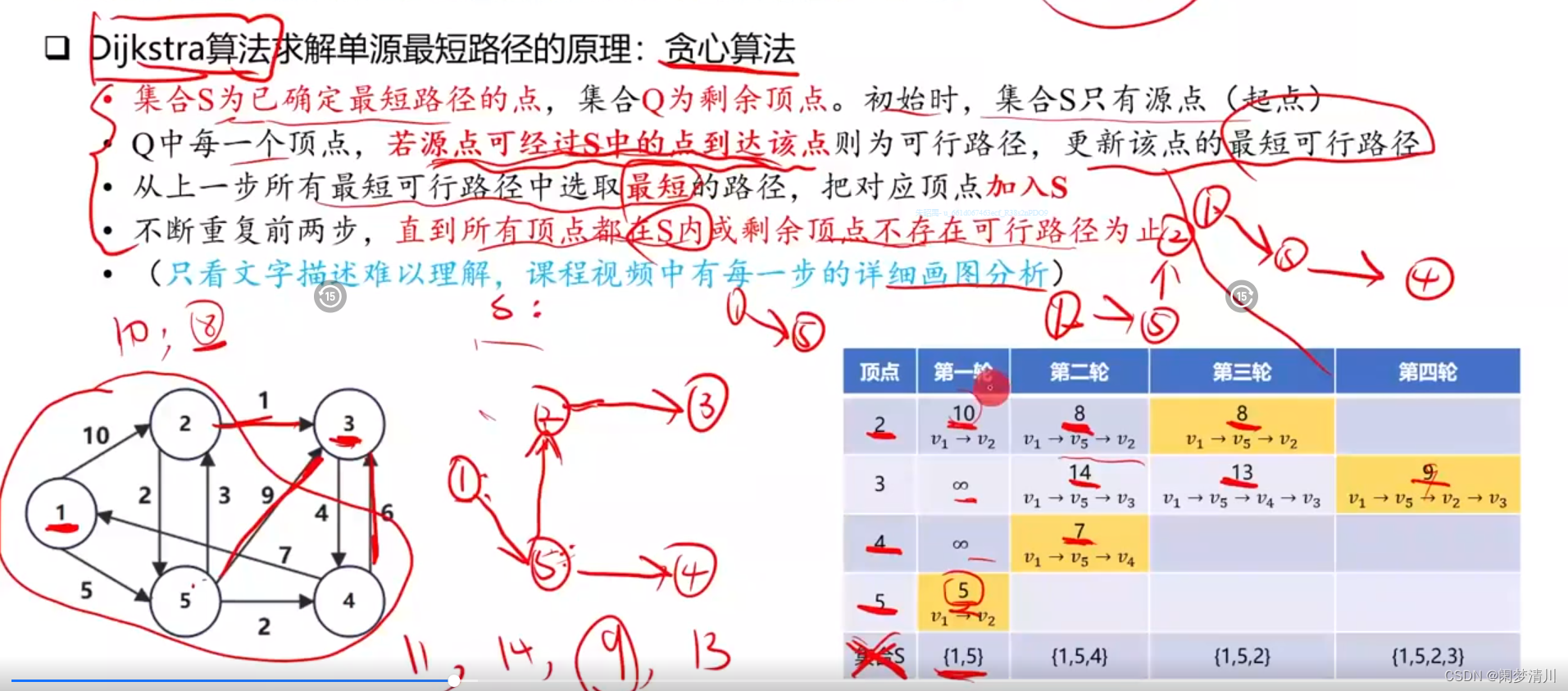
DIoU损失函数
论文链接:https://arxiv.org/pdf/1911.08287
DIoU损失函数(Distance Intersection over Union Loss)是一种在目标检测任务中常用的损失函数,用于优化边界框的位置。这种损失函数是IoU损失函数的改进版,其不仅考虑了边界框之间的重叠区域,还考虑了它们中心点之间的距离,从而提供更加精确的位置优化。以下是DIoU损失函数的设计原理和计算步骤的详细介绍:
设计原理
一、IoU的局限性
- IoU(Intersection over Union)损失函数主要基于预测框和真实框之间的交并比,这个比例值越大表示预测框越接近真实框。
- 但IoU损失函数在预测框和真实框没有重叠时无法提供有效的梯度信息,这限制了模型的学习效率。
二、DIoU的引入
- DIoU损失在IoU的基础上增加了中心点距离的考量,这使得即使在两个框不重叠的情况下也能有效地进行梯度下降。
- 通过考虑框的几何中心距离,DIoU损失有助于减少边界框的尺寸误差,并加速收敛。
计算步骤
一、计算IoU
- 计算两个边界框A和B的交集面积I。
- 计算两个边界框的并集面积U。
- IoU计算公式为:
二、计算框的中心距离
- 设预测框的中心为
,真实框的中心为
。
- 中心点距离 d 的计算公式为:
。
三、计算归一化中心距离
- 计算包围预测框和真实框的最小闭合矩形(称为最小闭合框),并求出其对角线长度。
- 归一化中心距离为
,这样可以确保距离的比例适应不同大小的边界框。
四、计算DIoU
- DIoU损失函数定义为:
- 其中,
表示中心点距离的归一化平方,这样确保了距离项在损失函数中占有合适的权重。
使用PyTorch实现DIoU计算的源代码
import torch
def diou_loss(pred_boxes, gt_boxes):
"""
计算 DIoU 损失。
:param pred_boxes: 预测的边界框,形状为 (batch_size, 4),格式为 (x1, y1, x2, y2)
:param gt_boxes: 真实的边界框,形状为 (batch_size, 4),格式为 (x1, y1, x2, y2)
:return: DIoU 损失值
"""
# 计算交集的坐标
inter_x1 = torch.max(pred_boxes[:, 0], gt_boxes[:, 0])
inter_y1 = torch.max(pred_boxes[:, 1], gt_boxes[:, 1])
inter_x2 = torch.min(pred_boxes[:, 2], gt_boxes[:, 2])
inter_y2 = torch.min(pred_boxes[:, 3], gt_boxes[:, 3])
# 计算交集的面积
inter_area = torch.clamp(inter_x2 - inter_x1, min=0) * torch.clamp(inter_y2 - inter_y1, min=0)
# 计算预测框和真实框的面积
pred_area = (pred_boxes[:, 2] - pred_boxes[:, 0]) * (pred_boxes[:, 3] - pred_boxes[:, 1])
gt_area = (gt_boxes[:, 2] - gt_boxes[:, 0]) * (gt_boxes[:, 3] - gt_boxes[:, 1])
# 计算并集的面积
union_area = pred_area + gt_area - inter_area
# 计算IoU
iou = inter_area / union_area
# 计算中心点的坐标
pred_center_x = (pred_boxes[:, 0] + pred_boxes[:, 2]) / 2
pred_center_y = (pred_boxes[:, 1] + pred_boxes[:, 3]) / 2
gt_center_x = (gt_boxes[:, 0] + gt_boxes[:, 2]) / 2
gt_center_y = (gt_boxes[:, 1] + gt_boxes[:, 3]) / 2
# 计算中心点距离的平方
center_distance = (pred_center_x - gt_center_x) ** 2 + (pred_center_y - gt_center_y) ** 2
# 计算包络框的对角线距离的平方
enclose_x1 = torch.min(pred_boxes[:, 0], gt_boxes[:, 0])
enclose_y1 = torch.min(pred_boxes[:, 1], gt_boxes[:, 1])
enclose_x2 = torch.max(pred_boxes[:, 2], gt_boxes[:, 2])
enclose_y2 = torch.max(pred_boxes[:, 3], gt_boxes[:, 3])
enclose_diagonal = (enclose_x2 - enclose_x1) ** 2 + (enclose_y2 - enclose_y1) ** 2
# 计算 DIoU
diou = iou - (center_distance / enclose_diagonal)
# DIoU 损失
diou_loss = 1 - diou
return diou_loss
# 示例
pred_boxes = torch.tensor([[50, 50, 90, 100], [70, 80, 120, 150]])
gt_boxes = torch.tensor([[60, 60, 100, 120], [80, 90, 130, 160]])
loss = diou_loss(pred_boxes, gt_boxes)
print(loss)
替换DIoU损失函数(基于MMYOLO)
由于MMYOLO中没有实现DIoU损失函数,所以需要在mmyolo/models/iou_loss.py中添加DIoU的计算和对应的iou_mode,修改完以后在终端运行
python setup.py install再在配置文件中进行修改即可。修改例子如下:
elif iou_mode == 'diou':
# CIoU = IoU - ( (ρ^2(b_pred,b_gt) / c^2) + (alpha x v) )
# calculate enclose area (c^2)
enclose_area = enclose_w**2 + enclose_h**2 + eps
# calculate ρ^2(b_pred,b_gt):
# euclidean distance between b_pred(bbox2) and b_gt(bbox1)
# center point, because bbox format is xyxy -> left-top xy and
# right-bottom xy, so need to / 4 to get center point.
rho2_left_item = ((bbox2_x1 + bbox2_x2) - (bbox1_x1 + bbox1_x2))**2 / 4
rho2_right_item = ((bbox2_y1 + bbox2_y2) -
(bbox1_y1 + bbox1_y2))**2 / 4
rho2 = rho2_left_item + rho2_right_item # rho^2 (ρ^2)
ious = ious - ((rho2 / enclose_area))修改后的配置文件(以configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py为例)
_base_ = ['../_base_/default_runtime.py', '../_base_/det_p5_tta.py']
# ========================Frequently modified parameters======================
# -----data related-----
data_root = 'data/coco/' # Root path of data
# Path of train annotation file
train_ann_file = 'annotations/instances_train2017.json'
train_data_prefix = 'train2017/' # Prefix of train image path
# Path of val annotation file
val_ann_file = 'annotations/instances_val2017.json'
val_data_prefix = 'val2017/' # Prefix of val image path
num_classes = 80 # Number of classes for classification
# Batch size of a single GPU during training
train_batch_size_per_gpu = 16
# Worker to pre-fetch data for each single GPU during training
train_num_workers = 8
# persistent_workers must be False if num_workers is 0
persistent_workers = True
# -----model related-----
# Basic size of multi-scale prior box
anchors = [
[(10, 13), (16, 30), (33, 23)], # P3/8
[(30, 61), (62, 45), (59, 119)], # P4/16
[(116, 90), (156, 198), (373, 326)] # P5/32
]
# -----train val related-----
# Base learning rate for optim_wrapper. Corresponding to 8xb16=128 bs
base_lr = 0.01
max_epochs = 300 # Maximum training epochs
model_test_cfg = dict(
# The config of multi-label for multi-class prediction.
multi_label=True,
# The number of boxes before NMS
nms_pre=30000,
score_thr=0.001, # Threshold to filter out boxes.
nms=dict(type='nms', iou_threshold=0.65), # NMS type and threshold
max_per_img=300) # Max number of detections of each image
# ========================Possible modified parameters========================
# -----data related-----
img_scale = (640, 640) # width, height
# Dataset type, this will be used to define the dataset
dataset_type = 'YOLOv5CocoDataset'
# Batch size of a single GPU during validation
val_batch_size_per_gpu = 1
# Worker to pre-fetch data for each single GPU during validation
val_num_workers = 2
# Config of batch shapes. Only on val.
# It means not used if batch_shapes_cfg is None.
batch_shapes_cfg = dict(
type='BatchShapePolicy',
batch_size=val_batch_size_per_gpu,
img_size=img_scale[0],
# The image scale of padding should be divided by pad_size_divisor
size_divisor=32,
# Additional paddings for pixel scale
extra_pad_ratio=0.5)
# -----model related-----
# The scaling factor that controls the depth of the network structure
deepen_factor = 0.33
# The scaling factor that controls the width of the network structure
widen_factor = 0.5
# Strides of multi-scale prior box
strides = [8, 16, 32]
num_det_layers = 3 # The number of model output scales
norm_cfg = dict(type='BN', momentum=0.03, eps=0.001) # Normalization config
# -----train val related-----
affine_scale = 0.5 # YOLOv5RandomAffine scaling ratio
loss_cls_weight = 0.5
loss_bbox_weight = 0.05
loss_obj_weight = 1.0
prior_match_thr = 4. # Priori box matching threshold
# The obj loss weights of the three output layers
obj_level_weights = [4., 1., 0.4]
lr_factor = 0.01 # Learning rate scaling factor
weight_decay = 0.0005
# Save model checkpoint and validation intervals
save_checkpoint_intervals = 10
# The maximum checkpoints to keep.
max_keep_ckpts = 3
# Single-scale training is recommended to
# be turned on, which can speed up training.
env_cfg = dict(cudnn_benchmark=True)
# ===============================Unmodified in most cases====================
model = dict(
type='YOLODetector',
data_preprocessor=dict(
type='mmdet.DetDataPreprocessor',
mean=[0., 0., 0.],
std=[255., 255., 255.],
bgr_to_rgb=True),
backbone=dict(
##使用YOLOv8的主干网络
type='YOLOv8CSPDarknet',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
norm_cfg=norm_cfg,
act_cfg=dict(type='SiLU', inplace=True)
),
neck=dict(
type='YOLOv5PAFPN',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
in_channels=[256, 512, 1024],
out_channels=[256, 512, 1024],
num_csp_blocks=3,
norm_cfg=norm_cfg,
act_cfg=dict(type='SiLU', inplace=True)),
bbox_head=dict(
type='YOLOv5Head',
head_module=dict(
type='YOLOv5HeadModule',
num_classes=num_classes,
in_channels=[256, 512, 1024],
widen_factor=widen_factor,
featmap_strides=strides,
num_base_priors=3),
prior_generator=dict(
type='mmdet.YOLOAnchorGenerator',
base_sizes=anchors,
strides=strides),
# scaled based on number of detection layers
loss_cls=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=loss_cls_weight *
(num_classes / 80 * 3 / num_det_layers)),
# 修改此处实现IoU损失函数的替换
loss_bbox=dict(
type='IoULoss',
iou_mode='diou',
bbox_format='xywh',
eps=1e-7,
reduction='mean',
loss_weight=loss_bbox_weight * (3 / num_det_layers),
return_iou=True),
loss_obj=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=loss_obj_weight *
((img_scale[0] / 640)**2 * 3 / num_det_layers)),
prior_match_thr=prior_match_thr,
obj_level_weights=obj_level_weights),
test_cfg=model_test_cfg)
albu_train_transforms = [
dict(type='Blur', p=0.01),
dict(type='MedianBlur', p=0.01),
dict(type='ToGray', p=0.01),
dict(type='CLAHE', p=0.01)
]
pre_transform = [
dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
dict(type='LoadAnnotations', with_bbox=True)
]
train_pipeline = [
*pre_transform,
dict(
type='Mosaic',
img_scale=img_scale,
pad_val=114.0,
pre_transform=pre_transform),
dict(
type='YOLOv5RandomAffine',
max_rotate_degree=0.0,
max_shear_degree=0.0,
scaling_ratio_range=(1 - affine_scale, 1 + affine_scale),
# img_scale is (width, height)
border=(-img_scale[0] // 2, -img_scale[1] // 2),
border_val=(114, 114, 114)),
dict(
type='mmdet.Albu',
transforms=albu_train_transforms,
bbox_params=dict(
type='BboxParams',
format='pascal_voc',
label_fields=['gt_bboxes_labels', 'gt_ignore_flags']),
keymap={
'img': 'image',
'gt_bboxes': 'bboxes'
}),
dict(type='YOLOv5HSVRandomAug'),
dict(type='mmdet.RandomFlip', prob=0.5),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
'flip_direction'))
]
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
persistent_workers=persistent_workers,
pin_memory=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file=train_ann_file,
data_prefix=dict(img=train_data_prefix),
filter_cfg=dict(filter_empty_gt=False, min_size=32),
pipeline=train_pipeline))
test_pipeline = [
dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
scale=img_scale,
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
val_dataloader = dict(
batch_size=val_batch_size_per_gpu,
num_workers=val_num_workers,
persistent_workers=persistent_workers,
pin_memory=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
test_mode=True,
data_prefix=dict(img=val_data_prefix),
ann_file=val_ann_file,
pipeline=test_pipeline,
batch_shapes_cfg=batch_shapes_cfg))
test_dataloader = val_dataloader
param_scheduler = None
optim_wrapper = dict(
type='OptimWrapper',
optimizer=dict(
type='SGD',
lr=base_lr,
momentum=0.937,
weight_decay=weight_decay,
nesterov=True,
batch_size_per_gpu=train_batch_size_per_gpu),
constructor='YOLOv5OptimizerConstructor')
default_hooks = dict(
param_scheduler=dict(
type='YOLOv5ParamSchedulerHook',
scheduler_type='linear',
lr_factor=lr_factor,
max_epochs=max_epochs),
checkpoint=dict(
type='CheckpointHook',
interval=save_checkpoint_intervals,
save_best='auto',
max_keep_ckpts=max_keep_ckpts))
custom_hooks = [
dict(
type='EMAHook',
ema_type='ExpMomentumEMA',
momentum=0.0001,
update_buffers=True,
strict_load=False,
priority=49)
]
val_evaluator = dict(
type='mmdet.CocoMetric',
proposal_nums=(100, 1, 10),
ann_file=data_root + val_ann_file,
metric='bbox')
test_evaluator = val_evaluator
train_cfg = dict(
type='EpochBasedTrainLoop',
max_epochs=max_epochs,
val_interval=save_checkpoint_intervals)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')