若该文为原创文章,转载请注明原文出处。
一、简介
人工智能的发展日新月异,也深刻的影响到人机交互领域的发展。手势动作作为一种自然、快捷的交互方式,在智能驾驶、虚拟现实等领域有着广泛的应用。手势识别的任务是,当操作者做出某个手势动作后,计算机能够快速准确的判断出该手势的类型。本文将使用ModelArts开发训练一个视频动态手势识别的算法模型,对上滑、下滑、左滑、右滑、打开、关闭等动态手势类别进行检测,实现类似隔空手势的功能。
在前面也有使用mediapipe实现类似功能。具体自行参考。
本文章参考CNN-VIT 视频动态手势识别【玩转华为云】-云社区-华为云
二、环境
使用的是AUTODL,配置如下:
镜像:PyTorch 1.7.0 Python 3.8(ubuntu18.04) Cuda 11.0
GPU :RTX 2080 Ti(11GB) * 1升降配置
CPU12 vCPU Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
三、环境搭建
1、创建虚拟环境
conda create -n cnn_hand_gesture_env python=3.82、激活
conda activate cnn_hand_gesture_env3、安装依赖项
conda install cudatoolkit=11.3.1 cudnn=8.2.1 -y --override-channels --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
pip install tensorflow-gpu==2.5.0 -i https://pypi.doubanio.com/simple --user
pip install opencv-contrib-python
pip install imageio
pip install imgaug
pip install tqdm
pip install IPython
pip install numpy==1.19.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplotlib==3.6这里需要注意的是numpy版本和matplotlib版本,tensorflow2.5版本对应的numpy版本是1.19.3
如果版本过高会一直出错错误。
四、数据下载
下载数据使用的是华为云,可以自行下载或联系我。
import os
import moxing as mox
if not os.path.exists('hand_gesture'):
mox.file.copy_parallel('obs://modelbox-course/hand_gesture', 'hand_gesture')五、算法简介
视频动态手势识别算法首先使用预训练网络InceptionResNetV2逐帧提取视频动作片段特征,然后输入Transformer Encoder进行分类。我们使用动态手势识别样例数据集对算法进行测试,总共包含108段视频,数据集包含无效手势、上滑、下滑、左滑、右滑、打开、关闭等7种手势的视频,具体操作流程如下:
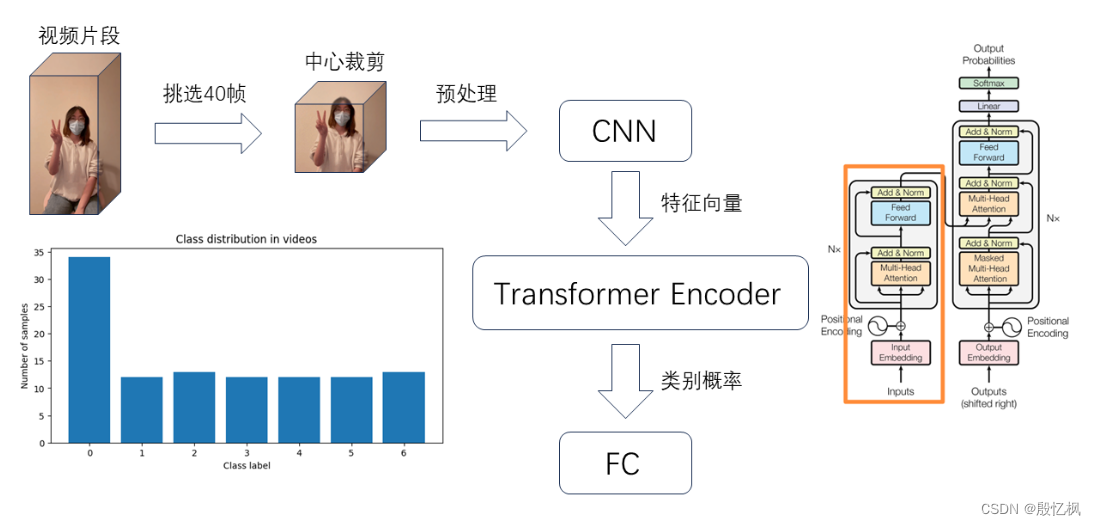
六、流程
1、将采集的视频文件解码抽取关键帧,每隔4帧保存一次,然后对图像进行中心裁剪和预处理
2、创建图像特征提取器,使用预训练模型InceptionResNetV2提取图像特征
3、提取视频特征向量,如果视频不足40帧就创建全0数组进行补白
4、创建VIT Mode
5、视频推理
6、加载VIT Model,获取视频类别索引标签
7、使用图像特征提取器InceptionResNetV2提取视频特征
8、将视频序列的特征向量输入Transformer Encoder进行预测
9、打印模型预测结果
七、测试

Autodl自带有JupyterLab, 直接运行一遍。
代码解析:
1、创建视频输入管道获取视频类别标签
videos = glob.glob('hand_gesture/*.mp4')
np.random.shuffle(videos)
labels = [int(video.split('_')[-2]) for video in videos]
videos[:5], len(videos), labels[:5], len(videos)2、视频抽帧预处理
def load_video(file_name):
cap = cv2.VideoCapture(file_name)
# 每隔多少帧抽取一次
frame_interval = 4
frames = []
count = 0
while True:
ret, frame = cap.read()
if not ret:
break
# 每隔frame_interval帧保存一次
if count % frame_interval == 0:
# 中心裁剪
frame = crop_center_square(frame)
# 缩放
frame = cv2.resize(frame, (IMG_SIZE, IMG_SIZE))
# BGR -> RGB [0,1,2] -> [2,1,0]
frame = frame[:, :, [2, 1, 0]]
frames.append(frame)
count += 1
return np.array(frames) 3、创建图像特征提取器
def get_feature_extractor():
feature_extractor = keras.applications.inception_resnet_v2.InceptionResNetV2(
weights = 'imagenet',
include_top = False,
pooling = 'avg',
input_shape = (IMG_SIZE, IMG_SIZE, 3)
)
preprocess_input = keras.applications.inception_resnet_v2.preprocess_input
inputs = keras.Input((IMG_SIZE, IMG_SIZE, 3))
preprocessed = preprocess_input(inputs)
outputs = feature_extractor(preprocessed)
model = keras.Model(inputs, outputs, name = 'feature_extractor')
return model4、提取视频图像特征
def load_data(videos, labels):
video_features = []
for video in tqdm(videos):
frames = load_video(video)
counts = len(frames)
# 如果帧数小于MAX_SEQUENCE_LENGTH
if counts < MAX_SEQUENCE_LENGTH:
# 补白
diff = MAX_SEQUENCE_LENGTH - counts
# 创建全0的numpy数组
padding = np.zeros((diff, IMG_SIZE, IMG_SIZE, 3))
# 数组拼接
frames = np.concatenate((frames, padding))
# 获取前MAX_SEQUENCE_LENGTH帧画面
frames = frames[:MAX_SEQUENCE_LENGTH, :]
# 批量提取特征
video_feature = feature_extractor.predict(frames)
video_features.append(video_feature)
return np.array(video_features), np.array(labels)5、编码器
# 编码器
class TransformerEncoder(layers.Layer):
def __init__(self, num_heads, embed_dim):
super().__init__()
self.p_embedding = PositionalEmbedding(MAX_SEQUENCE_LENGTH, NUM_FEATURES)
self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim, dropout=0.1)
self.layernorm = layers.LayerNormalization()
def call(self,x):
# positional embedding
positional_embedding = self.p_embedding(x)
# self attention
attention_out = self.attention(
query = positional_embedding,
value = positional_embedding,
key = positional_embedding,
attention_mask = None
)
# layer norm with residual connection
output = self.layernorm(positional_embedding + attention_out)
return output6、训练模式
history = model.fit(train_dataset,
epochs = 1000,
steps_per_epoch = train_count // batch_size,
validation_steps = test_count // batch_size,
validation_data = test_dataset,
callbacks = [checkpoint, earlyStopping, rlp])7、测试
# 视频预测
def testVideo():
test_file = random.sample(videos, 1)[0]
label = test_file.split('_')[-2]
print('文件名:{}'.format(test_file) )
print('真实类别:{}'.format(label_to_name.get(int(label))) )
# 读取视频每一帧
frames = load_video(test_file)
# 挑选前帧MAX_SEQUENCE_LENGTH显示
frames = frames[:MAX_SEQUENCE_LENGTH].astype(np.uint8)
# 保存为GIF
imageio.mimsave('animation.gif', frames, duration=10)
# 获取特征
feat = getVideoFeat(frames)
# 模型推理
prob = model.predict(tf.expand_dims(feat, axis=0))[0]
print('预测类别:')
for i in np.argsort(prob)[::-1][:5]:
print('{}: {}%'.format(label_to_name[i], round(prob[i]*100, 2)))
#return display(Image(open('animation.gif', 'rb').read()))8、源码
import cv2
import glob
import numpy as np
from tqdm import tqdm
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
from collections import Counter
import random
import imageio
from IPython.display import Image
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau
#%matplotlib inline
MAX_SEQUENCE_LENGTH = 40
IMG_SIZE = 299
NUM_FEATURES = 1536
# 图像中心裁剪
def crop_center_square(img):
h, w = img.shape[:2]
square_w = min(h, w)
start_x = w // 2 - square_w // 2
end_x = start_x + square_w
start_y = h // 2 - square_w // 2
end_y = start_y + square_w
result = img[start_y:end_y, start_x:end_x]
return result
# 视频抽帧预处理
def load_video(file_name):
cap = cv2.VideoCapture(file_name)
# 每隔多少帧抽取一次
frame_interval = 4
frames = []
count = 0
while True:
ret, frame = cap.read()
if not ret:
break
# 每隔frame_interval帧保存一次
if count % frame_interval == 0:
# 中心裁剪
frame = crop_center_square(frame)
# 缩放
frame = cv2.resize(frame, (IMG_SIZE, IMG_SIZE))
# BGR -> RGB [0,1,2] -> [2,1,0]
frame = frame[:, :, [2, 1, 0]]
frames.append(frame)
count += 1
return np.array(frames)
# 创建图像特征提取器
def get_feature_extractor():
feature_extractor = keras.applications.inception_resnet_v2.InceptionResNetV2(
weights = 'imagenet',
include_top = False,
pooling = 'avg',
input_shape = (IMG_SIZE, IMG_SIZE, 3)
)
preprocess_input = keras.applications.inception_resnet_v2.preprocess_input
inputs = keras.Input((IMG_SIZE, IMG_SIZE, 3))
preprocessed = preprocess_input(inputs)
outputs = feature_extractor(preprocessed)
model = keras.Model(inputs, outputs, name = 'feature_extractor')
return model
# 提取视频图像特征
def load_data(videos, labels):
video_features = []
for video in tqdm(videos):
frames = load_video(video)
counts = len(frames)
# 如果帧数小于MAX_SEQUENCE_LENGTH
if counts < MAX_SEQUENCE_LENGTH:
# 补白
diff = MAX_SEQUENCE_LENGTH - counts
# 创建全0的numpy数组
padding = np.zeros((diff, IMG_SIZE, IMG_SIZE, 3))
# 数组拼接
frames = np.concatenate((frames, padding))
# 获取前MAX_SEQUENCE_LENGTH帧画面
frames = frames[:MAX_SEQUENCE_LENGTH, :]
# 批量提取特征
video_feature = feature_extractor.predict(frames)
video_features.append(video_feature)
return np.array(video_features), np.array(labels)
# 位置编码
class PositionalEmbedding(layers.Layer):
def __init__(self, seq_length, output_dim):
super().__init__()
# 构造从0~MAX_SEQUENCE_LENGTH的列表
self.positions = tf.range(0, limit=MAX_SEQUENCE_LENGTH)
self.positional_embedding = layers.Embedding(input_dim=seq_length, output_dim=output_dim)
def call(self,x):
# 位置编码
positions_embedding = self.positional_embedding(self.positions)
# 输入相加
return x + positions_embedding
# 编码器
class TransformerEncoder(layers.Layer):
def __init__(self, num_heads, embed_dim):
super().__init__()
self.p_embedding = PositionalEmbedding(MAX_SEQUENCE_LENGTH, NUM_FEATURES)
self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim, dropout=0.1)
self.layernorm = layers.LayerNormalization()
def call(self,x):
# positional embedding
positional_embedding = self.p_embedding(x)
# self attention
attention_out = self.attention(
query = positional_embedding,
value = positional_embedding,
key = positional_embedding,
attention_mask = None
)
# layer norm with residual connection
output = self.layernorm(positional_embedding + attention_out)
return output
def video_cls_model(class_vocab):
# 类别数量
classes_num = len(class_vocab)
# 定义模型
model = keras.Sequential([
layers.InputLayer(input_shape=(MAX_SEQUENCE_LENGTH, NUM_FEATURES)),
TransformerEncoder(2, NUM_FEATURES),
layers.GlobalMaxPooling1D(),
layers.Dropout(0.1),
layers.Dense(classes_num, activation="softmax")
])
# 编译模型
model.compile(optimizer = keras.optimizers.Adam(1e-5),
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics = ['accuracy']
)
return model
# 获取视频特征
def getVideoFeat(frames):
frames_count = len(frames)
# 如果帧数小于MAX_SEQUENCE_LENGTH
if frames_count < MAX_SEQUENCE_LENGTH:
# 补白
diff = MAX_SEQUENCE_LENGTH - frames_count
# 创建全0的numpy数组
padding = np.zeros((diff, IMG_SIZE, IMG_SIZE, 3))
# 数组拼接
frames = np.concatenate((frames, padding))
# 取前MAX_SEQ_LENGTH帧
frames = frames[:MAX_SEQUENCE_LENGTH,:]
# 计算视频特征 N, 1536
video_feat = feature_extractor.predict(frames)
return video_feat
# 视频预测
def testVideo():
test_file = random.sample(videos, 1)[0]
label = test_file.split('_')[-2]
print('文件名:{}'.format(test_file) )
print('真实类别:{}'.format(label_to_name.get(int(label))) )
# 读取视频每一帧
frames = load_video(test_file)
# 挑选前帧MAX_SEQUENCE_LENGTH显示
frames = frames[:MAX_SEQUENCE_LENGTH].astype(np.uint8)
# 保存为GIF
imageio.mimsave('animation.gif', frames, duration=10)
# 获取特征
feat = getVideoFeat(frames)
# 模型推理
prob = model.predict(tf.expand_dims(feat, axis=0))[0]
print('预测类别:')
for i in np.argsort(prob)[::-1][:5]:
print('{}: {}%'.format(label_to_name[i], round(prob[i]*100, 2)))
#return display(Image(open('animation.gif', 'rb').read()))
if __name__ == '__main__':
print('Tensorflow version: {}'.format(tf.__version__))
print('GPU available: {}'.format(tf.config.list_physical_devices('GPU')))
# 创建视频输入管道获取视频类别标签
videos = glob.glob('hand_gesture/*.mp4')
np.random.shuffle(videos)
labels = [int(video.split('_')[-2]) for video in videos]
videos[:5], len(videos), labels[:5], len(videos)
print(labels)
# 显示数据分布情况
counts = Counter(labels)
print(counts)
plt.figure(figsize=(8, 4))
plt.bar(counts.keys(), counts.values())
plt.xlabel('Class label')
plt.ylabel('Number of samples')
plt.title('Class distribution in videos')
plt.show()
# 显示视频
label_to_name = {0:'无效手势', 1:'上滑', 2:'下滑', 3:'左滑', 4:'右滑', 5:'打开', 6:'关闭', 7:'放大', 8:'缩小'}
print(label_to_name.get(labels[0]))
frames = load_video(videos[0])
frames = frames[:MAX_SEQUENCE_LENGTH].astype(np.uint8)
imageio.mimsave('test.gif', frames, durations=10)
print('mim save test.git')
#display(Image(open('test.gif', 'rb').read()))
#frames.shape
print(frames.shape)
feature_extractor = get_feature_extractor()
feature_extractor.summary()
video_features, classes = load_data(videos, labels)
video_features.shape, classes.shape
print(video_features.shape)
print(classes.shape)
# Dataset
batch_size = 16
dataset = tf.data.Dataset.from_tensor_slices((video_features, classes))
dataset = dataset.shuffle(len(videos))
test_count = int(len(videos) * 0.2)
train_count = len(videos) - test_count
dataset_train = dataset.skip(test_count).cache().repeat()
dataset_test = dataset.take(test_count).cache().repeat()
train_dataset = dataset_train.shuffle(train_count).batch(batch_size)
test_dataset = dataset_test.shuffle(test_count).batch(batch_size)
train_dataset, train_count, test_dataset, test_count
print(train_dataset)
print(train_count)
print(test_dataset)
print(test_count)
# 模型实例化
model = video_cls_model(np.unique(labels))
# 打印模型结构
model.summary()
# 保存检查点
checkpoint = ModelCheckpoint(filepath='best.h5', monitor='val_loss', save_weights_only=True, save_best_only=True, verbose=1, mode='min')
# 提前终止
earlyStopping = EarlyStopping(monitor='loss', patience=50, mode='min', baseline=None)
# 减少learning rate
rlp = ReduceLROnPlateau(monitor='loss', factor=0.7, patience=30, min_lr=1e-15, mode='min', verbose=1)
# 开始训练
history = model.fit(train_dataset,
epochs = 1000,
steps_per_epoch = train_count // batch_size,
validation_steps = test_count // batch_size,
validation_data = test_dataset,
callbacks = [checkpoint, earlyStopping, rlp])
# 绘制结果
plt.plot(history.epoch, history.history['loss'], 'r', label='loss')
plt.plot(history.epoch, history.history['val_loss'], 'g--', label='val_loss')
plt.title('VIT Model')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.plot(history.epoch, history.history['accuracy'], 'r', label='acc')
plt.plot(history.epoch, history.history['val_accuracy'], 'g--', label='val_acc')
plt.title('VIT Model')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
# 加载训练最优权重
model.load_weights('best.h5')
# 模型评估
model.evaluate(dataset.batch(batch_size))
# 保存模型
model.save('saved_model')
print('save model')
# 手势识别
# 加载模型
model = tf.keras.models.load_model('saved_model')
# 类别标签
label_to_name = {0:'无效手势', 1:'上滑', 2:'下滑', 3:'左滑', 4:'右滑', 5:'打开', 6:'关闭', 7:'放大', 8:'缩小'}
# 视频推理
for i in range(20):
testVideo()运行后会训练模型

并保存模型测试,
测试结果


如有侵权,或需要完整代码,请及时联系博主。