线上OJ:
一本通:http://ybt.ssoier.cn:8088/problem_show.php?pid=1964
核心思想:
1、原文中提到 “如果这趟车次停靠了火车站 x,则始发站、终点站之间所有级别大于等于火车站 x 的都必须停靠”,如果设停靠站为A,未停靠站为B,则题意隐含公式
A
>
=
B
+
1
A >= B+1
A>=B+1。故本题为 差分约束 问题。
2、题中还提到 “输入保证所有的车次都满足要求”,所以本道题的差分约束问题 不存在环。且本题 不存在负权重。故可以采用 拓扑排序。
3、由于在采用拓扑排序时,使用的是最短路算法,故需要 建立边。(关于差分约束和拓扑排序,可参见基础题型 一本通:奖金
● 本题中的顶点即为站点,由于隐含公式
A
>
=
B
+
1
A >= B+1
A>=B+1,所以要 在不停靠站点和停靠站点之间建立边,且权重为+1。
● 由于有n个站点,所以需建立的边的最大数量为
(
n
/
2
)
∗
(
n
/
2
)
=
n
2
/
4
(n/2)*(n/2) = n^2/4
(n/2)∗(n/2)=n2/4。
● 当 n 达到1000时,
n
2
/
4
=
250000
n^2/4 = 250000
n2/4=250000。 也就是说每辆车最多建立
2.5
∗
1
0
5
2.5*10^5
2.5∗105条边,1000辆车就是
2.5
∗
1
0
8
2.5*10^8
2.5∗108 条边,会超时。
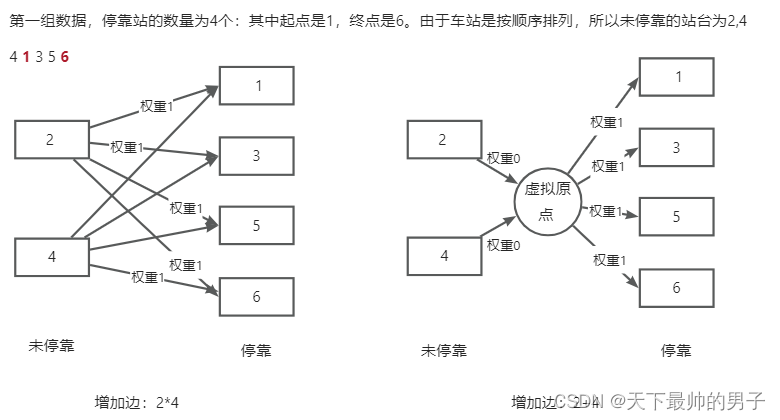
● 所以本题需要增加一个 虚拟原点,把不停靠和停靠的站点分割在两边(如下图所示)。这样可以把边的复杂度由 n ∗ m n*m n∗m 变为 n + m n+m n+m。也就是说,原本 ( n / 2 ) ∗ ( n / 2 ) (n/2)*(n/2) (n/2)∗(n/2) 的边的数量会变为 ( n / 2 ) + ( n / 2 ) (n/2)+(n/2) (n/2)+(n/2)。也就是说每辆车从最多建立 2.5 ∗ 1 0 5 2.5*10^5 2.5∗105条边,降到建立1000条边。1000辆车就是 1 0 6 10^6 106 条边,不会超时。
主流程
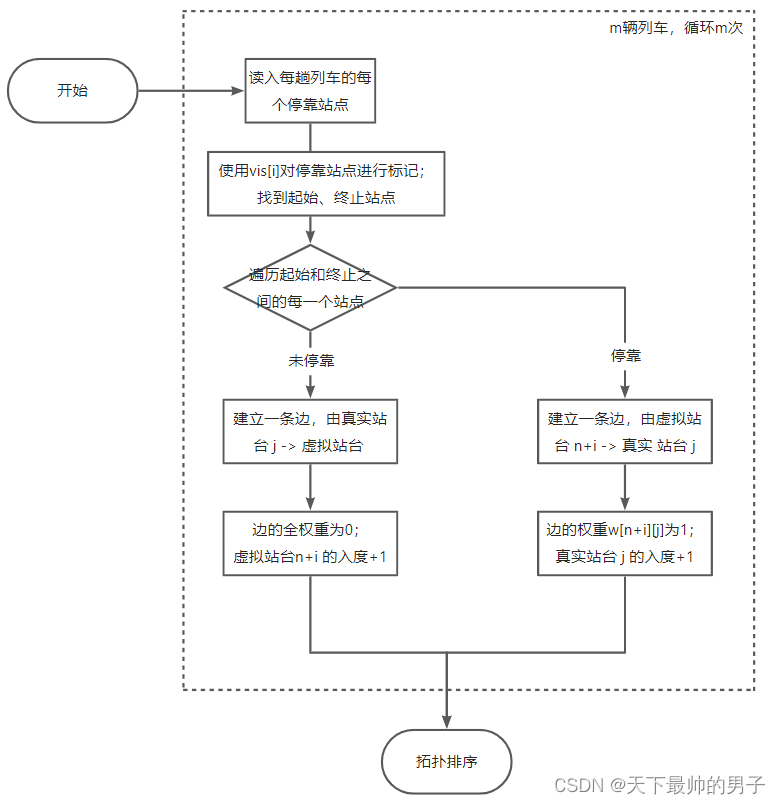
题解代码:
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 2010; // 真实站点的编号为 1 ~ n。虚拟站点的编号从 n 后面开始计算,每趟列车建立一个虚拟站点 n+i,最多到 n+m
int n, m, ans = 0;
// vis[i]=true 第i个站点被停靠; level[i]表示第i个车站的等级;du[i]表示第i个顶点的入度;e[v][j]=1 表示从v到j存在一条边; w[v][j]=1 表示从v到j的边的权重为1
int vis[MAXN], level[MAXN], du[MAXN], e[MAXN][MAXN], w[MAXN][MAXN];
queue<int> q;
void toposort()
{
// step1. 把所有入度为 0 的站点加入队列( n个真实站台 + m个虚拟站台 )
for(int i = 1; i <= n + m; i ++)
{
if (du[i] == 0)
{
q.push(i);
if(i <= n) level[i] = 1; // 如果入度为 0 的是真实站点,说明这么多趟车都没有停靠该站点,则该站点等级设为1( 虚拟站台等级为0 )
}
}
// step2. 栈顶元素v出栈;根据边 e[v][j]遍历 v 的每一个后继顶点 j
while (!q.empty())
{
int v = q.front(); // 取出栈顶元素,放在 v
q.pop();
for (int j = 1; j <= n + m; j ++) // 遍历所有顶点
{
if (e[v][j]) // 如果 v -> j 存在边
{
du[j]--; // 减少 j 点的入度(相当于删除 v->j 这条边)
if (du[j] == 0) // 如果删除 v->j 边后,j 的入度变为 0,则j入栈;同时 level[v] 传递给 level[j]
{
q.push(j);
level[j] = level[v] + w[v][j]; // j的站点等级 = v的站点等级+边的权重
}
}
}
}
}
int main()
{
scanf("%d%d", &n, &m);
for(int i = 1; i <= m; i ++)
{
int s, start, en, t; // s:每辆列车有s个站点要停靠。start:起点站,en:终点站
scanf("%d", &s);
memset(vis, 0, sizeof(vis)); // vis[i]=1 表示第i个站点被停靠; vis[i]=0 表示第i个站点不停靠
for(int j = 1; j <= s; j++) // 依次读入该趟列车的每个停靠站点
{
scanf("%d", &t); // 存储在t
vis[t] = 1; // vis[t]标记为停靠
if (j == 1) start = t; // 第一个读入的是该趟列车的起点站,存储在start
if (j == s) en = t; // 最后一个读入的是该趟列车的终点站,存储在en(end为关键字,故用en)
}
for(int j = start; j <= en; j++) // 对该趟列车起点站和终点站之间的每个站点,根据是否停靠建立与虚拟站点的边
{
if(vis[j] == 1) // 如果 j 号站点被停靠,则建立由虚拟站点 n+i 向 真实站点 j 的边,权值为1
{
e[n+i][j] = 1; // 建立一条边,由虚拟站台 n+i -> j站台
w[n+i][j] = 1; // 该边的权重为 1
du[j]++; // 真实站点 j 的入度 ++
}
else // 如果 j 号站点没有被停靠,则建立由真实站点 j 向虚拟站点 n+i 的边,权值为0
{
e[j][n+i] = 1; // 建立一条边,由 真实站点 j-> 虚拟站点 n+i ,边权为 0
w[j][n+i] = 0; // 该边的权重为 0
du[n+i]++; // 虚拟站点 n+i 的入度++
}
}
}
toposort(); // 拓扑排序
for(int i = 1; i <= n; i++)
ans = max(ans, level[i]);
cout << ans;
return 0;
}