1. 对于高方差(过拟合),有以下几种方式:
-
获取更多的数据,使得训练能够包含所有可能出现的情况
-
正则化(Regularization)
-
寻找更合适的网络结构
2. 对于高偏差(欠拟合),有以下几种方式:
-
扩大网络规模,如添加隐藏层或者神经元数量
-
寻找合适的网络架构,使用更大的网络结构,如AlexNet
-
训练时间更长一些
3. 正则化的方式(防止过拟合)
-
L2正则化(L1正则化使用很少)
-
Dropout正则化
-
早停止法(Early Stopping)
-
数据增强(增加数据维度或者变换数据形状)
一 偏差与方差
1 数据集划分
首先我们对机器学习当中涉及到的数据集划分进行一个简单的复习
-
训练集(train set):用训练集对算法或模型进行训练过程;
-
验证集(development set):利用验证集(又称为简单交叉验证集,hold-out cross validation set)进行交叉验证,选择出最好的模型;
-
测试集(test set):最后利用测试集对模型进行测试,对学习方法进行评估。
在小数据量的时代,如 100、1000、10000 的数据量大小,可以将数据集按照以下比例进行划分:
-
无验证集的情况:70% / 30%
-
有验证集的情况:60% / 20% / 20%
而在如今的大数据时代,拥有的数据集的规模可能是百万级别的,所以验证集和测试集所占的比重会趋向于变得更小。
-
100 万数据量:98% / 1% / 1%
-
超百万数据量:99.5% / 0.25% / 0.25%
以上这些比例可以根据数据集情况选择。
2 偏差与方差的意义
“偏差-方差分解”(bias-variance decomposition)是解释学习算法泛化性能的一种重要工具。
泛化误差可分解为偏差、方差与噪声,泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。
-
偏差:度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
-
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
-
噪声:表达了在当前任务上任何学习算法所能够达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
那么偏差、方差与我们的数据集划分到底有什么关系呢?
-
1、训练集的错误率较小,而验证集/测试集的错误率较大,说明模型存在较大方差,可能出现了过拟合
-
2、训练集和测试集的错误率都较大,且两者相近,说明模型存在较大偏差,可能出现了欠拟合
-
3、训练集和测试集的错误率都较小,且两者相近,说明方差和偏差都较小,这个模型效果比较好。
所以我们最终总结,方差一般指的是数据模型得出来了,能不能对未知数据的扰动预测准确。而偏差说明在训练集当中就已经误差较大了,基本上在测试集中没有好的效果。
所以如果我们的模型出现了较大的方差或者同时也有较大的偏差,该怎么去解决?
3 解决方法
对于高方差(过拟合),有以下几种方式:
-
获取更多的数据,使得训练能够包含所有可能出现的情况
-
正则化(Regularization)
-
寻找更合适的网络结构
对于高偏差(欠拟合),有以下几种方式:
-
扩大网络规模,如添加隐藏层或者神经元数量
-
寻找合适的网络架构,使用更大的网络结构,如AlexNet
-
训练时间更长一些
不断尝试,直到找到低偏差、低方差的框架。
二 正则化(Regularization)
正则化,即在损失函数中加入一个正则化项(惩罚项),惩罚模型的复杂度,防止网络过拟合
1 逻辑回归的L1与L2正则化
L1是直线距离, L2是平方再开方
由于 L1 正则化最后得到 w 向量中将存在大量的 0,使模型变得稀疏化,因此 L2 正则化更加常用。
2 正则化项的理解
在损失函数中增加一项,那么其实梯度下降是要减少损失函数的大小,对于L2或者L1来讲都是要去减少这个正则项的大小,那么也就是会减少W权重的大小。这是我们一个直观上的感受。
3 神经网络中的正则化

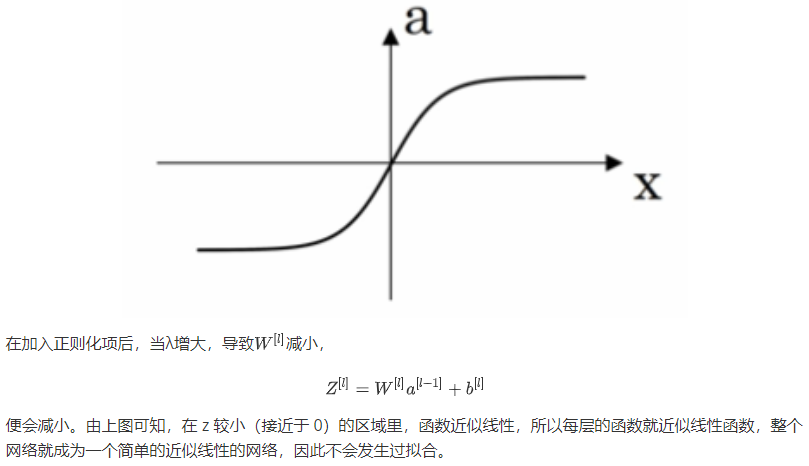
4 正则化为什么能够防止过拟合
正则化因子设置的足够大的情况下,为了使成本函数最小化,权重矩阵 W 就会被设置为接近于 0 的值,直观上相当于消除了很多神经元的影响,那么大的神经网络就会变成一个较小的网络。
三 Dropout正则化
Droupout:随机的对神经网络每一层进行丢弃部分神经元操作。
对于网络的每一层会进行设置保留概率,即keep_prob。假设keep_prob为0.8,那么也就是在每一层所有神经元有20% 的概率直接失效,可以理解为0.
1 Inverted droupout
这种方式会对每层进行如下代码操作
# 假设设置神经元保留概率
keep_prob = 0.8
# 随机建立一个标记1 or 0的矩阵,表示随机失活的单元,占比20%
dl = np.random.rand(al.shape[0], al.shape[1]) < keep_prob
# 让a1对应d1的为0地方结果为0
al = np.multiply(al, dl)
# 为了测试的时候,每一个单元都参与进来
al /= keep_prob-
训练练的时候只有占比为pp的隐藏层单元参与训练。
-
增加最后一行代码的原因,在预测的时候,所有的隐藏层单元都需要参与进来,就需要测试的时候将输出结果除以以pp使下一层的输入规模保持不变。

2 droupout为什么有效总结
加入了 dropout 后,输入的特征都存在被随机清除的可能,所以该神经元不会再特别依赖于任何一个输入特征,也就是不会给任何一个输入特征设置太大的权重。通过传播过程,dropout 将产生和 L2 正则化相同的收缩权重的效果。
-
对于不同的层,设置的keep_prob大小也不一致,神经元较少的层,会设keep_prob为 1.0,而神经元多的层则会设置比较小的keep_prob
-
通常被使用在计算机视觉领域,图像拥有更多的特征,场景容易过拟合,效果被实验人员证明是很不错的。
调试时候使用技巧:
-
dropout 的缺点是损失函数无法被明确定义,因为每次会随机消除一部分神经元,所以参数也无法确定具体哪一些,在反向传播的时候带来计算上的麻烦,也就无法保证当前网络是否损失函数下降的。如果要使用droupout,会先关闭这个参数,保证损失函数是单调下降的,确定网络没有问题,再次打开droupout才会有效。
四 其它正则化方法
-
早停止法(Early Stopping)
-
数据增强
1 早停止法(Early Stopping)
通常不断训练之后,损失越来越小。但是到了一定之后,模型学到的过于复杂(过于拟合训练集上的数据的特征)造成测试集开始损失较小,后来又变大。模型的w参数会越来越大,那么可以在测试集损失减小一定程度之后停止训练。
但是这种方法治标不治本,得从根本上解决数据或者网络的问题。
2 数据增强
- 数据增强
指通过剪切、旋转/反射/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换等一种或多种组合数据增强变换的方式来增加数据集的大小。
-
数据增强类别
那么我们应该在机器学习过程中的什么位置进行数据增强?在向模型输入数据之前增强数据集。
-
离线增强。预先进行所有必要的变换,从根本上增加数据集的规模(例如,通过翻转所有图像,保存后数据集数量会增加2倍)。
-
在线增强,或称为动态增强。可通过对即将输入模型的小批量数据的执行相应的变化,这样同一张图片每次训练被随机执行一些变化操作,相当于不同的数据集了。
那么我们的代码中也是进行这种在线增强。
-
数据增强技术
下面一些方法基础但功能强大的增强技术,目前被广泛应用。
-
翻转:tf.image.random_flip_left_right
-
你可以水平或垂直翻转图像。一些架构并不支持垂直翻转图像。但,垂直翻转等价于将图片旋转180再水平翻转。下面就是图像翻转的例子。
-
-
旋转:rotate
-
剪裁:random_crop
-
随机从原始图像中采样一部分,然后将这部分图像调整为原始图像大小。这个方法更流行的叫法是随机裁剪。
-
-
平移、缩放等等方法
数据增强的效果是非常好的,比如下面的例子,绿色和粉色表示没有数据增强之前的损失和准确率效果,红色和蓝色表示数据增强之后的损失和准确率结果,可以看到学习效果也改善较快。
那么TensorFlow 官方源码都是基于 vgg与inception论文的图像增强介绍,全部通过tf.image相关API来预处理图像。并且提供了各种封装过tf.image之后的API。那么TensorFlow 官网也给我们提供了一些模型的数据增强过程。
总结
-
掌握偏差与方差的意义
-
掌握L2正则化与L1正则化的数学原理
-
权重衰减
-
-
掌握droupout原理以及方法
-
Inverted droupout
-
-
知道正则化的作用