本篇文章主要讲解 C++容器之map相关用法 的相关内容
文章目录
- `1. map的介绍`
- `2. map的使用`
- ==<font size=5 color = #0000ff>💯map的模板参数==
- ==<font size=5 color = #0000ff>💯map的插入==
- ==<font size=4 color = #0000ff>💥✨关于pair的构造==
- ==<font size=4 color = #0000ff>💥✨map显示定义pair对象传入插入==
- ==<font size=4 color = #0000ff>💥✨map传入pair匿名对象插入==
- ==<font size=4 color = #0000ff>💥✨map的makepair插入==
- ==<font size=4 color = #0000ff>💥✨map的initializer_list插入==
- ==<font size=5 color = #0000ff>💯map的迭代器==
- ==<font size=5 color = #0000ff>💯关于map的 [ ] 操作==
- ==<font size=4 color = #0000ff>💥✨[ ] 的使用说明==
- `3.相关OJ题目`
1. map的介绍
C++ Reference 介绍链接:
map文档介绍
总结:
map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。(KV模型,之前文章讲过)- 在
map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair:- 在内部,
map中的元素总是按照键值key进行比较排序的。map中通过键值访问单个元素的速度通常比unordered_map(哈希表)容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
2. map的使用
💯map的模板参数

key: 键值对中key的类型;T: 键值对中value的类型;Compare: 比较器的类型,map中的元素是按照key来比较的,缺省情况下按照小于来比较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递);Alloc:通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的空间配置器。
💯map的插入

上面讲过
map是一个KV模型,即第一个存的是关键字Key,第二个存的是值Value,C++为了方便,把这两个要存的值放在了一个结构体pair中,并将他typedef成了value_type,一般称pair为键值对。
我们可以看一下pair类中的成员变量和成员函数:
其实也很容易能看懂对吧,就和我们上面介绍的一样,需要注意的是有两个构造函数,一个是默认的(无参),一个是有
const类型参数的。
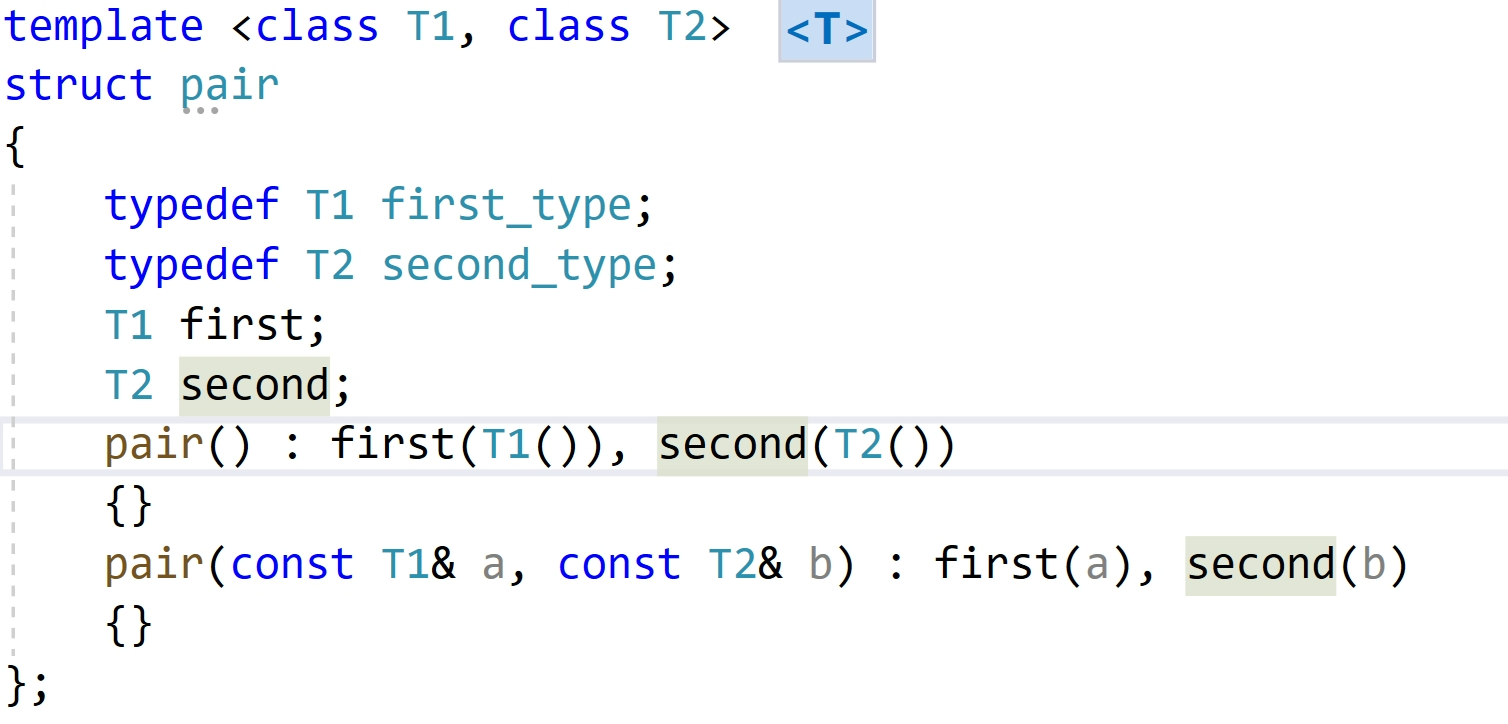
💥✨关于pair的构造
咱们先学习一下
pair的构造才能继续学习map的插入操作:

这里可以看到
pair是支持:
- 默认的无参构造;
- 拷贝构造;
initializer_list的构造(注意这里后面会用)。
除此之外还支持一个make_pair的构造:
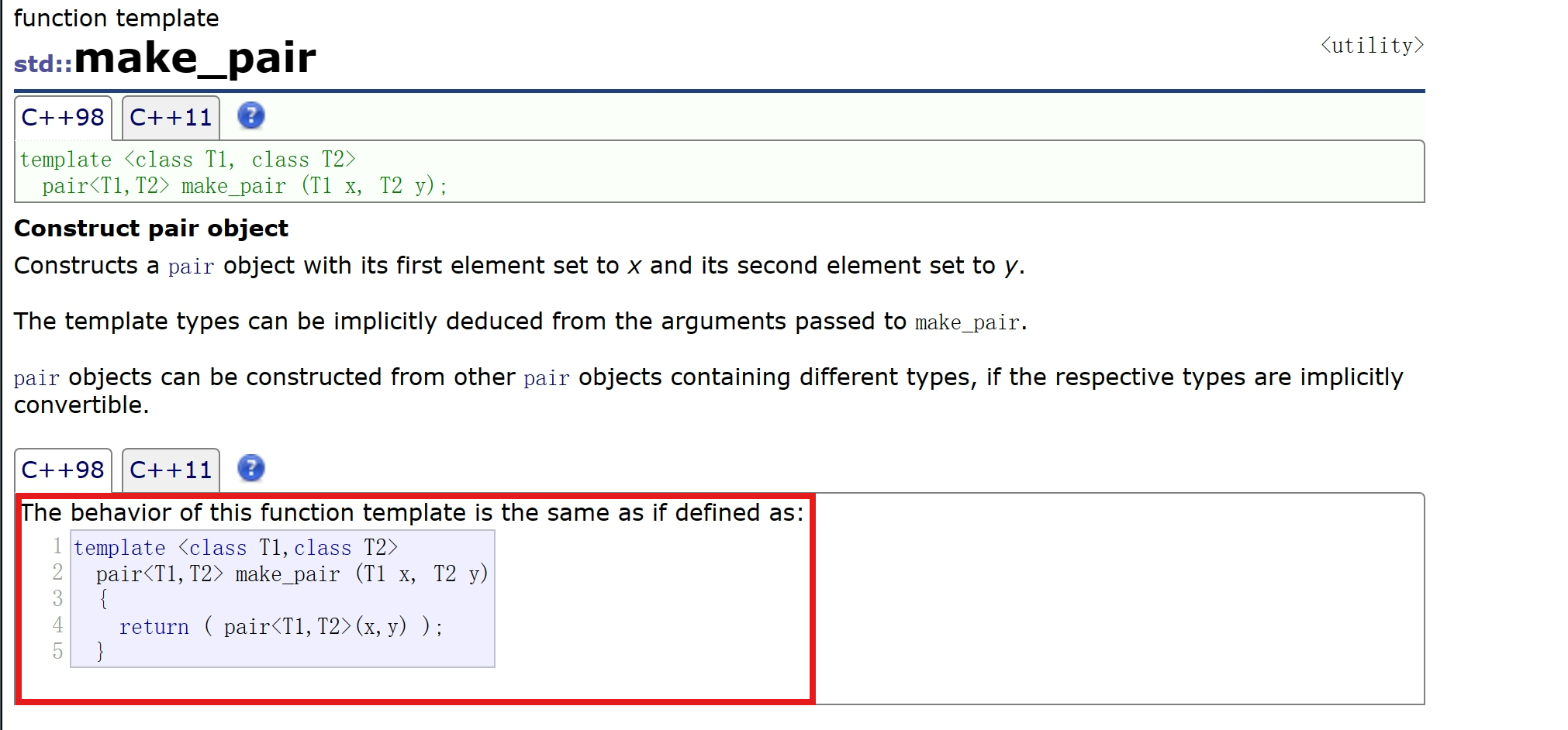
看的出来
make_pair是一个函数模板,它会根据我们传入的数据来推断出数据类型,返回类型也是一个pair。
pair构造的总结
pair最重要的还是两个构造方式:
make_pair的构造;initializer_list的构造。
💥✨map显示定义pair对象传入插入
这个很好理解,直接看代码吧:
void test_map1()
{
map<string, string> dict;
pair<string, string> kv1("sort", "排序");
dict.insert(kv1);
}
💥✨map传入pair匿名对象插入
这个也很好理解吧,直接看代码吧:
dict.insert(pair<string, string>("tree", "树"));
💥✨map的makepair插入
这边就是用到库中的
make_pair的函数,他会自动帮我们生成pair类型的对象,还会帮我们推出类型,看代码:
dict.insert(make_pair("heap", "堆"));
💥✨map的initializer_list插入
我们刚才说过
pair支持initializer_list的构造方式,所以我们可以用这个性质让他隐式类型转换成pair然后再插入(多参数类型的构造函数也支持隐式类型转换,只是要传入initializer_list类型)。
dict.insert({ "strawberry","草莓" });
💯map的迭代器
map也同样支持正向和反向迭代器,用法也类似,就拿我们刚才写的插入的代码来看,以下是迭代器的用法。
迭代器用法代码示例:
void test_map1()
{
map<string, string> dict;
pair<string, string> kv1("apple","苹果");
dict.insert(kv1);
dict.insert(pair<string, string>("banana", "香蕉"));
dict.insert(make_pair("pineapple", "菠萝"));
dict.insert({ "blueberry","蓝莓" });
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{
cout << (*it).first << " " << (*it).second << endl;
++it;
}
}
很多人可能有疑问为什么这里的访问不是
*it呢?我们可以回忆以下关于list的迭代器的实现方法,list的迭代器类中只有一个Node*类型的指针,为了解引用满足需求,我们进行了运算符重载,解引用返回值的是node->val。
所以这里也类似,返回值是pair类型,因此,根据我们刚才对pair的了解,pair->first是Key,pair->second是Value,这样理解起来就很简单了对吧。
除此之外,我们在模拟实现
list的时候,是不是也运算符重载了一个->,同样的map这里也有这个操作,返回值也可以和list的类比以下,list返回的是val的地址,这里返回值类型是pair*。
那么就可以有以下的用法:
while (it != dict.end())
{
cout << (*it).first << " " << (*it).second << endl;
// 不省略的写法
cout << it.operator->()->first << " " << it.operator->()->second << endl;
// 这里之前讲过,两个->省略成一个->
cout << it->first << " " << it->second << endl;
++it;
}
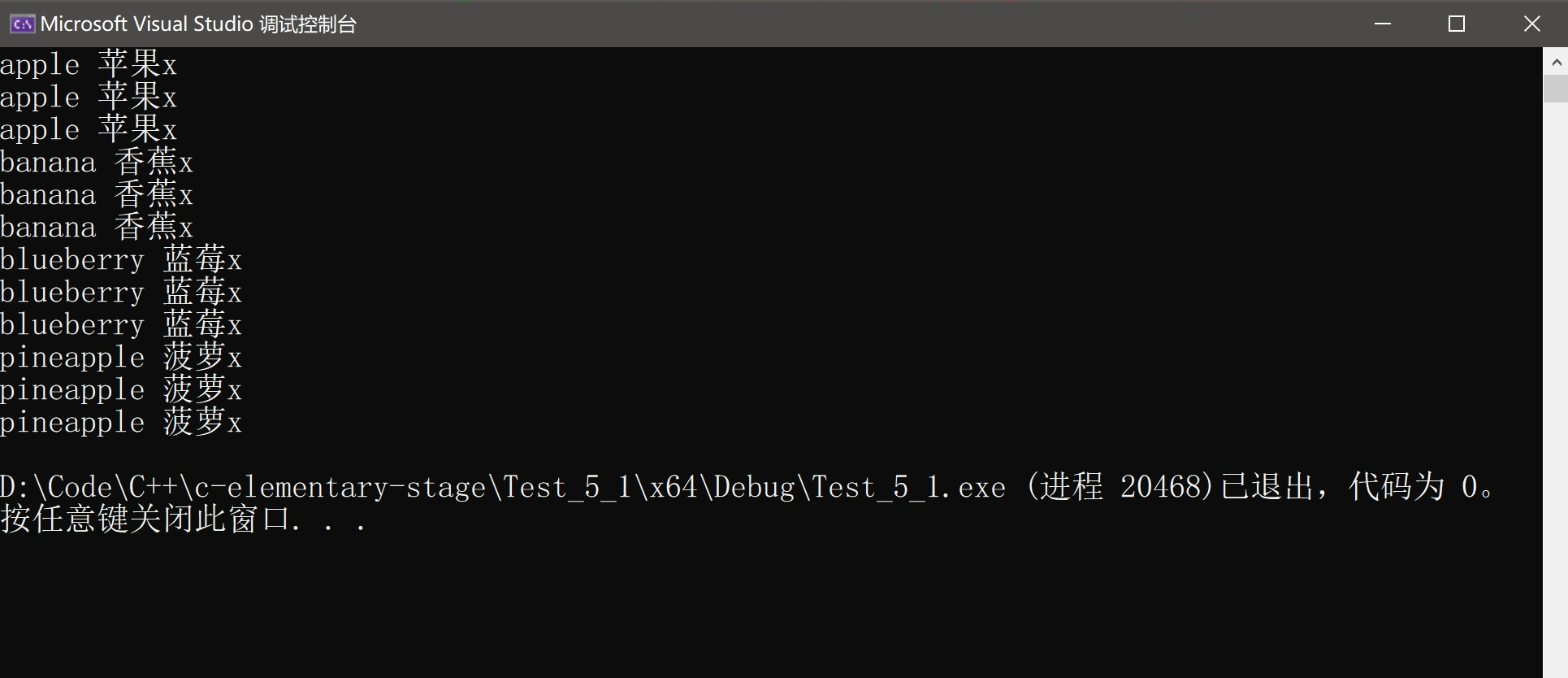
对于map来说,Key不可以修改,而Val可以修改,例如上面的代码稍加修改:
while (it != dict.end())
{
it->second += 'x';
// 下面会报错
//it->first += 'x';
cout << (*it).first << " " << (*it).second << endl;
cout << it.operator->()->first << " " << it.operator->()->second << endl;
cout << it->first << " " << it->second << endl;
++it;
}
💯关于map的 [ ] 操作
我们在之前讲过统计水果出现的次数的代码,可以用
KV模型来实现,我们尝试用map模拟一下:
void test_map2()
{
string arr[] = {"苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉","苹果","草莓", "苹果","草莓" };
map<string, int> countMap;
for (auto& e : arr)
{
auto it = countMap.find(e);
if (it != countMap.end())
{
it->second++;
}
else
{
countMap.insert({ e,1 });
}
}
for (auto& kv : countMap)
{
cout << kv.first << ":" << kv.second << endl;
}
cout << endl;
}
其实这里可以用
[]操作直接搞定:
void test_map2()
{
string arr[] = {"苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉","苹果","草莓", "苹果","草莓" };
map<string, int> countMap;
for (auto& e : arr)
{
countMap[e]++;
}
for (auto& kv : countMap)
{
cout << kv.first << ":" << kv.second << endl;
}
cout << endl;
💥✨[ ] 的使用说明
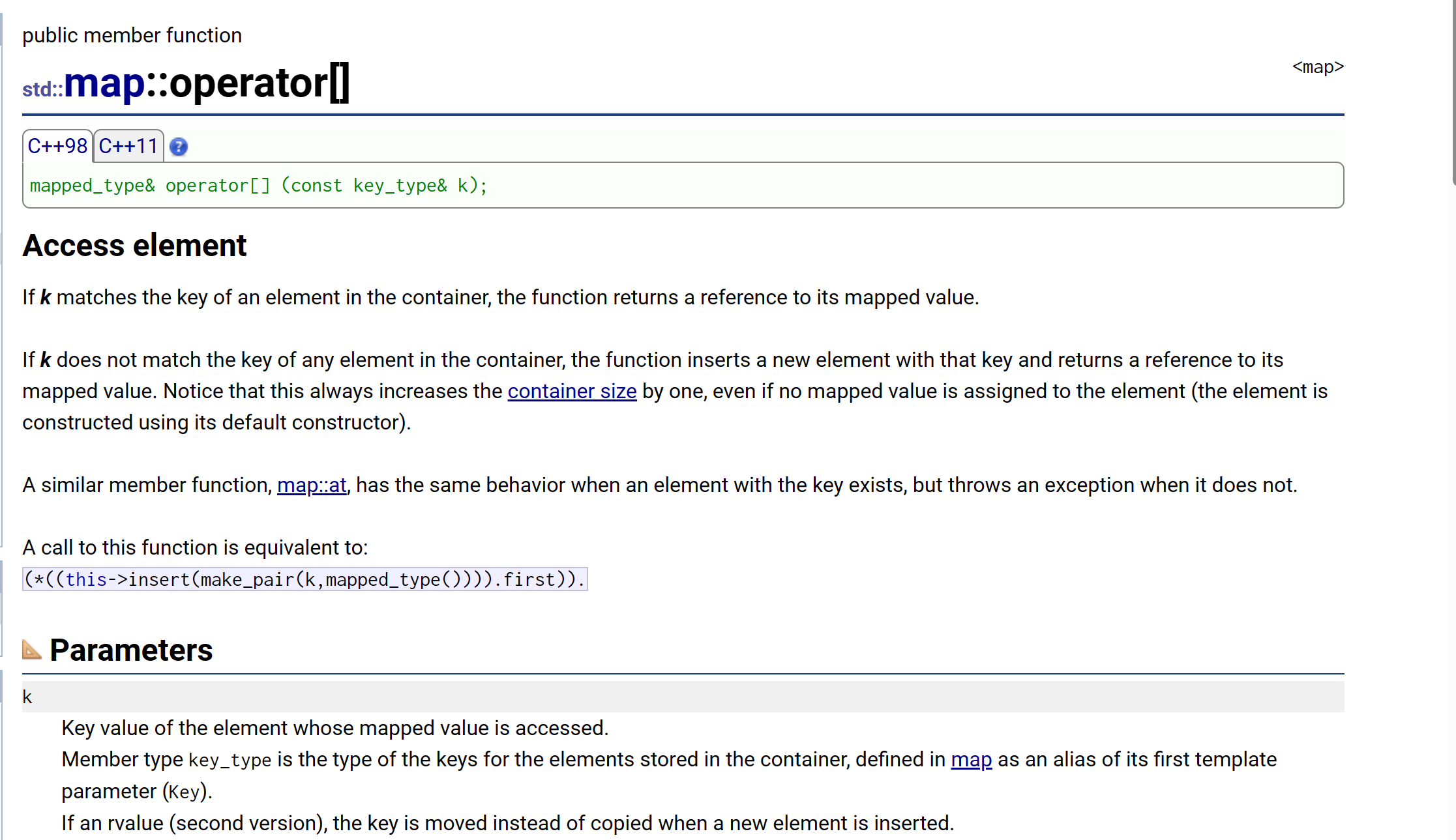
解释:
- 注意到
[ ]的返回值是mapped_type,即Value,传入类型是key_type,即Key;- 如果在容器中找到了匹配的
key,就会返回value的引用;
如果没找到所能够匹配的key,他就会插入这个新元素,并返回它的value的引用。- 与一下代码行为相同:
(*((this->insert(make_pair(k,mapped_type()))).first)).second
我们仔细分析一下他给出的行为相同的代码,先看一下
insert的返回值:
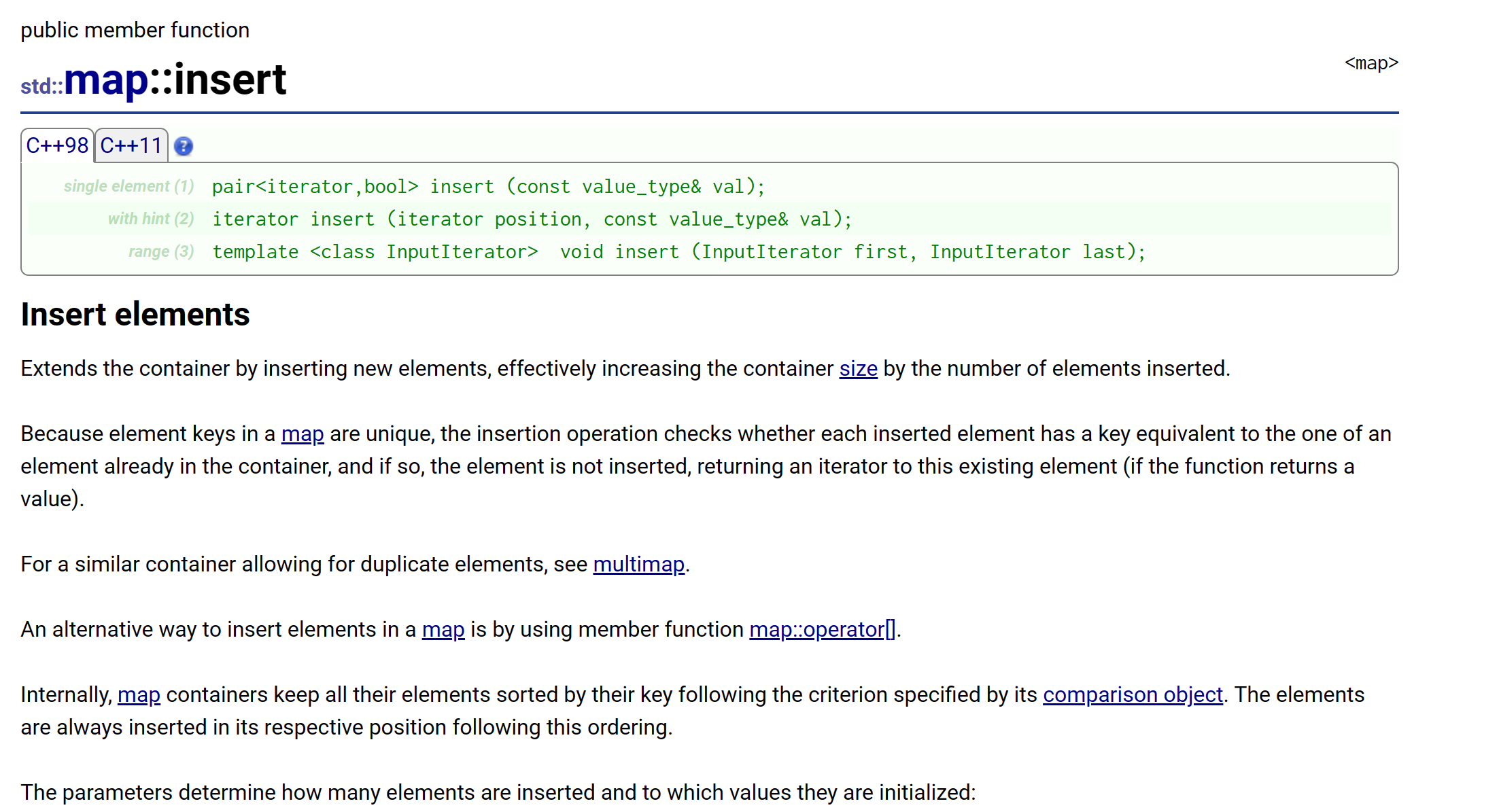

解释:
- 单元素的插入返回类型是
pair,并且pair的第一个元素类型是iterator,第二个元素类型是bool;- 对于迭代器:如果插入成功(
key不存在),就会返回此元素所在位置的迭代器,如果插入不成功(元素已经存在),就会返回相同元素所在位置的迭代器;- 对于
bool:如果插入成功(key不存在),就是true,如果插入不成功(元素已经存在),就是false。- 所以不管插入成功与否,都会返回
key节点所在的迭代器。
类似于这段代码:
V& operator[] (const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
iterator it = ret.first;
return it->second;
}
所以[]就有查找和插入两种操作:
void test_map3()
{
map<string, string> dict;
// 插入
dict["insert"];
// 插入 + 修改
dict["left"] = "左边";
// 查找
cout << dict["left"] << endl;
// 修改
dict["insert"] = "插入";
}
3.相关OJ题目
题目链接: 随机链表的复制
题目思路:这题的难点主要在random指针的深拷贝:
- 我们可以在每次新建一个结点之后用map来存储原始节点和新建节点的对应关系;
- 然后再遍历原始链表,针对每个节点,我们就可以查看其random指针指向的位置,然后利用map,就可以找到这个目标节点在复制链表中对应的新节点。
- 主要就是这行代码:
copy->random = RandomMap[cur->random](我只能说这个思路太牛逼了)。
实现代码:
class Solution
{
public:
Node* copyRandomList(Node* head)
{
Node* cur = head;
Node* newhead = nullptr, *tail = nullptr;
map<Node*, Node*> randomMap;
while (cur)
{
if (newhead == nullptr)
{
newhead = tail = new Node(cur->val);
}
else
{
tail->next = new Node(cur->val);
tail = tail->next;
}
// 每次新增cur和tail的映射关系
randomMap[cur] = tail;
cur = cur->next;
}
cur = head;
Node* copy = newhead;
while (cur)
{
// 判断为空的情况
if (cur->random == nullptr)
{
copy->random = nullptr;
}
else
{
// 这个思路的点睛之笔,以cur->random作为key,找到val,
// 这个val就是复制链表中copy->random所指的位置
copy->random = randomMap[cur->random];
}
cur = cur->next;
copy = copy->next;
}
return newhead;
}
};
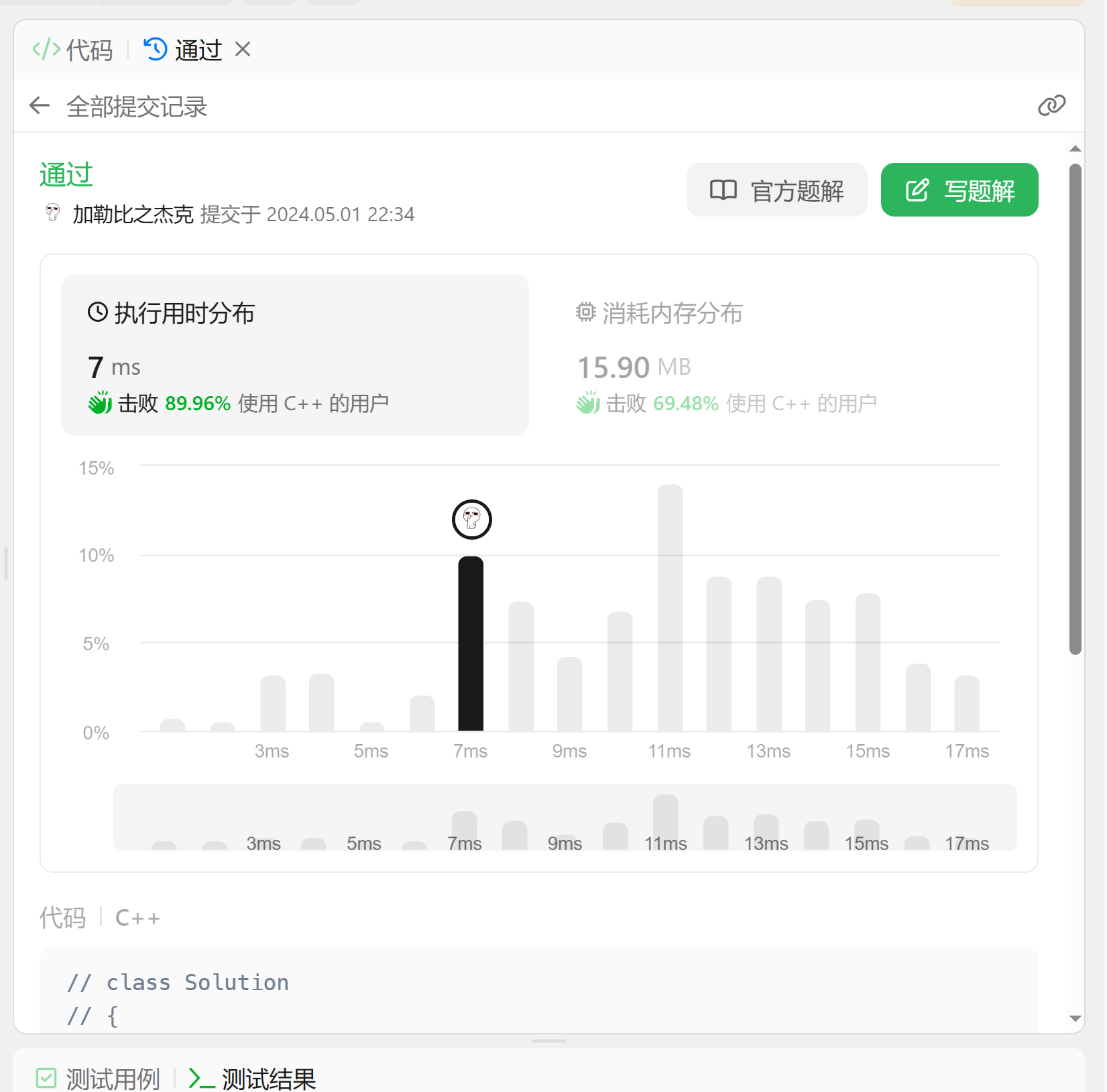
就很完美地过啦,而且效率很高:
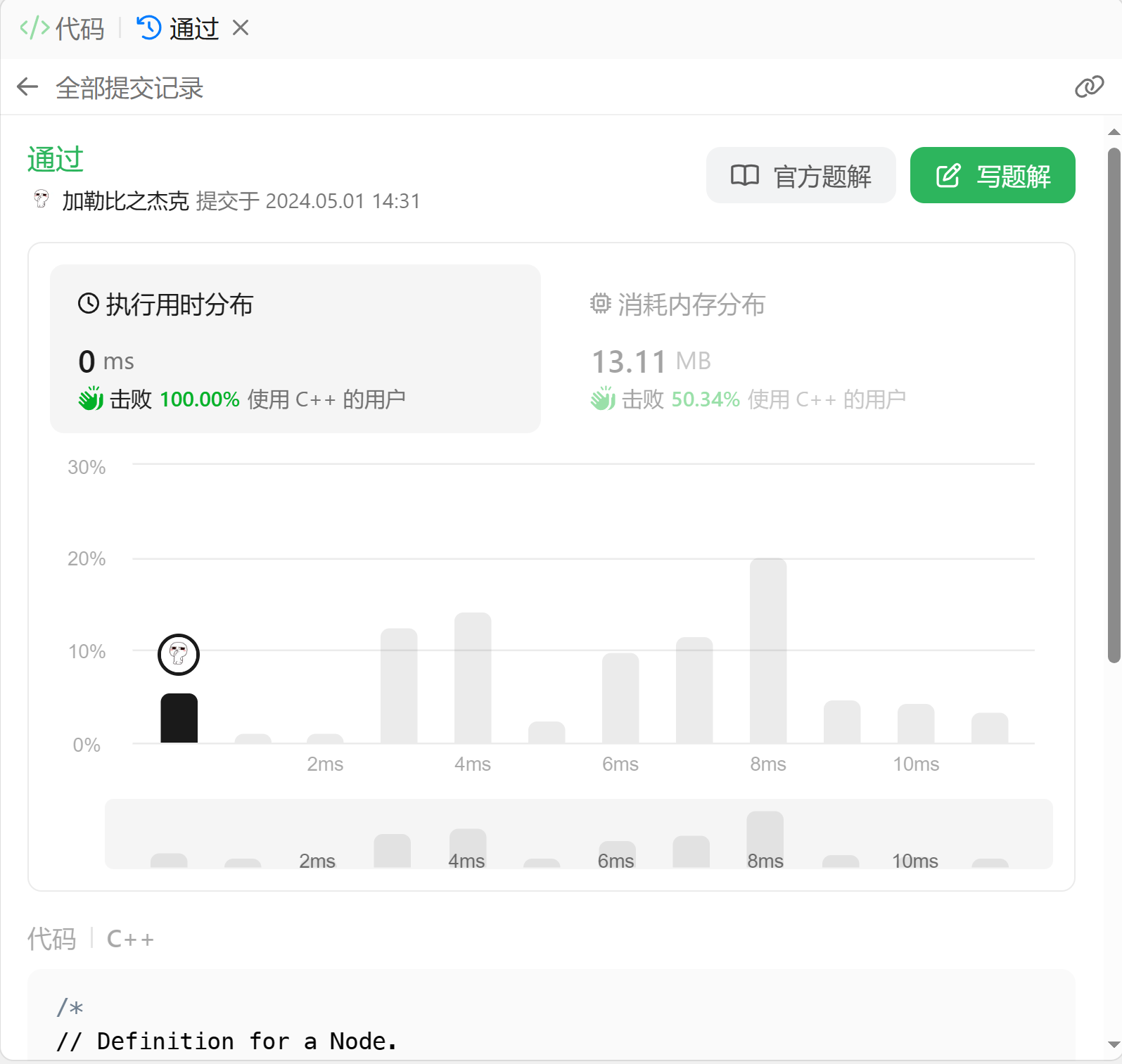
题目链接: 前K个高频单词
题目思路:
- 这题首先要去重,用
map就可以;- 然后要按照出现的次数排序,可以先把它放到
vector中,然后按照降序排序(仿函数);- 最后再把它放在返回的
vector中即可。
但是这题的难点是要按照字典序排序:
解决方法 1.
- 首先我们去重的时候用
map肯定是按照字典序排序的,但是把它放到vector中之后,然后按照出现的次数进行排序,因为sort的底层是快排(不稳定),所以当次数相同时字典序大的肯定再前面了,因此要用稳定的排序,库中有stable_sort(底层用的是归并排序),可以解决这个问题。
解决方法 2.
- 除此之外,还有一种方法,在仿函数中添加出现次数相同的情况下按照字典序排序即可。
解决方法1代码
struct kvComp
{
bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2)
{
return kv1.second > kv2.second;
}
};
class Solution
{
public:
vector<string> topKFrequent(vector<string>& words, int k)
{
map<string, int> countMap;
for (auto& e : words)
{
countMap[e]++;
}
vector<pair<string,int>> v(countMap.begin(),countMap.end());
stable_sort(v.begin(),v.end(),kvComp());
vector<string> ret;
for (size_t i = 0; i < k; ++i)
{
ret.push_back(v[i].first);
}
return ret;
}
};
解决方法2代码
struct kvComp
{
bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2)
{
return kv1.second > kv2.second || (kv1.second == kv2.second && kv1.first < kv2.first);
}
};
class Solution
{
public:
vector<string> topKFrequent(vector<string>& words, int k)
{
map<string, int> countMap;
for (auto& e : words)
{
countMap[e]++;
}
vector<pair<string,int>> v(countMap.begin(),countMap.end());
sort(v.begin(),v.end(),kvComp());
vector<string> ret;
for (size_t i = 0; i < k; ++i)
{
ret.push_back(v[i].first);
}
return ret;
}
};

![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-6.4--汇编LED驱动程序](https://img-blog.csdnimg.cn/direct/487de93cb8a744e68029b0290f7d918d.png)