目录
- 概述
- 一、复合索引
- (一)创建具有复合索引的 DataFrame
- 1. 使用 set_index 方法:
- 2.在创建 DataFrame 时直接指定索引:
- (二)使用复合索引进行数据选择和切片
- (三)重置索引
- (四)复合索引与分组操作
- (五)unstack()函数
- 1.参数
- 2. 将多层索引转换为列
- 2. 将列转换为行索引
- 3. 分组聚合中的使用
- 注意事项:
- 二 、Dataframe分组语法进阶
- (一)分组聚合多种写法
- 1. 写法一:中括号形式, df[列名]
- 2. 写法二:df.列名 直接实现.
- 3. 写法三:结合 agg() 或者 aggregate()函数实现
- 4. 写法四:还可以直接传入 numpy包下的 函数.
- 5. 传入自定义函数
- 6.agg 进行不同的聚合计算.
- (二)分组转换(开窗+具体操作)
- 1. 语法:
- 2.常见用途
- (三)分组过滤
- 1.普通过滤:
- 2. 分组后过滤
- 四、透视表
- (一)语法
- (二)参数
- (三)代码实现
- 下篇内容
概述
经过前几篇的基础语法的学习,您已经掌握了Dataframe的基础操作。在掌握基础操作后,进一步探索其进阶用法能够让你更高效地处理和分析数据。
DataFrame的进阶用法涵盖了数据处理、探索、可视化和集成等多个方面。通过深入学习和实践,你将能够更充分地利用DataFrame的功能和优势,提升数据处理和分析的能力,为数据驱动的决策提供有力支持。(可视化将在matpoltlib中详细介绍)
一、复合索引
在 Pandas 中,DataFrame 的复合索引(也称为多级索引或层次化索引)允许在多个维度上对数据进行索引。这通常通过使用 MultiIndex 来实现,它可以通过多种方式创建,包括从多个列或数组、从元组列表等。复合索引特别有用于在数据集中表示多个分类变量,并允许进行高级的数据选择和聚合。
下面是一些关于如何在 Pandas 中使用 DataFrame 的复合索引的示例和解释:
(一)创建具有复合索引的 DataFrame
可以通过几种方式创建具有复合索引的 DataFrame:
1. 使用 set_index 方法:
可以从一个现有的 DataFrame 的列中创建复合索引。
代码实现:
import pandas as pd
# 创建一个简单的 DataFrame
df = pd.DataFrame({
'A': ['foo', 'foo', 'foo', 'bar', 'bar'],
'B': ['one', 'one', 'two', 'two', 'one'],
'C': ['small', 'large', 'large', 'small', 'small'],
'D': [1, 2, 2, 3, 3],
'E': [2, 4, 5, 5, 6]
})
# 从列 'A' 和 'B' 创建复合索引
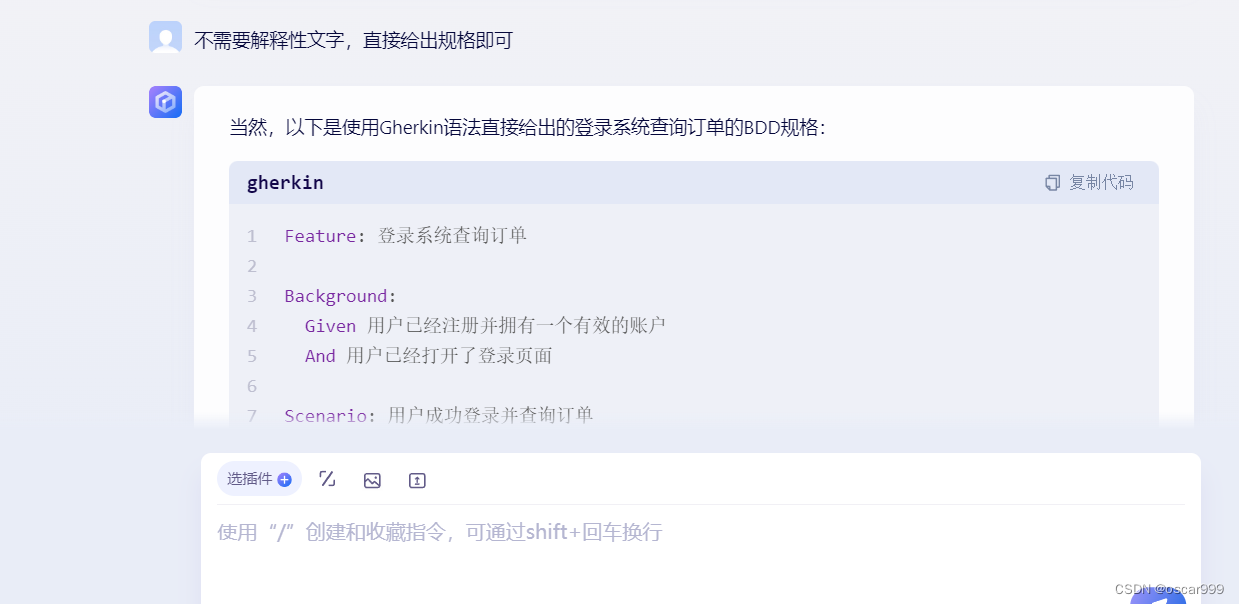
df_multiindex = df.set_index(['A', 'B'])
df_multiindex
运行结果:
2.在创建 DataFrame 时直接指定索引:
在创建 DataFrame 时直接传递一个 MultiIndex。
# 创建多级索引
index = pd.MultiIndex.from_tuples([('foo', 'one'), ('foo', 'two'), ('bar', 'one'), ('bar', 'two')])
# 创建一个简单的 DataFrame,并使用多级索引
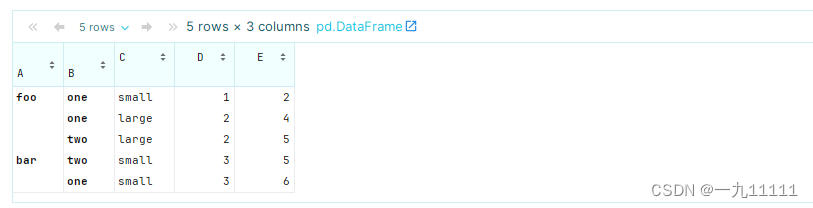
df_multiindex = pd.DataFrame({
'C': ['small', 'large', 'large', 'small'],
'D': [1, 2, 2, 3],
'E': [2, 4, 5, 6]
}, index=index)
df_multiindex
运行结果:
(二)使用复合索引进行数据选择和切片
有了复合索引,可以使用它们来方便地选择数据。
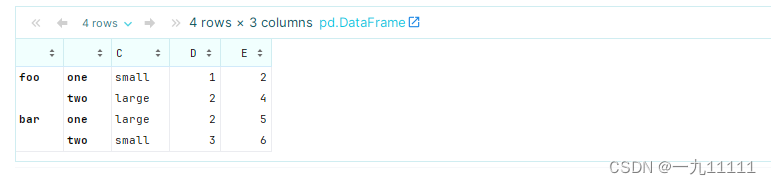
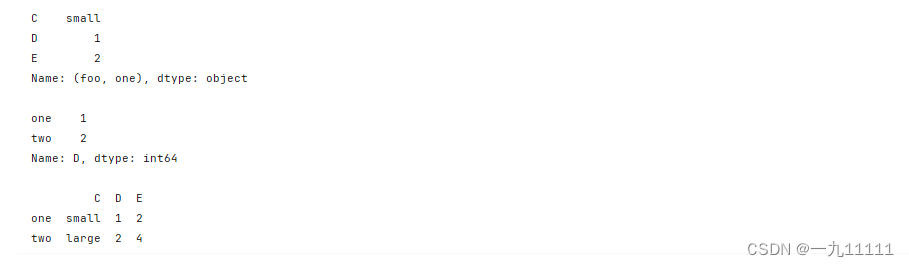
# 选择索引为 ('foo', 'one') 的行
print(df_multiindex.loc[('foo', 'one')])
# 选择所有 'foo' 行的 'D' 列
print(df_multiindex.loc['foo']['D'])
# 选择 'foo' 下 'one' 和 'two' 的所有行
print(df_multiindex.loc[('foo', slice(None))])
运行结果:
(三)重置索引
如果不再需要复合索引,或者想要将其转换回普通的列,可以使用 reset_index 方法。
# 重置索引,将复合索引的级别作为普通列添加回 DataFrame
df_reset = df_multiindex.reset_index()
df_reset
运行结果:
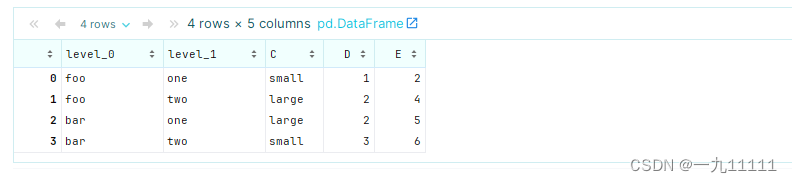
(四)复合索引与分组操作
复合索引与 groupby 方法结合使用时特别强大,因为它允许基于多个键对数据进行分组。
# 使用复合索引进行分组并计算每组的平均值
grouped = df_multiindex.groupby(level=[0, 1]).mean()
grouped
运行结果:
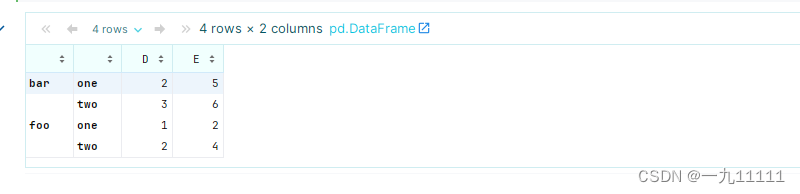
(五)unstack()函数
unstack()函数是用于将一个多级索引(multi-index)的DataFrame或Series从一个层级转换到列中,或者从列中转换到另一个层级。这通常用于数据重塑,使得数据的展现形式更符合分析的需要。
当DataFrame或Series具有一个或多个层级索引时,unstack()函数可以将低层级的索引转换为列标题,同时保持高层级索引作为行索引。反之,如果unstack()函数用于具有多层列标题的DataFrame,则可以将低层级的列标题转换为行索引。
1.参数
-
level:整数或字符串,可选参数。指定要解包的层级。如果省略此参数,将解包所有分层。通过指定level,你可以控制将哪一层级的索引横向展开,而其余层级的索引保持不变。
-
fill_value:可选参数。用于替换缺失值的值。在解包索引的过程中,可能会出现某些位置没有对应数据的情况,此时可以使用fill_value参数来指定一个默认值填充这些缺失位置。
-
dropna:布尔值,可选参数。指定是否删除那些只包含缺失值的列。当解包索引后,有些列可能全部为缺失值,通过设置dropna=True,可以自动删除这些列,使数据更加整洁。
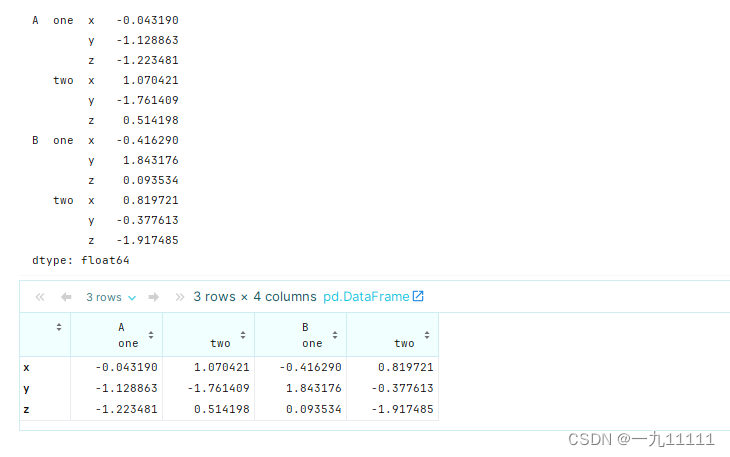
2. 将多层索引转换为列
# 创建一个具有多层索引的 DataFrame
index = pd.MultiIndex.from_product([['A', 'B'], ['one', 'two'], ['x', 'y', 'z']])
data = pd.Series(np.random.randn(12), index=index)
print(data)
df = data.unstack([0, 1])
df
在这个示例中,我们创建了一个具有三层索引的Series对象,并使用unstack([0, 1])将前两层索引转换为列标题。
2. 将列转换为行索引
df
#%%
# 创建一个具有多层索引的DataFrame
arrays = [np.array(['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux']),
np.array(['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']),
np.array(['small', 'large', 'large', 'small', 'small', 'large', 'large', 'small'])]
# 将这些数组转换为MultiIndex
index = pd.MultiIndex.from_arrays(arrays, names=('first', 'second', 'third'))
# 创建一个简单的DataFrame
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
print("原始DataFrame:")
print(df)
# 使用unstack将'third'层级的索引转换为列
df_unstacked = df.unstack('third')
print("\n使用unstack后的DataFrame:")
df_unstacked
运行结果:
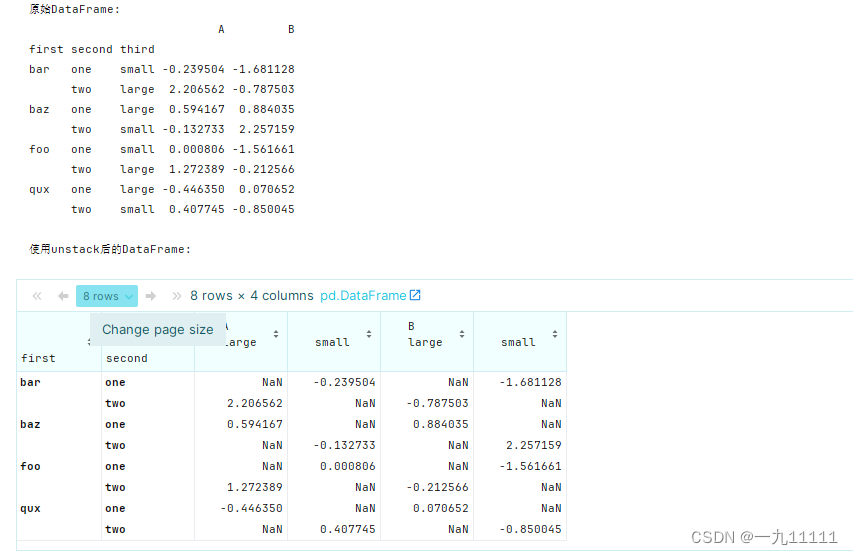
在这个示例中,我们创建了一个具有三层索引的DataFrame,并使用unstack(‘third’)将第三层索引(‘third’)转换为列。
3. 分组聚合中的使用
unstack() 可以用来将分组后的结果从层级索引的形式转换为更宽格式的表格。
# 创建一个示例 DataFrame
data = {
'A': ['foo', 'foo', 'foo', 'bar', 'bar'],
'B': ['one', 'one', 'two', 'two', 'one'],
'C': ['small', 'large', 'large', 'small', 'small'],
'D': [1, 2, 2, 3, 3],
'E': [2, 4, 5, 5, 6]
}
df = pd.DataFrame(data)
# 根据 A 和 B 列进行分组,并对 D 列求和
grouped = df.groupby(['A', 'B']).sum()
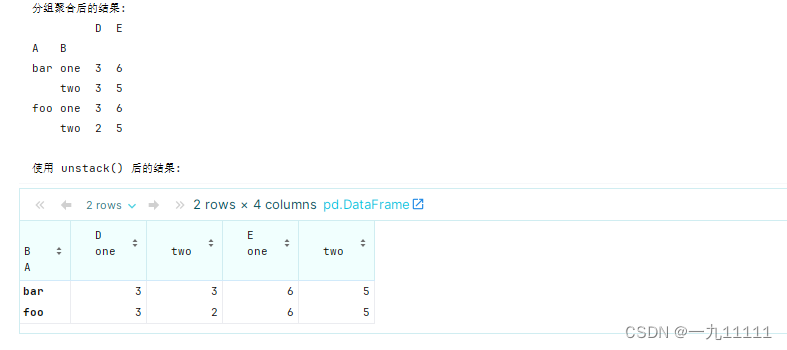
print("分组聚合后的结果:")
print(grouped)
# 使用 unstack() 将 B 列的层级索引转换为列
unstacked = grouped.unstack('B')
print("\n使用 unstack() 后的结果:")
print(unstacked)
代码实现:
注意事项:
- unstack()函数不会修改原始DataFrame或Series,而是返回一个新的对象。
- 如果level参数指定的层级不存在,会引发KeyError。
- 如果解包后的数据结构中存在重复的列标题,Pandas会保留所有的数据,并使用多级列标题来区分。
二 、Dataframe分组语法进阶
(一)分组聚合多种写法
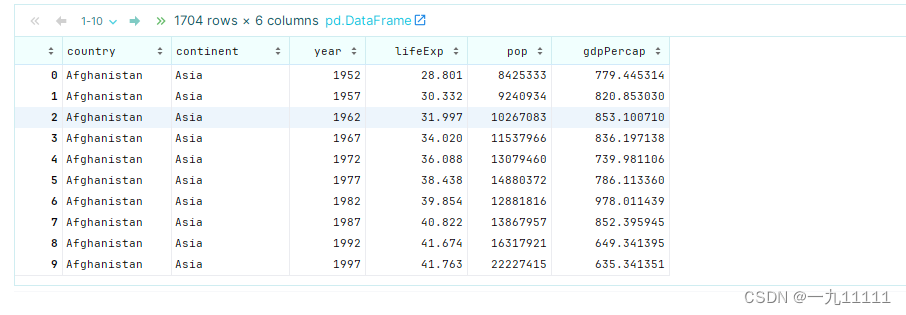
首先我们先导入数据
import numpy as np
data = pd.read_csv('/export/data/pandas_data/gapminder.tsv',sep='\t')
data
数据样式:
1. 写法一:中括号形式, df[列名]
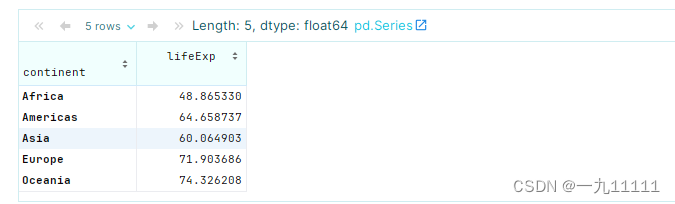
# 求不同洲的平均寿命
data.groupby('continent')['lifeExp'].mean()
运行结果:
2. 写法二:df.列名 直接实现.
# 写法2: df.列名 直接实现.
data.groupby('continent').lifeExp.mean()
运行结果:
3. 写法三:结合 agg() 或者 aggregate()函数实现
这两个函数完全一样, 并无任何区别.
# 写法3: 结合 agg() 或者 aggregate()函数实现, 这两个函数完全一样, 并无任何区别.
data.groupby('continent').lifeExp.agg('mean') # 这个mean是 Pandas中的mean()函数, 要加: 引号包裹
data.groupby('continent').lifeExp.aggregate('mean')
# 上述格式变形写法: {要操作的列1: 聚合函数, 要操作的列2: 聚合函数...}
data.groupby('continent').agg({'lifeExp':'mean'})
data.groupby('continent').aggregate({'lifeExp':'mean'})
4. 写法四:还可以直接传入 numpy包下的 函数.
# 写法4: 还可以直接传入 numpy包下的 函数.
data.groupby('continent').lifeExp.agg(np.mean) # 这里的np.mean是 Numpy中的mean()函数对象, 不要加引号
data.groupby('continent').agg({'lifeExp': np.mean})
5. 传入自定义函数
# 写法5: 传入自定义函数, 实现: 计算平均值.
# 1. 自定义函数, 用于计算 某列值 的平均值.
def my_mean(col):
# 该列平均值 = 该列数据和 / 该列数据个数
return col.sum() / col.size # Series中: sum()函数, size: 属性
# 2. groupby分组聚合时, 可以传入: 自定义函数.
data.groupby('continent').lifeExp.agg(my_mean) # 这里传入的是: 自定义函数对象, 不加引号.
data.groupby('continent').agg({'lifeExp': my_mean})
运行结果:
6.agg 进行不同的聚合计算.
# 写法7: 分组后, 可以针对于 多列数据, 进行不同的聚合计算.
# 需求: 根据年份分组, 计算: lifeExp(预期寿命)的平均值, pop(平均人口)的 最大值, gdpPercap(平均GDP) 的 中位数.
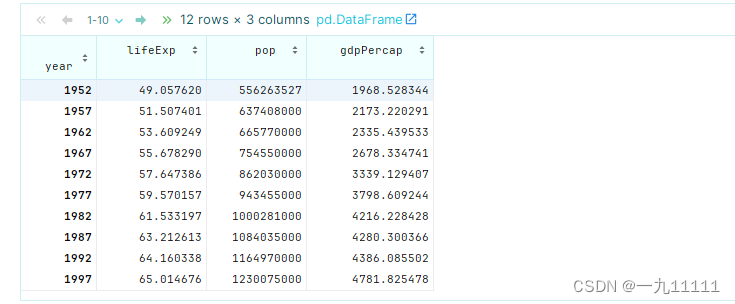
data.groupby('year').agg({'lifeExp': 'mean', 'pop': 'max', 'gdpPercap': 'median'})
运行结果:
(二)分组转换(开窗+具体操作)
transform()方法在Pandas库中是一个强大的工具,尤其在分组计算时。当对数据进行分组操作后,transform()方法允许对每个分组应用一个函数,并返回与原始DataFrame形状相同的结果。这对于在分组后进行标准化、填充缺失值、计算分组统计量等操作非常有用。
1. 语法:
当与groupby()结合使用时,transform()的语法基本保持不变:
grouped.transform(func, *args, **kwargs)
其中,grouped是一个通过groupby()方法得到的分组对象,func是你想要应用于每个分组的函数。
2.常见用途
- 标准化:在每个分组内计算均值和标准差,然后用原始值减去均值并除以标准差,从而得到标准化的数据。
- 填充缺失值:在每个分组内计算非缺失值的均值或中位数,并用这个值填充该分组内的缺失值。
计算分组统计量:计算每个分组的均值、总和、最大值、最小值等,并将这些统计量广播回原始形状。
示例:
假设我们有一个包含销售数据的DataFrame,其中包含产品类别、销售额和利润等列,我们想要计算每个产品类别的销售额均值,并将这个均值填充到该类别下的每一行中:
# 创建一个简单的DataFrame
df = pd.DataFrame({
'category': ['A', 'A', 'B', 'B', 'C', 'C'],
'sales': [100, 150, 75, 125, 50, 70],
'profit': [20, 30, 15, 25, 10, 14]
})
print('原表:')
print(df)
# 使用groupby和transform计算每组的销售额均值,并将结果广播回原始形状
df['sales_mean_per_category'] = df.groupby('category')['sales'].transform('mean')
print('转换之后的表:')
df
运行结果:
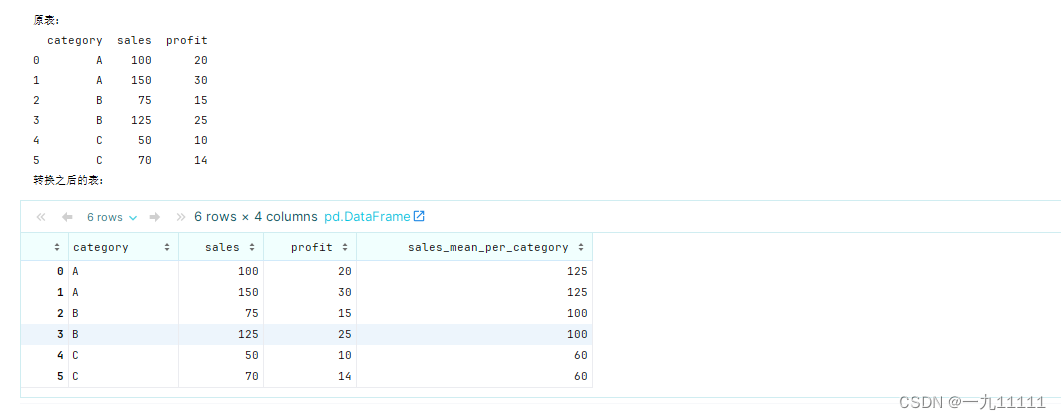
输出将是一个新的DataFrame,其中包含一个额外的列sales_mean_per_category,该列包含了每个产品类别的销售额均值,并且这个均值被填充到了该类别下的每一行中。
通过transform()方法,你可以轻松地在分组后对数据进行各种转换和操作,而无需改变原始数据的形状或结构。这使得它在数据清洗、预处理和特征工程等任务中非常有用。
(三)分组过滤
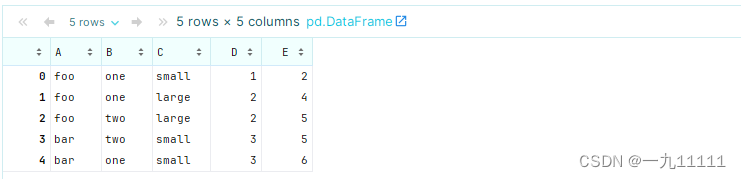
首先我们创建一个Dataframe
# 示例DataFrame
import pandas as pd
df = pd.DataFrame({
'A': ['foo', 'foo', 'foo', 'bar', 'bar'],
'B': ['one', 'one', 'two', 'two', 'one'],
'C': ['small', 'large', 'large', 'small', 'small'],
'D': [1, 2, 2, 3, 3],
'E': [2, 4, 5, 5, 6]
})
df
运行结果:
1.普通过滤:
常见的是使用query或布尔索引来直接过滤DataFrame。
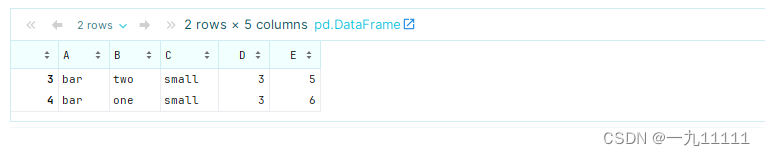
- 使用query方法过滤:
# 选择列'D'的值大于2的行
filtered_df = df.query('D > 2')
filtered_df
运行结果:
- 使用布尔索引过滤
# 选择列'D'的值大于2的行
filtered_df = df[df['D'] > 2]
filtered_df
运行结果:

2. 分组后过滤
分组后过滤组可用filter函数传入一个lambda函数或自定义函数,进行组的过滤
- 传入lambda函数
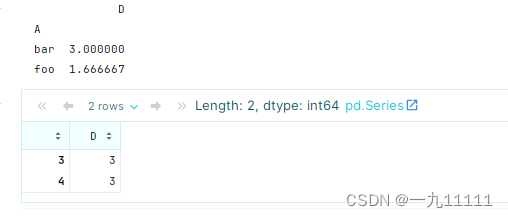
# 查看按A分组的组内Dde平均值
c = df.groupby('A')[['D']].mean()
print(c)
# 过滤出按A分组的组内的平均值大于2的
df.groupby('A')['D'].filter(lambda x:x.mean()>2 )
运行结果:
- 传入自定义函数
注意,这里使用自定义函数的时候一定要return一个bool值,否则会报错
# 定义一个自定义函数,功能是guol出平均值大于2的
def my_func(col):
if col.mean()>2:
return True
return False
df.groupby('A')['D'].filter(my_func)
运行结果:
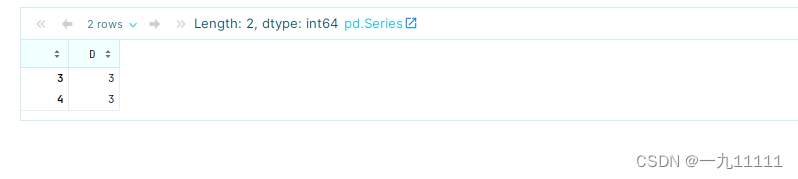
注意:
无论是apply函数还是transform函数还是filter函数,在传入一个自定函数的时候,只需要传入函数名,而非函数名+()
四、透视表
pivot_table函数是用于创建数据透视表(pivot table)的强大工具。数据透视表是一种可以对数据进行汇总、分析、探索和呈现的有效方式,它允许用户根据一个或多个键对数据进行重排,并对结果进行聚合运算。功能的同于excel的数据透视表相同。
(一)语法
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
(二)参数
- data: DataFrame
要进行透视的数据源。通常是一个DataFrame对象。 - values: list-like, optional
要进行聚合计算的列名。如果不提供此参数,那么会使用所有数值型列。 - index: list-like, optional
用作透视表行索引的列名或列名列表。 - columns: list-like, optional
用作透视表列标签的列名或列名列表。 - aggfunc: function, str, list, or dict, default ‘mean’
聚合函数或函数列表,用于计算每个组(由index和columns定义)的聚合值。可以是’mean’, ‘sum’, ‘count’, ‘min’, ‘max’, ‘var’, 'std’等字符串,或者是一个自定义函数。如果传入一个函数列表,那么会返回一个多层级的列标签。 - fill_value: scalar, default None
用于填充缺失值的值。如果数据中没有缺失值,则此参数无效。 - margins: bool, default False
是否添加所有行/列的小计和总计。如果为True,则会在透视表的底部和右侧添加额外的行和列,显示聚合后的总计值。 - dropna: bool, default True
是否删除包含缺失值的行。如果为True,则任何在index或columns中包含缺失值的行都会被排除在外。 - margins_name: str, default ‘All’
边际(小计和总计)的名称。当margins=True时,此参数定义了总计行和列的名称。
(三)代码实现
- 创建Dataframe表
import pandas as pd
data = {
'year': [2020, 2020, 2021, 2021, 2021],
'product': ['A', 'B', 'A', 'B', 'C'],
'region': ['North', 'North', 'South', 'South', 'East'],
'sales': [100, 200, 150, 300, 50]
}
df = pd.DataFrame(data)
df
数据样式:

- 基本透视表
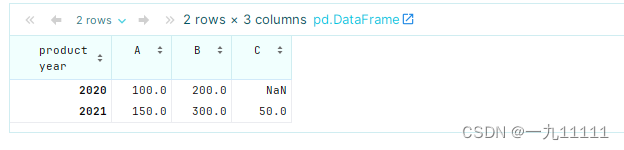
# 每个商品每年的总的销售数量
pivot_table = df.pivot_table(values='sales', index='year', columns='product', aggfunc='sum')
pivot_table
运行结果:
- 使用多层索引和列
# 每个商品每年在每个地区的销售总量
pivot_table = df.pivot_table(values='sales', index=['year', 'region'], columns='product', aggfunc='sum')
pivot_table
运行结果:
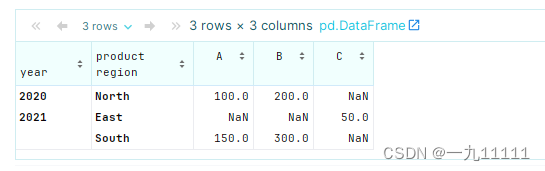
在这个例子中,我们添加了region作为第二层索引。
- 使用多个聚合函数
# 求每个产品,每年的销售总量和平均销售量
pivot_table = df.pivot_table(values='sales', index='year', columns='product', aggfunc=['sum', 'mean'])
pivot_table
运行结果:
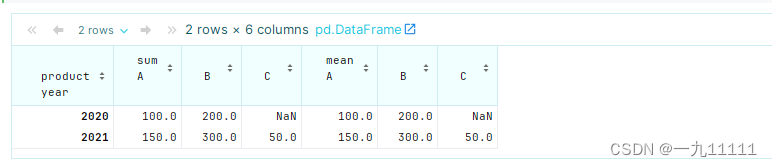
这里我们使用了两个聚合函数:sum和mean。这将产生一个多层级的列标签。
- 填充缺失值
# 将缺失值填充为0
pivot_table = df.pivot_table(values='sales', index='year', columns='product', aggfunc='sum', fill_value=0)
pivot_table
运行结果:
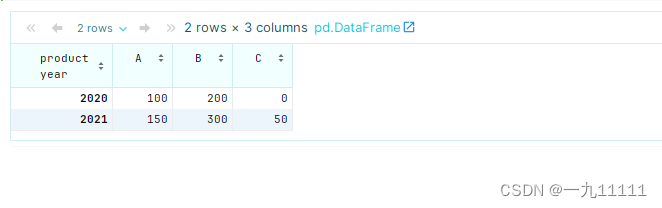
如果某些组合在数据中没有出现,则可以使用fill_value参数为这些缺失的组合填充一个默认值。
- 添加边际
margins=True会在透视表的底部和右侧添加所有行和列的小计。
pivot_table = df.pivot_table(values='sales', index='year', columns='product', aggfunc='sum', margins=True)
pivot_table
运行结果:
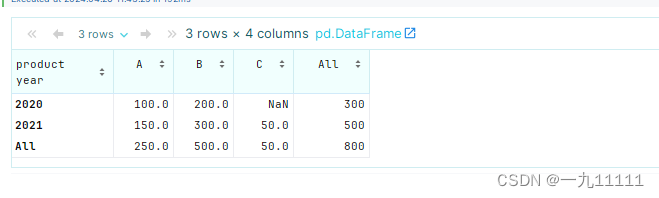
通过调整index、columns和aggfunc等参数,你可以创建出各种复杂的数据透视表,以满足不同的数据分析需求。
下篇内容
Pandas的时间转换