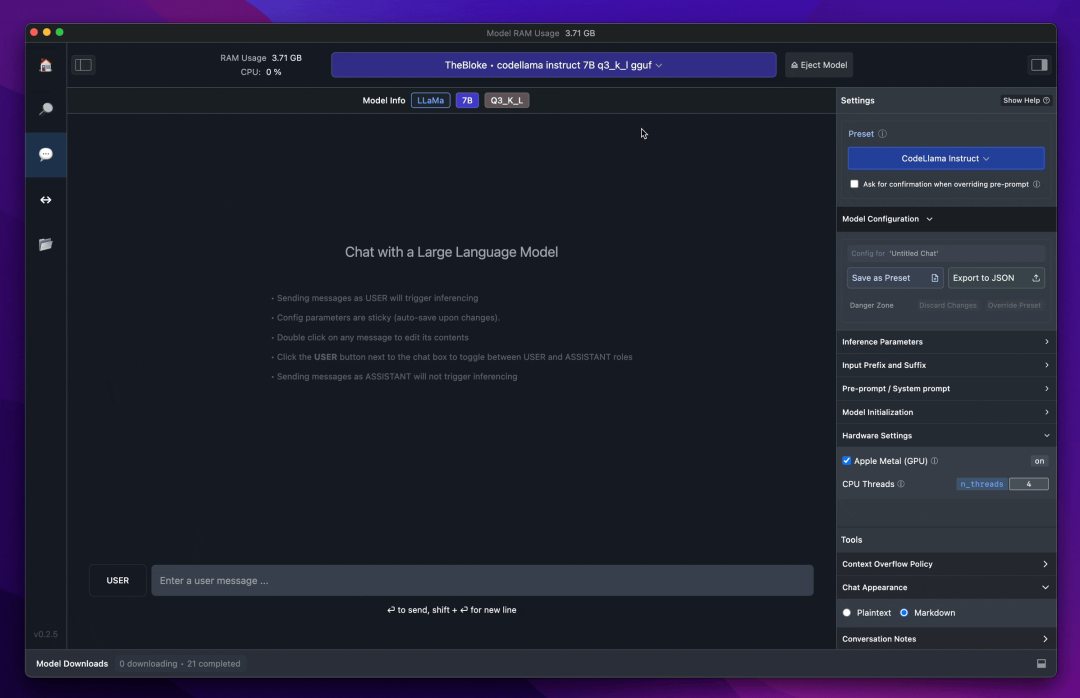
LM Studio 是一款用户友好的桌面应用,专为本地和开源的大型语言模型(LLM)的实验设计,操作简单直观。
使用LM Studio,可以:
-
在笔记本电脑上完全离线运行LLM
-
通过应用程序内的聊天界面或兼容OpenAI的本地服务器来使用模型
-
从HuggingFace资源库下载兼容的模型文件
-
在应用程序的主页面发现新的和值得注意的LLM
与 GPT4ALL 相比,LM Studio 具有多项优势。
首先,用户界面非常出色,仅需几次点击,就可完成安装 Hugging Face Hub 上的任意模型。
此外,LM Studio 还支持 GPU 加速功能,并提供 GPT4ALL 所不具备的一些额外选项。
需要注意的是,LM Studio 是一个闭源软件,它不提供通过读取项目文件来生成上下文感知响应的功能。
3 Ollama
安装链接:https://ollama.com/
Ollama提供了一种轻量级和用户友好的方式来搭建和运行各种开源LLM,消除了复杂配置或依赖外部服务器的需要,适用于多种应用场景:
-
开发:允许开发人员对 LLM 项目进行实验和快速迭代,而无需将其部署到云端。
-
研究:研究人员可以使用Ollama在受控环境中研究LLM的行为,从而促进深入分析。
-
隐私:在本地运行 LLM 可确保数据不会离开你的机器,这对敏感信息很重要。
Ollama 预置了训练有素的语言模型库,例如:
-
Llama 2:能够执行文本生成、翻译和问答等多种任务的大型语言模型。
-
Mistral:在大量文本和代码数据集上训练的事实性语言模型。
-
Gemma:专为对话应用设计的语言模型,旨在增强对话的互动性和吸引力。
-
LLaVA:针对聊天和教学用例训练的强大模型。
该库简化了预训练模型的集成流程,开发人员可以直接在应用程序中使用这些模型,无需从零开始训练,大大节省了时间和资源。Ollama充分利用了NVIDIA GPU以及现代CPU的高级指令集(如AVX和AVX2)来加速模型的运行,整个过程无需复杂的配置或虚拟化操作。
在下面的示例中,我们可以下载Mistral LLM:

下载模型后,可以开始询问与它聊天:

4 LLaMA.cpp
安装链接:https://github.com/ggerganov/llama.cpp
LLaMA.cpp由Georgi Gerganov开发。它以 C/C++ 语言高效实现了 Meta 的 LLaMa 模型架构,并且是围绕LLM推理的最活跃的开源社区之一,拥有超过390名贡献者,在官方GitHub仓库上有43,000+个星标和 930 多次的发布。
Llama.cpp的核心是原始的Llama模型,该模型采用变换器架构构建。开发者们不仅采用了该领域后续的各种改进,还参考了如 PaLM 等其他模型的特点,来进一步提升模型的性能和应用范围。

可以使用以下命令安装:
pip install llama-cpp-python
安装后,使用以下命令导入:
from llama_cpp import Llama
上面导入的 Llama 类包含的主要构造函数在使用 Llama.cpp 时会被调用,它接受多个参数,并不仅限于以下列出的这些。完整的参数列表可以在官方文档中找到(https://llama-cpp-python.readthedocs.io/en/latest/api-reference/#llama_cpp.Llama):
-
model_path:正在使用的Llama模型文件的路径.
-
prompt:模型的输入提示。该文本将被标记化并传递给模型。
-
device:用于运行Llama模型的设备;此类设备可以是CPU或GPU。
-
max_tokens:模型响应中要生成的最大令牌数。
-
stop:会导致模型生成过程停止的字符串列表。
-
temperature:这个值在0到1之间。值越低,结果越确定性。反之,数值越高,随机性越大,输出也就越多样、越有创意。
-
top_p:用于控制预测的多样性,即选择累积概率超过给定阈值的最有可能的令牌。从零开始,数值越大,找到更好输出结果的几率越大,但需要额外的计算。
-
echo:一个布尔值,用于确定模型是否在开头包含原始提示(True)或不包含(False)
例如,假设要使用一个名为“MY_AWESOME_MODEL”的大型语言模型,该模型存储在当前工作目录中,实例化过程如下所示:
# 实例化模型
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# 定义参数
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()
5 NVIDIA RTX聊天
安装链接:https://www.nvidia.com/en-us/ai-on-rtx/chatrtx/
ChatRTX 是一款演示应用程序,用户可以通过 GPT 大型语言模型(LLM)个性化地接入自己的内容,包括文档、笔记或其他数据。利用检索增强生成(RAG)、TensorRT-LLM 和 RTX 加速,可以查询自定义聊天机器人,快速获得与上下文相关的答案。由于所有操作都在 Windows RTX PC 或工作站上本地运行,因此用户可以获得快速、安全的结果。
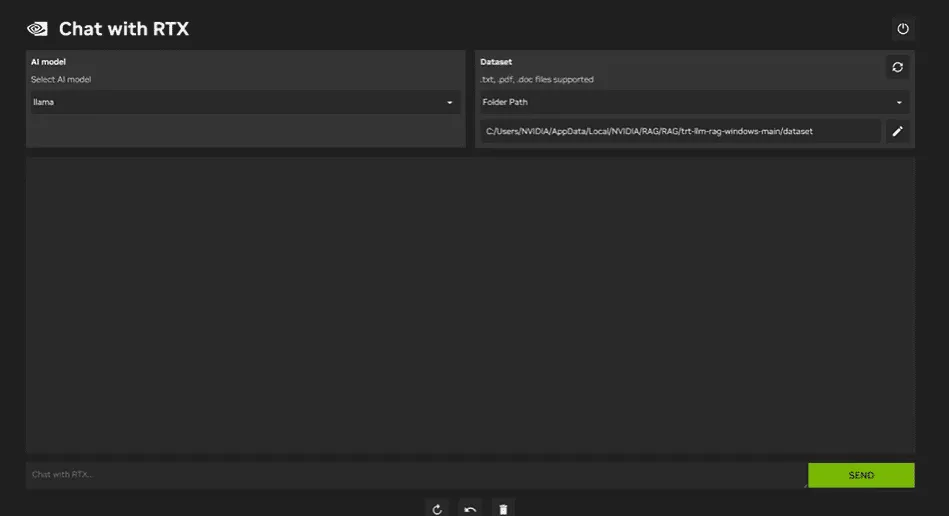
使用RTX上的Chat,可以直接在笔记本电脑上本地运行LLaMA和Mistral模型。这款快速高效的应用程序,可以从用户提供的文档或视频中学习。需要注意的是,Chat with RTX依赖于TensorRTX-LLM,它只支持30系列或更新的GPU。




![JSP简介——[JSP]1](https://img-blog.csdnimg.cn/direct/4e8a23fd4dd94eb48de2fe48f7c8da70.png)