一、字符串
实际上C语言中实际上是没有内置的字符串类型的,大部分字符串都是以字符型数组和常量字符串的形式存在的。
字符串可以通过多种方式在C语言中声明和初始化:
直接初始化:
char greeting[] = "Hello, world!";在这个例子中,greeting是一个字符数组,自动计算所需的大小以容纳字符串"Hello, world!"及其结尾的空字符\0。
指定数组大小:
char buffer[50] = "Hello";这里,buffer是一个大小为50的字符数组,初始化时只有前5个字符被设置为"Hello",第6个字符为空字符\0,其余字符因不完全初始化而初始化为\0。
指针指向字符串字面量:
const char *message = "Hello, world!";message是一个指向字符的指针,指向字符串字面量"Hello, world!"的首字符。注意,字符串字面量存储在程序的只读部分,因此通过指针修改字符串内容可能会导致未定义行为。
二、字符串相关函数
C语言的库中提供了很多字符串处理函数:
1、strlen
函数原型:
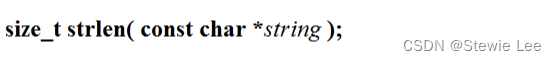
以 \0 为终止标志,计算并返回字符串的长度,不包括终止的空字符。传的字符串必须有\0,当且仅当以\0结尾时会返回正确的字符串的长度。
#include <stdio.h>
#include <string.h>
int main()
{
char str[20] = "Hello";
int len = strlen(str);
printf("%zu\n", len);
return 0;
}运行结果:

对于其返回值类型 size_t 是 usigned int 的别名,是一种无符整形,这里有一个点要注意:
下面程序的运行结果:
#include <stdio.h>
#include <string.h>
int main()
{
if (strlen("abc") - strlen("abcdef") > 0)
{
printf(">\n");
}
else
{
printf("<\n");
}
return 0;
}这里凭直觉判断,3 - 6 = -3 应当小于零,应该返回 < 啊,可是运行结果是:

为什么呢?就是因为这里的 strlen 的返回值是无符整形,所以这里经过运算后,结果是 -3 ,但是实际上:

对于4294967293是大于零的,所以会打印 > 。
2、strcpy
函数的原型:
 将
将 strSourse 指向的字符串复制到 strDestination 指向的位置,遇到\0就会停止,包括终止的空字符。strDestination 必须有足够的空间(而且这里的目标空间必须是可改动的)来接收复制的字符。传的 Sourse 字符串必须有\0,当且仅当以\0结尾时会拷贝正确的字符串到 Destination 中。
#include <stdio.h>
#include <string.h>
int main()
{
char buffer[20] = { 0 };
strcpy(buffer, "zhangsan");
printf("%s\n", buffer);
return 0;
}运行结果:

模拟这个函数的构成:
#include <stdio.h>
#include <assert.h>
char* my_strcpy(char* strDestination, const char* strSourse)
{
assert(strDestination);
assert(strSourse);
char* retValue = strDestination;
while (*strSourse != '\0')
{
*strDestination++ = *strSourse++;
}
*strDestination = '\0';
return retValue;
}
int main()
{
char buffer[20] = { 0 };
printf("%s\n", my_strcpy(buffer, "zhangsan"));
return 0;
}运行结果:

3、strcat
在C语言中,strcat 是一个标准的库函数,该名称是 "string concatenate" 的缩写,意为“字符串连接”。strcat 函数的功能是将一个字符串(source string)连接(append)到另一个字符串(destination string)的末尾。完成操作后,目标字符串将包含连接后的新字符串,而源字符串保持不变。
函数原型:

strDestination:目标字符串数组的指针,它应该有足够的空间来容纳连接后的结果。
strSourse:源字符串的指针,该字符串将被连接到目标字符串的末尾。
使用 strcat 函数时,必须确保目标字符串数组有足够的空间来存放两个字符串连接后的结果,以及额外的空字符(null terminator)'\0',这是C字符串的结束标记。 如果目标数组没有足够的空间,可能会导致缓冲区溢出,这是常见的安全问题。而且目标字符数组需要可改动,而且源字符串要有\0,只有源字符串以\0结尾时可以正常链接。连接时会把目标字符串的\0覆盖,以使字符串可以被完整访问。
#include <stdio.h>
#include <string.h>
int main()
{
char buffer[20] = "Hello ";
//append the string "World!" to the string "Hello " in buffer
strcat(buffer, "World!");
printf("%s\n", buffer);
return 0;
}模拟实现该函数:
#include <stdio.h>
#include <assert.h>
char* my_strcat(char* strDestination, const char* strSourse)
{
assert(strDestination);
assert(strSourse);
char* retValue = strDestination;
while (*strDestination != '\0')
{
strDestination++;
}
while (*strSourse != '\0')
{
*strDestination++ = *strSourse++;
}
*strDestination = '\0';
return retValue;
}
int main()
{
char buffer[20] = "Hello ";
//append the string "World!" to buffer
printf("%s\n", my_strcat(buffer, "World!"));
return 0;
}运行结果:

4、strcmp
在C语言中,strcmp 是 "string compare" 的缩写,它的功能是比较两个字符串。strcmp 函数按字典顺序比较两个字符串,并返回一个整数来表示这两个字符串的相对顺序。
函数原型:

string1:指向第一个要进行比较的以 \0 结尾的字符串的指针。
string2:指向第二个要进行比较的以 \0 结尾的字符串的指针。
strcmp 函数比较通过 str1 和 str2 指针传入的两个字符串。比较是基于字符串中相应字符的无符号字符值按字典顺序进行的。会从两个字符串的第一个字符开始,并按顺序比较对应位置的字符。比较是基于字符的ASCII值进行的。函数会逐个字符地比较,直到发现不同的字符或者遇到字符串的结束符 \0。

当 str1 小于 str2 时,返回值小于 0。
当 str1 等于 str2 时,返回值等于 0。
当 str1 大于 str2 时,返回值大于 0。
#include <stdio.h>
#include <string.h>
int main()
{
char buffer1[20] = "abcdef";
char buffer2[20] = "abcdeg";
if (strcmp(buffer1, buffer2) == 0)
{
printf("等于\n");
}
else if (strcmp(buffer1, buffer2) > 0)
{
printf("大于\n");
}
else
{
printf("小于\n");
}
return 0;
}运行结果:

模拟这个函数:
#include <stdio.h>
#include <assert.h>
int my_strcmp(const char* string1, const char* string2)
{
assert(string1);
assert(string2);
while (*string1 && *string2)
{
if (*string1 > *string2)
{
return 1;
}
else if (*string1 < *string2)
{
return -1;
}
string1++;
string2++;
}
if (*string1 == '\0' || *string2 != '\0')
{
return -1;
}
else if (*string1 != '\0' || *string2 == '\0')
{
return 1;
}
else
{
return 0;
}
}
int main()
{
char buffer1[20] = "abcdef";
char buffer2[20] = "abcdeg";
if (my_strcmp(buffer1, buffer2) == 0)
{
printf("等于\n");
}
else if (my_strcmp(buffer1, buffer2) > 0)
{
printf("大于\n");
}
else
{
printf("小于\n");
}
return 0;
}运行结果:

5、strncpy
n 表示 "number" 或者 "counted",意味着该函数是进行有限数量字符的字符串拷贝。strncpy 的功能是从源字符串复制多达 n 个字符到目标字符串,如果源字符串的长度小于 n,剩余的部分将用空字符 \0 填充。
函数原型:
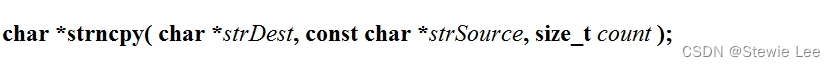
strDest:指向用于存储复制内容的目标数组的指针。
strSourse:指向要复制的源字符串的指针。
count:要复制的最大字符数。
如果 strSourse 的长度小于 count,strncpy 将剩余的部分用 \0 填充,直到总共复制了 count 个字符。如果 strSourse 的长度大于或等于 count,则目标字符串中不会自动包含空字符(null-terminating character)。如果等于,源字符串会被复制到目的字符数组中,且不会加上\0,如果大于,就只会复制前 count 个源字符串到目的字符数组中,不会加上\0。
小于的情况:
#include <stdio.h>
#include <string.h>
int main()
{
char buffer1[20] = "abcdefghi";
char buffer2[20] = "git";
strncpy(buffer1, buffer2, 5);
printf("%s\n", buffer1);
return 0;
}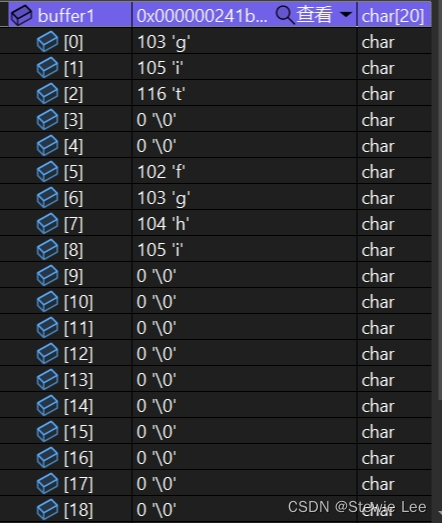
可以看到剩余的部分用\0填充了。
等于的情况:
#include <stdio.h>
#include <string.h>
int main()
{
char buffer1[20] = "abcdefghi";
char buffer2[20] = "Hello";
strncpy(buffer1, buffer2, 5);
printf("%s\n", buffer1);
return 0;
}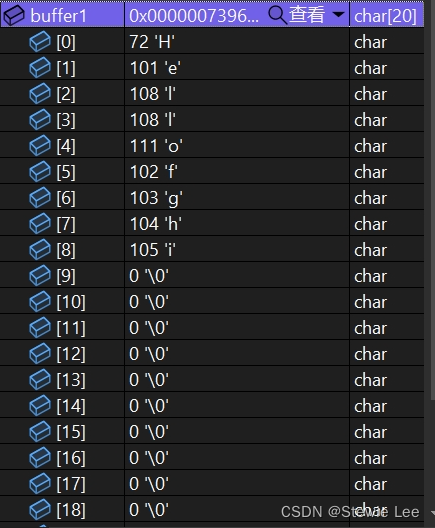
Hello后面没有加\0。
大于的情况:
#include <stdio.h>
#include <string.h>
int main()
{
char buffer1[20] = "abcdefghi";
char buffer2[20] = "Hello World!";
strncpy(buffer1, buffer2, 5);
printf("%s\n", buffer1);
return 0;
}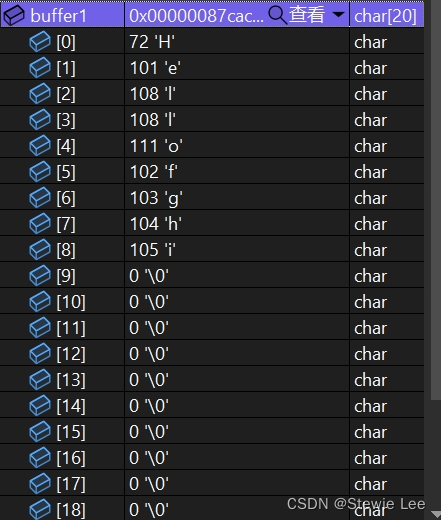
只复制了前5个字符没有加\0。
6、strncat
n 表示限制拼接的最大字符数量,cat 是 concatenate(连接)的缩写。该函数的功能是将一定数量的字符从源字符串拼接到目标字符串的末尾。
函数原型:
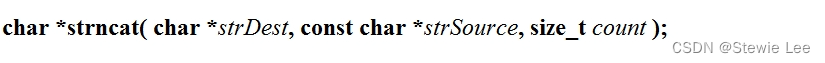
strDest:目标字符串的指针,即将被追加内容的字符串。该字符串应有足够的空间来存储额外的字符,包括拼接后的新字符串和空终止符 \0。
strSourse:源字符串的指针,即要追加到目标字符串后面的字符串。
count:最多从源字符串追加的字符数。如果 strSourse 的长度少于 count,则只追加到源字符串的结束位置。
strncat工作原理:
- 查找
strDest字符串的空终止符\0的位置,即字符串的末尾。 - 从该位置开始,将
strSourse字符串中的字符逐个追加到strDest,但不超过count个字符。 - 追加操作完成后,无论是因为追加了
count个字符还是因为strSourse达到了字符串末尾,strncat都会在新的strDest字符串末尾添加一个空终止符\0。
#include <stdio.h>
#include <string.h>
int main()
{
char buffer1[20] = "xxxxx\0xxxxxxxxxxx";
char buffer2[20] = "Hello";
strncat(buffer1, buffer2, 5);
printf("%s\n", buffer1);
return 0;
}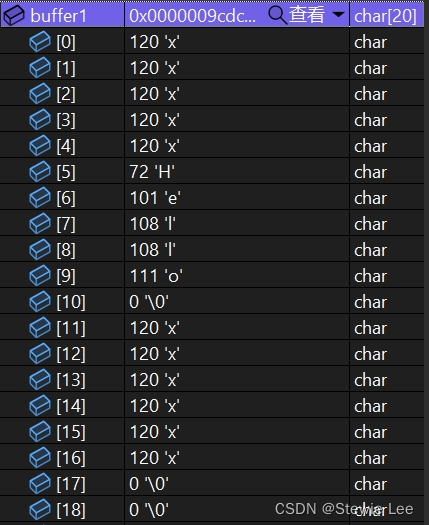
可以看到在Hello后面加了一个\0。
7、strncmp
n 表示进行比较的最大字符数,而 cmp 是 compare(比较)的缩写。该函数的功能是比较两个字符串的前 n 个字符,以确定它们是否相等或者一个字符串是否在字典顺序上小于或大于另一个字符串。
函数原型:
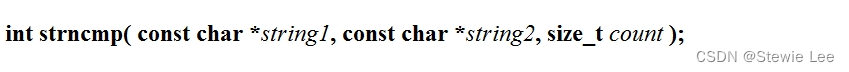
string1:指向第一个要比较的字符串的指针。
string2:指向第二个要比较的字符串的指针。
count:比较的最大字符数。
strncmp 函数按照字典顺序比较两个字符串的前 count 个字符或直到遇到空终止符 \0。如果两个字符串在比较的范围内完全相同,则函数返回 0。如果在比较的字符中,string1 字符串在字典顺序上小于 string2 字符串,函数返回一个小于 0 的值。相反,如果 string1 字符串在字典顺序上大于 string2 字符串,函数返回一个大于 0 的值。
#include <stdio.h>
#include <string.h>
int main()
{
char buffer1[20] = "xxxxx";
char buffer2[20] = "Hello";
int res = strncmp(buffer1, buffer2, 5);
if (res > 0)
{
printf("大于\n");
}
else if (res < 0)
{
printf("小于\n");
}
else
{
printf("等于\n");
}
return 0;
}运行结果:

8、strstr
strstr 函数是 C 语言标准库中的一个函数,用于在一个字符串内搜索另一个子字符串的首次出现。其名称中的 str 代表字符串(string),第二个 str 表示它在搜索另一个字符串。该函数的功能是返回子字符串在主字符串中的首次出现的位置的指针。如果子字符串未被找到,则返回 NULL。
函数原型:

也可以是这样:
char *strstr(const char *haystack, const char *needle);这是一个很生动的比喻,在一个干草垛中寻找一根针。
haystack:指向主字符串的指针。
needle:指向子字符串的指针。
当 needle 是一个空字符串时,strstr 通常返回 haystack 的指针,因为空字符串被视作在任何字符串的开始位置都可以找到。
#include <stdio.h>
#include <string.h>
int main()
{
char buffer[20] = "Hello World!";
char substr[20] = "World";
printf("%s\n", strstr(buffer, substr));
return 0;
}运行结果:

模拟实现这个函数:
#include <stdio.h>
#include <assert.h>
char* my_strstr(const char* string, const char* substr)
{
assert(string && substr);
if (!*substr)
{
return (char*)string;
}
const char* p = string;
const char* s1 = string;
const char* s2 = substr;
while (*p)
{
s1 = p;
s2 = substr;
while (*s1 == *s2 && *s2)
{
s1++;
s2++;
}
if (!*s2)
{
return (char*)p;
}
p++;
}
return NULL;
}
int main()
{
char buffer[110] = "abbbckgfkjgs;lgdjf";
char substr[20] = "bbc";
if (my_strstr(buffer, substr) == NULL)
{
printf("未找到\n");
}
else
{
printf("%s\n", my_strstr(buffer, substr));
}
return 0;
}运行结果:

该函数在两个字符串 string 和 substr 之间进行搜索,以找到子字符串 substr 在字符串 string 中的首次出现,并返回一个指向该出现处的指针。如果未找到子字符串,则返回 NULL。
这个函数首先通过断言(assert)检查输入的字符串指针是否非空。然后,检查 substr 是否是空字符串,如果是,根据 strstr 的标准行为,直接返回输入的 string。
在主循环中,p 指针遍历 string,而 s1 和 s2 分别用于在每个新的位置上与 substr 进行比较。如果在这个过程中 s1 和 s2 所指向的字符始终相等,且 s2 到达了子字符串的结尾(这意味着子字符串完全匹配),则返回当前 p 指针指向的地址,这表示找到了子字符串的位置。
如果在任何时候 s1 和 s2 所指向的字符不相等,或者在 s2 到达子字符串的结尾之前 s1 遇到了原字符串的结尾,循环就会移动 p 指针到下一个位置,并重新开始比较。
如果 string 遍历完成后,没有找到 substr,则函数返回 NULL。
9、strtok
strtok 函数是一个标准的C语言库函数,定义在 <string.h> 头文件中。它用于将一个字符串分解成一系列的标记(token)。strtok 函数通过接受一组指定的分隔符来分割字符串,每次调用返回字符串中的下一个标记。
函数原型:

功能:
- 分割字符串:
strtok通过一组预定义的分隔符来逐个分割字符串,每次调用返回字符串中的下一个标记。 - 状态保持:
strtok在内部使用静态变量保存当前的位置状态,所以它在连续调用时能够继续从上次分割的位置开始处理字符串。这也意味着strtok在同一时间只能用于一个字符串的分割,它是非线程安全的。
使用方法:
- 首次调用:首次调用
strtok时,第一个参数是要分割的字符串,第二个参数是一个包含所有分隔符的字符串。函数将返回指向第一个标记的指针。 - 连续调用:之后的调用中,第一个参数应该传递
NULL,以告诉函数继续处理原先的字符串,第二个参数保持不变。当字符串中不再有标记时,函数返回NULL。
这里的一系列分割符是指一个字符串,该字符串包含了所有用于切分输入字符串的字符。当strtok在工作时,它会检查输入字符串中的每个字符,看它是否出现在分割符字符串中。如果是,那么该字符会被视为分隔符,并在此处将输入字符串分割,每个分割点都会被替换为字符串结束符\0,从而使得每个分割出来的部分都成为了一个独立的子字符串或称为“标记”。
举个例子,如果分隔符字符串是 " ,.-!",那么strtok将会使用空格、逗号、点、破折号和感叹号作为分隔符来分割输入字符串。这意味着,如果输入字符串是 "Hello, world! Welcome to the C programming language.",使用上述分隔符字符串调用strtok将会得到以下标记序列:
"Hello"
"world"
"Welcome"
"to"
"the"
"C"
"programming"
"language"每次调用strtok时,它会返回上述标记中的一个,从左到右依次返回,直到没有更多的标记可返回,此时strtok将返回NULL。
示例:
#include <stdio.h>
#include <string.h>
int main()
{
char str[100] = "Hello, world! Welcome to the C programming language.";
char delimit[10] = " !,.";
char copy[100];
strcpy(copy, str);//使用原来字符串的拷贝
char* token = strtok(copy, delimit);
while (token != NULL)
{
printf("%s\n", token);
token = strtok(NULL, delimit);
}
return 0;
}运行结果:

注意事项:
strtok会修改原始字符串,通过在每个标记后面插入'\0'来分割字符串。所以一般使用原始字符串的拷贝。- 它不是线程安全的,因为内部使用了静态变量来保存当前的状态。在多线程程序中使用
strtok_r(一个线程安全的变体)是更好的选择。 - 因为
strtok会修改原始字符串,所以如果原始字符串是一个字符串字面量或位于只读内存区,尝试使用strtok分割这样的字符串会导致未定义行为,包括程序崩溃。
10、strerror
strerror 函数是 C 语言标准库中的一个函数,用于将错误代码(通常是整数)转换成一个可读的错误消息字符串。这个函数定义在 <string.h> 头文件中,是处理错误代码时非常有用的工具。它可以帮助程序员理解和调试程序中出现的错误。
函数原型:

功能:
- 错误代码转换:
strerror根据传入的错误代码(通常来源于其他函数调用的错误返回值),返回一个指向描述该错误的字符串的指针。 - 提高可读性:错误代码本身通常是整数值,直接输出给用户或者在调试过程中查看这些代码,可能不够直观。
strerror使得错误信息更加易于理解。
使用方法:
- 参数
errnum:错误代码,通常是一个整数值,例如来自系统调用失败的返回值。 - 返回值:指向一个字符串的指针,该字符串描述了相应错误代码的错误消息。这个字符串不应该被修改或释放,因为它可能指向一个静态分配的字符串。
示例:
假设你在调用某个需要打开文件的函数时遇到了错误,你可以使用 errno(定义在 <errno.h>)来获取最后的错误代码,然后使用 strerror 来获取可读的错误消息。
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main()
{
FILE *fp = fopen("nonexistentfile.txt", "r");
if (fp == NULL)
{
int err_code = errno;
printf("Error opening file: %s\n", strerror(err_code));
}
else
{
// 处理成功打开文件的情况
fclose(fp);
}
return 0;
}在这个示例中,如果文件不存在,fopen 函数将失败并设置 errno。strerror(errno) 会返回一个描述错误的字符串,比如 "No such file or directory",然后这个错误消息被输出到控制台。
运行结果:
![]()
注意事项
strerror返回的字符串不应该被修改;它可能指向静态存储区域,修改可能导致未定义行为。- 在多线程环境中,使用
strerror可能不是线程安全的,因为它可能返回一个指向静态存储的指针,这可能会在多线程中被覆盖。为了解决这个问题,某些环境提供了strerror_r函数,这是一个线程安全的版本。
11、字符分类函数
在C语言中,字符分类函数主要包含在ctype.h头文件中。这些函数用于检测字符的类型,例如是否为字母、数字等。使用这些函数可以简化对字符属性的判断,提高代码的可读性和效率。以下是一些常用的字符分类函数及其功能:
isalpha(int c)- 检查给定的字符是否是字母(包括小写和大写字母)。isdigit(int c)- 检查给定的字符是否是数字(0到9)。isalnum(int c)- 检查给定的字符是否是字母或数字。isspace(int c)- 检查给定的字符是否是空白字符,例如空格、制表符、换页符、换行符和回车符。islower(int c)- 检查给定的字符是否是小写字母。isupper(int c)- 检查给定的字符是否是大写字母。iscntrl(int c)- 检查给定的字符是否是控制字符。ispunct(int c)- 检查给定的字符是否是标点符号,即不是字母、数字、控制字符或空白字符的其他字符。isxdigit(int c)- 检查给定的字符是否是十六进制数字(0-9,A-F,a-f)。isgraph(int c)- 检查给定的字符是否是任何图形字符。isprint(int c)- 检查给定的字符是否是任何可打印字符,包括图形字符和空白字符。
12、字符转换函数
tolower(int c)- 如果给定的字符是大写字母,则将其转换为相应的小写字母;否则,原样返回该字符。toupper(int c)- 如果给定的字符是小写字母,则将其转换为相应的大写字母;否则,原样返回该字符。
13、memcpy
memcpy 函数是C语言中的一种标准库函数,定义在 <string.h> 头文件中。它的功能是从源内存地址的位置开始复制一定数量的字节到目标内存地址的位置。这个函数在处理非重叠内存块时是非常有效和常用的。
函数原型:
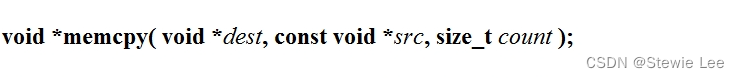
其中,dest 是指向目标内存地址的指针,src 是指向源内存地址的指针,count 是要复制的字节数。
memcpy 函数不会检查目标内存和源内存是否重叠,并且也不会检查count字节后的任何类型的终止字符。也就是说 memcpy 函数遇到 \0 不会停下,如果目标区域和源区域有重叠,请使用 memmove 函数,它在处理重叠区域时更为安全。
该函数返回一个指向 dest 的泛型指针。
实例:
#include <stdio.h>
#include <string.h>
int main()
{
int arr1[10] = { 0 };
int arr2[10] = { 1,2,3,4,5,6,7,8,9,10 };
memcpy(arr1, arr2, sizeof(arr2));
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr1[i]);
}
printf("\n");
return 0;
}运行结果:

模拟实现此函数:
#include <stdio.h>
#include <assert.h>
void* my_memcpy(void* dest, const void* src, size_t count)
{
assert(dest && src);
char* destination = (char*)dest;
char* source = (char*)src;
while (count)
{
*destination++ = *source++;
count--;
}
return dest;
}
int main()
{
int arr1[10] = { 0 };
int arr2[10] = { 1,2,3,4,5,6,7,8,9,10 };
my_memcpy(arr1, arr2, sizeof(arr2));
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr1[i]);
}
printf("\n");
return 0;
}运行结果:

memcpy函数的特点与限制:
memcpy用于将一块内存的内容复制到另一块内存中,它假设这两块内存不会重叠。- 如果源地址和目的地址的内存区域有重叠,
memcpy的行为是未定义的,可能会导致数据复制出错。 - 通常,
memcpy由于没有处理重叠的额外逻辑,可能在某些情况下比memmove更快。
所以最好将memcpy用于没有的重叠的内存拷贝中。
但是对于不同的编译器,具体实现可能不一样,有的编译器使用memcpy也可以实现重叠内存块的拷贝。
14、memmove
memmove函数是C语言标准库中提供的一个内存拷贝函数,其原型位于<string.h>头文件中。它的主要用途是从源内存区域复制n个字节到目标内存区域,即使这两个内存区域重叠,memmove也能保证拷贝的安全性,不会导致不期望的数据覆盖。这是memmove相对memcpy的一个重要特性,因为memcpy在处理重叠内存区域时的行为是未定义的。
函数原型:
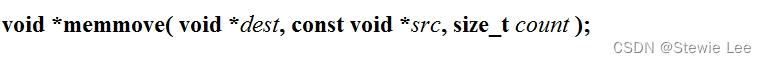
memmove函数的特点:
memmove也是用来复制内存内容,但它能够正确处理源地址和目的地址内存区域重叠的情况。- 因为
memmove需要处理潜在的重叠,其实现可能会稍微复杂一些,有时也可能会慢一些,尽管现代编译器和处理器的优化很可能缩小了这一差距。
参数:
dest:指向拷贝目标开始处的指针。src:指向要拷贝数据源开始处的指针。n:要从源内存地址拷贝到目标内存地址的字节数。
memmove函数返回一个指向目标内存区域开始处的指针,即dest参数的值。
#include <stdio.h>
#include <string.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
memmove(arr+2, arr, 20);
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}这里的memmove就是实现了重叠内存块的拷贝。
模拟实现此函数:
当src和dest指向的内存区域没有重叠时,memmove的行为与memcpy相似。然而,memmove的设计考虑了内存区域可能重叠的情况,因此,它首先判断源和目的地址的相对位置。如果目的地址在源地址之后,并且两个内存区域重叠,即目的地址与源地址之间的字节数小于 count 时,memmove会从后向前拷贝数据,以避免在拷贝过程中覆盖尚未复制的源数据。反之,如果目的地址在源地址之前,或者两个内存区域不重叠,memmove则从前向后拷贝数据。
#include <stdio.h>
#include <assert.h>
void* my_memmove(void* dest, const void* src, size_t count)
{
assert(dest && src);
char* destination = (char*)dest;
const char* source = (const char*)src;
if (source < destination && destination - source < count)
{
destination += count - 1;
source += count - 1;
while (count--)
{
*destination-- = *source--;
}
}
else
{
while (count--)
{
*destination++ = *source++;
}
}
return dest;
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
my_memmove(arr + 2, arr, 20);
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}运行结果:

这里有一个更好理解的方式:
主要是要保护 src 中的数据在复制之前不被覆盖,只要 src 的某一部分被覆盖了,就从这一部分开始复制。
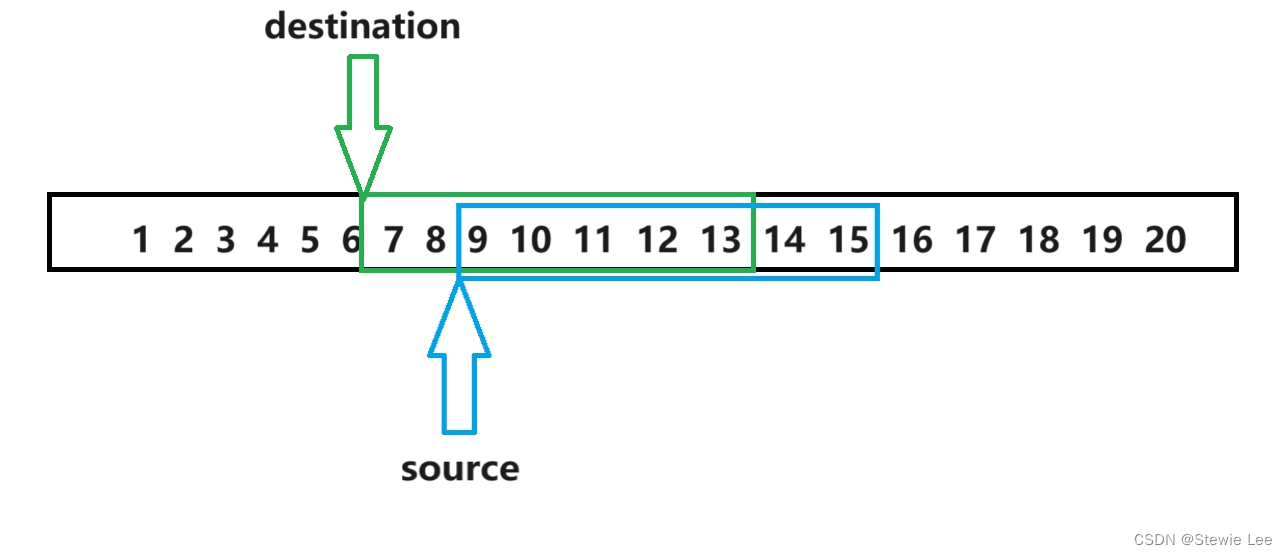
这里 src 的前面部分被覆盖,所以从前往后复制。
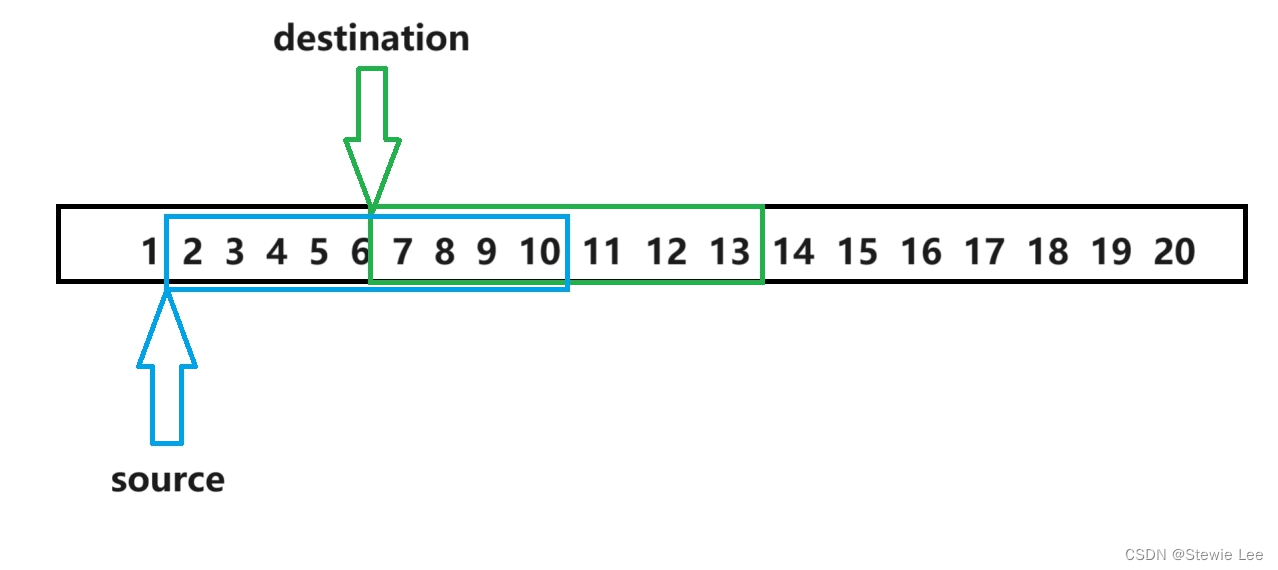
这里 src 的后面被覆盖了,所以从后往前复制。
15、memcmp
memcmp 函数是C语言标准库中用于比较内存区域的函数。它的原型也位于 <string.h> 头文件中。memcmp 函数用于比较两块内存区域的前 n 个字节,并根据比较结果返回一个整数。这个函数通常用于比较两个不同的内存块,例如字符串、结构体、数组或任何其他类型的数据块。
函数原型:
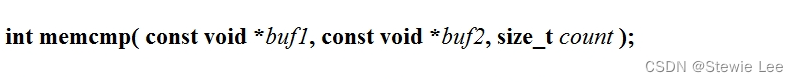
buf1:指向第一个内存块的指针。buf2:指向第二个内存块的指针。count:要比较的字节数。
返回值:

- 如果
buf1和buf2所指的内存内容在前count个字节内完全相同,则函数返回0。
- 如果两个内存块在前
n个字节内不相同,memcmp会返回两个内存块中第一个不同字节的差值(buf1 - buf2)。差值的正负取决于buf1和buf2的字节值的相对大小:- 如果
buf1处的不同字节大于buf2处相应的字节,则返回正值。 - 如果
buf1处的不同字节小于buf2处相应的字节,则返回负值。
- 如果
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
int arr1[] = { 1,2,3 };//01 00 00 00 02 00 00 00 03 00 00 00
int arr2[] = { 1,3,2 };//01 00 00 00 03 00 00 00 02 00 00 00
printf("%d\n", memcmp(arr1, arr2, 12));
return 0;
}运行结果:

注意事项:
memcmp函数使用的是无符号字节比较,这意味着比较是按照字节的数值来进行,不会将任何字节解释为负数。- 该函数不适用于比较字符串,因为它不会在遇到空字符(
'\0')时停止;它总是比较完指定的n个字节。 - 使用
memcmp需要保证比较的内存区块是有效的,并且至少有n个字节大小。
16、memset
memset 函数是标准C库函数,用于将内存中的每个字节都设置为特定的值。该函数通常用于初始化内存块,将其所有字节设置为相同的值。
函数原型:
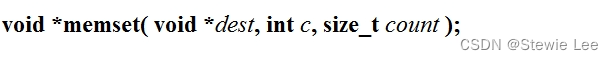
参数解释:
dest:指向要填充的内存块的指针。c:是一个int类型的值,但是memset会将其转换为一个无符号字符,并用这个字符的值来填充内存块。count:表示要设置的字节数。
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = "hello world";
memset(arr, 'x', 11);
printf("%s\n", arr);
return 0;
}运行结果:

注意事项:
memset对于初始化较大的内存块非常有效,但是它不了解数据类型,只是简单地将内存视为字节序列。memset传入的填充值c是int类型,但内部会将其转换为unsigned char,因此实际上只有c的低 8 位会被用来设置内存。- 尽管
memset在一般情况下非常有用,但是对于需要特定初始化模式的非字符数组,可能需要使用其他方法进行初始化。