概述

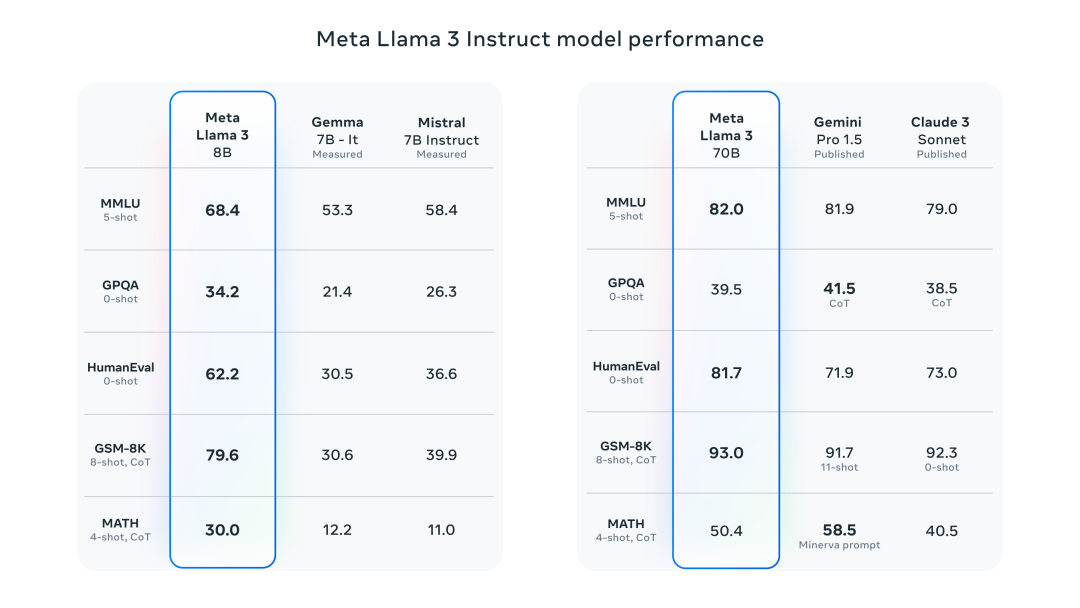
Meta公司自豪地宣布推出其最新的开源大型语言模型——Llama 3,这是一款专为未来AI挑战而设计的先进工具。Llama 3包含两个不同参数规模的版本,以满足多样化的计算需求:
- 8B版本:优化了在消费级GPU上的部署和开发流程,使得个人开发者和小型团队也能轻松利用其强大的语言处理能力。
- 70B版本:为大规模AI应用量身定制,提供了无与伦比的处理能力和深度学习能力。
即将到来的广泛平台支持
Llama 3模型预计将在一系列顶尖的云服务平台和AI技术提供商中推出,包括AWS、Databricks、Google Cloud等。此外,该模型也将得到AMD、AWS、Dell、Intel、NVIDIA以及高通等硬件制造商的全面支持。
性能提升与新特性
Llama 3模型将带来一系列创新特性,包括:
- 新功能:增强模型的功能性,以适应更广泛的应用场景。
- 更长的上下文窗口:提升模型对长文本的理解能力。
- 额外的模型大小:提供更多参数选项,以适应不同规模的AI任务。
- 增强的性能:在各项任务中提供更快的处理速度和更高的准确率。
Meta还将分享Llama 3的详细研究论文,以促进更广泛的学术交流和技术发展。
性能指标与人类评估集
为了全面评估Llama 3的性能,Meta开发了一套新的高质量人类评估集,包含1,800个精心设计的提示,覆盖12个关键用例,包括但不限于:
- 寻求建议
- 头脑风暴
- 分类
- 封闭式问答
- 编码
- 创意写作
- 提取
- 塑造角色/角色
- 开放式问答
- 推理
- 重写
- 总结
评估结果
Llama 的演变:从 Llama 2 到 Llama 3
Meta的首席执行官马克·扎克伯格宣布,公司最新开发的人工智能模型Llama 3现已开源,这一举措标志着Meta在AI领域的最新进展。Llama 3旨在提升Meta旗下包括Messenger和Instagram在内的多个产品,使其成为全球领先的AI助手之一。
Llama 2的回顾与Llama 3的进步
Llama 2模型于两年前推出,作为开源Llama系列的一个重要里程碑,它提供了一个既强大又高效的模型,能够在消费级硬件上运行。尽管Llama 2取得了显著成就,但它也存在一些局限性,包括用户报告的错误拒绝问题、有限的帮助范围,以及在推理和代码生成方面需要改进的地方。
Llama 3: Meta的创新回应
针对这些挑战和社区的反馈,Meta通过Llama 3进行了回应。Meta的目标是构建一个能与当今市场上顶级专有模型相媲美的开源模型,同时将负责任的开发和部署实践放在首位。
Llama 3的推出,不仅代表了Meta在AI技术上的飞跃,也体现了公司对于开放创新和社区协作的承诺。随着Llama 3的开源,研究人员、开发者和AI爱好者现在可以访问这一先进的模型,共同推动人工智能技术的发展。
Llama 3:架构与训练
Meta的Llama 3模型在人工智能领域带来了显著的技术突破。其中一项创新是其分词器,它显著扩展了词汇量至128,256个令牌,相较于Llama 2的32,000个令牌,这是一个巨大的跃升。这种词汇量的增加不仅意味着模型能够更精细地理解和生成文本,而且也极大地增强了其多语言处理能力,从而提升了整体性能。
此外,Llama 3还引入了分组查询注意力(Grouped Query Attention, GQA)技术。这是一种先进的表示方法,它通过提高模型的可扩展性,帮助其更有效地处理更长的文本序列。特别是,Llama 3的8B版本采用了GQA技术,而8B和70B模型均能够处理长达8,192个令牌的序列。
这些创新不仅展示了Meta在AI技术上的领导地位,也预示着Llama 3将为各种应用场景带来前所未有的性能提升。无论是在理解复杂查询、生成创意内容,还是在多语言支持方面,Llama 3都展现了其强大的潜力。
训练数据和扩展
Llama 3 使用的训练数据是其性能提升的关键因素。 Meta 策划了超过 15万亿 来自公开在线资源的令牌,比 Llama 2 使用的数据集大七倍。该数据集还包括很大一部分(超过 5%)的高质量非英语数据,涵盖超过 30语言,为未来的多语言应用做准备。
为了确保数据质量,Meta 采用了先进的过滤技术,包括启发式过滤器、NSFW 过滤器、语义重复数据删除和在 Llama 2 上训练的文本分类器来预测数据质量。该团队还进行了广泛的实验,以确定预训练数据源的最佳组合,确保 Llama 3 在各种用例中表现良好,包括琐事、STEM、编码和历史知识。
扩大预训练规模是 Llama 3 开发的另一个关键方面。 Meta 开发了缩放法则,使他们能够在实际训练之前预测最大模型在代码生成等关键任务上的性能。这为数据混合和计算分配的决策提供了信息,最终导致更高效和有效的培训。
Llama 3 最大的模型在两个定制的 24,000 个 GPU 集群上进行训练,利用数据并行化、模型并行化和管道并行化技术的组合。 Meta 的高级训练堆栈可自动检测、处理和维护错误,从而最大限度地延长 GPU 正常运行时间,并将训练效率比 Llama 2 提高约三倍。
指令微调和性能
为了充分发挥 Llama 3 在聊天和对话应用程序方面的潜力,Meta 创新了其指令微调方法。其方法结合了 监督微调 (SFT),拒绝采样, 近端政策优化 (PPO),以及 直接偏好优化 (数据保护办公室)。
SFT 中使用的提示的质量以及 PPO 和 DPO 中使用的偏好排名对于对齐模型的性能起着至关重要的作用。 Meta 的团队精心整理了这些数据,并对人类注释者提供的注释进行了多轮质量保证。
通过 PPO 和 DPO 进行偏好排名训练也显着提高了 Llama 3 在推理和编码任务上的表现。 Meta 发现,即使模型难以直接回答推理问题,它仍然可能产生正确的推理轨迹。对偏好排名的训练使模型能够学习如何从这些痕迹中选择正确的答案。
[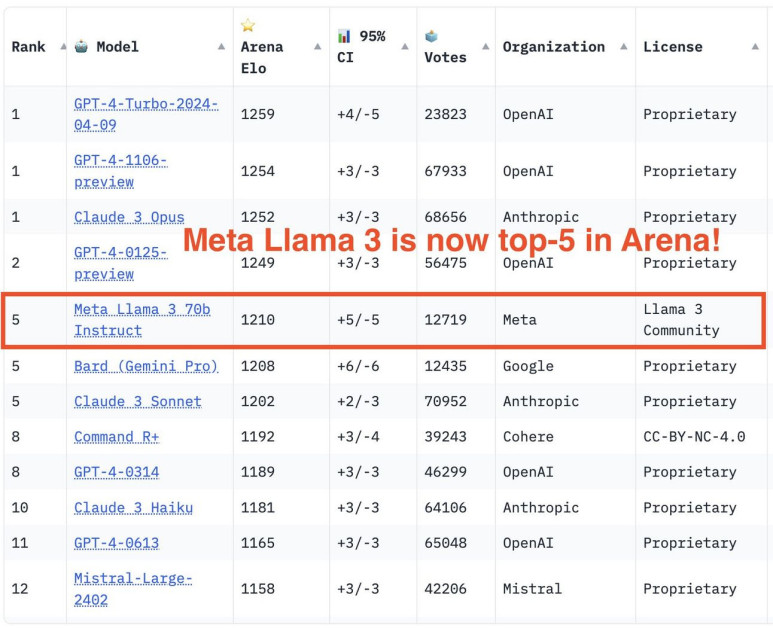
结果不言而喻:Llama 3 在常见行业基准上优于许多可用的开源聊天模型,在 8B 和 70B 参数范围内为法学硕士建立了新的最先进的性能。
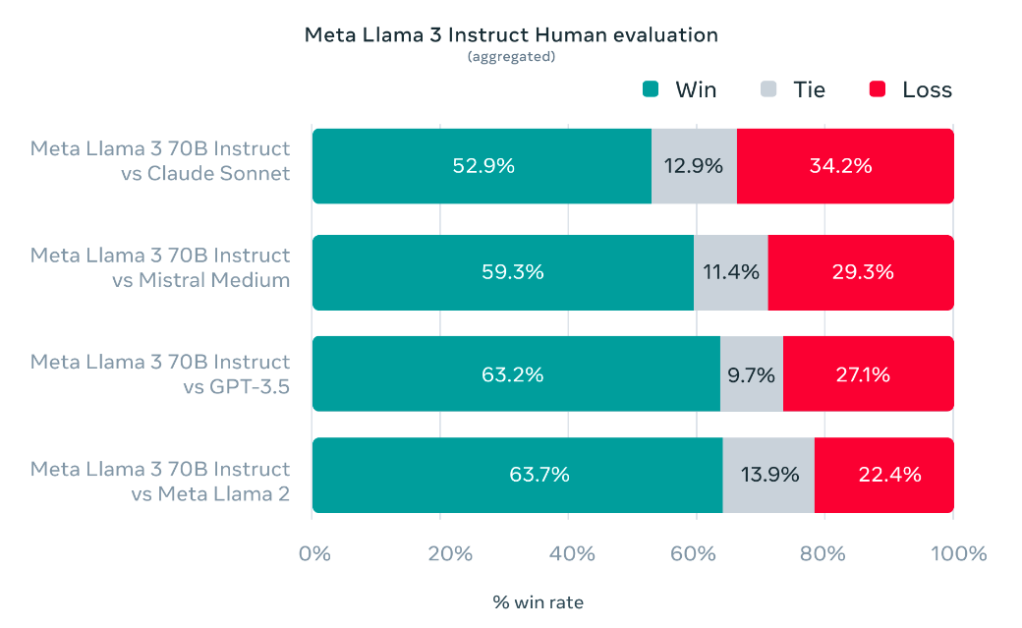 ](https://www.unite.ai/wp-content/uploads/2024/04/aggregated-results-of-our-human-evaluations-across-of-these-categories-and-prompts-against-Claude-Sonnet-Mistral-Medium-and-GPt.png)
](https://www.unite.ai/wp-content/uploads/2024/04/aggregated-results-of-our-human-evaluations-across-of-these-categories-and-prompts-against-Claude-Sonnet-Mistral-Medium-and-GPt.png)
负责任的开发和安全考虑
在追求尖端性能的同时,Meta 还优先考虑了 Llama 3 的负责任的开发和部署实践。该公司采用了系统级方法,将 Llama 3 模型设想为更广泛的生态系统的一部分,让开发人员处于主导地位,使他们能够设计并根据其特定用例和安全要求定制模型。
和响应进行分类,检测可能被认为不安全或有害的内容。 CyberSecEval 2 在其前身的基础上进行了扩展,添加了防止滥用模型代码解释器、攻击性网络安全功能以及对提示注入攻击的敏感性的措施。
Code Shield 是 Llama 3 的新功能,增加了对 LLM 生成的不安全代码的推理时过滤,从而减轻与不安全代码建议、代码解释器滥用和安全命令执行相关的风险。
访问和使用 Llama 3
随着 Meta AI 的 Llama 3 的推出,多个开源工具已经可以在各种操作系统上进行本地部署,包括 Mac、Windows 和 Linux。本节详细介绍了三个值得注意的工具:Ollama、Open WebUI 和 LM Studio,每个工具都提供了在个人设备上利用 Llama 3 功能的独特功能。
奥拉马:适用于 Mac、Linux 和 Windows, 奥拉马 简化了 Llama 3 和其他大型语言模型在个人计算机上的操作,即使是那些硬件不太强大的计算机。它包括一个包管理器,可轻松管理模型,并支持跨平台下载和运行模型的命令。
使用 Docker 打开 WebUI:该工具提供了一个用户友好的、 码头工人基于接口,与 Mac、Linux 和 Windows 兼容。它与 Ollama 注册表中的模型无缝集成,允许用户在本地 Web 界面中部署 Llama 3 等模型并与之交互。
LM工作室:针对 Mac、Linux 和 Windows 上的用户, LM工作室 支持一系列模型,并基于 llama.cpp 项目构建。它提供聊天界面并促进与各种模型的直接交互,包括 Llama 3 8B Instruct 模型。
这些工具确保用户可以在其个人设备上高效地使用 Llama 3,满足一系列技术技能和要求。每个平台都提供了设置和模型交互的分步流程,使开发人员和爱好者更容易使用高级人工智能。
大规模部署 Llama 3
除了提供对模型权重的直接访问之外,Meta 还与各种云提供商、模型 API 服务和硬件平台合作,以实现 Llama 3 的大规模无缝部署。
Llama 3 的主要优势之一是通过新的分词器提高了代币效率。基准测试显示 Llama 3 需要多达 代币减少 15% 与 Llama 2 相比,推理速度更快且更具成本效益。
尽管参数数量有所增加,但在 8B 版本的 Llama 3 中集成分组查询注意力(GQA)有助于保持与 7B 版本的 Llama 2 相当的推理效率。
为了简化部署过程,Meta 提供了 Llama Recipes 存储库,其中包含开源代码以及用于微调、部署、模型评估等的示例。对于希望在其应用程序中利用 Llama 3 功能的开发人员来说,该存储库是宝贵的资源。
对于那些有兴趣探索 Llama 3 性能的人,Meta 已将其最新模型集成到 Meta AI 中,Meta AI 是一款采用 Llama 3 技术构建的领先人工智能助手。用户可以通过各种 Meta 应用程序(例如 Facebook、Instagram、WhatsApp、Messenger 和网络)与 Meta AI 进行交互,以完成工作、学习、创建和连接对他们来说重要的事物。
骆驼 3 的下一步是什么?
虽然 8B 和 70B 型号标志着 Llama 3 版本的开始,但 Meta 对这一开创性的 LLM 的未来制定了雄心勃勃的计划。
在接下来的几个月中,我们预计会看到新功能的推出,包括多模态(处理和生成不同数据模态的能力,例如图像和视频)、多语言(支持多种语言)以及更长的上下文窗口以增强性能需要广泛背景的任务。
此外,Meta 计划发布更大的模型规模,包括具有超过 400 亿个参数的模型,这些模型目前正在训练中,并在性能和功能方面显示出有希望的趋势。
为了进一步推进该领域的发展,Meta 还将发布有关 Llama 3 的详细研究论文,与更广泛的人工智能社区分享其发现和见解。
作为对未来的预览,Meta 分享了其最大的 LLM 模型在各种基准测试中的性能的一些早期快照。虽然这些结果基于早期检查点并且可能会发生变化,但它们让我们对 Llama 3 的未来潜力有了令人兴奋的了解。
结论
Llama 3 代表了开源大型语言模型发展的一个重要里程碑,突破了性能、功能和负责任的开发实践的界限。凭借其创新的架构、海量的训练数据集和尖端的微调技术,Llama 3 为 8B 和 70B 参数尺度的法学硕士建立了新的最先进基准。
然而,Llama 3 不仅仅是一个强大的语言模型;它还是一个强大的语言模型。这证明了 Meta 致力于培育开放、负责任的人工智能生态系统的承诺。通过提供全面的资源、安全工具和最佳实践,Meta 使开发人员能够充分利用 Llama 3 的潜力,同时确保根据其特定用例和受众进行负责任的部署。
随着 Llama 3 之旅的继续,新的功能、模型大小和研究成果即将出现,人工智能社区热切地等待着这一突破性的法学硕士无疑将出现的创新应用和突破。
无论您是突破自然语言处理界限的研究人员、构建下一代智能应用程序的开发人员,还是对最新进展感到好奇的人工智能爱好者,Llama 3 都有望成为您武器库中的强大工具,为您打开新的大门,解锁一个充满可能性的世界。