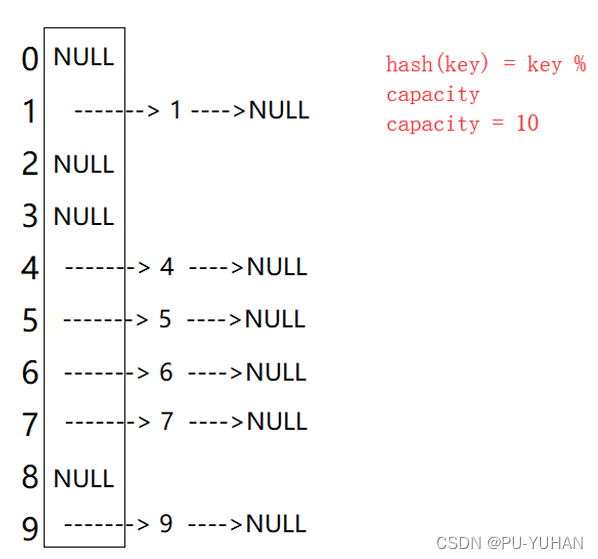
文章目录
- 前言
-
- 交叉验证:保证模型的稳健性
-
- 理论基础
- Scikit-learn中的实现
- 网格搜索:寻找最佳参数
-
- 理论基础
- Scikit-learn中的实现
- 应用示例
- 结论
前言
模型选择和调优是机器学习项目成功的关键步骤。在Scikit-learn中,交叉验证和网格搜索是两个强大的工具,用于选择最佳模型和调整参数以提高模型性能。
交叉验证:保证模型的稳健性
理论基础
交叉验证是一种评估统计模型性能的技术,它通过将数据集分割成小的部分来重复进行训练与验证过程。其中,最常见的方法是k折交叉验证,即将数据集随机分成k个子集,每次留其中一个子集作为验证集,其余k-1个子集用于训练。
Scikit-learn中的实现
Scikit-learn提供了许多交叉验证的实用工具,如cross_val_score和cross_validate函数,以及KFold和StratifiedKFold等类。
from sklearn.model_selection import cross_val_score, KFold
from sklearn.ensemble import RandomForestClassifier
# 假设X为特征集,y为对应的标签
clf = RandomForestClassifier(n_estimators=100)


![[数据结构]———交换排序](https://img-blog.csdnimg.cn/direct/7fb0534550834b0681b193b62c6bec0e.png)