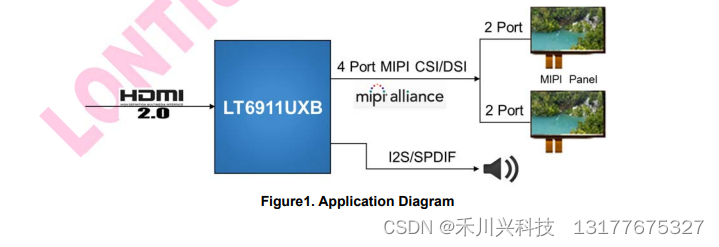
概述
基于计算机视觉的模型的核心挑战之一是生成高质量的分割掩模。大规模监督训练的最新进展已经实现了跨各种图像风格的零样本分割。此外,无监督训练简化了分割,无需大量注释。尽管取得了这些进展,构建一个能够在没有注释的零样本设置中分割任何东西的计算机视觉框架仍然是一项复杂的任务。语义分割是计算机视觉模型中的一个基本概念,涉及将图像划分为具有统一语义的较小区域。该技术为许多下游任务奠定了基础,例如医学成像、图像编辑、自动驾驶等。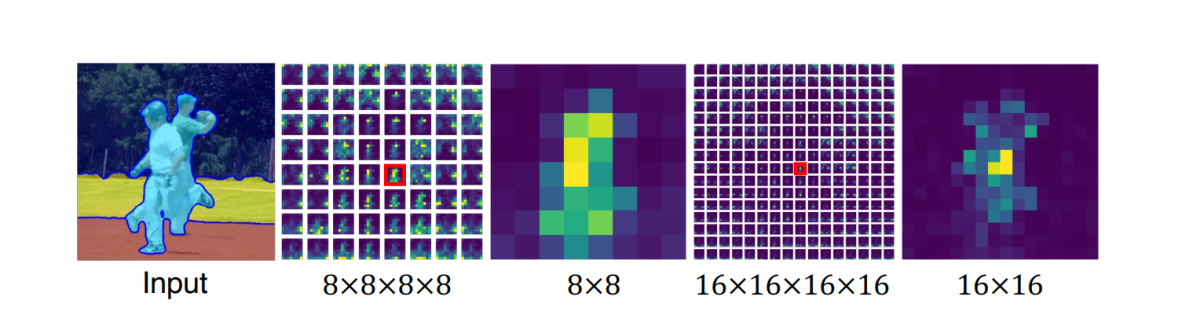
为了推进计算机视觉模型的发展,图像分割不局限于类别有限的固定数据集,这一点至关重要。相反,它应该充当各种其他应用程序的多功能基础任务。然而,在每个像素的基础上收集标签的高昂成本提出了重大挑战,限制了不需要注释且缺乏对目标的事先访问的零样本和监督分割方法的进展。本文将讨论自注意力层如何Stable Diffusion可以促进创建能够在零样本设置中分割任何输入的模型,即使没有适当的注释。这些自注意力层本质上理解通过预训练的稳定扩散模型学习的对象概念。
DiffSeg:增强的零样本分割算法
语义分割是将图像划分为不同部分的过程,每个部分共享相似的语义。该技术构成了众多下游任务的基础。传统上,零样本计算机视觉任务依赖于监督语义分割,利用带有注释和标记类别的大型数据集。然而,在零样本设置中实现无监督语义分割仍然是一个挑战。虽然传统的监督方法是有效的,但它们的每像素标记成本往往令人望而却步,这凸显了在限制较少的零样本设置中开发无监督分割方法的必要性,其中模型既不需要注释数据也不需要数据的先验知识。
为了解决这一限制,DiffSeg 引入了一种新颖的后处理策略,利用稳定扩散框架的功能来构建能够在任何图像上进行零镜头传输的通用分割模型。稳定扩散框架已证明其在根据提示条件生成高分辨率图像方面的功效。对于生成的图像,这些框架可以使用相应的文本提示生成分割掩模,通常仅包括主要的前景对象。
相比之下,DiffSeg 是一种创新的后处理方法,它通过利用扩散模型中自注意力层的注意力张量来创建分割掩模。 DiffSeg 算法由三个关键组件组成:迭代注意力合并、注意力聚合和非极大值抑制,如下图所示。
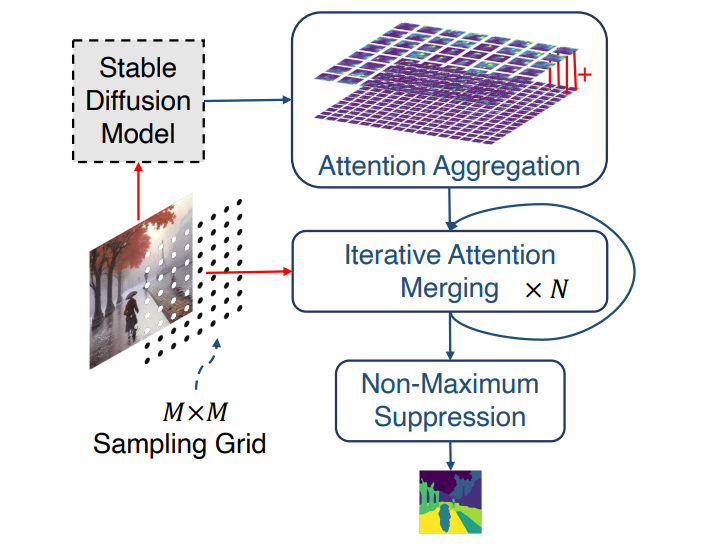
DiffSeg 算法通过聚合具有空间一致性的 4D 注意力张量,并通过采样锚点来利用迭代合并过程,从而保留多个分辨率下的视觉信息。这些锚点充当合并注意力蒙版的发射台,并最终吸收相同的对象锚点。 DiffSeg 框架通过以下方式控制合并过程: KL散度法衡量两个注意力图之间的相似度。
与基于聚类的无监督分割方法相比,开发人员不必在 DiffSeg 算法中事先指定聚类的数量,即使没有任何先验知识,DiffSeg 算法也可以在不利用额外资源的情况下产生分割。总的来说,DiffSeg 算法是“一种新颖的无监督零样本分割方法,利用预先训练的稳定扩散模型,无需任何额外资源或先验知识即可分割图像。=
DiffSeg:基本概念
DiffSeg 是一种新颖的算法,它建立在扩散模型、无监督分割和零样本分割的学习基础上。
扩散模型
DiffSeg 算法建立在预训练扩散模型的学习基础上。扩散模型是最流行的计算机视觉模型生成框架之一,它从采样的各向同性高斯噪声图像中学习前向和反向扩散过程以生成图像。稳定扩散是扩散模型最流行的变体,它用于执行各种任务,包括监督分割、零样本分类、语义对应匹配、标签高效分割和开放词汇分割。然而,扩散模型的唯一问题是它们依赖高维视觉特征来执行这些任务,并且它们通常需要额外的训练才能完全利用这些特征。
无监督分割
DiffSeg 算法与无监督分割密切相关,无监督分割是一种现代人工智能实践,旨在在不使用任何注释的情况下生成密集的分割掩模。然而,为了提供良好的性能,无监督分割模型确实需要对目标数据集进行一些事先的无监督训练。基于无监督分割的人工智能框架可以分为两类:使用预训练模型的聚类和基于不变性的聚类。在第一类中,框架利用预先训练的模型学习的判别特征来生成分割掩模,而属于第二类的框架使用通用聚类算法,该算法优化两个图像之间的相互信息,将图像分割成语义簇并避免退化分割。
零样本分割
DiffSeg 算法与零样本分割框架密切相关,零样本分割框架是一种无需任何事先训练或数据知识即可分割任何内容的方法。尽管零样本分割模型需要一些文本输入和提示,但它们近年来已经展示了出色的零样本传输能力。相比之下,DiffSeg 算法采用扩散模型来生成分割,无需查询和合成多个图像,也不知道对象的内容。
DffSeg:方法和架构
DiffSeg 算法利用预训练的稳定扩散模型中的自注意力层来生成高质量的分割任务。
稳定扩散模型
稳定扩散是 DiffSeg 框架中的基本概念之一。稳定扩散是一种生成式人工智能框架,也是最流行的扩散模型之一。扩散模型的主要特征之一是前向和反向传递。在前向传播中,在每个时间步迭代地将少量高斯噪声添加到图像中,直到图像变成各向同性高斯噪声图像。另一方面,在反向过程中,扩散模型迭代地去除各向同性高斯噪声图像中的噪声,以恢复没有任何高斯噪声的原始图像。
稳定扩散框架采用编码器-解码器和带有注意层的 U-Net 设计,其中使用编码器首先将图像压缩到具有较小空间维度的潜在空间,并利用解码器解压缩图像。 U-Net 架构由一堆模块化块组成,其中每个块由以下两个组件之一组成:Transformer 层和 ResNet 层。
组件和架构
扩散模型中的自注意力层以空间注意力图的形式对固有对象的信息进行分组,而 DiffSeg 是一种新颖的后处理方法,可将注意力张量合并到有效的分割掩模中,管道由三个主要组件组成:注意力聚合、非极大值抑制和迭代注意力。
注意力聚合
对于经过 U-Net 层和编码器的输入图像,稳定扩散模型总共生成 16 个注意力张量,每个维度有 5 个张量。生成 16 个张量的主要目标是将这些具有不同分辨率的注意力张量聚合成具有尽可能高的分辨率的张量。为了实现这一目标,DiffSeg 算法对 4 个维度进行不同的处理。
在四个维度中,注意力传感器中的最后 2 个维度具有不同的分辨率,但它们在空间上是一致的,因为 DiffSeg 框架的 2D 空间图对应于位置和空间位置之间的相关性。结果,DiffSeg 框架将所有注意力图的这两个维度采样为最高分辨率,64 x 64。另一方面,前 2 个维度表示注意力图的位置参考,如下图所示。

由于这些维度指的是注意力图的位置,因此需要相应地聚合注意力图。此外,为了确保聚合的注意力图具有有效的分布,框架在聚合后对分布进行归一化,并为每个注意力图分配与其分辨率成比例的权重。
迭代注意力合并
虽然注意力聚合的主要目标是计算注意力张量,但主要目标是将张量中的注意力图合并到一堆对象提案中,其中每个单独的提案包含内容类别或单个对象的激活。所提出的实现此目的的解决方案是通过在张量的有效分布上实施 K-Means 算法来查找对象的簇。然而,使用 K-Means 并不是最佳解决方案,因为 K-Means 聚类需要用户事先指定聚类的数量。此外,实施 K 均值算法可能会导致同一图像产生不同的结果,因为它随机地依赖于初始化。为了克服这个障碍,DiffSeg 框架建议生成一个采样网格,通过迭代合并注意力图来创建建议。
非极大值抑制
迭代注意力合并的上一步以概率注意力图的形式生成一个对象提案列表,其中每个对象提案都包含对象的激活。该框架利用非极大值抑制将对象建议列表转换为有效的分割掩模,并且该过程是一种有效的方法,因为列表中的每个元素已经是概率分布图。对于所有地图上的每个空间位置,该算法采用最大概率的索引,并根据相应地图的索引分配隶属度。
DiffSeg:实验和结果
用于无监督分割的框架使用两个分割基准,即 Cityscapes 和 COCO-stuff-27。 Cityscapes 基准是一个包含 27 个中级类别的自动驾驶数据集,而 COCO-stuff-27 基准是原始 COCO-stuff 数据集的精选版本,它将 80 个事物和 91 个类别合并为 27 个类别。此外,为了分析分割性能,DiffSeg 框架使用并集或 mIoU 和像素精度或 ACC 上的平均交集,并且由于 DiffSeg 算法无法提供语义标签,因此它使用匈牙利匹配算法来分配地面真值掩模每个预测的掩模。如果预测掩码的数量超过地面实况掩码的数量,框架会将不匹配的预测任务视为假阴性。
此外,DiffSeg框架还强调以下三个工作来运行干扰:语言依赖(LD)、无监督适应(UA)和辅助图像(AX)。语言依赖意味着该方法需要描述性文本输入以促进图像分割,无监督适应是指该方法需要在目标数据集上使用无监督训练,而辅助图像是指该方法需要额外的输入作为合成图像,或作为参考图像池。
成果
在 COCO 基准上,DiffSeg 框架包括两个 k-means 基线:K-Means-S 和 K-Means-C。 K-Means-C 基准包括 6 个聚类,通过对所评估的图像中的对象数量进行平均来计算,而 K-Means-S 基准则根据存在的对象数量为每个图像使用特定数量的聚类图像的真实情况,这两个基准的结果如下图所示。
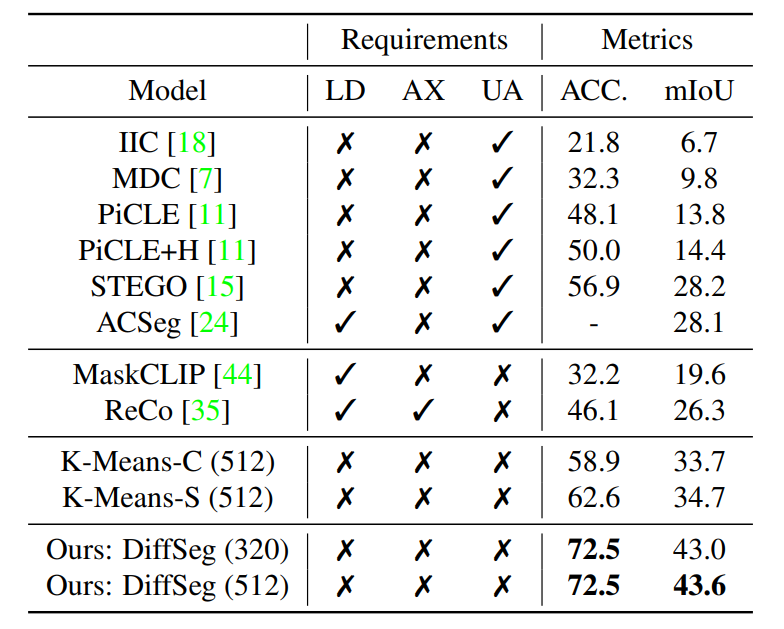
可以看出,K-Means 基线优于现有方法,从而证明了使用自注意力张量的好处。有趣的是,K-Means-S 基准测试优于 K-Means-C 基准测试,这表明聚类数量是一个基本的超参数,调整它对于每个图像都很重要。此外,即使依赖相同的注意力张量,DiffSeg 框架也优于 K-Means 基线,这证明了 DiffSeg 框架不仅能够提供更好的分割,而且还可以避免使用 K-Means 基线带来的缺点。
在 Cityscapes 数据集上,DiffSeg 框架提供的结果与使用较低 320 分辨率输入的框架类似,同时在准确度和 mIoU 方面优于采用较高 512 分辨率输入的框架。

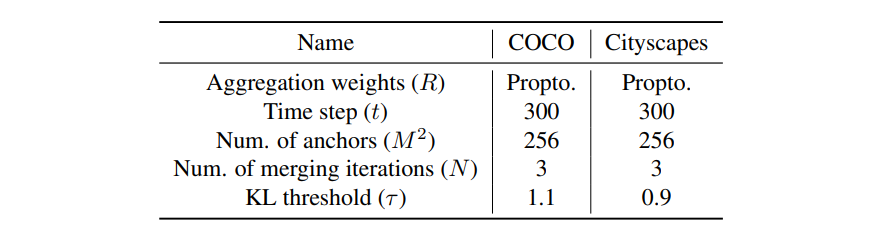
如前所述,DiffSeg 框架使用多个超参数,如下图所示。
注意力聚合是 DiffSeg 框架中采用的基本概念之一,在图像分辨率不变的情况下,使用不同聚合权重的效果如下图所示。
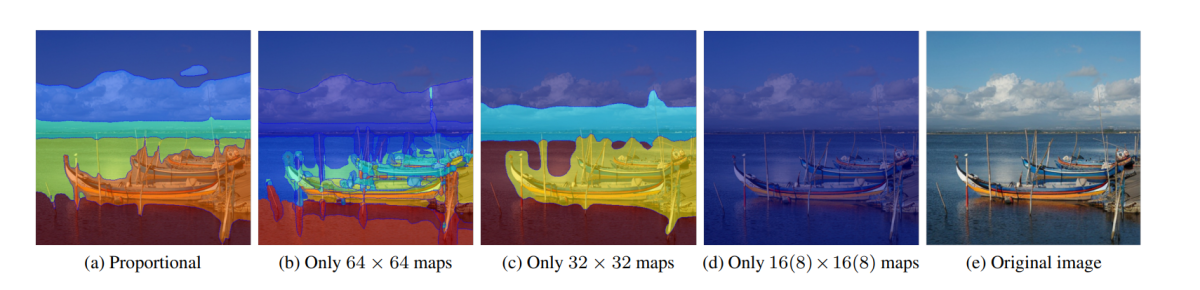
可以看出,图 (b) 中具有 64 x 64 地图的高分辨率地图产生了最详细的分割,尽管分割确实有一些可见的裂缝,而较低分辨率的 32 x 32 地图往往会过度分割细节,尽管它确实会导致增强的连贯分割。在图(d)中,低分辨率图无法生成任何分割,因为整个图像使用现有的超参数设置合并为单个对象。最后,图(a)利用比例聚合策略增强了细节并平衡了一致性。
总结
零样本无监督分割仍然是计算机视觉框架的最大障碍之一,现有模型要么依赖于非零样本无监督适应,要么依赖外部资源。为了克服这个障碍,我们讨论了稳定扩散模型中的自注意力层如何能够构建一个能够在零样本设置中分割任何输入而无需适当注释的模型,因为这些自注意力层持有以下固有概念预训练的稳定扩散模型学习的对象。我们还讨论了 DiffSeg,一种新颖的印后策略,旨在利用稳定扩散框架的潜力构建通用分割模型,可以在任何图像上实现零镜头传输。该算法依靠注意力间相似度和注意力内相似度将注意力图迭代地合并到有效的分割掩模中,以在流行的基准上实现最先进的性能。