今天要解决的问题是如何使用spark sql 建表,插入数据以及查询数据
1、建立一个类叫 DeltaLakeWithSparkSql1,具体代码如下,例子参考Delta Lake Up & Running第3章内容
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DeltaLakeWithSparkSql1 {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder()
.master("local[*]")
.appName("delta_lake")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate();
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
spark.sql("CREATE DATABASE IF NOT EXISTS taxidb");
spark.sql("CREATE TABLE IF NOT EXISTS taxidb.YellowTaxi(" +
"RideID INT,"+
"PickupTime TIMESTAMP,"+
"CabNumber STRING)" +
"USING DELTA LOCATION 'file:///D:\\\\bigdata\\\\detla-lake-with-java\\\\YellowTaxi'"
);
// 插入5条记录
spark.sql("DESCRIBE TABLE taxidb.YellowTaxi").show();
spark.sql("INSERT INTO taxidb.YellowTaxi (RideID,PickupTime,CabNumber) values (1,'2013-10-13 10:13:15','51-96')");
spark.sql("INSERT INTO taxidb.YellowTaxi (RideID,PickupTime,CabNumber) values (2,'2013-10-13 10:13:15','51-96')");
spark.sql("INSERT INTO taxidb.YellowTaxi (RideID,PickupTime,CabNumber) values (3,'2013-10-13 10:13:15','51-96')");
spark.sql("INSERT INTO taxidb.YellowTaxi (RideID,PickupTime,CabNumber) values (4,'2013-10-13 10:13:15','51-96')");
spark.sql("INSERT INTO taxidb.YellowTaxi (RideID,PickupTime,CabNumber) values (5,'2013-10-13 10:13:15','51-96')");
System.out.println("不分区查询开始时间(含毫秒): " + sdf.format(new Date()));
spark.sql("SELECT RideID,PickupTime,CabNumber FROM taxidb.YellowTaxi").show();
System.out.println("不分区查询结束时间(含毫秒): " + sdf.format(new Date()));
spark.sql("CREATE TABLE IF NOT EXISTS taxidb.YellowTaxiPartitioned(" +
"RideID INT,"+
"PickupTime TIMESTAMP,"+
"CabNumber STRING)" +
"USING DELTA PARTITIONED BY(RideID) LOCATION 'file:///D:\\\\bigdata\\\\detla-lake-with-java\\\\YellowTaxiPartitioned'"
);
spark.sql("DESCRIBE TABLE taxidb.YellowTaxiPartitioned").show();
var df=spark.read().format("delta").table("taxidb.YellowTaxi");
//将数据复制到分区表
df.write().format("delta").mode(SaveMode.Overwrite).save("file:///D:\\\\bigdata\\\\detla-lake-with-java\\\\YellowTaxiPartitioned");
System.out.println("分区查询开始时间(含毫秒): " + sdf.format(new Date()));
spark.sql("SELECT RideID,PickupTime,CabNumber FROM taxidb.YellowTaxiPartitioned").show();
System.out.println("分区查询结束时间(含毫秒): " + sdf.format(new Date()));
spark.close();
}
}
代码主要实现建立一个表名为YellowTaxi,插入5条数据,然后查询YellowTaxi这5条数据,再建立一个表YellowTaxiPartitioned,YellowTaxiPartitioned是分区表。然后从YellowTaxi获取数据并写入到YellowTaxiPartitioned,再查询YellowTaxiPartitioned这5条数据
2、IDEA运行结果如下:
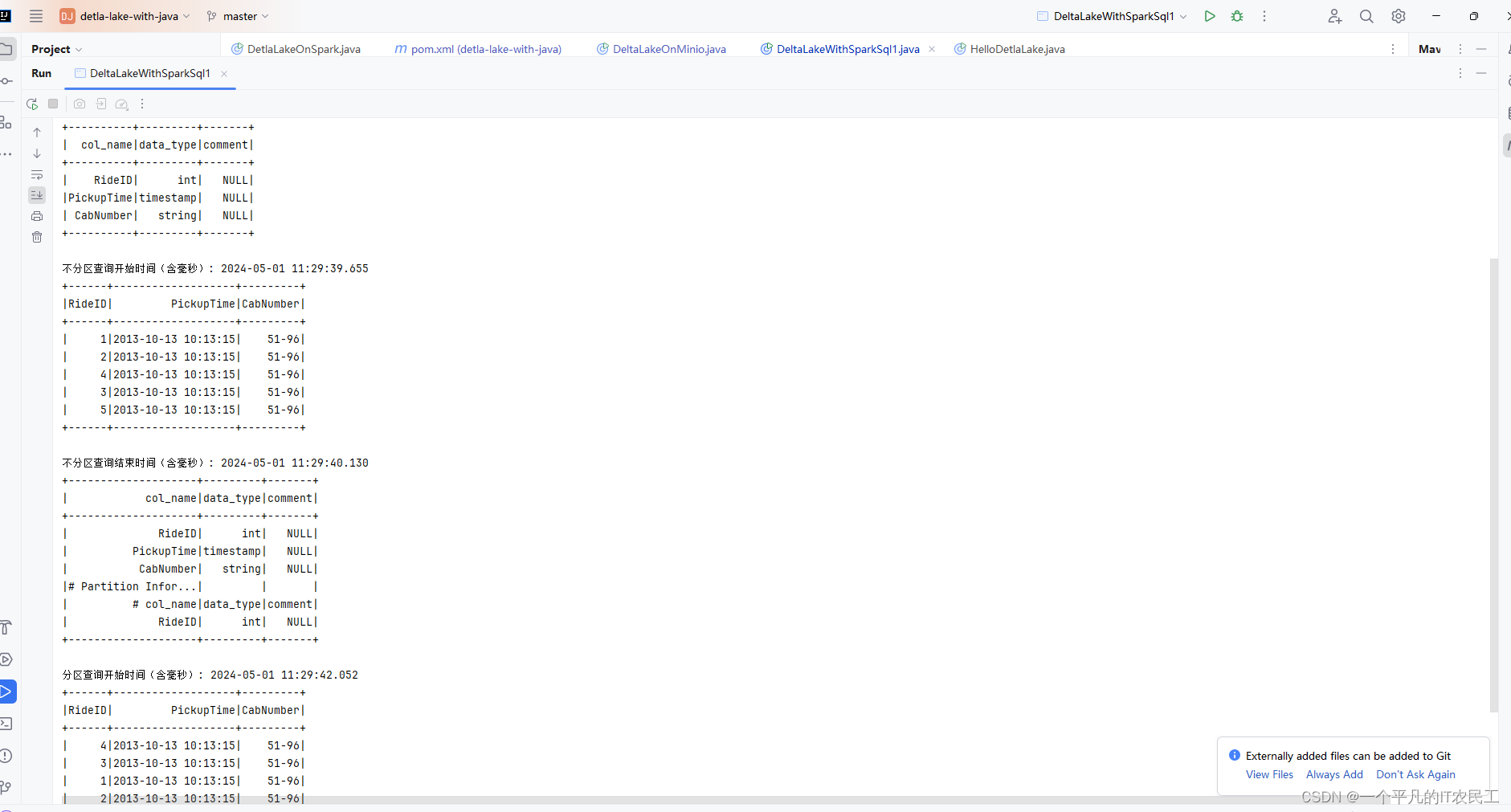
具体文字内容如下,从结果可以看出分区表的查询效率要比不分区表要好,后面建表还是要用分区表。
+----------+---------+-------+
| col_name|data_type|comment|
+----------+---------+-------+
| RideID| int| NULL|
|PickupTime|timestamp| NULL|
| CabNumber| string| NULL|
+----------+---------+-------+
不分区查询开始时间(含毫秒): 2024-05-01 11:29:39.655
+------+-------------------+---------+
|RideID| PickupTime|CabNumber|
+------+-------------------+---------+
| 1|2013-10-13 10:13:15| 51-96|
| 2|2013-10-13 10:13:15| 51-96|
| 4|2013-10-13 10:13:15| 51-96|
| 3|2013-10-13 10:13:15| 51-96|
| 5|2013-10-13 10:13:15| 51-96|
+------+-------------------+---------+
不分区查询结束时间(含毫秒): 2024-05-01 11:29:40.130
+--------------------+---------+-------+
| col_name|data_type|comment|
+--------------------+---------+-------+
| RideID| int| NULL|
| PickupTime|timestamp| NULL|
| CabNumber| string| NULL|
|# Partition Infor...| | |
| # col_name|data_type|comment|
| RideID| int| NULL|
+--------------------+---------+-------+
分区查询开始时间(含毫秒): 2024-05-01 11:29:42.052
+------+-------------------+---------+
|RideID| PickupTime|CabNumber|
+------+-------------------+---------+
| 4|2013-10-13 10:13:15| 51-96|
| 3|2013-10-13 10:13:15| 51-96|
| 1|2013-10-13 10:13:15| 51-96|
| 2|2013-10-13 10:13:15| 51-96|
| 5|2013-10-13 10:13:15| 51-96|
+------+-------------------+---------+
分区查询结束时间(含毫秒): 2024-05-01 11:29:42.198