2024五一数学建模竞赛(五一赛)C题保姆级分析完整思路+代码+数据教学
煤炭是中国的主要能源和重要的工业原料。然而,随着开采深度的增加,地应力增大,井下煤岩动力灾害风险越来越大,严重影响着煤矿的安全高效开采。在各类深部煤岩动力灾害事故中,冲击地压已成为威胁中国煤矿安全生产最重要的灾害之一,冲击地压事故易造成严重的人员伤亡和财产损失。近年来,研究人员进行了大量深入的研究,采取了许多防控措施,中国煤矿安全形势持续稳步改善。但是,冲击地压事故仍时有发生,煤矿安全形势依然严峻,冲击地压的监测预警和有效防控仍是煤矿安全生产中亟待解决的科技问题。在深部煤矿开采过程中,可以监测声发射(AE)和电磁辐射(EMR)信号,电磁辐射和声发射传感器每30秒采集一个数据,可通过这些数据的变化趋势判断目前工作面或巷道是否存在冲击地压危险。电磁辐射和声发射数据随着采煤工作面的推进波动,一般在冲击地压发生前数天(如0-7天,即大约冲击地压发生前7天内)会有一些趋势性前兆特征,因此我们将电磁辐射和声发射数据分为5类,(A)正常工作数据;(B)前兆特征数据;(C)干扰信号数据;(D)传感器断线数据;(E)工作面休息数据,其中,A、B、C 类为工作面正常生产时的数据,D类为监测系统不正常时的数据,E类为停产期间的数据。附件1给出了2019年1月9日-2020年1月7日采集的电磁辐射和声发射数据,并且标记出了所对应的A、B、C类以及D或者E类(D/E)数据。
首先来看看问题是什么:
问题1:如图1,已知现场工作面的部分电磁辐射和声发射信号中存在大量干扰信号,有可能是工作面的其他作业或设备干扰等因素引起,这对后期的电磁辐射和声发射信号处理造成了一定的影响。应用附件1和2中的数据,完成以下问题。
添加图片注释,不超过 140 字(可选)
(1.1) 建立数学模型,对存在干扰的电磁辐射和声发射信号进行分析,分别给出电磁辐射和声发射中的干扰信号数据的特征(不少于3个)。
(1.2) 利用问题(1.1)中得到的特征,建立数学模型,对2022年5月1日-2022年5月30日的电磁辐射和2022年4月1日-2022年5月30日及2022年10月10日-2022年11月10日声发射信号中的干扰信号所在的时间区间进行识别,分别给出电磁辐射和声发射最早发生的5个干扰信号所在的区间,完成表1和表2。
问题总体分析:
将问题拆解,可以得到以下内容:
题目要求分析电磁辐射(EMR)和声发射(AE)信号,建立数学模型以预测和识别冲击地压的危险。
问题1:针对存在干扰的信号数据,分析其特征,并建立模型识别干扰信号的时间区间。
问题2:分析显示前兆特征的信号,建立模型识别前兆特征信号的时间区间,以预测可能发生的冲击地压。
问题3:为了尽早发出预警,建立模型计算每个数据采集时刻前兆特征出现的概率。
数据集分析:
首先需要大家先对题目给的三个数据集进行数据清洗和预处理,以便后续进行更深入的分析。
l 附件1 包含声波强度(声发射AE)、时间和类别(正常、干扰等)信息。 主要用于声发射信号的分析。
l 附件2 包含电磁辐射(EMR)和时间信息,分布在三个不同的时间段。
l 主要用于电磁辐射信号的分析。
l 附件3 也包含电磁辐射数据,但有五个不同的时间段。与附件2相似,主要用于更详细的电磁辐射信号分析,覆盖更多的时间段。
为了分析电磁辐射(EMR)数据中的干扰信号,可以使用时间序列分析的方法,例如应用异常值检测算法。下面给出了这部分可以使用的代码:
import numpy as np
# Define a function to detect outliers based on the mean and standard deviation
def detect_outliers(data, window=7, sigma=2):
rolling_mean = data['EMR'].rolling(window=window).mean()
rolling_std = data['EMR'].rolling(window=window).std()
# Define upper and lower bounds for normal data
lower_bound = rolling_mean - (sigma * rolling_std)
upper_bound = rolling_mean + (sigma * rolling_std)
# Identify points where data values exceed these bounds
data['Outlier'] = (data['EMR'] < lower_bound) | (data['EMR'] > upper_bound)
return data
# Apply the outlier detection function
emr_outliers = detect_outliers(emr_combined_3)
# Visualize the data with outliers marked
plt.figure(figsize=(12, 6))
plt.plot(emr_combined_3['Time'], emr_combined_3['EMR'], label='EMR Data', color='blue')
plt.scatter(emr_combined_3['Time'][emr_outliers['Outlier']], emr_combined_3['EMR'][emr_outliers['Outlier']], color='red', label='Outliers')
plt.title('EMR Data with Outliers Highlighted')
plt.xlabel('Time')
plt.ylabel('EMR Value')
plt.xticks(rotation=45)
plt.legend()
plt.grid(True)
plt.show()
它可以进行异常检测,首先定义了一个用于检测异常值的函数,该函数基于数据的移动平均和标准差计算异常阈值。异常值是指那些超出给定标准差倍数的数据点。随后,该函数在数据集中标记这些异常值,并通过绘图可视化这些潜在的干扰信号。
接下来就是问题一的分析了。
问题一分析:针对题目C的第一问,我们需要分析电磁辐射(EMR)和声发射(AE)信号中存在的干扰信号,并识别它们的特征。这包括定义干扰信号的特征、建立用于识别干扰的数学模型,并最终确定存在干扰信号的时间区间。可以使用以下步骤:
l 特征定义与数据预处理:我们需要定义干扰信号可能具有的特征(如信号强度的突变、频率的异常变化等),并对数据进行适当的预处理(如滤波、去噪等)。
l 模型建立:建立适合识别干扰信号的数学模型。这可能包括统计模型、机器学习模型或基于规则的模型。
l 时间区间识别:应用建立的模型,识别出数据中干扰信号所在的时间区间。
这里给大家推荐一种模型方法:隔离森林(Isolation Forest)。这种模型特别适合处理高维度数据和识别异常值或干扰,因为它基于随机森林的思想,通过隔离机制来识别不符合整体分布的点。
隔离森林是一种有效的无监督学习算法,用于异常检测。它的工作原理是随机选择一个特征,然后随机选择该特征的一个切分值,以此方式递归地划分数据。异常点通常是那些具有较短路径长度的数据点,即它们容易被隔离。
过程:
l 数据准备:整理和标准化数据,准备适合模型的输入格式。
l 模型训练:使用隔离森林模型来训练数据。
l 干扰识别:应用模型识别干扰并标记可能的干扰时间区间。
l 结果可视化:将识别结果可视化,以便进一步分析。
Python代码:
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
# 假设已有清洗和准备好的EMR数据 'emr_combined_3'
# 数据标准化
emr_data_normalized = (emr_combined_3['EMR'] - emr_combined_3['EMR'].mean()) / emr_combined_3['EMR'].std()
# 转换为适合模型输入的格式
emr_data_for_model = emr_data_normalized.values.reshape(-1, 1)
# 初始化隔离森林模型
iso_forest = IsolationForest(n_estimators=100, contamination='auto', random_state=42)
# 训练模型
iso_forest.fit(emr_data_for_model)
# 预测数据点的异常状态
outliers = iso_forest.predict(emr_data_for_model)
# 将异常检测结果转换为布尔值,便于可视化
is_outlier = outliers == -1
# 可视化结果
plt.figure(figsize=(12, 6))
plt.plot(emr_combined_3['Time'], emr_combined_3['EMR'], label='EMR Data')
plt.scatter(emr_combined_3['Time'][is_outlier], emr_combined_3['EMR'][is_outlier], c='r', label='Detected Interferences')
plt.title('Detected Interferences in EMR Data Using Isolation Forest')
plt.xlabel('Time')
plt.ylabel('Normalized EMR Value')
plt.legend()
plt.show()
在这里,首先对EMR数据进行了标准化处理,然后使用隔离森林模型来训练和预测数据点的异常状态。最后,将检测到的异常点在图中标记出来,以红色点显示。这种方法可以有效地帮助我们识别数据中的潜在干扰,且不需要任何先验知识。
之后就需要识别出数据中干扰信号所在的时间区间了,为了识别数据中干扰信号所在的时间区间,我们将使用前面提到的隔离森林模型的输出来确定异常数据点,然后基于这些数据点找出连续的时间区间,这些区间将被认为是潜在的干扰信号所在区间。
首先,我们将使用隔离森林模型来识别EMR数据中的异常点。然后,我们将这些异常点分组,以便识别出连续的时间段。以下是python代码:
import pandas as pd
from sklearn.ensemble import IsolationForest
# 假设已有清洗和准备好的EMR数据 'emr_combined_3',并且已经包含时间戳 'Time' 和电磁辐射值 'EMR'
# 数据标准化
emr_data_normalized = (emr_combined_3['EMR'] - emr_combined_3['EMR'].mean()) / emr_combined_3['EMR'].std()
# 转换为适合模型输入的格式
emr_data_for_model = emr_data_normalized.values.reshape(-1, 1)
# 初始化隔离森林模型
iso_forest = IsolationForest(n_estimators=100, contamination='auto', random_state=42)
# 训练模型并预测
outliers = iso_forest.fit_predict(emr_data_for_model)
# 转换为布尔数组,其中True表示异常
emr_combined_3['Outlier'] = outliers == -1
# 识别连续的异常区间
emr_combined_3['Time'] = pd.to_datetime(emr_combined_3['Time']) # 确保时间列是datetime类型
emr_combined_3['Block'] = (emr_combined_3['Outlier'] != emr_combined_3['Outlier'].shift()).cumsum()
outlier_blocks = emr_combined_3[emr_combined_3['Outlier']].groupby('Block').agg(Start_Time=('Time', 'min'), End_Time=('Time', 'max'))
# 显示异常时间区间
print(outlier_blocks)
这段代码首先对数据进行了标准化,并且使用隔离森林模型来标识异常点。然后,它创建了一个新列Block来帮助识别连续的异常块。最后,通过分组并聚合这些连续的异常块,可以得到每个干扰信号的开始时间和结束时间。
这些时间区间表示模型识别为异常的连续时间段,很可能是由干扰引起的。通过观察这些区间,可以进一步分析干扰的特性或进行必要的控制措施。这个方法提供了一个自动化的方式来检测和记录干扰信号在时间上的分布,非常适合于监控和分析大规模数据集中的异常活动。
后两问思路及代码后续更新哦,需要的同学看文末文章
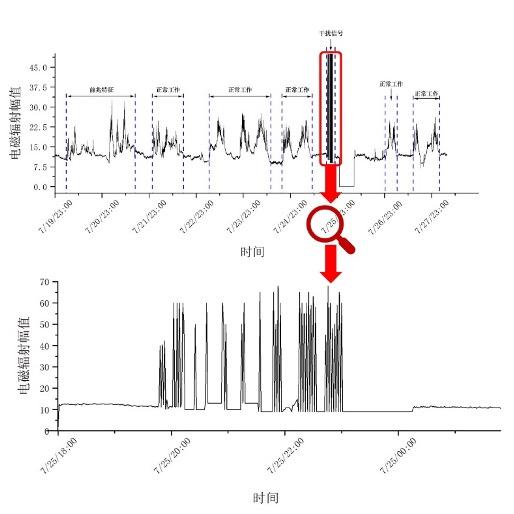
问题2:已知在发生冲击地压危险前约7天内,电磁辐射和声发射信号存在随时间循环增大的趋势(如图2所示),这类信号我们称为前兆特征信号。在出现前兆特征信号之后的约7天内,有可能发生冲击地压,所以一般情况下出现前兆特征信号之后,会采取一定措施尽可能的防止冲击地压发生。应用附件1和2中的数据,完成以下问题。
(2.1) 建立数学模型,对电磁辐射和声发射信号中的前兆特征信号进行分析,重点分析信号的变化趋势,分别给出电磁辐射和声发射信号危险发生前(前兆特征)数据的趋势特征(不少于3个)。
(2.2) 利用问题(2.1)中得到的特征,建立数学模型,对2020年4月8日-2020年6月8日及2021年11月20日-2021年12月20日的电磁辐射和2021年11月1日-2022年1月15日声发射信号中的前兆特征所在的时间区间进行识别,分别给出电磁辐射和声发射信号最早发生的5个前兆特征信号所在的时间区间,完成表3和表4。
问题3:为了尽早的识别前兆特征信号,在前兆特征信号出现的第一时间发出预警,需要在每次数据采集的时刻对危险进行预判。附件3给出了一些非连续时间段采集的电磁辐射和声发射信号数据。请建立数学模型,给出附件3中的每个时间段最后时刻出现前兆特征数据的概率,完成表5。
其中更详细的思路,各题目思路、代码、讲解视频、成品论文及其他相关内容,可以点击下方群名片哦!