代码展示:
import jieba
import re
import json
import logging
import sys
import gensim.models as word2vec
from gensim.models.word2vec import LineSentence, logger
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
def get_sentence(data_file):
f = open(data_file, encoding='utf-8') #读取json数据
reader = f.readlines()
sentences = [] # 修改:存放每个句子的列表
for line in reader:
line = json.loads(line.strip())
sentence = ' '.join(jieba.cut(re.sub(pattern, '', line['sentence'])))
sentences.append(sentence) # 修改:将每个分词后的句子添加到 sentences 列表中
word_lists = [sentence.split() for sentence in sentences]
return word_lists
def train_word2vec(sentences, out_vector):
# 设置输出日志
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# 训练word2vec模型
model = word2vec.Word2Vec(sentences, vector_size=100, sg=1, window=5, min_count=5, workers=4, epochs=5)
# 保存word2vec模型
model.save("word2vec_model.model")
# 保存词向量到文件
model.wv.save_word2vec_format(out_vector, binary=False)
def load_model(w2v_path):
model = word2vec.Word2Vec.load(w2v_path) # 读取保存的模型
return model
def calculate_most_similar(model, word):
similar_words = model.wv.most_similar(word)
print(word)
for term in similar_words:
print(term[0], term[1])
if __name__ == '__main__':
out_vector = 'word_vectors.txt'
word_lists = get_sentence('train.json')
train_word2vec(word_lists, out_vector)
model = load_model('word2vec_model.model')
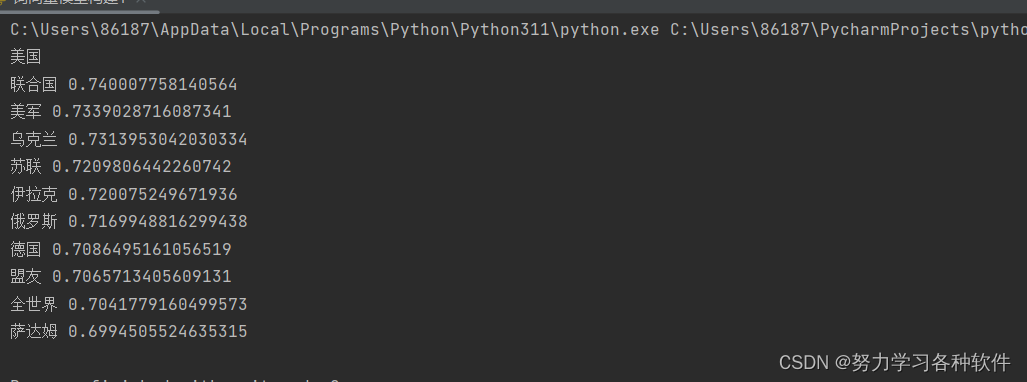
calculate_most_similar(model, "美国") # 输出与美国在词向量空间中相近的词结果展现:
word2vec.Word2Vec 方法中的参数含义如下:
-
sentences:输入的句子集合,可以是一个可迭代对象,每个元素表示一个句子,句子则是由单词组成的列表。 -
vector_size:词向量的维度大小。它决定了每个单词在训练过程中学习到的词向量的维度。 -
window:词向量训练时的上下文窗口大小。窗口大小表示当前词与预测词之间的最大距离。在训练时,窗口大小决定了模型考虑的上下文单词数量。 -
min_count:忽略频率低于此值的单词。如果一个单词在整个语料库中的出现次数少于min_count,则该单词将被忽略,不会被用于训练模型。 -
workers:训练时使用的线程数量,用于加速训练过程。指定多个线程可以加快模型的训练速度。 -
sg:用于指定训练算法的模型类型。当sg=0时,表示使用 CBOW 模型;当sg=1时,表示使用 Skip-Gram 模型。 -
epochs:指定训练的迭代次数。一个迭代表示对整个语料库的一次遍历。
这些参数共同决定了 Word2Vec 模型的训练过程和最终学习到的词向量的质量。根据具体的应用场景和语料库的特点,可以调整这些参数以获得更好的结果。
sentence的具体格式(两个列表):
sentences = [['海陆空', '全能', '反恐', '王'], ['说', '出来', '你', '可能', '不', '信', '旅游', '日', '免费', '吃', '砂锅', '自助餐']]