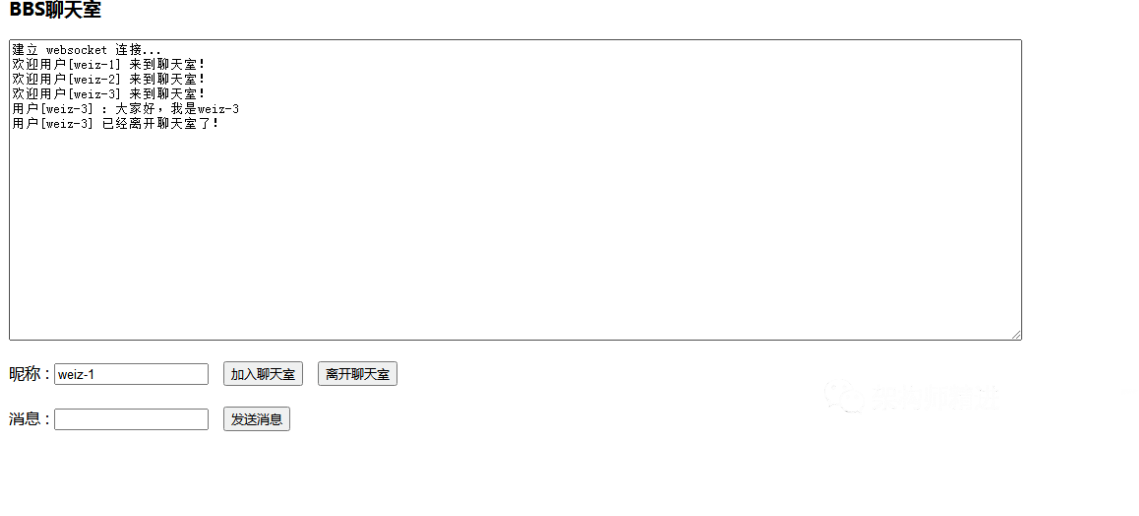
Multi-Attention Based Ultra Lightweight Image Super-Resolution
- 论文地址
- 摘要
- 1 简介
- 2 相关工作
- 3 建议的方法
- 3.1 特征融合组(FFG)
- 3.2 多注意力块(MAB)
- 4 Experimental Setup
- 4.1 消融研究
- 4.2 Comparison with Existing Methods
- 5 AIM2020高效SR挑战
- 6 限制和未来工作
- 7 结论
论文地址
1、源码
2、论文
基于多注意力的超轻量级图像超分辨率
摘要
轻量级图像超分辨率 (SR) 网络对于现实世界的应用具有极其重要的意义。有几种基于深度学习的 SR 方法具有显着的性能,但它们的内存和计算成本是实际使用中的障碍。为了解决这个问题,我们提出了一个多注意力特征融合超分辨率网络(MAFFSRN)。 MAFFSRN 由作为特征提取块的建议特征融合组 (FFG) 组成。每个 FFG 都包含一堆建议的多注意块 (MAB),它们组合在一个新颖的特征融合结构中。此外,具有成本效益的注意机制 (CEA) 的 MAB 帮助我们使用多种注意机制改进和提取特征。综合实验表明我们的模型优于现有的最新技术。我们使用我们的 MAFFSRN 模型参加了 AIM 2020 高效 SR 挑战赛,在内存使用、浮点运算 (FLOPs) 和参数数量方面分别获得了第一、第三和第四名。
关键词:超分辨率、特征提取、多-注意力,低计算资源,轻量级卷积神经网络
1 简介
本文重点讨论了单幅图像超分辨率(SISR)问题。在SISR中,我们的目标是从低分辨率(LR)图像重建高分辨率(HR)图像。我们将超分辨率(SR)与本文其余部分的SISR互换使用。根据[47],SISR问题在数学上可以写成:

其中 ILR 和 IHR 指的是给定的输入 LR 和期望的 HR 图像。方程式中的‘k’。 1) 表示模糊核,↓s 表示缩小算子,‘n’ 是高斯噪声。通过遵循以前的工作,我们假设图像是使用双三次插值 [2][52] 进行下采样的。
从单个 LR 图像到 HR 图像有多种可能的映射解决方案,这使得这个问题不适定。尽管存在不适定性,但像 [8,10,22] 这样的深度学习方法在这个领域取得了显着的成功。例如,只有三层的 SRCNN [8] 优于以前的非深度学习方法。随后,提出了更深层次和复杂的架构来提高 SR 方法的性能 [2,29,13,50,51]。尽管它们具有出色的性能,但由于它们的内存大小、操作数量和参数大,这些方法在实际应用中是不切实际的。
已经提出了许多轻量级模型来解决这些问题。 CARN [2] 引入了一种具有多个残差连接的轻量级高效级联残差网络。 FALSR [7] 采用网络架构搜索 (NAS) 技术,而不是在 SISR 域中手动搜索。 CBPN [52] 提出了 DBPN 网络 [13] 的高效版本,强调了 LR 图像的高分辨率特征的重要性。这些模型旨在降低计算成本,尽管所有这些模型都带有较小版本的模型,例如 CARN-M[2]、CBPN-S[52]、FALSR-B 和 FALSR-C[7] .因此,这表明他们的原始模型不适合实际应用。
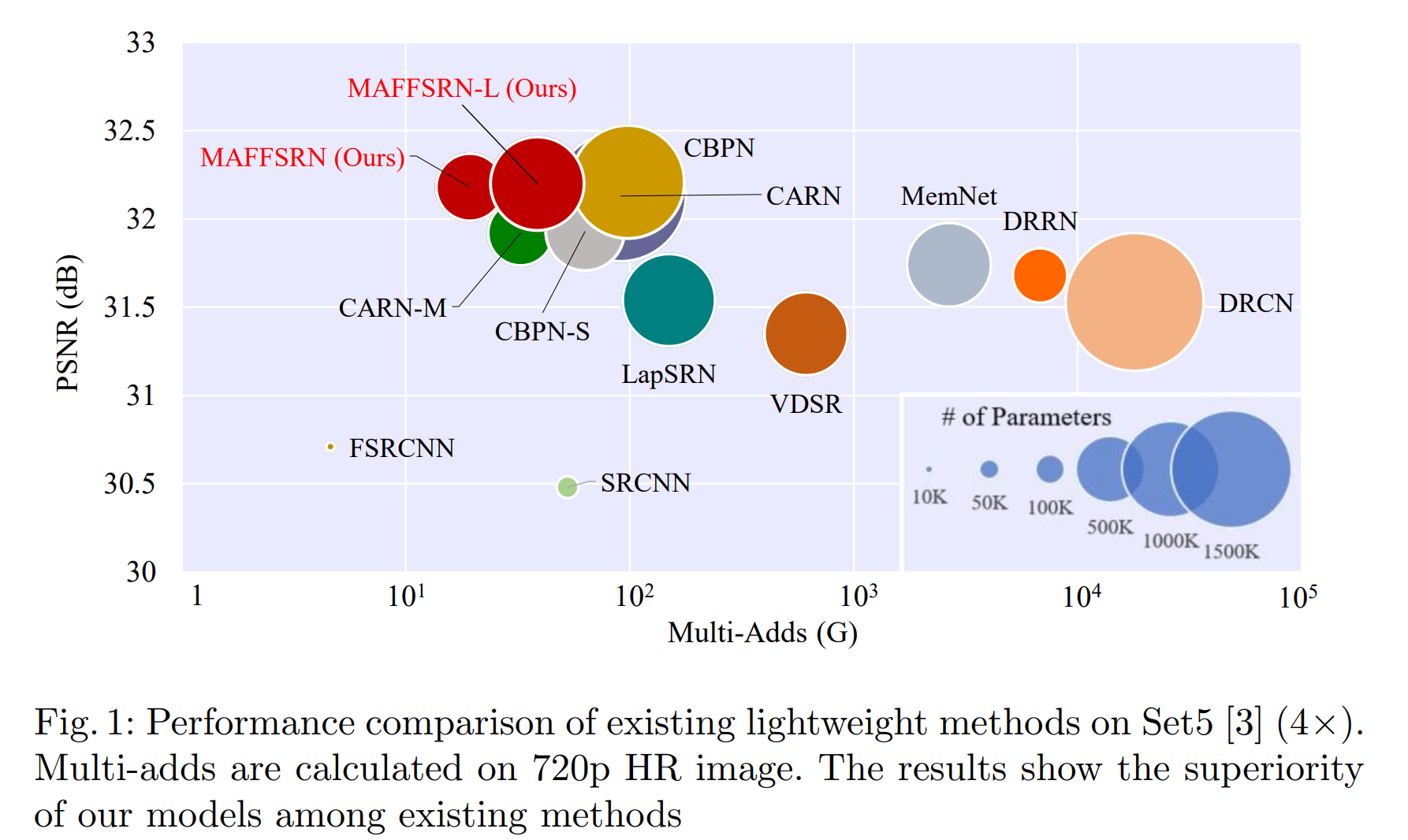
这种实用模型的需求促使我们提出一种称为 MAFFSRN 的轻量级模型。它的计算成本与 CARN-M、CBPN-S、FALSR-B、FALSR-C [2,52,7] 相似,但与它们相应的原始模型的性能相匹配。通过综合实验,我们表明我们的模型在所有基准数据集上都取得了最佳性能。此外,我们引入了一个大型模型 (MAFFSRN-L) 来将性能与最先进的重型方法进行比较。请注意,它的尺寸仍然小于现有的高效模型。我们在图 1 中显示了我们的基准测试结果。
我们的模型专门旨在最小化浮点运算 (FLOP) 和内存消耗等计算成本,同时最大化网络性能。
• 为了提高网络性能,我们利用由多个多注意块(MAB)组成的特征融合组(FFG)。
• 在 SR 深度网络架构中,重要信息在网络流动期间消失 [50]。我们的方法使用 FFG 和 MAB 解决了这个问题,结果表明它们使我们能够以最小的计算成本增加网络深度,从而提高网络性能。
下一个挑战是最小化计算成本和内存使用。
为此,我们建议对增强空间注意力 (ESA) 块 [30] 进行更改。
• 首先,我们引入了成本高效(CEA)块来直接在输入特征上应用注意力机制。
• 其次,我们用扩张卷积替换了 ESA [30] 的 Conv 组,以从大空间尺寸中获益。
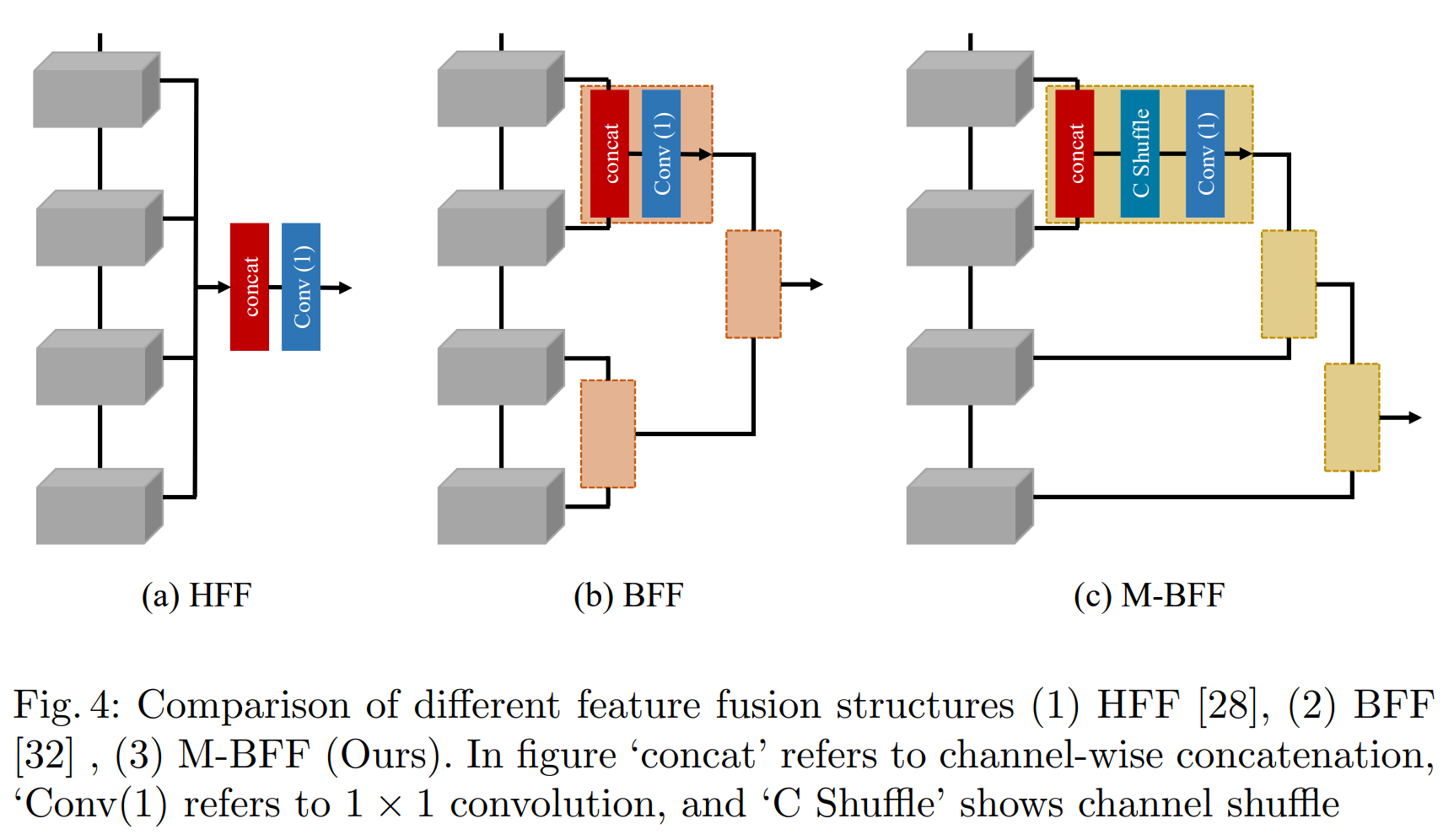
对于特征融合结构,我们在实验中发现分层特征融合(HFF)[27]的性能仍然低于二值化特征融合(BFF)[32]。
我们在消融研究中讨论了这些实验的细节。我们在基准数据集上评估我们的方法,并将性能与现有方法进行比较。
我们的总体贡献总结如下:
- 我们引入了一个轻量级模型,该模型由改进的 BFF、MAB 和 CEA 模块组成,优于现有方法。我们参加了 AIM 2020 SR 挑战赛 [46],我们的模型在内存消耗方面排名第一,在 FLOPS 方面排名第三,在参数数量方面排名第四。
2)我们在具有多个缩放因子(×2、×3 和×4)的基准数据集上提供了全面的定性和定量比较结果。
2 相关工作
深度神经网络在其他计算机视觉任务中取得的显著成功[17]、[14]、[6]鼓励了 SR 社区在 SR 领域应用深度学习技术。 SRCNN [8] 应用浅层神经网络并超越传统和传统的基于非深度学习的方法的性能。正如 [39] 表明深度网络比浅层网络表现出更好的结果,几种方法遵循这一趋势并提出了更深的网络。 VDSR [21] 提出了一个由全局跳过连接组成的 20 层网络,该网络逐元素地将上采样的 LR 图像添加到输出重建图像中。 EDSR [29] 改进了基于 ResNet 架构 [14] 的 SRResNet [26],方法是删除琐碎的层或那些会降低性能的层,例如 Batch Normalization [20]。 RDN 引入了类似于 DenseNet [18] 的密集连接,并以比 EDSR [29] 更少的参数提高了性能。当然,它们显着提高了图像保真度,例如 PSNR 或 SSIM,但是,具有低功耗计算设备的受限现实环境需要关注其他指标,例如参数数量、内存消耗、FLOP、延迟时间等。因此,人们越来越关注构建也需要准确的轻量级模型。一种策略是采用模型压缩技术来压缩模型 [12,16]。在本文中,我们的重点是开发一种新的网络架构来解决这个问题。因此,我们只讨论以前在 SR 域中解决此类问题的工作。这种轻量级架构的进展始于 FSRCNN [10]。它通过直接将 SR 网络应用于 LR 图像而不是上采样输入来提高 SRCNN [8] 的性能。它还通过删除高成本的上采样层来减少推理时间。 DRRN [35] 利用递归层来减少参数数量,同时保持网络深度。 CARN [2] 应用了几个剩余连接和递归层来降低计算成本。 FALSR [7] 在 SR 域中引入了自动神经架构搜索 (NAS) 策略,以提出用于受限环境的 SR 模型。 CBPN [52] 通过用像素洗牌层替换昂贵的上下投影模块,提出了 DBPN 网络 [13] 的高效版本。我们观察到所有这些方法都侧重于性能和计算成本之间的权衡,这导致他们提出了另一个更小版本的模型,例如 CBPN-S [52]、CARN-M [2]、FALSR-B [7]。然而,我们提出的方法实现了与其原始模型更好或相当的性能,而计算成本与其轻量级版本相比保持相同或更低。
3 建议的方法
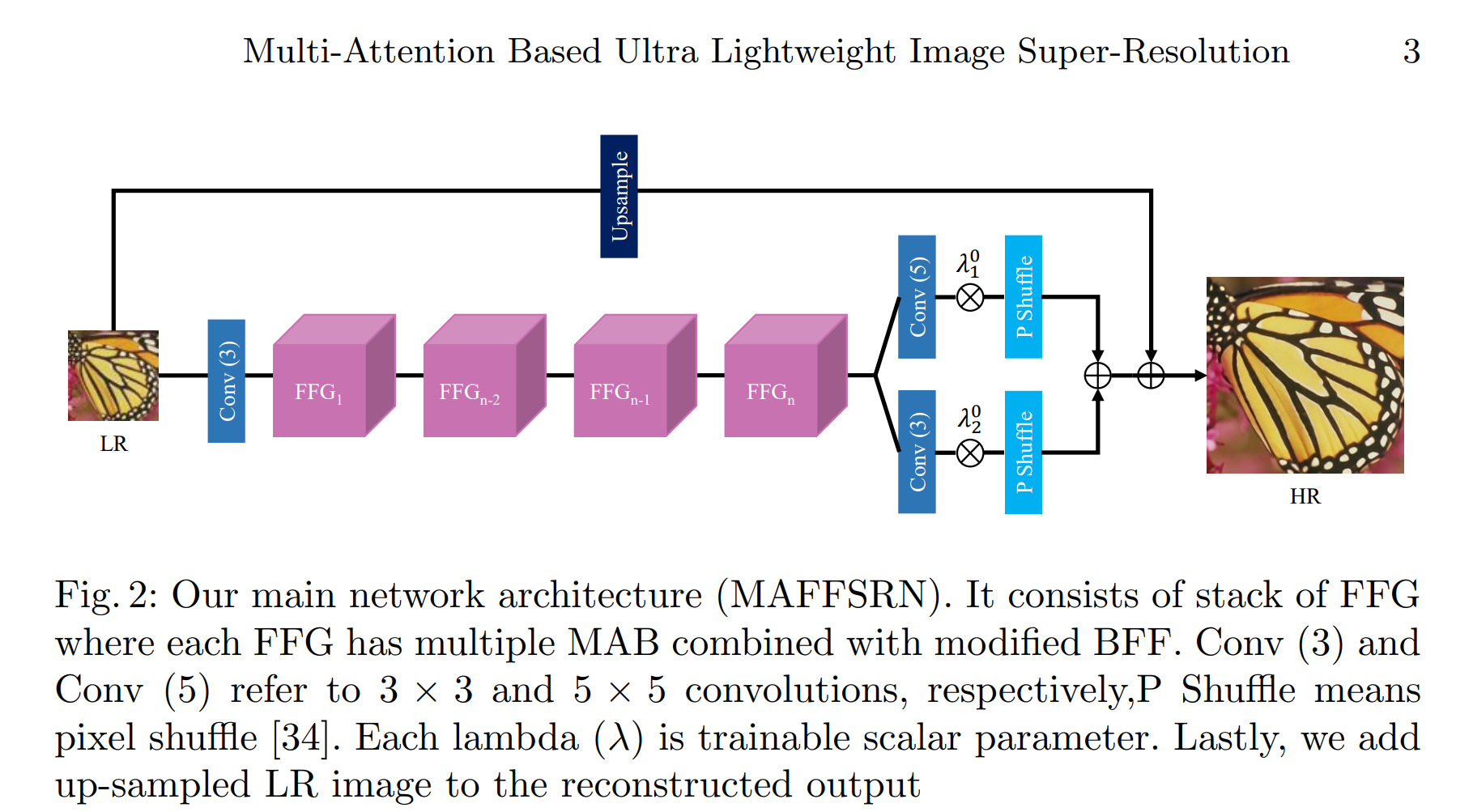
在本节中,我们将描述所建议架构的细节。如图 2 所示,我们的网络架构由 n 个按顺序堆叠的 FFG 组成。FFG的详细信息见第3.1节。我们在FFG之前使用一个卷积(Conv)层从输入LR中提取浅层特征图像。最后,我们应用几个具有不同过滤器大小的Conv层来减出多尺度特征,然后是像素随机层[34]。此外,在[40]的激励下,我们向两个Conv层添加权重(用λ01和λ02表示),以赋予特征权重,并将加权的特征传递给后来的外行者。稍后,将逐个元素添加结果信息。与 [21] 类似,我们将上采样 LR 输入逐个添加到输出层中。请注意,我们的整体架构主要基于 RDN 架构 [51],该架构由本地和全局块组成。对于给定的ILR图像,浅层特征提取步骤如下:

其中 fsf e 和 xsf e 分别表示 3 × 3 卷积和结果输出。接下来,对于非线性映射或深度特征提取步骤,我们应用 FFG 的堆栈如下
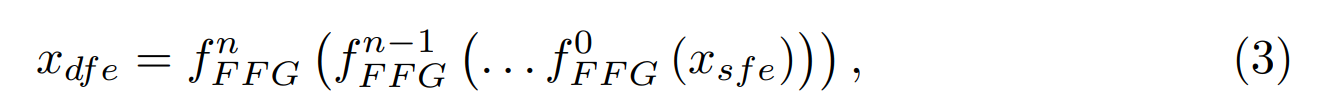
其中 fn 和 xdfe 表示深度特征提取的第 n 个 FFG 和输出分别。最后,重建阶段如下:
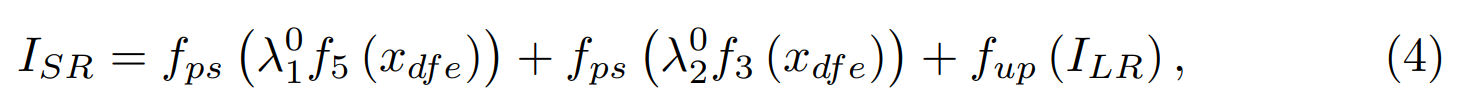
其中方程 4 中的符号详细信息如下:ISR 表示所需的 SR 图像,f3 和 f5 分别表示 3 × 3 和 5 × 5 个卷积,fps 表示像素随机层 [34],fup 表示上采样层,λ01 和 λ02 表示可训练的标量参数。
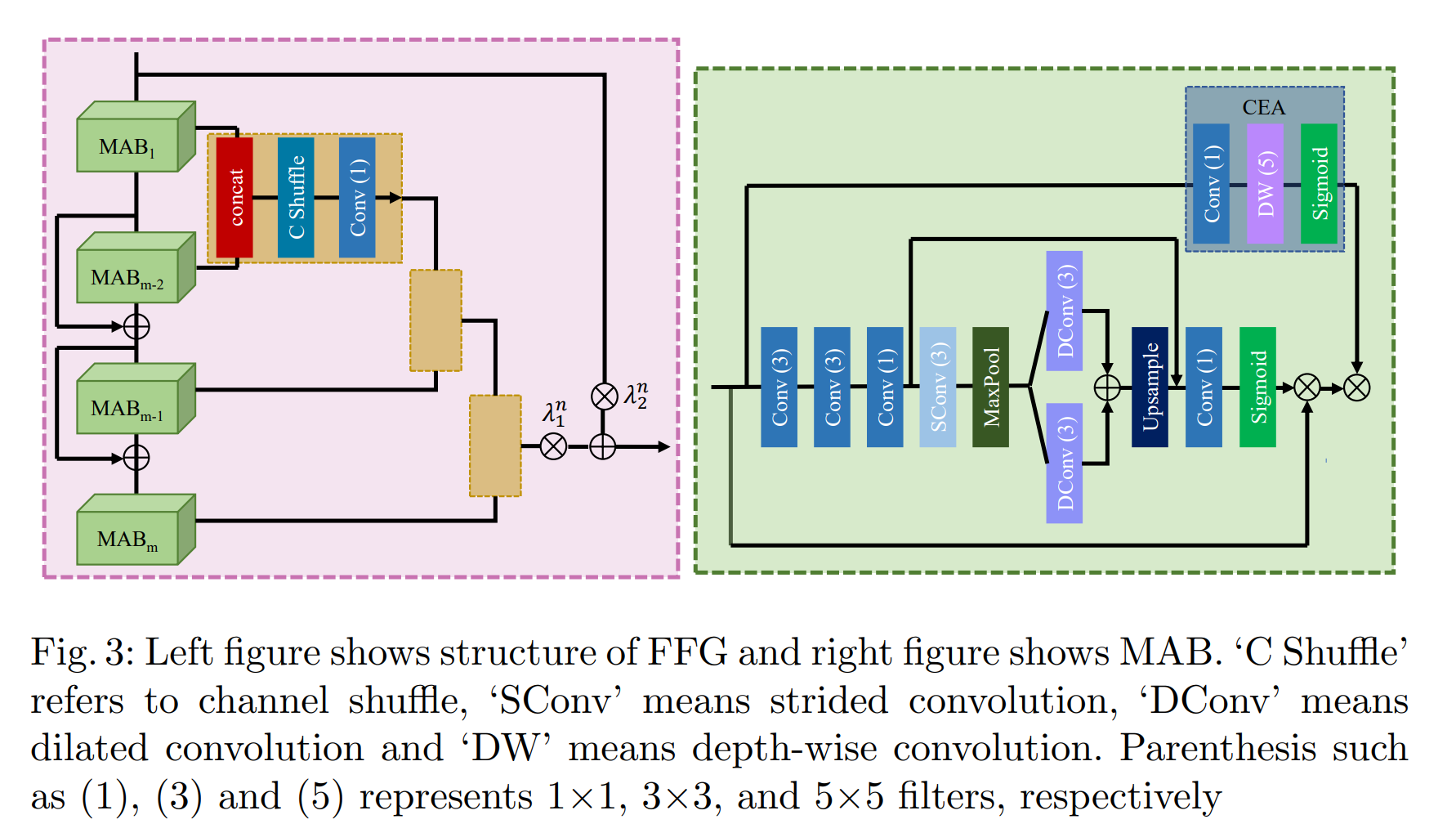
3.1 特征融合组(FFG)
我们提出的 FFG 有 m 个多注意力块(MAB)。 MAB 的详细信息将在下一节中讨论。所提出的 MAB 通过二值化特征融合 (BFF) 结构的修改形式组合 [32]。 HFF [28] 是另一种常用的融合结构,尽管在实验过程中我们发现 BFF [32] 的性能优于 HFF [28](详情在第 4.1 节中讨论)。我们将修改后的 BFF 称为 M-BFF。结构的比较如图 4 所示。在 BFF 中,所有相邻的块都像二叉树结构一样单独连接。相比之下,我们的 M-BFF 将生成的特征块与下一个 MAB 连接起来,如图 3 左侧所示。从 ShuffleNet [49] 中汲取灵感,应用通道混洗方法在组间混合信息,我们介绍通道洗牌以混合连接通道之间的信息,然后是通道缩减层,该层减少通道以使其等于输入通道的数量。最后,我们按元素将输入特征添加到输出特征。此外,残差连接可能包含冗余信息,因此为了过滤所需和有用的信息,我们将结果与可训练参数 λn1 和 λn2 相乘,其中 n 指的是第 n 个 FFG。
3.2 多注意力块(MAB)
在本节中,我们定义了我们提议的残差块的详细信息,称为MAB。[50]强调了信道注意(CA)机制的重要性。因此,许多SR方法都集中在注意力机制上,主要是CA和空间注意(SA)[43,23,32]。最近,[30]提出了一种CA和SA的组合解决方案,称为增强空间注意(ESA)。欧空局区块减少了 1×1 卷积的通道数和跨步卷积的空间大小。稍后,这些空间和通道大小会增加以匹配输入大小。最后,应用 sigmoid 操作来获得与通道注意机制类似的效果 [17]。我们修改了 ESA 块,通过引入具有不同滤波器大小的空洞卷积来使其更高效。此外,我们逐元素地将扩张卷积的所有输出特征相加,以最小化网格效应 [44]。
扩张卷积不仅减少了我们的内存计算,而且增加了空间滤波器的大小,使我们能够提高性能。
此外,我们引入了另一种具有成本效益的注意机制 (CEA) [4] 来改进我们的输入特征。 CEA 由点卷积和深度卷积组成。它被合并到 MAB 块中,以提高我们网络的性能,而额外的计算成本可以忽略不计。 MAB 的结构如图 3 右侧所示。
4 Experimental Setup
Implementation Details
由于我们专注于开发轻量级模型,我们的目标是最大化现有网络的性能并最小化它们的计算成本。我们将我们的原始模型表示为 MAFFSRN。此外,我们还介绍了更大的模型 MAFFSRN-L,以表明我们可以根据可用的计算资源来提高模型的性能。我们的轻量级模型 MAFFSRN 由 4 个 FFG 和 4 个 MAB 组成,而对于 MAFFSRN-L 模型,我们保留相同数量的 MAB,并将 FFG 增加到 8。我们将 MAB 中的通道数量减少了 4 倍,并设置步长 = 3 以减小空间大小。膨胀因子设置为 D = 1 和 D = 2。比例 λ 的值初始化为 0.5。我们将除最后一层之外的每个 Conv 层的过滤器数量设置为 32。对于最后一层,我们使用 3 个滤波器来重建 3 色图像。对于灰度图像,它可以修改为 1 个过滤器。训练设置我们使用 AdamP optmizer [15] 来训练我们的模型,初始学习率为 2×10−4。对于数据增强,我们应用标准技术,即图像水平或垂直翻转并随机旋转 90°、180°和 270°。这些模型训练了 1000 个 epoch,每 200 个 epoch 后学习率减半。我们将 batch-size 设置为 16,输入 patch size 为 48×48。我们在 PyTorch 上实现我们的网络并在 NVIDIA RX 2080TI GPU 上训练它并选择最佳性能模型。数据集我们使用高质量的 DIV2K [1] 数据集来训练我们的模型。它由 800 张训练图像的 LR 和 HR 对组成。 LR图像是通过双立方下采样。为了评估我们的模型,我们使用标准和公开可用的基准数据集,Set5 [3],Set14 [45],B100 [31]和Urban100 [19]数据集。Set5 [3]、Set14 [45]、B100 [31] 包含动物、人物和自然场景,而 Urban100 [19] 仅包含城市场景。评估指标我们使用变换后的YCbCr色彩空间的亮度或Y通道,通过遵循[21]来衡量PSNR和SSIM [42]重建的SR图像的性能。我们还计算参数和多加法的数量,以将所提出的模型与现有方法的计算复杂度进行比较。
4.1 消融研究
我们进行了一系列消融研究,以证明我们模型中使用的每个建议模块的重要性。对于所有这些实验,我们对我们的 MAFFSRN 模型进行了 1000 次全面训练。在第一个实验中,我们训练了多个具有相似设置的模型,以显示 M-BFF 和 CEA 的整体贡献。每次我们删除一个组件并在没有该特定模块的情况下测试网络性能。结果如表 1 所示。请注意,没有 M-BFF 的模型是指具有 HFF [27] 结构的模型,这是 SR 方法的常见选择。表 1 的第 2 行表明 M-BFF 仅使用 8K 附加参数就提高了 0.07 dB PSNR。同样,CEA 在 32K 参数下增加 0.05 dB。最后,当我们结合 CEA 和 M-BFF 时,我们的模型获得了 0.1 dB PSNR,附加参数少于 40K。请注意,为了公平比较,我们在所有三种方法中都添加了通道洗牌。为了证明通道洗牌在我们提出的 MAFFSRN 中的重要性,我们从 MAFFSRN 中删除了通道洗牌,并在表 2 中报告了结果。结果清楚地表明,使用通道洗牌,我们可以将性能提高到 0.04 PSNR。为了进一步评估,我们用不同类型的 Conv 层进行了实验,以显示扩张卷积在 MAB 中的功效。表 3 中的实验结果表明,我们的扩张卷积比三个卷积执行的结果更好卷积和令人惊讶的是,具有 5 × 5 个卷积的方法是最差的性能。原因可能是 Conv 层的结构,因为 3 × 3 和 5 × 5 个 Conv 层的元素添加与更有效地利用两层的扩张卷积相比没有显着优势。我们进一步进行了实验,比较了表4中的Adam [24]和AdamP [15],发现AdamP [15]在所有数据集上始终优于Adam[24]优化器,并且有很大的优势。
4.2 Comparison with Existing Methods
在本节中,我们展示了我们的定量和定性结果,并使用最先进的方法[8,10,21,22,33,25,35,11,5,7,48,2,52]在三个放大因子2×,3×和4×上比较了它们的表现。定量结果如表5所示。这些还包括操作数(多添加)和参数数,以显示模型复杂性。在 720pHR 图像上估计多次添加。结果表明,我们的轻量级MAFFSRN模型在多个数据集和比例因子上比其他方法具有更好的性能。请注意,我们的轻量级 MAFFSRN 模型的性能与消耗 2× 到 3× 计算资源的模型相当
此外,为了证明我们模型的优越性,我们将模型的性能(PSNR)和计算成本(Multi-Adds)与图1中的现有模型进行了比较。从图中可以明显看出,我们的方法在复杂性和PSNR方面都优于现有网络。值得请注意,我们的 MAFFSRN 模型甚至比 SRCNN [8] 包含更少的多添加,SRCNN [8] 是一个具有 3 层的浅层神经网络。我们在图5和图6中显示了我们的定性结果。在图5中,从输出结果可以看出,“狒狒”胡须的毛发被精确重建,而其他方法则显示出模糊的结果。类似的效果可以在图5的其他图像中看到,我们的方法展示了更好的结果。结果还包括PSNR以显示定性结果。此外,我们的方法在更大规模的4×中继续显示出改进的结果。总体而言,与现有方法相比,我们的方法显示出更好的结果。
5 AIM2020高效SR挑战
我们的模型是为参加AIM 2020高效SR挑战而开发的[46]。
本次竞赛旨在开发一种可在受限环境中使用的实用SR方法。目的是在DIV2K [37]验证集上维护MSResNet [41]的PSNR,同时降低其计算成本。我们提交了MAFFSRN模型来应对这个挑战,并在内存计算中获得了第一名,在FLOP中获得了第三名,在参数数量方面获得了第四名。我们在图7和表6中给出了结果。图 7 显示了 y 轴上的标准化分数和 x 轴上的最终参与者。它还指示我们提出的MAFFSRN模型是所有参与者中的轻量级模型。同样,我们显示了表 6 中按内存计算排序的前参与者的性能。请注意,内存计算是用 Py- torch 代码 torch.cuda 测试的.max内存分配() 和 FLOP 是用输入图像 256 × 256 计算的。
6 限制和未来工作
尽管降低了计算成本(内存消耗、FLOP、参数数量),但所提出的方法在 100 val 上的运行时间DIV2K 数据集 [37] 的识别图像每张图像 0.104 秒3。估计运行时间平均超过 100 张图像。我们认为这是我们网络中比其他高效架构更多的层的结果。尽管如此,所提出的方法是超轻量级的,其内存效率高的模块可以帮助未来的研究人员推进具有较低运行时间和更少内存消耗的高效SR架构。
7 结论
这项工作引入了一种用于约束环境的轻量级SR方法,称为MAFFSRN。我们通过一些定量和定性实验表明,MAFFSRN在性能和计算成本方面优于其他现有的轻量级模型。此外,我们提出了消融研究,以显示每个拟议模块的贡献。