文章目录
- 六、string类
- 7. string类的模拟实现
- 未完待续
六、string类
7. string类的模拟实现
我们在上文简单实现了string类的构造函数。不知道大家有没有发现一个问题,我们在进行实现无参的构造函数时,初始化列表将 _str 初始化为 nullptr 了,但是这里真的可以初始化为 nullptr 吗?要仔细想一想,当不提供参数的时候,我们是应该得到一个空指针还是一个空串?对,我们应该是得到一个空串,空串末尾是携带 ‘\0’ 的。我们在修改上次的问题的同时,再将两个函数给合并成一个缺省函数。
// string.h 头文件下
#pragma once
#include<iostream>
namespace my
{
class string
{
public:
// 默认是空串而不是空指针
string(const char* str = "")
:_size(strlen(str))
{
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
}
OK,接下来实现析构函数。
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
析构函数没什么好说的,接下来我们来实现一下字符串的遍历。
首先要实现的就是 size 函数了,遍历需要知道字符串的长度。
// 加 const 使其成为 const 成员函数,使 const 对象也能调用这个函数
size_t size() const
{
return _size;
}
遍历方法①:下标 + [] 遍历
// 引用返回,可读可写
inline char& operator[](size_t pos)
{
// 越界检查
// assert函数需要: #include<assert.h>
assert(pos < _size);
// _str是字符数组
return _str[pos];
}
写了这么多了,我们来使用一下。
// test.cpp 源文件下
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"
using namespace my;
int main()
{
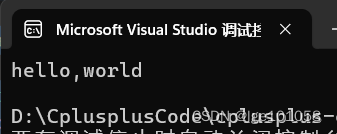
string s("hello,world");
for (size_t i = 0; i < s.size(); ++i)
{
std::cout << s[i];
}
std::cout << std::endl;
return 0;
}
nice!但是,我们要知道,下标访问支持可读可写,但是const对象不支持,所以刚刚那个函数不支持const对象,于是我们得重载一个针对于const对象的下标访问函数。
// 针对 const对象 的可读不可写,加 & 是为了减少拷贝
inline const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
访问容量函数:
size_t capacity() const
{
return _capacity;
}
遍历方法②:迭代器。我们之前介绍了,迭代器是类似指针的东西,但是它不一定是指针! 但是我们这里可以就把它当作指针来实现。
// string.h 头文件下
#pragma once
#include<iostream>
#include<assert.h>
namespace my
{
class string
{
public:
// 底层是原生指针的迭代器
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
// 默认是空串而不是空指针
string(const char* str = "")
:_size(strlen(str))
{
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
// 加 const 使其成为 const 成员函数,使 const 对象也能调用这个函数
size_t size() const
{
return _size;
}
// 引用返回,可读可写
inline char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
// 针对 const对象 的可读不可写,加 & 是为了减少拷贝
inline const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
size_t capacity() const
{
return _capacity;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
}
来跑一跑:
// test.cpp源文件下
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"
using namespace my;
int main()
{
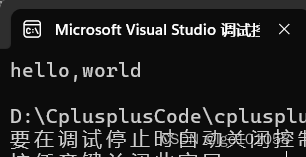
string s("hello,world");
//for (size_t i = 0; i < s.size(); ++i)
//{
// std::cout << s[i];
//}
//std::cout << std::endl;
for (auto e : s)
{
std::cout << e;
}
std::cout << std::endl;
return 0;
}
由于 范围for 底层就是替换成迭代器的形式,所以这里使用 范围for 来验证迭代器的实现。
没问题,接下来就是为 const对象 来实现专门的 const_iterator 了。
typedef const char* const_iterator;
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
反向迭代器咱们就不去实现了,咱们学到后面了在谈。
接下来实现 string类 的修改。①push_back 尾插。首先先实现扩容函数 reserve 。
void reserve(size_t n)
{
// 只有要扩容的大小比当前容量大才能扩容
if (n > _capacity)
{
// 开辟新空间,考虑 '\0' 的空间
char* tmp = new char[n + 1];
// 拷贝
strcpy(tmp, _str);
// 释放旧空间
delete[] _str;
// 更改指针指向
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size == _capacity)
{
// 扩容2倍
reserve(_capacity == 0 ? 4 : 2 * _capacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
接下来是②append追加函数。
void append(const char* str)
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
// 从末尾开始,拷贝新字符串
strcpy(_str + _size, str);
_size += len;
}
接下来是③重载 +=
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
由于我们还没有实现流插入和流提取函数,所以我们无法直接输出我们的字符串,但是我们可以实现 c_str() 函数,这个函数的作用是将 string类型 的字符串转换成C语言的字符数组。
char* c_str()
{
// 返回字符数组就好
return _str;
}
再来跑跑:
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"
using namespace my;
int main()
{
string s("hello,world");
//for (size_t i = 0; i < s.size(); ++i)
//{
// std::cout << s[i];
//}
//std::cout << std::endl;
/*for (auto e : s)
{
std::cout << e;
}
std::cout << std::endl;*/
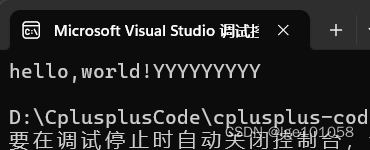
s += '!';
s += "YYYYYYYYY";
std::cout << s.c_str() << std::endl;
return 0;
}
④insert 和 erase
// 在 pos 位置插入一个字符
void insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
// 扩容2倍
reserve(_capacity == 0 ? 4 : 2 * _capacity);
}
// 小细节
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
}
注意细节:end 选择的是每次右移的移动终点,如果是起点,会写成 end = _size; end >= pos 当 pos 等于 0 时,由于end和pos都是无符号整形,end不可能比 0 小,所以就会死循环,当end处于右侧时则完美解决了这个问题。
// 从 pos 开始,删除 len 个字符,如果 len 是 npos ,则全删
void erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
// pos + len >= _size 可能会溢出
if (len == npos || len >= _size - pos)
{
_str[pos] = '\0';
_size = pos;
}
strcpy(_str + pos + len, _str + pos);
_size -= len;
}
跑跑看:
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"
using namespace my;
int main()
{
string s("hello,world");
//for (size_t i = 0; i < s.size(); ++i)
//{
// std::cout << s[i];
//}
//std::cout << std::endl;
/*for (auto e : s)
{
std::cout << e;
}
std::cout << std::endl;*/
//s += '!';
//s += "YYYYYYYYY";
//std::cout << s.c_str() << std::endl;
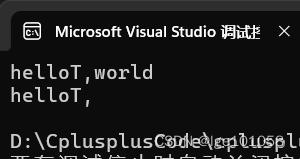
s.insert(5, 'T');
std::cout << s.c_str() << std::endl;
s.erase(8);
std::cout << s.c_str() << std::endl;
return 0;
}
接下来是 resize 。
void resize(size_t n, char ch = '\0')
{
// 比 size 小则删除
if (n <= _size)
{
_str[n] = '\0';
_size = n;
}
else
{
// 比size大则填充
reserve(n);
for (size_t i = _size; i < n; ++i)
{
_str[i] = ch;
}
_str[n] = '\0';
_size = n;
}
}
再看看:
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"
using namespace my;
int main()
{
string s("hello,world");
//for (size_t i = 0; i < s.size(); ++i)
//{
// std::cout << s[i];
//}
//std::cout << std::endl;
/*for (auto e : s)
{
std::cout << e;
}
std::cout << std::endl;*/
//s += '!';
//s += "YYYYYYYYY";
//std::cout << s.c_str() << std::endl;
//s.insert(5, 'T');
//std::cout << s.c_str() << std::endl;
//s.erase(8);
//std::cout << s.c_str() << std::endl;
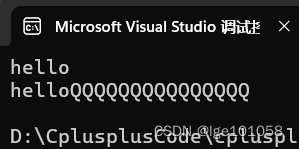
s.resize(5);
std::cout << s.c_str() << std::endl;
s.resize(20, 'Q');
std::cout << s.c_str() << std::endl;
return 0;
}
写了这么多成员函数,但是没有写拷贝构造函数。有人可能会说哈,拷贝构造函数是默认成员函数,不写编译器也会自动生成,我们不需要写,但是真的不需要写吗?我们之前说过,编译器默认生成的拷贝构造都是浅拷贝,按字节一个一个拷贝,我们来看看下图:
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"
using namespace my;
int main()
{
string s("hello,world");
// 拷贝构造
string s2(s);
return 0;
}
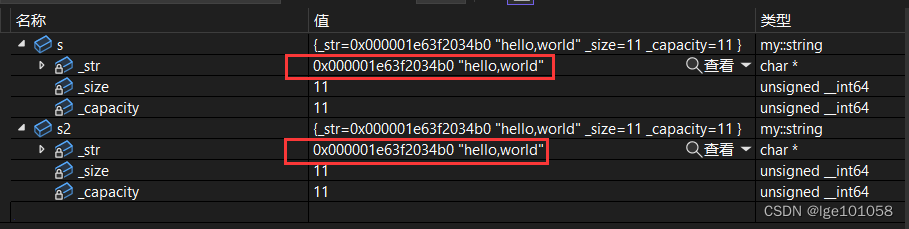
我们发现这里拷贝构造出来的 s2 和 s 的 _str 指向同一块空间,这就是浅拷贝导致的,这样的情况会使:操作其中一个,另一个也会改变,同一块空间会被析构两次,产生报错。所以说默认的拷贝构造函数不一定好,我们需要自己实现一个深拷贝的拷贝构造函数。
string(const string& s)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}
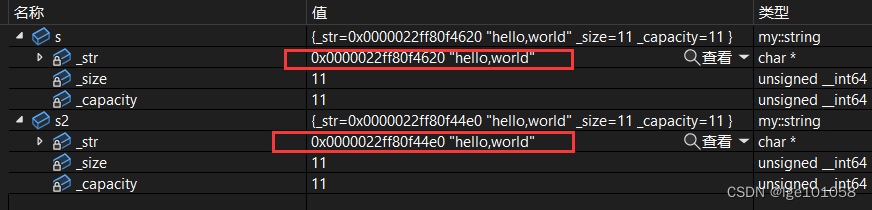
不一样了。