通过数组来模拟双链表,并执行一些插入和删除的功能。
目录
一、问题描述
二、模拟思路
1.变量解释
2.数组初始化
3.在下标是k的结点后面插入一个结点
4.删除下标为k的结点
5.基本功能解释
三、代码如下
1.代码如下:
2.读入数据:
3.代码运行结果如下:
总结
前言
通过数组来模拟双链表,并执行一些插入和删除的功能。
一、问题描述
实现一个双链表,双链表初始为空,支持 55 种操作:
- 在最左侧插入一个数;
- 在最右侧插入一个数;
- 将第 k 个插入的数删除;
- 在第 k 个插入的数左侧插入一个数;
- 在第 k 个插入的数右侧插入一个数
现在要对该链表进行 M次操作,进行完所有操作后,从左到右输出整个链表。
注意:题目中第 k个插入的数并不是指当前链表的第 k 个数。例如操作过程中一共插入了 n 个数,则按照插入的时间顺序,这 n个数依次为:第 1 个插入的数,第 22个插入的数,…第 n个插入的数。
输入格式
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令可能为以下几种:
L x,表示在链表的最左端插入数 x。R x,表示在链表的最右端插入数 x。D k,表示将第 k 个插入的数删除。IL k x,表示在第 k 个插入的数左侧插入一个数。IR k x,表示在第 k个插入的数右侧插入一个数。
输出格式
共一行,将整个链表从左到右输出。
数据范围
1≤M≤100000
所有操作保证合法。
二、模拟思路
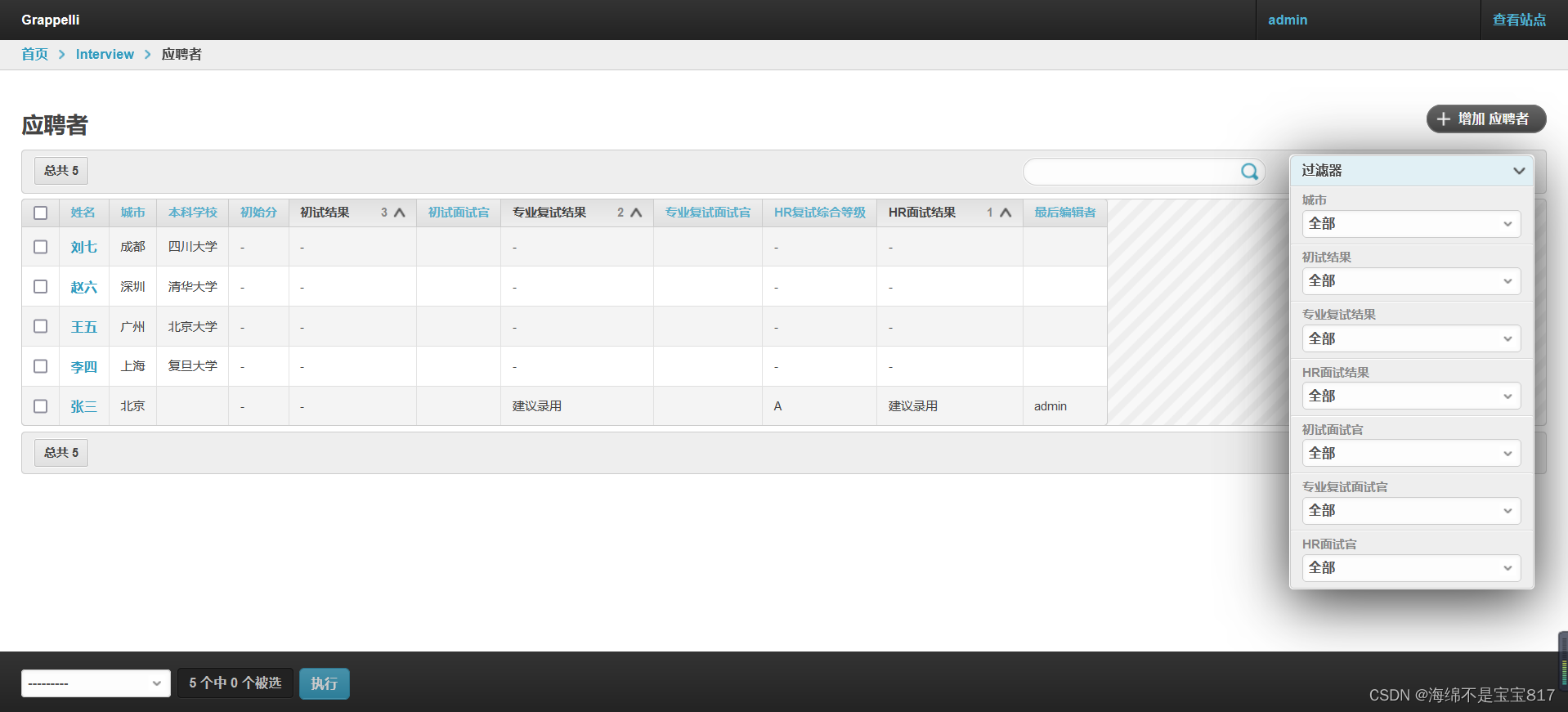
1.变量解释

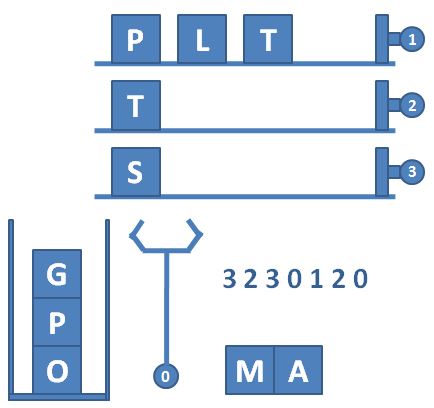
图1.1样例图
我们引入一维整型数组e,用来存储结点的值;一维整型数组l,用来记录当前结点指向左边结点的索引值;一维整型数组r,用来记录当前结点指向的右边结点的索引值;整型变量index用来表示数组e中第一个空结点的索引值,即创建新结点的索引值。
2.数组初始化

图2.1样例图
我们进行初始化操作将索引0和索引1的结点直接占用,分别表示头结点和尾结点,让头结点的右指针指向尾结点,然后让尾结点的左指针指向头结点,第一个空结点从索引为2的结点开始。
//初始化
public static void init(){
r[0] = 1;
l[1] = 0;
index = 2;
}3.在下标是k的结点后面插入一个结点

图3.1
我们传入下标k和结点的值x,我们先让结点存入链表,即e[index] = x。然后我们需要让新插入的结点的右指针指向下标为k指向的右节点;新插入的结点的右指针为r[index],下标为k的结点指向的右节点为r[k],即r[index] = r[k];让新插入的结点的左指针指向下标为k的结点即l[index] = k;让下标为k的结点指向的右结点的左指针指向新插入的结点,让下标为k的结点指向的右结点的左指针为l[r[k]],即l[r[k]] = index;再让下标为k的结点指向的右指针指向新结点即r[k] = index;此时我们就完成了将新结点插入整个链表。切记因为进行这一系列操作我们需要记录下标为k的结点的下一个结点即r[k],如果我们先修改这个值,那么后面再用就会发生变化,所以要么用变量先存储,要么r[k]我们先用,修改的操作最后进行,这样不容易发生错误。
最后将index++,让index一直保持是第一个空结点的下标。
4.删除下标为k的结点
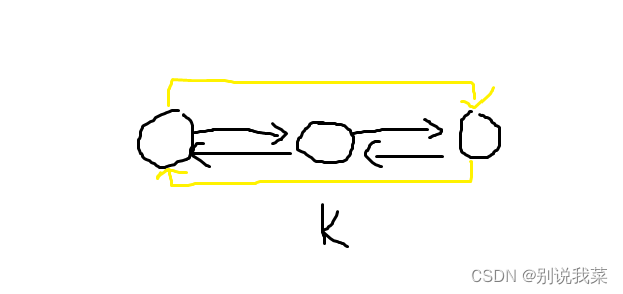
图4.1思路模拟
我们删除下标为k的结点 ,即直接让下标为k的前一个结点的右指针指向下标为k的结点的后一个结点,让下标为k的结点的后一个结点的左指针指向下标为k的的结点的前一个结点即可。下标为k的前一个结点为l[k],下标为k的后一个结点为r[k],我们完场上述两个操作是r[l[k]] = r[k]、l[r[k]] = l[k],这样我们就完成了删除下标为k的结点的操作。
//删除下标为k的结点
public static void delete(int k){
r[l[k]] = r[k];
l[r[k]] = l[k];
}5.基本功能解释
在最左则插入一个结点就是在下标为0的点的右边插入一个结点,即是add(0,x);在最右侧添加一个结点就是在尾结点的前一个结点的后面添加一个结点,即add(l[1],x);将第 k 个插入的结点删除,我们第1个插入的结点是在索引2的位置,那么我们第k个插入的结点就是在索引为k+1的位置,那么该操作为delete(k+1);在第 k 个插入的数左侧插入一个结点,即是在下标为k+1的左边的结点的后面插入一个数即add(l[k+1],x);在第 k个插入的数右侧插入一个结点,就直接在下标为k+1的结点后面插入一个结点即add(k+1,x)。
三、代码如下
1.代码如下:
import java.io.*;
import java.util.*;
public class 双链表 {
static PrintWriter pw = new PrintWriter(new OutputStreamWriter(System.out));
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static int N = 100010;
//存储结点的值
static int[] e = new int[N];
//存储结点连接的左节点索引
static int[] l = new int[N];
//存储结点连接的右节点索引
static int[] r = new int[N];
//数组e中第一个空结点的索引
static int index;
public static void main(String[] args) {
Scanner sc = new Scanner(br);
int m = Integer.parseInt(sc.nextLine());
init();
while (m-- > 0){
String[] str = sc.nextLine().split(" ");
String cmd = str[0];
int k,x;
//最左边插入,即在下标为0的结点右边插入
if(cmd.equals("L")){
x = Integer.parseInt(str[1]);
add(0,x);
}
//最右边插入,即尾结点1的左指针指向的结点的右边插入
else if (cmd.equals("R")) {
x = Integer.parseInt(str[1]);
add(l[1],x);
}
else if (cmd.equals("D")) {
k = Integer.parseInt(str[1]);
delete(k+1);
} else if (cmd.equals("IL")) {
k = Integer.parseInt(str[1]);
x = Integer.parseInt(str[2]);
add(l[k+1],x);
}else if(cmd.equals("IR")) {
k = Integer.parseInt(str[1]);
x = Integer.parseInt(str[2]);
add(k+1,x);
}
}
for(int i = r[0];i !=1;i = r[i]){
pw.print(e[i]+" ");
}
pw.flush();
}
//初始化
public static void init(){
r[0] = 1;
l[1] = 0;
index = 2;
}
//在下标是k的右边插入一个点
public static void add(int k,int x){
e[index] = x;
r[index] = r[k];
l[index] = k;
l[r[k]] = index;
r[k] = index;
index++;
}
//删除下标为k的结点
public static void delete(int k){
r[l[k]] = r[k];
l[r[k]] = l[k];
}
}
2.读入数据:
10
R 7
D 1
L 3
IL 2 10
D 3
IL 2 7
L 8
R 9
IL 4 7
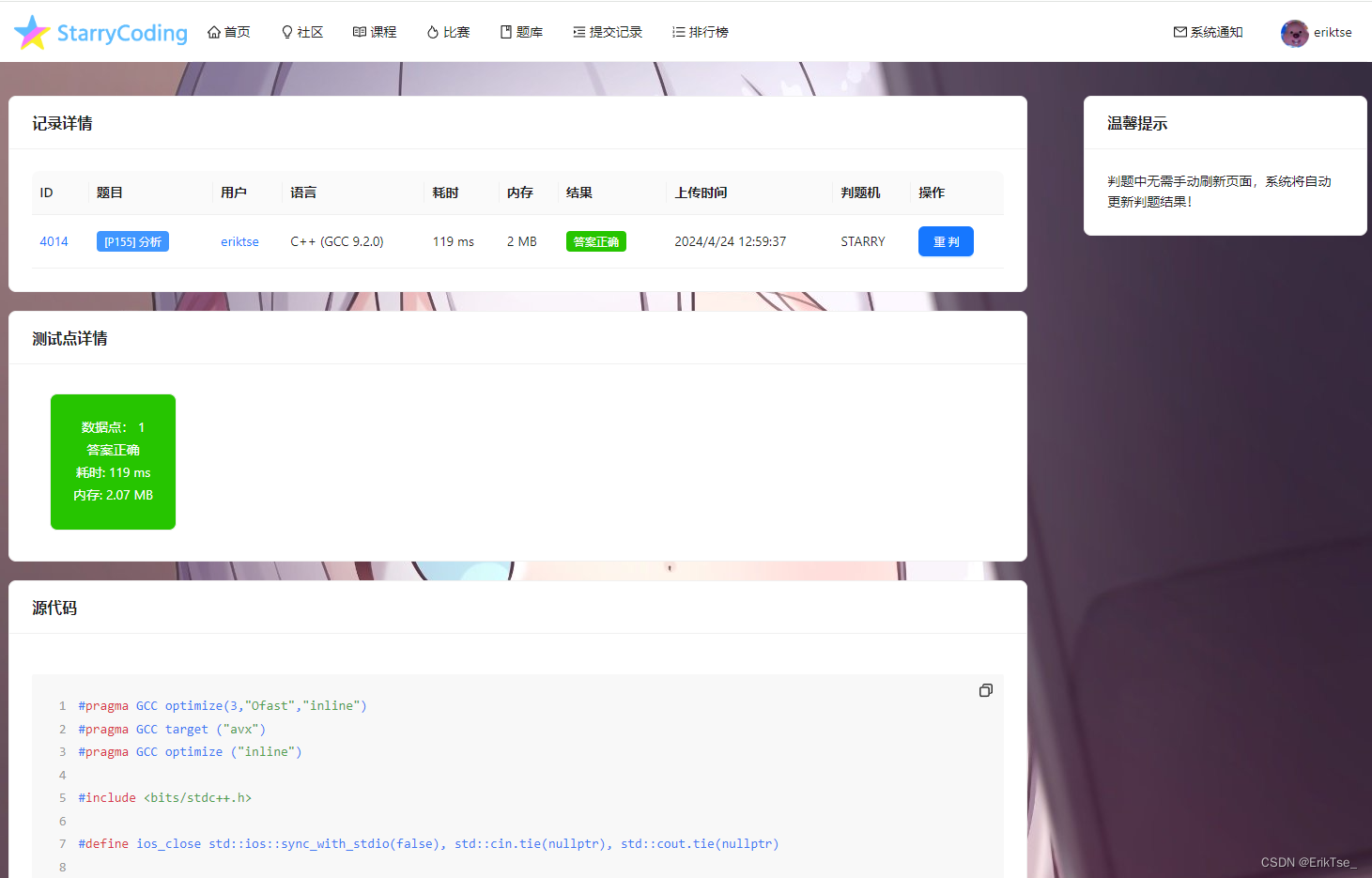
IR 2 23.代码运行结果如下:
8 7 7 3 2 9总结
当我们刷算法题时可以通过数组来模拟链表,比直接用结构体的代码会简洁一点。