大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。
本文主要介绍了推开通用人工智能大门,多模态大模型是新一代人工智能技术范式,希望能对学习大模型的同学们有所帮助。
文章目录
- 1. 前言
- 2. 书籍推荐
- 2.1 内容简介
- 2.2 本书作者
- 2.3 本书目录
- 2.4 适合读者
1. 前言
2023年3月15日,OpenAI发布的GPT-4掀起了多模态大模型的研究浪潮,国内诸多研究机构纷纷加入多模态大模型的研发,如智谱清言、华为盘古大模型、腾讯混元大模型、百度文心一言、讯飞星火大模型、百川大模型等。
2024年2月16日,OpenAI再次发布了“从文本到视频”生成式AI模型Sora,其强大的长视频生成能力和物理世界模拟能力,再次激发了研究者对世界模型和通用人工智能的美好憧憬。
多模态大模型作为新一代人工智能的核心技术,将我们带入了人工智能新时代,AIGC、世界模型、具身智能、超级智能体等关键词频繁地出现在各大新闻头条中,人工智能正经历着范式转变。
在全球竞相发展新一代人工智能技术的时代背景下,2024年的《政府工作报告》明确指出要加快发展新质生产力,并首次提出“人工智能+”行动,这标志着人工智能已成为引领新质生产力发展的关键引擎,我国正将“人工智能+”提升至国家层面的战略行动。
1956年起,人工智能的发展跌宕起伏,经历了三次大的浪潮。
-
第一次浪潮是1956—1976年,这期间符号主义(逻辑主义)发展很快;
-
第二个浪潮是1976—2006年,这期间联结主义得到发展;
-
第三次浪潮是2006年至今,深度神经网络再次受到人们的重视和关注。
此后,有两个汹涌澎湃的大浪:
-
第一个大浪是从2012年开始的以人脸识别为代表的计算机视觉的发展,图像分类与视频理解等技术的进步速度令人刮目相看;
-
第二个大浪是2022年年底开始的以ChatGPT为代表的大语言模型技术的发展,创造了自iPhone推出以来计算机技术对社会发展的最大冲击。
有人说,人工智能的第三次浪潮,可能会像蒸汽机、发电机、计算机对于前三次工业革命的贡献一样,成为催生第四次工业革命的核心要素。
什么是新一代人工智能?
新一代人工智能将如何改变我们的生活?
如何在这场技术革命中抢占先机?
这些问题影响着人工智能的发展,更深刻地影响着国家的前途命运。
目前,我国正在全力构筑人工智能发展的先发优势,推动战略性新兴产业融合集群发展,构建新一代信息技术、人工智能、生物技术、新能源、新材料、高端装备、绿色环保等一批新的增长引擎。
随着ChatGPT等多模态大模型面世并迅速风靡全球,我们正面临新一代人工智能技术范式的变革。
其中,多模态大模型,是这场技术范式变革的核心,是迈向通用人工智能(AGI)的关键。
多模态大模型包含的技术分支众多,如自然语言处理、计算机视觉、机器人和具身智能等,加之近年来积累的大量研究成果分散在多个领域、多篇文章之中,表述的习惯、用词、数学变量符号、专业术语等不尽相同,难成体系,给初学者的学习和理解带来一定程度的困难。
2. 书籍推荐
因此,像《多模态大模型:新一代人工智能技术范式》这样一本全面且系统地介绍多模态大模型的书是非常必要的。

当然,完成这样一本书是一项艰巨的任务,需要从大量已有成果中筛选出既有代表性,又能反映新一代人工智能技术范式发展全貌的材料,并将它们提炼组织起来。
2.1 内容简介
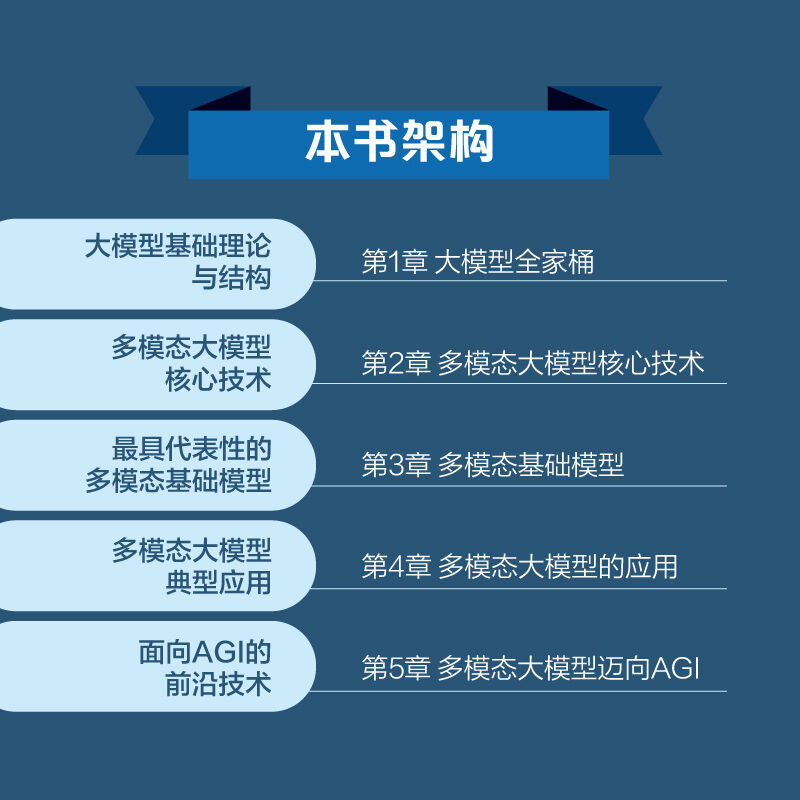
全书内容共5章:
-
第1章引领读者深入探索最具代表性的大模型结构,包括BERT、ChatGPT 和ChatGLM等,为建立对多模态大模型的全面认知打下基础。
-
第2章深度剖析多模态大模型的核心技术,如提示学习、上下文学习、思维链和人类反馈强化学习等,揭示多模态大模型的独特之处和引人入胜的技术内涵。
-
第3章介绍多个具有代表性的多模态基础模型,如CLIP、LLaMA、SAM和PaLM-E等,为读者呈现多样和广泛的技术解决方案。
-
第4章深入分析视觉问答、AIGC和具身智能这三个典型应用,展示多模态大模型在实际场景中的强大能力。
-
第5章探讨实现AGI 的可行思路,包括因果推理、世界模型、超级智能体与具身智能等前沿技术方向。
本书以深入浅出的方式系统地介绍多模态大模型技术方法、开源平台和应用场景的书,并对如何实现AGI提供深入透彻的探讨。
本书的出版,有助于人工智能科研工作者全面了解多模态大模型的特点及潜在发展方向,将对新一代人工智能技术范式和AGI的发展起到重要推动作用。
当然,由于大模型技术的演进变化还在进行,难免有些最新成果未被包含,可以留给未来再版时更新,是遗憾,更是期待。

2.2 本书作者
林倞教授领导的中山大学人机物智能融合实验室长期致力于多模态认知推理、可控内容生成、具身智能与机器人等领域的研究,并深入应用场景打造产品原型,输出大量原创技术及孵化创业团队,许多重要学术和产业成果享誉全球,他的团队创作的这本书也一定干货满满,值得广大读者期待!
本书也得到高文院士作序力荐!
2.3 本书目录
**1 大模型全家桶 1**
1.1 多模态大模型基本概念 3
1.1.1 多模态 4
1.1.2 大模型和基础模型 4
1.1.3 多模态大模型 5
1.2 BERT技术详解 6
1.2.1 模型结构 6
1.2.2 预训练任务 10
1.2.3 下游应用场景 13
1.3 ViT技术详解 14
1.3.1 模型结构 15
1.3.2 预训练任务 17
1.4 GPT系列 19
1.4.1 GPT-1结构详解 20
1.4.2 GPT-2结构详解 23
1.4.3 GPT-3结构详解 24
1.5 ChatGPT简介 28
1.5.1 InstructGPT 28
1.5.2 ChatGPT 32
1.5.3 多模态GPT-4V 37
1.6 中英双语对话机器人ChatGLM 40
1.6.1 ChatGLM-6B模型 41
1.6.2 千亿基座模型GLM-130B的结构 43
1.7 百川大模型 46
1.7.1 预训练 47
1.7.2 对齐 51
1.8 本章小结 53
**2 多模态大模型核心技术 54**
2.1 预训练基础模型 55
2.1.1 基本结构 56
2.1.2 学习机制 57
2.2 预训练任务概述 59
2.2.1 自然语言处理领域的预训练任务 59
2.2.2 计算机视觉领域的预训练任务 59
2.3 基于自然语言处理的预训练关键技术 60
2.3.1 单词表征方法 61
2.3.2 模型结构设计方法 63
2.3.3 掩码设计方法 63
2.3.4 提升方法 64
2.3.5 指令对齐方法 65
2.4 基于计算机视觉的预训练关键技术 67
2.4.1 特定代理任务的学习 68
2.4.2 帧序列学习 68
2.4.3 生成式学习 69
2.4.4 重建式学习 70
2.4.5 记忆池式学习 71
2.4.6 共享式学习 72
2.4.7 聚类式学习 74
2.5 提示学习 75
2.5.1 提示的定义 76
2.5.2 提示模板工程 78
2.5.3 提示答案工程 81
2.5.4 多提示学习方法 82
2.6 上下文学习 85
2.6.1 上下文学习的定义 86
2.6.2 模型预热 86
2.6.3 演示设计 88
2.6.4 评分函数 90
2.7 微调 91
2.7.1 适配器微调 92
2.7.2 任务导向微调 95
2.8 思维链 98
2.8.1 思维链的技术细节 99
2.8.2 基于自洽性的思维链 100
2.8.3 思维树 103
2.8.4 思维图 106
2.9 RLHF 110
2.9.1 RLHF技术分解 111
2.9.2 RLHF开源工具集 114
2.9.3 RLHF的未来挑战 115
2.10 RLAIF 115
2.10.1 LLM的偏好标签化 116
2.10.2 关键技术路线 118
2.10.3 评测118
2.11 本章小结119
**3 多模态基础模型 120**
3.1 CLIP 122
3.1.1 创建足够大的数据集 122
3.1.2 选择有效的预训练方法 123
3.1.3 选择和扩展模型 124
3.1.4 预训练 124
3.2 BLIP 125
3.2.1 模型结构 125
3.2.2 预训练目标函数 126
3.2.3 标注过滤 127
3.3 BLIP-2 128
3.3.1 模型结构 129
3.3.2 使用冻结的图像编码器进行视觉与语言表示学习 129
3.3.3 使用冻结的LLM进行从视觉到语言的生成学习 130
3.3.4 模型预训练 131
3.4 LLaMA 132
3.4.1 预训练数据 132
3.4.2 网络结构 133
3.4.3 优化器 134
3.4.4 高效实现 134
3.5 LLaMA-Adapter 134
3.5.1 LLaMA-Adapter的技术细节 136
3.5.2 LLaMA-Adapter V2 137
3.6 VideoChat 140
3.6.1 VideoChat-Text 142
3.6.2 VideoChat-Embed 143
3.7 SAM 146
3.7.1 SAM任务 149
3.7.2 SAM的视觉模型结构 150
3.7.3 SAM的数据引擎 151
3.7.4 SAM的数据集 152
3.8 PaLM-E 153
3.8.1 模型结构155
3.8.2 不同传感器模态的输入与场景表示 157
3.8.3 训练策略 158
3.9 本章小结 159
**4 多模态大模型的应用 160**
4.1 视觉问答 160
4.1.1 视觉问答的类型 161
4.1.2 图像问答 162
4.1.3 视频问答 179
4.1.4 未来研究方向 190
4.2 AIGC 191
4.2.1 GAN和扩散模型 192
4.2.2 文本生成 194
4.2.3 图像生成 198
4.2.4 视频生成 203
4.2.5 三维数据生成 204
4.2.6 HCP-Diffusion统一代码框架 204
4.2.7 挑战与展望 209
4.3 具身智能 209
4.3.1 具身智能的概念 210
4.3.2 具身智能模拟器 212
4.3.3 视觉探索 216
4.3.4 视觉导航 219
4.3.5 具身问答 223
4.3.6 具身交互 225
4.3.7 存在的挑战 228
4.4 本章小结 231
**5 多模态大模型迈向AGI 232**
5.1 研究挑战 233
5.1.1 缺乏评估准则 233
5.1.2 模型设计准则模糊 233
5.1.3 多模态对齐不佳 234
5.1.4 领域专业化不足 234
5.1.5 幻觉问题 236
5.1.6 鲁棒性威胁 236
5.1.7 可信性问题 238
5.1.8 可解释性和推理能力问题 242
5.2 因果推理 246
5.2.1 因果推理的基本概念 247
5.2.2 因果的类型 251
5.2.3 LLM的因果推理能力 252
5.2.4 LLM和因果发现的关系 254
5.2.5 多模态因果开源框架CausalVLR 255
5.3 世界模型 257
5.3.1 世界模型的概念 258
5.3.2 联合嵌入预测结构 261
5.3.3 Dynalang:利用语言预测未来 264
5.3.4 交互式现实世界模拟器 266
5.3.5 Sora:模拟世界的视频生成模型 267
5.4 超级智能体AGI Agent 271
5.4.1 Agent的定义 272
5.4.2 Agent的核心组件 274
5.4.3 典型的AGI Agent模型 275
5.4.4 AGI Agent的未来展望 284
5.5 基于Agent的具身智能 286
5.5.1 具身决策评测集 287
5.5.2 具身知识与世界模型嵌入 288
5.5.3 具身机器人任务规划与控制 289
5.6 本章小结 296
书籍链接(含目录、参考文献等资源):https://hcplab-sysu.github.io/Book-of-MLM/


2.4 适合读者
本书不仅适合高校相关专业高年级本科生和研究生作为教材使用,更是各类IT从业者的必备参考之作。最终希望能对学习大模型的同学们有所帮助。