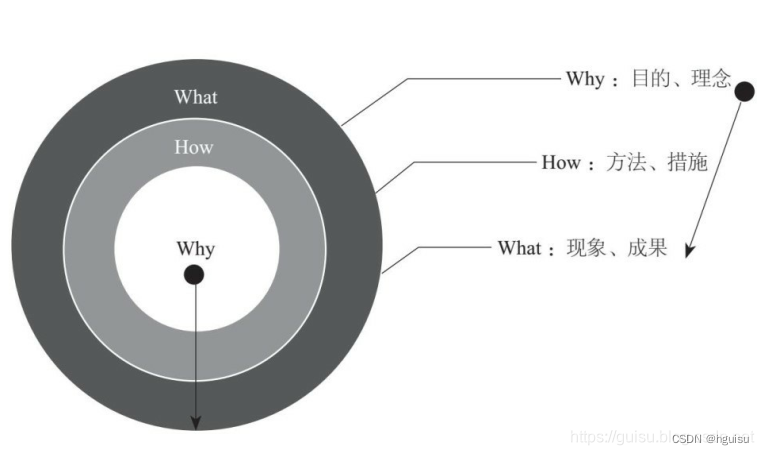
本学习笔记的组织结构是,先跟李沐老师学一下,再去kaggle上寻摸一下有没有类似的练习,浅做一下,作为一个了解。
———————————0428更新——————————————
课程和博客看到后面准备主要看两个:GCN和GAT,后续会把链接放在文章末尾
——————————————————————————————
阅读材料:A Gentle Introduction to Graph Neural Networks
课程链接:零基础多图详解图神经网络(GNN/GCN)【论文精读】_哔哩哔哩_bilibili
相对于之前接触的数据结构,文本(序列),图片(矩阵),图相对来说更加复杂。之前的图主要应用于社交网络中,但是因为图本身的复杂性,导致大家对图并没有更多的关注(不过现在已经很流行了)。
Neural networks have been adapted to leverage the structure and properties of graphs. We explore the components needed for building a graph neural network - and motivate the design choices behind them.
可以通过点击阅读材料中的点,来看这个点是怎么计算得来的,如下图所示:

可以看到只要图越深,那么在顶部的一个节点就可以处理比较大范围的图里面的节点信息(弹幕在刷感受野,俺也觉得很像)
实际的应用方向包括:antibacterial discovery,physics simulations, fake news detection, traffic prediction, recommendation systems。
解决几个问题:
1. 什么数据可以表示成图
2. 图和其他数据结构有什么不一样的地方,为什么要用图神经网络而不采用其他神经网络
3. 构建一个GNN,看一下各个模块长什么样子
4. 提供了一个GNN playground(可以去玩玩~)
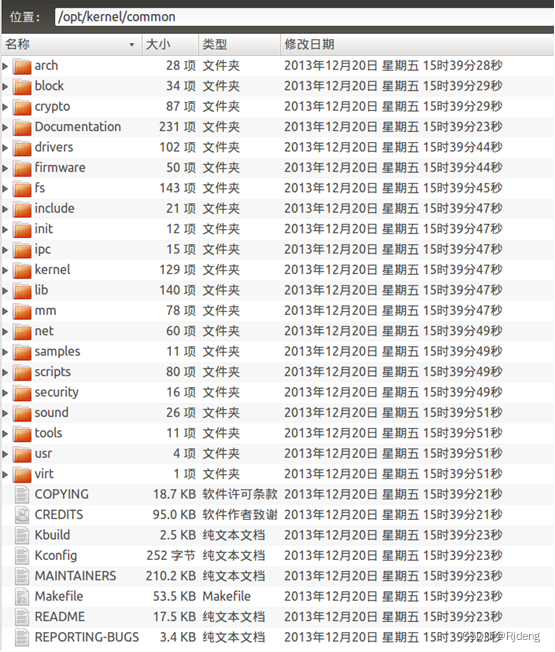
什么是图
A graph represents the relations (edges) between a collection of entities (nodes).
图是表现实体(顶点)之间的一些关系(边)
顶点可以用embedding(就是一条向量)来表示其中的一些属性
边也可以用embedding来表示,边的长度(指向量的长度)可以和顶点的长度不一样
全局的信息也可以用embedding来表示(长度也可以不一样)
核心->如何把我们想要的信息,表示成这些向量,以及这些向量是否能通过数据来学到

有向图&无向图
比如微信好友是没有方向的,A是B的好友的同时,B也是A的好友,但是在B站上,我们关注UP主A,UP主A没有关注我们(有方向了)
如何把图片表示成图(image->graph)
假设现在我们有一张图244x244x3(3个通道),一般来说,我们会把他表示成三个维度的一个tensor。但是从另外一个角度来看,可以看作是一个图,每一个像素就是一个点,如果像素之间是连接关系呢,就在点之间连一条边。

0-0表示,第0列,第0行,对应在图上也是左上角的0-0。类似的2-2表示,第2列,第2行,对应在图上也是中间的2-2
->这样,我们就可以把图片上的每一个像素映射成图上的一点。
接下来看边,比如现在点0-0点,可以看到,这里把与其相邻的像素认成自己的邻居,这里就连了3条边(有3个邻居)。类似的2-2点就连了8条边(有8个邻居)。
中间的图是邻接矩阵,矩阵的每一行都代表一个顶点,每一列也代表一个顶点,如果第i行 第j列是蓝色,就代表第i个节点和第j个节点之间是有边的,白色的部分表示是没有边的(注意到一个细节,对角线是白色的)
如何把文本表示成图(text->graph)
文本可以看作是一个序列。可以把每一个词表示成一个顶点,一个词和下一个词之间有一条有向边

这里行是当前词,列是下一个词
当然实际上这种编码图片和文字的方法并不是常用的方法。
其他数据
除了图片和文本之外,还有其他数据也可以表示成图
Molecules as graphs

分子图⬆️,一些原子通过一些作用力连接在一起
每一个原子可以表示成图里面的一个点,如果原子连在一起,就可以连一条边。
上图是一个香料分子的图

上图为咖啡因分子的图
Social networks as graphs
社交网络是研究人们、机构和组织的集体行为模式的工具。我们可以通过将个体建模为节点,将他们的关系建模为边来构建一个表示人群的图。

上图为戏剧奥赛罗中的人物关系图任何人物如果在一个场景中同时出现,就会在两个人(人是顶点)之间连一条边

上图为一个空手道俱乐部中的人比赛的记录。
Citation networks as graphs
如果文章A引用了文章B,就会在A B之间连一条边(这里是有向边,因为引用是有方向的,A引用B不代表B同时也会引用A。之前人之间的交互、分子之间的连接、像素之间的邻接都是相互的)
图的大小⬇️
graph数据可以解决什么问题?
大体上,图可以解决三类预测问题:图层面上,顶点层面上,边层面上(graph-level, node-level, and edge-level)
graph-level task
在图级任务中,我们的目标是预测整个图的属性。例如,对于用图形表示的分子,我们可能想要预测分子的气味,或者它是否会与与疾病有关的受体结合。

这里的例子是分类任务,看图中有没有两个环
Node-level task
这里举的例子就是之前的空手道俱乐部成员指甲的比赛情况。

随着故事的发展,Hi先生(教练)和John H(管理员)之间的不和导致了空手道俱乐部的分裂。节点表示单个空手道练习者,边缘表示空手道之外这些成员之间的交互。预测问题是,在争执之后,一个给定的成员是忠于Hi先生还是忠于John H(什么华山派故事)。
Edge-level task
除了识别图像中的对象之外,深度学习模型还可以用于预测它们之间的关系。我们可以将其描述为边缘级分类:给定代表图像中对象的节点,我们希望预测这些节点中的哪些节点共享一条边或该边的值是多少。如果我们希望发现实体之间的联系,我们可以认为图是完全连接的,并根据它们的预测值修剪边缘,得到一个稀疏图。


上图的例子,我们先通过语义分割把人物和背景都拿出来,然后判断人物之间是什么关系。在这个例子里,顶点(人物)已经有了,我们要判断的是边(人物之间的关系)->预测边的属性
在机器学习中使用图有什么挑战?
当我们把图用在神经网络中时,我们要解决的第一步是如何让图和神经网络兼容。图提供四种信息:顶点、边、全局上下文、连接性(每条边到底连的那两个顶点)(nodes, edges, global-context and connectivity)前面的三个都可以使用向量表示。那么怎么表示连接性呢?可以用之前提到的邻接矩阵来表示,如果我们有n个顶点,那么邻接矩阵就是一个nxn的矩阵,如果两个顶点之间有连接,那就是1,否则就是0。这个矩阵对于神经网络当然是OK的,但是也会带来一些问题,比如:这个矩阵可能会非常大,比如前面的表格里关于维基百科的图,12Mx12M正常存下来可能就不太可能了,但是由于我们知道里面的边没有那么稠密,是一个稀疏的矩阵->可以用稀疏矩阵的形式来存储。但是这带来另一个问题,想要高效计算稀疏矩阵是一件比较难的事情(待后期补充,为什么是比较难的事情),特别是将稀疏矩阵用在GPU上面(同样待后期补充,为什么)。p.s.文章里提到稀疏邻接矩阵是space-inefficient的,并没有提到计算的困难程度,应该是李沐老师补充的。
另一个问题是,有许多邻接矩阵可以编码相同的连通性,并且不能保证这些不同的矩阵会在深度神经网络中产生相同的结果(也就是说,它们不是排列不变的)。

简单来说就是改变行(列)的顺序并不会影响信息。虽然视觉上,上面的图看起来不一样,但是实际上表示的是相同的人物信息

类似的,上面的图表示了四个顶点,四条边,所有可能的邻接矩阵(但本质上都是同样的点,同样的连接方式,只是表示不同 )。

如果既希望存储高效,又想要排序不影响,可以采用⬆️存储方法。这里一共有8个顶点,7条边,每个点/边的属性用标量表示(当然也可以用向量表示),全局的信息也是用标量来表示(当然用向量也OK)。接下来维护一个称为临界列表的东西(adjacency list),其长度和边数是一样的,列表的第i项表示第i条边连接的是哪两条节点。我们可以把边、顶点的顺序打乱,只要相应的调整临界列表中的顺序、数字即可。
->存储高效&与顺序无关
图神经网络
A GNN is an optimizable transformation on all attributes of the graph (nodes, edges, global-context) that preserves graph symmetries (permutation invariances).
GNN是对图的所有属性(节点,边,全局上下文)的可优化变换,这个变换保持图的对称性(排列不变性)。
接下来会用使用message passing neural network框架构建GNN。GNN的输入是图,输出也是图。会对属性(顶点、边、全局的属性)进行变换(progressively transform these embeddings),但是不改变图的连接性(边时连接哪些顶点的信息,在进入GNN之后,是不会被改变的)
The simplest GNN
对于顶点、边、全局向量,分别构建一个MLP(多层感知机,multilayer perceptron)。这个MLP输入的大小和输出的大小是一样的。

三个MLP就组成了一个GNN的层。
最后我们得到的是属性被更新过,但是图的结构没有发生变化(相对于输入而言)的图。
(弹幕有人在问,为什么图的结构没有发生变化,弹幕有人回答如下:
因为node edge的结构没有变,只有attribute变了
结构没变:因为是一个个顶点的属性向量分别送进顶点MLP)
因为MLP是对每一个向量独自作用的,它不会考虑所有的连接信息,因此即使我们对整个顶点做排序,也不会改变结果。
(弹幕:个人观点:这里的三个f做了一些映射,使得新的Layer N+1的图能够更好地去完成指定任务。具体的参数学习应该还是要根据指定任务进行反向传播更新)
可以把这些层叠加在一起,构造出一个比较深一点的GNN。
Because a GNN does not update the connectivity of the input graph, we can describe the output graph of a GNN with the same adjacency list and the same number of feature vectors as the input graph. But, the output graph has updated embeddings, since the GNN has updated each of the node, edge and global-context representations.
GNN Predictions by Pooling Information
最后一层输出怎么得到我们要的预测值。

我们首先看一个最简单的情况:对每个顶点做预测。顶点的向量是已知的。
与一般的神经网络没有什么区别。因为我们的顶点已经有了一个向量表示,我们要对顶点做二分类预测(比如之前的空手道的图,预测学生到底跟A老师还是B老师)。每一个学生已经有了其对应的向量表示,那么我们就在后面加一个输出维度为2的全连接层,然后再加一个softmax就得到输出了。同理,如果是做n类的话,就做一个输出大小是n的全连接层,然后再加一个softmax即可。所有顶点都共享同一个全连接层。
->不管图有多大,一层里面就是3个MLP,所有的顶点共享同一个MLP,所有的边共享同一个MLP,全局当然就一个MLP(不用共享了)
(弹幕:每个顶点的属性向量,都送同一个MLP层)
接下来我们看一个稍微复杂的情况,我们还是想对顶点做预测,但是顶点并没有向量->pooling

假设我这个点是没有向量的,但是我还是想得到它的向量,来对它做预测。这时可以把与这些点连接的边的向量拿出来,把全局的向量也拿出来,这样我们就拿到了5个向量。把这5个向量全部加起来,就得到了代表这个顶点的向量(当然这里是假设我们所有的顶点、边、全局向量的维度是一样的,如果不一样,我们需要做一些投影)
(弹幕提到了一个问题,为什么顶点会没有自己的向量?俺也不知道,待后期补充)
如果换一个顶点⬇️,由于连接关系是不一样的,最后得到的向量也会是不一样的。


这样我们就可以继续添加全连接层,得到最后的输出了

同样的,假设我们只有顶点的向量,没有边的向量,但是我们想对每条边做预测的话->可以把顶点的向量pooling到边上

假设我们没有全局的向量,但是我们有顶点的向量,我们需要对整个图做预测(全局)。->可以把所有顶点向量加起来,得到一个全局的向量->进入全局的输出层->得到输出

这有点类似于CNN中的global average pooling layers
(待补充)
因此,无论缺少哪一个属性,都可以通过pooling得到这个属性的向量
总结一下,最简单的GNN长这样:

我们首先进入一系列GNN层,每一层里就是3个MLP,对应3种不同的属性。最后会得到一个保持了图结构的输出,但是里面的属性已经发生了变化。最后,根据我们要对哪一个属性做预测 ,添加一些合适的输出层,如果缺失信息,我们就添加合适的pooling layers。
(弹幕:缺少顶点信息,GNN block就没有顶点的MLP, 通过边和全局的MLP输出后做汇聚(属性向量相加)得到顶点向量)
但是这种结构也有其局限性,在开始的GNN层中,并没有用到连接性的信息,并没有看到边与哪些顶点相连,顶点与哪些边是相连的->并没有把整个图的信息更新到属性中->导致最后的结果并不能特别leverage图的信息
Passing messages between parts of the graph
如何将图的信息尽早放进去
信息传递(message passing)

假设我们要对这个顶点的向量进行更新,我们之前的做法是把他的向量直接拿过来,然后进入f(就是MLP),直接变换后得到更新的向量。但是在信息传递中,我们把这个顶点的向量和它的邻居的向量都加在一起得到一个汇聚的向量,把这个汇聚的向量放进MLP,得到这个点的向量的更新。同样的在更新其他顶点的时候也这么做。
这与conv有点像(但是权重没有了)
本质上,消息传递和卷积是聚合和处理元素邻居信息的操作,以便更新元素的值。在图形中,元素是一个节点,在图像中,元素是一个像素。然而,图中相邻节点的数量可以是可变的,不像在图像中,每个像素都有一定数量的相邻元素。

(弹幕:总结下:这里信息的汇聚是指把相邻节点的属性以相同权重的形式进行相加,使得该节点汇聚了其他节点的信息)
->完成了整个图的比较长距离的一个信息传递的过程
Learning edge representations
Our dataset does not always contain all types of information (node, edge, and global context). When we want to make a prediction on nodes, but our dataset only has edge information, we showed above how to use pooling to route information from edges to nodes, but only at the final prediction step of the model. We can share information between nodes and edges within the GNN layer using message passing.
我们不需要在最后做pooling,可以在前面就进行。
这里举的例子是怎么把顶点的信息传递给边然后再把边的信息传递给顶点。

首先把顶点传递给边(把每条边连接的两个顶点的信息,加到边自己的向量中,如果维度不一样->做投影,然后加进去)。这样边就拿到了顶点的信息。
同样的,每个顶点可以加上它连的边的信息
(如果维度不一样需要做两次投影,如果维度一样直接加就好了)
另一种思路是concat在一起。
(弹幕:一个简单的 投影的实现是 乘以一个 m*n的W就可以了。mn是输入输出的维度)

这样顶点和边就可以同时做了。
Adding global representations
为什么需要全局信息?
There is one flaw with the networks we have described so far: nodes that are far away from each other in the graph may never be able to efficiently transfer information to one another, even if we apply message passing several times. For one node, If we have k-layers, information will propagate at most k-steps away. This can be a problem for situations where the prediction task depends on nodes, or groups of nodes, that are far apart. One solution would be to have all nodes be able to pass information to each other. Unfortunately for large graphs, this quickly becomes computationally expensive (although this approach, called ‘virtual edges’, has been used for small graphs such as molecules)
假设我们的图很大,且连接没有那么紧密的时候,会导致一个消息从一个点传递到一个很远的点需要走很远。
->解决方案:加入一个master node(或context vector)
这个点是一个虚拟的点,可以和所有顶点&边相连

即:U和V&E中所有的东西都相连(有点抽象)
因此,如果想要将顶点的信息汇聚给边的时候,也会把U也汇聚过来。同理,汇聚边的信息给顶点的时候也会把U汇聚过来。最后我们在更新U的时候,也会把所有顶点和边的信息都拿过来,完成汇聚后再做更新。

现在,我们对这三类属性都学到了对应的向量,并且在早期就进行了消息传递,因此在做预测的时候,可以只用本身的向量,也可以把相邻的边的向量、相邻的顶点的向量、全局向量也拿过来->不仅用本身的向量,可以把别的和我相关的东西都拿过来,一起做预测。
->有点像attention mechanism
GNN playground
调节GNN中不同的超参数来看实际训练的效果
Our playground shows a graph-level prediction task with small molecular graphs. We use the the Leffingwell Odor Dataset, which is composed of molecules with associated odor percepts (labels). Predicting the relation of a molecular structure (graph) to its smell is a 100 year-old problem straddling chemistry, physics, neuroscience, and machine learning.
To simplify the problem, we consider only a single binary label per molecule, classifying if a molecular graph smells “pungent” or not, as labeled by a professional perfumer. We say a molecule has a “pungent” scent if it has a strong, striking smell. For example, garlic and mustard, which might contain the molecule allyl alcohol have this quality. The molecule piperitone, often used for peppermint-flavored candy, is also described as having a pungent smell.
We represent each molecule as a graph, where atoms are nodes containing a one-hot encoding for its atomic identity (Carbon, Nitrogen, Oxygen, Fluorine) and bonds are edges containing a one-hot encoding its bond type (single, double, triple or aromatic).
分类,气味分子,是否刺鼻
可以选GNN层数,汇聚操作的方法(其中mean、max对应CNN中的average pooling和max pooling,sum在CNN中用的不多)顶点、边、全局的embedding size,是否对边、顶点、全局学习。
采用50个epoch,会给出一个AUC(越大越好)
真实值是边框的颜色,预测值是内部的颜色(右侧)

左边可以对给定的一个图做预测
Some empirical GNN design lessons
超参数对预测结果的影响
A Gentle Introduction to Graph Neural Networks
具体图片参考网站(图片是交互式的)
当模型参数增加的时候,可以看到AUC的上限是在增加的(但是参数没调好最后的AUC和少参数没有什么区别)
看embedding dimension的box plot,我们希望medium越大越好,同时我们也希望20%-75%的bar不要太长,太长意味着更敏感

看起来都不是特别明显
不同层数的影响,也参考网站。
当增加层数的时候,AUC medium在增加,但是bar的长度还是蛮长的->还是要好好调参才行
下一个是不同的聚合方式max mean sum(没啥影响)
下一个是信息传递。不传递信息的AUC是最差的,通过不断增加新的东西,可以看到是在上升的。可以看到顶点、边、全局都传递信息的效果最好(当然也需要好好调参)
One of the frontiers of GNN research is not making new models and architectures, but “how to construct graphs”, to be more precise, imbuing graphs with additional structure or relations that can be leveraged. As we loosely saw, the more graph attributes are communicating the more we tend to have better models. In this particular case, we could consider making molecular graphs more feature rich, by adding additional spatial relationships between nodes, adding edges that are not bonds, or explicit learnable relationships between subgraphs.
图属性的交流越多,我们就越倾向于拥有更好的模型。在这种特殊情况下,我们可以考虑通过在节点之间添加额外的空间关系,添加非键边或子图之间明确的可学习关系来使分子图具有更丰富的特征。
相关技术
Other types of graphs (multigraphs, hypergraphs, hypernodes, hierarchical graphs)
multigraphs
a pair of nodes can share multiple types of edges, this happens when we want to model the interactions between nodes differently based on their type. For example with a social network, we can specify edge types based on the type of relationships (acquaintance, friend, family).
顶点之间可以有多种边
hypernode graph
We can also consider nested graphs, where for example a node represents a graph, also called a hypernode graph.Nested graphs are useful for representing hierarchical information. For example, we can consider a network of molecules, where a node represents a molecule and an edge is shared between two molecules if we have a way (reaction) of transforming one to the other . In this case, we can learn on a nested graph by having a GNN that learns representations at the molecule level and another at the reaction network level, and alternate between them during training.
图可能是分层的,有些顶点是子图。

Sampling Graphs and Batching in GNNs
怎么对图进行采样和batching。
为什么要对图进行采样?
假设我们有很多层,最后一层的一个顶点,即使每一层只看其一近邻,最后这个顶点因为有很多层的信息传递,最后一层其实能看到的是一个很大的图。假设这个图的连通性够的话,最后这个顶点可能看到的是整个图的信息。
在计算梯度的时候,我们需要把整个forward里面的所有的中间变量存下来。如果最后一个顶点要看整个图,就意味着我们对这个顶点计算梯度的时候,要把整个图的中间结果都存下来->导致计算可能是无法承受的。
->对图进行采样
每次采样一个小图出来,在这个小图上做信息汇聚,这样算梯度的时候,只要把小图上的中间结果记录下来就可以了。

1. (左上)随机采样一些点,然后吧这些点最近的邻居找出来
2. (右上)随机游走,从某个顶点开始,随机选一条边向下走,规定最多走多少步
3. (左下)结合1 2,先随机走三步,把这三个点的邻居找出来
4. (右下)随机取一个点,然后把这个点的1, 2, 3, ……, k近邻找出来(走k步)
具体哪一种采样方法比较好,取决于图长什么样子
batching
从性能上考虑,我们不想对每个顶点逐步更新,因为这样计算量太小,不利于并行计算->把小样本做成小批量->对一个大的矩阵or tensor做运算
但是这里,每个顶点的邻居的个数是不一样的->怎么把这些顶点和顶点的邻居合并成一个规则的tensor?
Inductive biases
任何机器学习都包含假设,比如卷积神经网络,假设的是空间变换的不变性(translation invariant,一只狗无论出现在图片的哪里都是狗);循环伸进网络假设的是时序的延续性(一些词,比如not的位置会影响剩下句子部分的含义。
In the case of graphs, we care about how each graph component (edge, node, global) is related to each other so we seek models that have a relational inductive bias. A model should preserve explicit relationships between entities (adjacency matrix) and preserve graph symmetries (permutation invariance). We expect problems where the interaction between entities is important will benefit from a graph structure. Concretely, this means designing transformation on sets: the order of operation on nodes or edges should not matter and the operation should work on a variable number of inputs.
对于GNN,假设:
1. 保持图的对称性(permutation invariance),无论怎样交换顶点的顺序,GNN的作用都是保持不变的。
2. 保持连接性
Comparing aggregation operations
之前在playground部分提到了可以mean、sum、max,但是没有一种是特别理想的。

如左图,可能没办法区分两个网络,左图的max就没法区分两个网络,而右图仅有sum可以区分两个网络。当然,如果各个节点加起来是一样的,那么sum也没办法区分两个网络了。
GCN as subgraph function approximators
When focusing on one node, after k-layers, the updated node representation has a limited viewpoint of all neighbors up to k-distance, essentially a subgraph representation. Same is true for edge representations.
GCN(graph convolutional network,图卷机神经网络)以及MPNN(message passing neural network)如果有k层,每一层都是看一个邻居,类似卷积神经网络中有k层3*3的卷积,这样,每一个最后的顶点看到的是一个子图(大小是k->到最远的顶点的距离是k,也就是说每一个顶点看到的是往前走k步的子图的信息的汇聚)
所以GCN就可以看作是有n个这样的子图,在所有的子图上求一个embedding出来
GCN可参考另一篇博客Understanding Convolutions on Graphs

Edges and the Graph Dual
可以把点和边做对偶(图论中把点变成边,把边变成点,邻接关系不变),在GNN上也可以这么做。
A graph and its dual contain the same information, just expressed in a different way. Sometimes this property makes solving problems easier in one representation than another, like frequencies in Fourier space. In short, to solve an edge classification problem on 𝐺, we can think about doing graph convolutions on 𝐺’s dual (which is the same as learning edge representations on 𝐺), this idea was developed with Dual-Primal Graph Convolutional Networks.
Graph convolutions as matrix multiplications, and matrix multiplications as walks on a graph
在图上做卷积、在图上做random walk,等价于把邻接矩阵拿出来,做一个矩阵的乘法。
(page rank)
Graph Attention Networks
在图上做汇聚的时候,是每个顶点和它的邻接的顶点的权重加起来,但是如果是卷积的话,是做一个加权和。同理,在图上也可以做加权和。但是需要注意的是,卷积的权重是和位置相关的(每个窗口,e.g. 3x3的窗口,在每个固定的点上有固定的权重),但是对图来说,不需要这个位置信息。因为每个顶点的邻居的个数不变,并且邻居是可以随意打乱顺序的->所以需要权重对位置不敏感->idea1:可以采用注意力机制的方法,权重取决于两个顶点向量之间的关系(不是顶点的位置)。给每个顶点权重之后。再按这个权重加起来,得到GAN
(弹幕:点乘相似度高的在pooling时给予更高的权重)

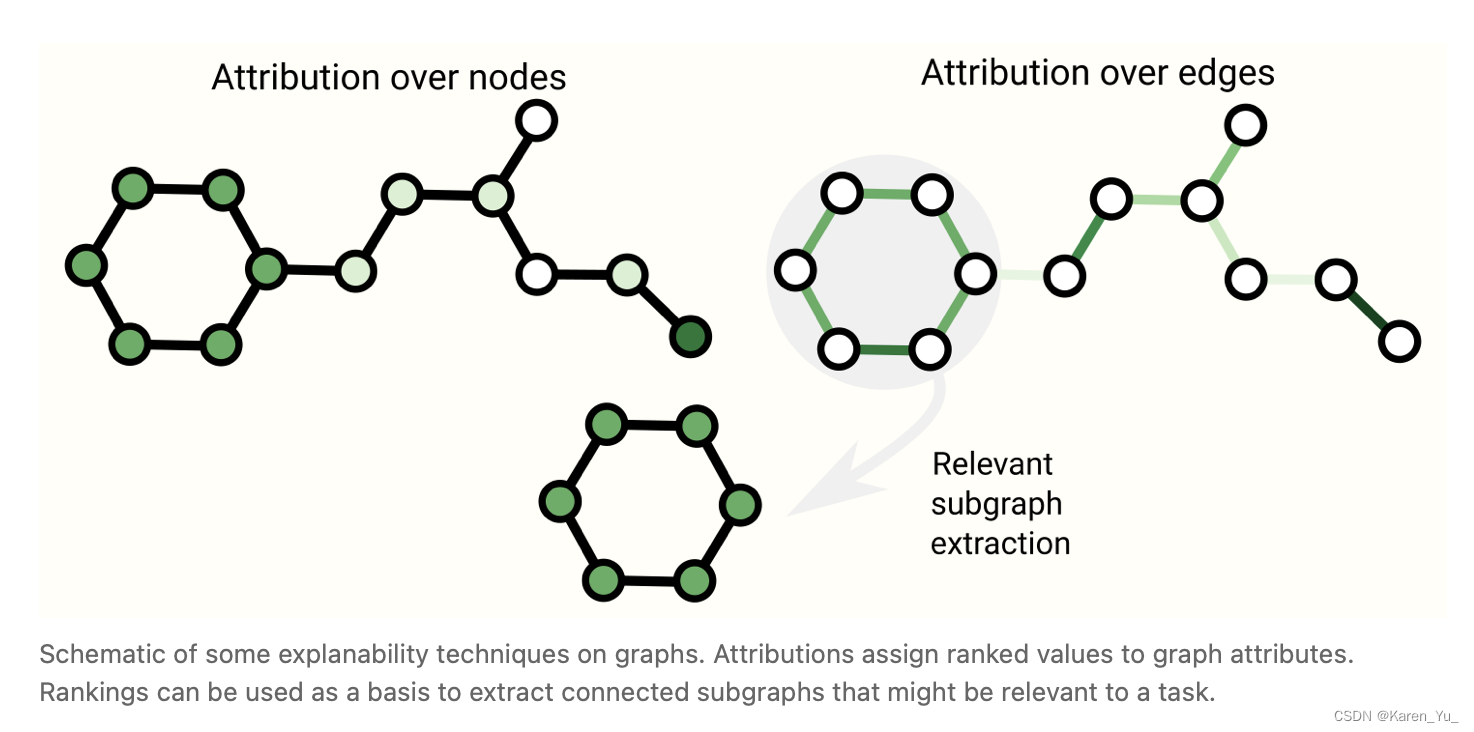
Graph explanations and attributions
图的可解释性