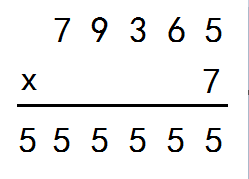目录
- Redis通用命令
- String类型常用的操作命令
- 一些特殊命令详解
- setnx
- 示例
- 使用
- setrange
- 示例
- mset
- 示例
- msetnx
- 示例
- append
- 示例
- getset
- 示例
- incr
- 示例
- 使用
- 1.计数器
- 2.限速器
- bitcount
- 示例
- 使用:使用 bitmap 实现用户上线次数统计
- 性能
- String类型
- String类型简介
- String类型的特性
- String应用场景
- String底层结构
- SDS介绍
- SDS结构
- SDS优势
Redis通用命令
| 命令 | 作用 | 语法格式 | 举个栗子 |
|---|---|---|---|
| keys | 查找所有符合给定模式 pattern 的 key | keys pattern | KEYS * 匹配数据库中所有 key KEYS t?? KEYS t[w]* KEYS *o* |
| exists | 检查给定 key 是否存在 | exists key | EXISTS nick_name |
| type | 返回 key 所储存的值的类型 | type key | TYPE page_views |
| randomkey | 从当前数据库中随机返回一个 key | randomkey | RANDOMKEY |
| expire | 为给定 key 设置生存时间,单位是秒 | expire key seconds | EXPIRE nick_name 120 |
| pexpire | 为给定 key 设置生存时间,单位是毫秒 | pexpire key milliseconds | PEXPIRE age 60000 |
| EXPIREAT | EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置生存时间。不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 | expireat key timestamp | EXPIREAT cache 1714060800000 这个 key 将在 2024-4-26过期 |
| PEXPIREAT | 这个命令和 EXPIREAT 命令类似,但它以毫秒为单位设置 key 的过期 unix 时间戳,而不是像 EXPIREAT 那样,以秒为单位 | pexpireat key milliseconds | PEXPIREAT cache 1714060800000000 |
| ttl | 以秒为单位,返回剩余生存时间 | ttl key | TTL nick_name |
| pttl | 以毫秒为单位,返回剩余生存时间 | pttl key | PTTL nick_name |
| PERSIST | 移除给定 key 的生存时间,将这个 key 从『可挥发』的(带生存时间 key )转换成『持久化』的(一个不带生存时间、永不过期的 key )。 | persist key | PERSIST nick_name |
| move | 将当前数据库的key移动到给定的数据库中 | move key db | MOVE goods_lock 3 |
| del | 删除给定的一个或多个 key | del key [key …] | DEL name type website |
| rename | 将 key 改名为 newkey,当 key 和 newkey 相同,或者 key 不存在时,返回一个错误。当 newkey 已经存在时,RENAME 命令将覆盖旧值 | rename key newkey | RENAME message msg |
| RENAMENX | 当且仅当 newkey 不存在时,将 key 改名为 newkey 。当 key 不存在时,返回一个错误 | renamenx key newkey | RENAMENX player best_player |
| flushdb | 清空当前库 | flushdb | flushdb |
| flushall | 清空所有库 | flushall | flushall |
String类型常用的操作命令
| 命令 | 作用 | 语法格式 | 举个栗子 |
|---|---|---|---|
| set | 添加一个键值对 | set key value | SET apple www.apple |
| get | 获取 key 所关联的字符串值 | get key GET apple | |
| mset | 同时设置多个key-value | mset <key1> <value1> <key2> <value2> … | MSET nick_name jack age 30 |
| mget | 获取多个key对应的值 | mget <key1> <key2> … | MGET nick_name age |
| append | 将给定的value追加到原值的末尾 | append key value | APPEND apple “.com” |
| setex | 将值 value 关联到 key ,并将 key的生存时间设为 seconds (以秒为单位) | setex key seconds value | SETEX cache_user 100 10086 |
| psetex | 将值 value 关联到 key ,并将 key的生存时间设为 milliseconds(以毫秒为单位) | psetex key milliseconds value | PSETEX cache_user_id 101 10000 |
| setnx | key不存在时,设置key的值,可以实现分布式锁 | setnx <key> <value> | SETNX goods_lock 1 |
| setrange | 覆盖指定位置的值 | setrange <key> <起始位置> <value> | SETRANGE nick_name 4 son |
| getrange | 获取指定范围的值,类似java中的substring | getrange key start end | GETRANGE nick_name 4 6 |
| strlen | 获取值的长度 | strlen <key> | STRLEN nick_name |
| incr | 原子递增1 | incr <key> | INCR page_views |
| decr | 原子递减1 | decr <key> | DECR page_views |
| incrby/decrby | 将key中存储的数字值递增/递减指定的步长,若key不存在,则相当于在原值为0的值上递增/递减指定的步长。 | incrby/decrby <key> <步长> | INCRBY page_views 5 DECRBY page_views 5 |
| getset | 以新换旧,设置新值同时返回旧值 | getset <key> <value> | GETSET nick_name tom |
| MSETNX | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。即使只有一个给定 key 已存在, MSETNX 也会拒绝执行所有给定 key 的设置操作。 | msetnx key value [key value …] | MSETNX rmdbs “MySQL” nosql “MongoDB” key-value-store “redis” |
一些特殊命令详解
setnx
- 语法:
setnx key value - 解释:
- 将 key 的值设为 value ,当且仅当 key 不存在。
- 若给定的 key 已经存在,则 SETNX 不做任何动作。
- SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
- 返回值
- 设置成功,返回 1 。
- 设置失败,返回 0 。
示例
127.0.0.1:6379[1]> exists task #task 不存在
(integer) 0
127.0.0.1:6379[1]> setnx task do-something #此时task能够设置成功
(integer) 1
127.0.0.1:6379[1]> setnx task do-other #尝试覆盖task,但是失败
(integer) 0
127.0.0.1:6379[1]> get task #获取task,还是第一次设置的值
"do-something"
127.0.0.1:6379[1]>
使用
可以将 SETNX 用于加锁(locking)
- 警告:已经证实这个加锁算法带有竞争条件,在特定情况下会造成错误,请不要使用这
个加锁算法。 - SETNX 可以用作加锁原语(locking primitive)。比如说,要对关键字(key) foo 加锁,
客户端可以尝试以下方式:SETNX lock.foo <current Unix time + lock timeout + 1> - 如果 SETNX 返回 1 ,说明客户端已经获得了锁, key 设置的 unix 时间则指定了锁失
效的时间。之后客户端可以通过 DEL lock.foo 来释放锁。 - 如果 SETNX 返回 0 ,说明 key 已经被其他客户端上锁了。如果锁是非阻塞(non
blocking lock)的,我们可以选择返回调用,或者进入一个重试循环,直到成功获得锁或重
试超时(timeout)。
处理死锁(deadlock)
-
上面的锁算法有一个问题:如果因为客户端失败、崩溃或其他原因导致没有办法释放锁
的话,怎么办? -
这种状况可以通过检测发现——因为上锁的 key 保存的是 unix 时间戳,假如 key 值
的时间戳小于当前的时间戳,表示锁已经不再有效。 -
但是,当有多个客户端同时检测一个锁是否过期并尝试释放它的时候,我们不能简单粗
暴地删除死锁的 key ,再用 SETNX 上锁,因为这时竞争条件(race condition)已经形成了:- C1 和 C2 读取 lock.foo 并检查时间戳,SETNX 都返回 0 ,因为它已经被 C3 锁上了,但 C3 在上锁之后就崩溃(crashed)了。C1 向 lock.foo 发送 DEL 命令。
- C1 向 lock.foo 发送 SETNX 并成功。
- C2 向 lock.foo 发送 DEL 命令。
- C2 向 lock.foo 发送 SETNX 并成功。
- 出错:因为竞争条件的关系,C1 和 C2 两个都获得了锁。幸好,以下算法可以避免以上问题。来看看我们聪明的 C4 客户端怎么办:
- C4 向 lock.foo 发送 SETNX 命令。
- 因为崩溃掉的 C3 还锁着 lock.foo ,所以 Redis 向 C4 返回 0 。
- C4 向 lock.foo 发送 GET 命令,查看 lock.foo 的锁是否过期。如果不,则休眠(sleep)一段时间,并在之后重试。
- 另一方面,如果 lock.foo 内的 unix 时间戳比当前时间戳老,C4 执行以下命令:
GETSET lock.foo <current Unix timestamp + lock timeout + 1> - 因为 GETSET 的作用,C4 可以检查看 GETSET 的返回值,确定 lock.foo 之前储存的旧值仍是那个过期时间戳,如果是的话,那么 C4 获得锁。
- 如果其他客户端,比如 C5,比 C4 更快地执行了 GETSET 操作并获得锁,那么 C4 的 GETSET 操作返回的就是一个未过期的时间戳(C5 设置的时间戳)。C4 只好从第一步开始重试
-
注意,即便 C4 的 GETSET 操作对 key 进行了修改,这对未来也没什么影响。
-
警告:为了让这个加锁算法更健壮,获得锁的客户端应该常常检查过期时间以免锁因诸如 DEL 等命令的执行而被意外解开,因为客户端失败的情况非常复杂,不仅仅是崩溃这么简单,还可能是客户端因为某些操作被阻塞了相当长时间,紧接着 DEL 命令被尝试执行(但这时锁却在另外的客户端手上)。
setrange
- 语法:setrange key offset value
- 解释:
- 用 value 参数覆写(overwrite)给定 key 所储存的字符串值,从偏移量 offset 开始。不存在的 key 当作空白字符串处理。
- SETRANGE 命令会确保字符串足够长以便将 value 设置在指定的偏移量上,如果给定key 原来储存的字符串长度比偏移量小(比如字符串只有 5 个字符长,但你设置的 offset 是 10 ),那么原字符和偏移量之间的空白将用零字节(zerobytes, “\x00” )来填充。
- 注意你能使用的最大偏移量是2^29-1(536870911) ,因为 Redis 字符串的大小被限制在 512 兆(megabytes)以内。如果你需要使用比这更大的空间,你可以使用多个 key
- 警告:当生成一个很长的字符串时,Redis 需要分配内存空间,该操作有时候可能会造成服务器阻塞(block)。在 2010 年的 Macbook Pro 上,设置偏移量为 536870911(512MB 内存分配),耗费约 300 毫秒,设置偏移量为 134217728(128MB 内存分配),耗费约 80 毫秒,设置偏移量33554432(32MB 内存分配),耗费约 30 毫秒,设置偏移量为 8388608(8MB 内存分配),耗费约 8 毫秒。注意若首次内存分配成功之后,再对同一个 key 调用 SETRANGE 操作,无须再重新内存。
- 时间复杂度:对小(small)的字符串,平摊复杂度 O(1)。(关于什么字符串是”小”的,请参考APPEND 命令)否则为 O(M), M 为 value 参数的长度
- 返回值:被 SETRANGE 修改之后,字符串的长度。
示例
127.0.0.1:6379[1]> set str "hello world"
OK
127.0.0.1:6379[1]> SETRANGE str 6 "redis" #对非空字符串进行 SETRANGE
(integer) 11
127.0.0.1:6379[1]> get str
"hello redis"
127.0.0.1:6379[1]> exists empty_str #对空字符串/不存在的 key 进行 SETRANGE
(integer) 0
127.0.0.1:6379[1]> SETRANGE empty_str 5 "redis" #对不存在的 key 进行 SETRANGE
(integer) 10
127.0.0.1:6379[1]> get empty_str # 空白处被"\x00"填充
"\x00\x00\x00\x00\x00redis"
127.0.0.1:6379[1]>
因为有了 SETRANGE 和 GETRANGE 命令,你可以将 Redis 字符串用作具有 O(1)随机访问时间的线性数组,这在很多真实用例中都是非常快速且高效的储存方式
mset
- 语法:mset key value [key value …]
- 解释:
- 同时设置一个或多个 key-value 对。
- 如果某个给定 key 已经存在,那么 MSET 会用新值覆盖原来的旧值,如果这不是你所希望的效果,请考虑使用 MSETNX 命令:它只会在所有给定 key 都不存在的情况下进行设置操作。
- MSET 是一个原子性(atomic)操作,所有给定 key 都会在同一时间内被设置,某些给定key 被更新而另一些给定 key 没有改变的情况,不可能发生。
- 时间复杂度:O(N), N 为要设置的 key 数量。
- 返回值:总是返回 OK (因为 MSET 不可能失败)
示例
127.0.0.1:6379[1]> mset str hellochina date 2024-4-26 time "9:57"
OK
127.0.0.1:6379[1]> mget str date time
1) "hellochina"
2) "2024-4-26"
3) "9:57"
127.0.0.1:6379[1]>
msetnx
- 语法:msetnx key value [key value …]
- 解释:
- 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
- 即使只有一个给定 key 已存在, MSETNX 也会拒绝执行所有给定 key 的设置操作。
- MSETNX 是原子性的,因此它可以用作设置多个不同 key 表示不同字段(field)的唯一性逻辑对象(unique logic object),所有字段要么全被设置,要么全不被设置。
- 时间复杂度:O(N), N 为要设置的 key 的数量。
- 返回值:当所有 key 都成功设置,返回 1 。如果所有给定 key 都设置失败(至少有一个 key 已经存在),那么返回 0
示例
127.0.0.1:6379[1]> msetnx job dev str hellojava use springboot
(integer) 0
127.0.0.1:6379[1]> msetnx job dev use springboot
(integer) 1
127.0.0.1:6379[1]> mget job use
1) "dev"
2) "springboot"
127.0.0.1:6379[1]>
append
- 语法:append key value
- 解释:
- 如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。
- 如果 key 不存在, APPEND 就简单地将给定 key 设为 value ,就像执行 SET key value 一样。
- 时间复杂度:平摊 O(1)
- 返回值:追加 value 之后, key 中字符串的长度
示例
127.0.0.1:6379[1]> exists phone # 对不存在的 key 执行 APPEND
(integer) 0
127.0.0.1:6379[1]> append phone apple # 对不存在的 key 执行 APPEND,等同于 SET phone "apple"
(integer) 5 # 字符长度
127.0.0.1:6379[1]> append phone "- 17" # 对已存在的字符串进行 APPEN
(integer) 9 # 长度从 5 个字符增加到 9 个字符
127.0.0.1:6379[1]> get phone
"apple- 17"
127.0.0.1:6379[1]>
- 解析:
- APPEND 可以为一系列定长(fixed-size)数据(sample)提供一种紧凑的表示方式,通常称之为时间序列。每当一个新数据到达的时候,执行以下命令:
APPEND timeseries "fixed-size sample" - 然后可以通过以下的方式访问时间序列的各项属性:
- STRLEN 给出时间序列中数据的数量
- GETRANGE 可以用于随机访问。只要有相关的时间信息的话,我们就可以在 Redis 2.6 中使用 Lua 脚本和 GETRANGE 命令实现二分查找。
- SETRANGE 可以用于覆盖或修改已存在的的时间序列。
- 这个模式的唯一缺陷是我们只能增长时间序列,而不能对时间序列进行缩短,因为Redis 目前还没有对字符串进行修剪(tirm)的命令,但是,不管怎么说,这个模式的储存方式还是可以节省下大量的空间
- APPEND 可以为一系列定长(fixed-size)数据(sample)提供一种紧凑的表示方式,通常称之为时间序列。每当一个新数据到达的时候,执行以下命令:
- 注:可以考虑使用 UNIX 时间戳作为时间序列的键名,这样一来,可以避免单个 key 因为保存过大的时间序列而占用大量内存,另一方面,也可以节省下大量命名空间
getset
- 语法:getset key value
- 解释
- 将给定 key 的值设为 value ,并返回 key 的旧值(old value)。
- 当 key 存在但不是字符串类型时,返回一个错误。
- 时间复杂度:O(1)
- 返回值:返回给定 key 的旧值。当 key 没有旧值时,也即是, key 不存在时,返回 nil 。
示例
127.0.0.1:6379[1]> getset db mysql # 没有旧值,返回 nil
(nil)
127.0.0.1:6379[1]> get db
"mysql"
127.0.0.1:6379[1]> getset db redis
"mysql"
127.0.0.1:6379[1]> get db
"redis"
127.0.0.1:6379[1]>
- 使用:
-
GETSET 可以和 INCR 组合使用,实现一个有原子性(atomic)复位操作的计数器(counter)。
-
举例来说,每次当某个事件发生时,进程可能对一个名为 mycount 的 key 调用 INCR 操作,通常我们还要在一个原子时间内同时完成获得计数器的值和将计数器值复位为 0 两个操作。
-
可以用命令 GETSET mycounter 0 来实现这一目标
...... 127.0.0.1:6379[1]> incr mycount (integer) 10 127.0.0.1:6379[1]> getset mycount 0 "10" 127.0.0.1:6379[1]> get mycount "0" 127.0.0.1:6379[1]>
-
incr
- 语法:incr key
- 解释
- 将 key 中储存的数字值增一。
- 如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作。
- 如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。
- 本操作的值限制在 64 位(bit)有符号数字表示之内。
- 注:这是一个针对字符串的操作,因为 Redis 没有专用的整数类型,所以 key 内储存的字符串被解释为十进制 64 位有符号整数来执行 INCR 操作。
- 时间复杂度:O(1)
- 返回值:执行 INCR 命令之后 key 的值
示例
127.0.0.1:6379[1]> set currentPage 5
OK
127.0.0.1:6379[1]> incr currentPage
(integer) 6
127.0.0.1:6379[1]> get currentPage
"6"
127.0.0.1:6379[1]>
使用
1.计数器
- 计数器是 Redis 的原子性自增操作可实现的最直观的模式了,它的想法相当简单:每当某个操作发生时,向 Redis 发送一个 INCR 命令。
- 比如在一个 web 应用程序中,如果想知道用户在一年中每天的点击量,那么只要将用户 ID 以及相关的日期信息作为键,并在每次用户点击页面时,执行一次自增操作即可。
- 比如用户名是 peter ,点击时间是 2024 年 4 月 22 日,那么执行命令:
INCR peter::2024.4.22 。 - 可以用以下几种方式扩展这个简单的模式:
- 可以通过组合使用 INCR 和 EXPIRE ,来达到只在规定的生存时间内进行计数(counting)的目的。
- 客户端可以通过使用 GETSET 命令原子性地获取计数器的当前值并将计数器清零,更多信息请参考 GETSET 命令。
- 使用其他自增/自减操作,比如 DECR 和 INCRBY ,用户可以通过执行不同的操作增加或减少计数器的值,比如在游戏中的记分器就可能用到这些命令
2.限速器
-
限速器是特殊化的计算器,它用于限制一个操作可以被执行的速率(rate)。
-
限速器的典型用法是限制公开 API 的请求次数,以下是一个限速器实现示例,它将 API 的最大请求数限制在每个 IP 地址每秒钟十个之内
FUNCTION LIMIT_API_CALL(ip) ts = CURRENT_UNIX_TIME() keyname = ip+":"+ts current = GET(keyname) IF current != NULL AND current > 10 THEN ERROR "too many requests per second" END IF current == NULL THEN MULTI INCR(keyname, 1) EXPIRE(keyname, 1) EXEC ELSE INCR(keyname, 1) END PERFORM_API_CALL() -
这个实现每秒钟为每个 IP 地址使用一个不同的计数器,并用 EXPIRE 命令设置生存时间(这样 Redis 就会负责自动删除过期的计数器)。
-
注意,我们使用事务打包执行 INCR 命令和 EXPIRE 命令,避免引入竞争条件,保证每次调用 API 时都可以正确地对计数器进行自增操作并设置生存时间。
-
以下是另一个限速器实现:
FUNCTION LIMIT_API_CALL(ip): current = GET(ip) IF current != NULL AND current > 10 THEN ERROR "too many requests per second" ELSE value = INCR(ip) IF value == 1 THEN EXPIRE(ip,1) END PERFORM_API_CALL() END -
这个限速器只使用单个计数器,它的生存时间为一秒钟,如果在一秒钟内,这个计数器的值大于 10 的话,那么访问就会被禁止。
-
这个新的限速器在思路方面是没有问题的,但它在实现方面不够严谨,如果我们仔细观察一下的话,就会发现在 INCR 和 EXPIRE 之间存在着一个竞争条件,假如客户端在执行INCR 之后,因为某些原因(比如客户端失败)而忘记设置 EXPIRE 的话,那么这个计数器就会一直存在下去,造成每个用户只能访问 10 次,这简直是个灾难!
-
要消灭这个实现中的竞争条件,我们可以将它转化为一个 Lua 脚本,并放到 Redis 中运行(这个方法仅限于 Redis 2.6 及以上的版本):
local current current = redis.call("incr",KEYS[1]) if tonumber(current) == 1 then redis.call("expire",KEYS[1],1) end -
通过将计数器作为脚本放到 Redis 上运行,我们保证了 INCR 和 EXPIRE 两个操作的原子性,现在这个脚本实现不会引入竞争条件,它可以运作的很好。
-
关于在 Redis 中运行 Lua 脚本的更多信息,请参考 EVAL 命令。
-
还有另一种消灭竞争条件的方法,就是使用 Redis 的列表结构来代替 INCR 命令,这个方法无须脚本支持,因此它在 Redis 2.6 以下的版本也可以运行得很好:
FUNCTION LIMIT_API_CALL(ip) current = LLEN(ip) IF current > 10 THEN ERROR "too many requests per second" ELSE IF EXISTS(ip) == FALSE MULTI RPUSH(ip,ip) EXPIRE(ip,1) EXEC ELSE RPUSHX(ip,ip) END PERFORM_API_CALL() END -
新的限速器使用了列表结构作为容器, LLEN 用于对访问次数进行检查,一个事务包裹着 RPUSH 和 EXPIRE 两个命令,用于在第一次执行计数时创建列表,并正确设置地设置过期时间,最后, RPUSHX 在后续的计数操作中进行增加操作。
bitcount
- 语法:bitcount key [start] [end]
- 解释:
- 计算给定字符串中,被设置为 1 的比特位的数量。
- 一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。
- start 和 end 参数的设置和 GETRANGE 命令类似,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位,以此类推。
- 不存在的 key 被当成是空字符串来处理,因此对一个不存在的 key 进行 BITCOUNT 操作,结果为 0 。
- 时间复杂度:O(N)
- 返回值:被设置为 1 的位的数量。
示例
127.0.0.1:6379[1]> bitcount bits
(integer) 0
127.0.0.1:6379[1]> setbit bits 0 1 # 0001
(integer) 0
127.0.0.1:6379[1]> bitcount bits
(integer) 1
127.0.0.1:6379[1]> setbit bits 3 1 # 1001
(integer) 0
127.0.0.1:6379[1]> bitcount bits
(integer) 2
127.0.0.1:6379[1]>
使用:使用 bitmap 实现用户上线次数统计
- Bitmap 对于一些特定类型的计算非常有效。
- 假设现在我们希望记录自己网站上的用户的上线频率,比如说,计算用户 A 上线了多少天,用户 B 上线了多少天,诸如此类,以此作为数据,从而决定让哪些用户参加 beta 测试等活动 —— 这个模式可以使用 SETBIT 和 BITCOUNT 来实现。
- 比如说,每当用户在某一天上线的时候,我们就使用 SETBIT ,以用户名作为 key ,将那天所代表的网站的上线日作为 offset 参数,并将这个 offset 上的为设置为 1 。
- 举个例子,如果今天是网站上线的第 100 天,而用户 peter 在今天阅览过网站,那么执行命令
SETBIT peter 100 1;如果明天 peter 也继续阅览网站,那么执行命令SETBIT peter 101 1,以此类推。 - 当要计算 peter 总共以来的上线次数时,就使用 BITCOUNT 命令:执行
BITCOUNT peter,得出的结果就是 peter 上线的总天数。
性能
- 前面的上线次数统计例子,即使运行 10 年,占用的空间也只是每个用户 10*365 比特位(bit),也即是每个用户 456 字节。对于这种大小的数据来说, BITCOUNT 的处理速度就像 GET 和 INCR 这种 O(1) 复杂度的操作一样快。
- 如果你的 bitmap 数据非常大,那么可以考虑使用以下两种方法:
- 将一个大的 bitmap 分散到不同的 key 中,作为小的 bitmap 来处理。使用 Lua 脚本可以很方便地完成这一工作。
- 使用 BITCOUNT 的 start 和 end 参数,每次只对所需的部分位进行计算,将位的累积工作(accumulating)放到客户端进行,并且对结果进行缓存 (caching)。
String类型
String类型简介
- Redis 的 String 数据类型是最基本的数据类型,它在内部使用 SDS(Simple Dynamic String)实现。String 类型的值可以是字符串、整数或者浮点数,并且可以对整个字符串或者字符串的其中一部分执行操作。
- Redis 中的 string 是直接按照二进制数据的方式进行存储的,也就是说不会进行任何编码转化,存的是啥,取出来还是啥(不同于 mysql ,插入中文就会失败).
- 不仅可以存储文本数据、整数、普通文本字符串、JSON、xml,还可以存储二进制数据(图片、视频、音频…),但是 Redis 对于 string 类型限制了大小最大是 512M(不要记这个数字,因为可以配置),一般不会存放像音频视频这种比较大的数据,因为 Redis 是单线程模型,希望进行的操作都能比较迅速.
String类型的特性
以下是 Redis String 数据类型的一些主要特性:
- 二进制安全:String 类型的值可以包含任何数据,例如 jpg 图片或者序列化的对象,因为Redis不会对字符串类型的值做任何解析,而是将其看作是一个字节数组;
- 最大容量:Redis 的 String 类型的值最大可以存储 512MB 的内容;
- 原子操作:Redis 的很多操作都是原子的,也就是说,这些操作要么全部执行,要么全部不执行,不会出现部分执行的情况。这对于并发环境下的操作是非常有用的;
- 整数和浮点数操作:Redis 提供了一些操作,可以将字符串解析为整数或者浮点数,并执行自增或者自减操作
String应用场景
- 缓存:由于Redis的高性能特性,String类型常常被用作缓存,可以将数据库查询结果、网页内容、会话信息等缓存在Redis中,提高系统的读取速度;
- 计数器:Redis的String类型可以将值解析为整数,并提供了自增(INCR)和自减(DECR)操作,因此可以作为各种计数器使用,例如网页访问量、下载量等;
- 分布式锁:通过 “SET key value”(只有当 key 不存在时才设置 value)命令,可以实现分布式锁,保证系统的并发安全;
- 分布式共享:可以将需要在多个系统间共享的数据存储在 Redis 的 String 类型中,例如用户的会话信息等;
- 限流:通过 INCR 命令和 EXPIRE 命令,可以实现 API 的限流功能,防止系统被过度访问,例如以访问者的 ip 和其他信息作为 key,访问一次增加一次计数,超过次数则返回 false
String底层结构
SDS介绍
Redis 使用 SDS 简单动态字符串(Simple Dynamic String,SDS)来表示字符串,Redis 中字符串类型包含的数据结构有:“整数(R_INT)” 与 “字符串(R_RAW)”
SDS 被广泛应用在 Redis 的各个地方,包括:
- 作为字符串对象的底层实现: 在 Redis 中,所有的键都是字符串,而值可以是五种类型之一,其中包括字符串类型。这些字符串类型的键和值都是由 SDS 实现的;
- 作为缓冲区: Redis 的客户端和服务器在进行通信时,会使用 SDS 作为输入缓冲区和输出缓冲区,用于存储待发送的命令或者待返回的结果;
- 作为 AOF 模块的缓冲区: Redis 的 AOF(Append Only File,只追加文件)持久化功能,会把所有修改数据库的命令追加到 AOF 文件的末尾。在追加命令时,Redis 会先把命令追加到一个 SDS 中,然后再把 SDS 写入到 AOF 文件。
SDS结构
SDS(Simple Dynamic String,简单动态字符串)是 Redis 自己构建的抽象字符串类型,其在 C 语言原生字符串类型的基础上进行了一些改进和扩展。SDS 的主要结构如下
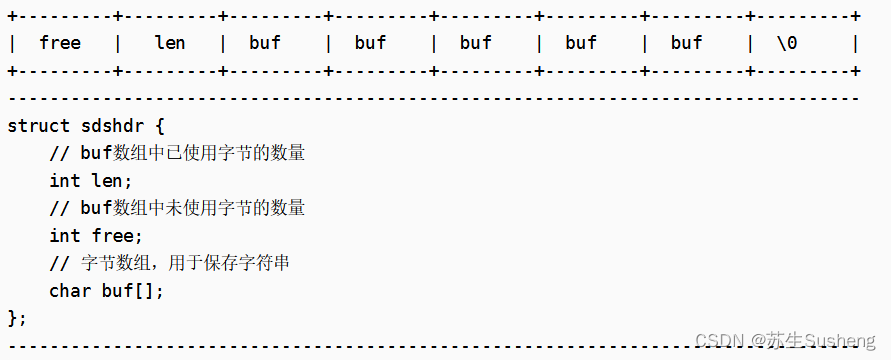
| 属性 | 说明 |
|---|---|
| free | 表示 Buf 数组中未使用字节的数量,也就是 Buf 数组的剩余空间。这样可以在增加字符串长度时,避免频繁的内存重新分配 |
| len | 表示 Buf 数组中已使用字节的数量,也就是字符串的长度。这样可以在 O(1) 的时间复杂度内获取字符串长度,而不需要像 C 语言字符串那样遍历整个字符串 |
| buf[] | 字节数组,用于保存字符串。这个数组的末尾总是包含一个空字符(‘\0’),这样 SDS 就可以兼容 C 语言的字符串函数 |
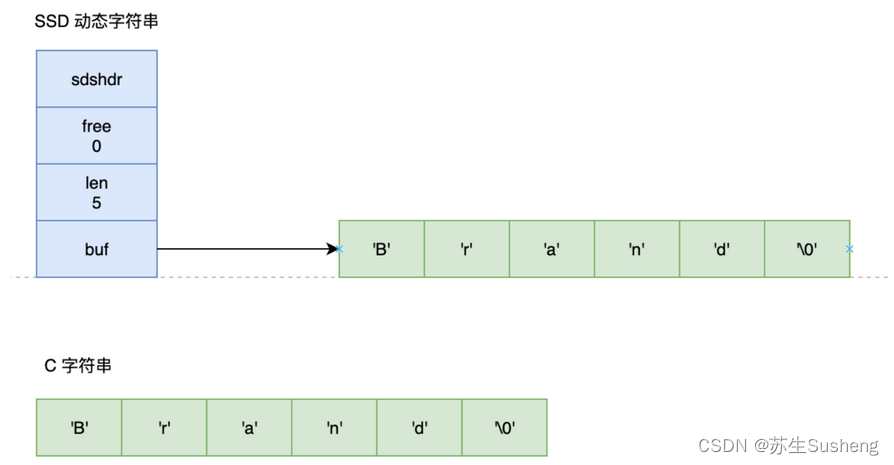
这种设计使得 SDS 在保持与 C 语言字符串兼容的同时,具有更高的效率和更好的安全性。对比参照如下:
SDS优势
- 获取长度的时间复杂度为 O(1):SDS 内部维护了一个 len 属性,这个属性记录了字符串的长度,因此获取字符串长度的时间复杂度为 O(1),而 C 字符串需要遍历整个字符串才能获取到长度,时间复杂度为 O(n);
- 内存效率:SDS 通过维护一个 free 属性,记录了 buf 数组中未使用的字节数量,这样可以在需要扩展字符串时,直接使用这些未使用的空间,而不需要重新分配内存,提高了内存的使用效率;
- 避免缓冲区溢出:SDS在进行字符串修改操作时,会先检查缓冲区是否满足条件,如果不满足,会自动扩展缓冲区,因此可以避免缓冲区溢出的问题。而C字符串则需要程序员自己保证不会发生缓冲区溢出;
- 减少内存重新分配的次数:SDS通过空间预分配和惰性空间释放两种策略,减少了内存重新分配的次数。空间预分配是在修改字符串时,如果需要改变字符串长度,除了为修改后的字符串分配所需的空间外,还会分配额外的未使用空间;惰性空间释放是在缩短字符串时,不立即释放多余的空间,而是等待将来使用。这两种策略都可以减少内存重新分配的次数,提高效率;
- 二进制安全:C 字符串是以空字符 ‘\0’ 作为结束标志,因此不能正确存储包含 ‘\0’ 的字符串。而 SDS 的每一个字符都可以是 ‘\0’,因此 SDS 可以存储任何二进制数据;
- 兼容部分 C 字符串函数:SDS 在保证自身特性的同时,仍然保留了对部分 C 字符串函数的兼容性,这样可以方便地在 SDS 和 C 字符串之间进行转换。