目录
1. 简介
2. 认识MAXI
3. MAXI突发操作
3.1 全局/本地存储器
3.2 MAXI优势与特点
3.3 查看MAXI报告
3.3.1 HW Interfaces
3.3.2 M_AXI Burst Information
3.4 MAXI 资源消耗
4. 理解 Volatile
4.1 标准C/C++中的 volatile
4.2 HLS 中的 volatile
5. 总结
1. 简介
Vitis HLS 支持的 AXI4 接口包括 AXI4-Stream 接口 (axis)、AXI4-Lite (s_axilite) 和 AXI4 主接口 (m_axi)。
m_axi:适用于阵列和指针(以及 C++ 中的引用)。
s_axilite:适用于在除串流外的任意类型的实参上指定此协议。
axis:适用于输入实参或输出实参上指定此协议,而不得在输入/输出实参上指定。
AXI4 存储器映射 (m_axi) 接口允许内核在全局存储器(DDR、HBM 和 PLRAM)内读写数据。存储器映射接口便于跨加速应用的不同元素共享数据。
本文分享使用 AXI4 存储器映射 (m_axi) 接口的经验总结。
2. 认识MAXI
AXI4 存储器映射接口、AXI4 主接口、maxi、axi4-master指的是同一个事,因为会从处理器中接管AXI总线,从而操作全局存储器,体现出一个“主动的”、“全局的”、“存储器的”含义。
MAXI 可在阵列或指针/参考实参上使用,通过以下任一模式来实现该接口:
- 单独数据传输
- 突发模式数据传输
很少会用到单独数据传输,我们先通过这个突发模式数据传输了解MAXI:
#include <stdio.h>
#include <string.h>
void func(volatile int *a, volatile int *b){
#pragma HLS INTERFACE mode=s_axilite port=return
#pragma HLS INTERFACE mode=m_axi port=a depth=50
#pragma HLS INTERFACE mode=m_axi port=b depth=50
int i;
int buff[50];
memcpy(buff, (const int*)a, 50*sizeof(int));
for(i=0; i < 50; i++){
buff[i] = buff[i] + 100;
}
memcpy((int *)b, buff, 50*sizeof(int));
}
在这个例子中,函数func接收两个指向整数的volatile指针a和b,然后将a指向的数据拷贝到一个本地缓冲区buff,对每个元素增加100,最后将结果拷贝回b指向的内存位置。
这段代码经过综合后将在FPGA硬件上执行,此时指针a和b分别指向全局内存中的地址。因此,可以看出,M_AXI接口在此扮演了DMA(直接内存访问)的角色,实现了高效的内存数据传输。
3. MAXI突发操作
3.1 全局/本地存储器
- 全局存储器
通常是片外存储器,包括DDR、HBM 和 PLRAM等,这些存储器通过FPGA的外部接口与之连接。片外存储器通常用于存储大量数据,片外存储器的访问速度通常比本地存储器慢,受限于接口速度和通信协议。
- 本地存储器
本地存储器位于FPGA芯片内部的存储资源。这些存储资源通常访问速度快,延迟低,因为它们直接嵌入在FPGA逻辑中,无需经过外部接口。本地存储器通常用于存储小量数据,如配置参数、中间计算结果或小数组。
本地存储器包括:
Block RAM(BRAM):一种较大的、可配置的内部存储块,适用于实现FIFO、缓冲区、查找表等。
Distributed RAM:利用FPGA内部逻辑单元(如LUTs)的存储能力,适合于小规模存储需求。
寄存器:非常小的存储单元,用于存储极少量的数据,如状态机的状态、计数器的当前值等。
访问这些存储器可能需耗费大量周期:
3.2 MAXI优势与特点
以下列出了 m_axi 接口的主要优势:
- 此接口有独立的读取通道和写入通道
- 支持基于突发的访问,潜在性能可达 ~17 GB/s
- 它可为未完成传输事务提供支持
突发
突发是一种对内核执行的最优化,它会尝试以智能方式聚集对 DDR 的存储器访问操作,以便尽可能提升吞吐量带宽和/或减小时延。通常可以实现 4 到 5 倍的提升,结合其它最优化(例如,访问拓宽或者确保不存在通过 DDR 的依赖关系)甚至可提供更大的性能提升。通常 DDR 端口上存在争用(源于多个相互竞争的内核)时,适合使用突发。
传输速度
计算方式如下:
((传输的字节数) * (内核频率)/(时间))
最大内核接口位宽为 512位,如果内核编译为按 300 MHz 频率运行,那么理论上每个 DDR 可达成 (512* 300 MHz)/1 秒 = ~17 GB/s。
未完成传输事务
允许HLS内核以流水线方式管理存储器请求的数量,这意味着它可以连续发送请求到全局存储器,而不需要等待前一个请求完成。通过提高流水线请求的数量,可以增加读/写操作的流水线深度,这样做虽然可以提升性能,但同时也会增加对BRAM/URAM资源的消耗。

大部分情况下,当突发长度 >=16 时,未完成的读/写操作数应足矣。
3.3 查看MAXI报告
在Vitis HLS中综合示例代码后,可以查看综合报告,这里分析其中关于MAXI的部分。
3.3.1 HW Interfaces
================================================================
== HW Interfaces
================================================================
* M_AXI
+------------+------------+---------------+---------+--------+----------+-----------+--------------+--------------+-------------+-------------+
| Interface | Data Width | Address Width | Latency | Offset | Register | Max Widen | Max Read | Max Write | Num Read | Num Write |
| | (SW->HW) | | | | | Bitwidth | Burst Length | Burst Length | Outstanding | Outstanding |
+------------+------------+---------------+---------+--------+----------+-----------+--------------+--------------+-------------+-------------+
| m_axi_gmem | 32 -> 32 | 64 | 0 | slave | 0 | 0 | 16 | 16 | 16 | 16 |
+------------+------------+---------------+---------+--------+----------+-----------+--------------+--------------+-------------+-------------+
* S_AXILITE Interfaces
+---------------+------------+---------------+--------+----------+
| Interface | Data Width | Address Width | Offset | Register |
+---------------+------------+---------------+--------+----------+
| s_axi_control | 32 | 6 | 16 | 0 |
+---------------+------------+---------------+--------+----------+
* S_AXILITE Registers
+---------------+----------+--------+-------+--------+----------------------------------+----------------------------------------------------------------------+
| Interface | Register | Offset | Width | Access | Description | Bit Fields |
+---------------+----------+--------+-------+--------+----------------------------------+----------------------------------------------------------------------+
| s_axi_control | CTRL | 0x00 | 32 | RW | Control signals | 0=AP_START 1=AP_DONE 2=AP_IDLE 3=AP_READY 7=AUTO_RESTART 9=INTERRUPT |
| s_axi_control | GIER | 0x04 | 32 | RW | Global Interrupt Enable Register | 0=Enable |
| s_axi_control | IP_IER | 0x08 | 32 | RW | IP Interrupt Enable Register | 0=CHAN0_INT_EN 1=CHAN1_INT_EN |
| s_axi_control | IP_ISR | 0x0c | 32 | RW | IP Interrupt Status Register | 0=CHAN0_INT_ST 1=CHAN1_INT_ST |
| s_axi_control | a_1 | 0x10 | 32 | W | Data signal of a | |
| s_axi_control | a_2 | 0x14 | 32 | W | Data signal of a | |
| s_axi_control | b_1 | 0x1c | 32 | W | Data signal of b | |
| s_axi_control | b_2 | 0x20 | 32 | W | Data signal of b | |
+---------------+----------+--------+-------+--------+----------------------------------+----------------------------------------------------------------------+
* TOP LEVEL CONTROL
+-----------+------------+-----------+
| Interface | Type | Ports |
+-----------+------------+-----------+
| ap_clk | clock | ap_clk |
| ap_rst_n | reset | ap_rst_n |
| interrupt | interrupt | interrupt |
| ap_ctrl | ap_ctrl_hs | |
+-----------+------------+-----------+M_AXI 接口的性能和行为特征:
- Interface: 接口的名称是m_axi_gmem。
- Data Width (SW->HW): 表示软件到硬件方向上数据传输的位宽。
- Address Width: 地址宽度是64位数。
- Latency: 延迟,表示从发出请求到开始接收数据之间的时间延迟。0表示由系统决定。
- Offset: 表示地址偏移的配置,这里是slave,将由软件通过 s_axilite 接口来指定地址。
- Max Widen Bitwidth: 最大位宽拓宽,这里是0,未使用自动增加数据位宽的功能。
- Max Read Burst Length: 最大读突发长度,这里是16,表示一次读操作可以连续读取的最大数据块数目为16个数据宽度的单位。
- Max Write Burst Length: 最大写突发长度,也是16,表示一次写操作可以连续写入的最大数据块数目为16个数据宽度的单位。
- Num Read Outstanding: 读操作的未完成请求数量,这里是16,表示可以有最多16个读请求在没有完成的情况下同时存在。
- Num Write Outstanding: 写操作的未完成请求数量,同样是16,表示可以有最多16个写请求在没有完成的情况下同时存在。
S_AXILITE Registers 中a和b参数解释:
* S_AXILITE Registers
+---------------+----------+--------+-------+--------+----------------------------------+
| Interface | Register | Offset | Width | Access | Description |
+---------------+----------+--------+-------+--------+----------------------------------+
| s_axi_control | a_1 | 0x10 | 32 | W | Data signal of a |
| s_axi_control | a_2 | 0x14 | 32 | W | Data signal of a |
| s_axi_control | b_1 | 0x1c | 32 | W | Data signal of b |
| s_axi_control | b_2 | 0x20 | 32 | W | Data signal of b |
+---------------+----------+--------+-------+--------+----------------------------------+- s_axi_control 总线数据宽度为32位,如下:
* S_AXILITE Interfaces
+---------------+------------+---------------+--------+----------+
| Interface | Data Width | Address Width | Offset | Register |
+---------------+------------+---------------+--------+----------+
| s_axi_control | 32 | 6 | 16 | 0 |
+---------------+------------+---------------+--------+----------+- 参数a和b为指针,数据位宽为64位
- 所以 s_axi_control 需要通过两个寄存器进行配置
3.3.2 M_AXI Burst Information
================================================================
== M_AXI Burst Information
================================================================
Note: All burst requests might be further partitioned into multiple requests during RTL generation based on max_read_burst_length or max_write_burst_length settings.
* Inferred Burst Summary
+--------------+-----------+-----------+--------+-------+------------------------+
| HW Interface | Loop | Direction | Length | Width | Location |
+--------------+-----------+-----------+--------+-------+------------------------+
| m_axi_gmem | anonymous | read | 50 | 32 | mult/src/func.cpp:13:5 |
| m_axi_gmem | anonymous | write | 50 | 32 | mult/src/func.cpp:17:5 |
+--------------+-----------+-----------+--------+-------+------------------------+
* Inferred Bursts and Widening Missed
+--------------+----------+-----------+-------------------------------------------------------------------------------------------------------+------------+------------------------+
| HW Interface | Variable | Loop | Problem | Resolution | Location |
+--------------+----------+-----------+-------------------------------------------------------------------------------------------------------+------------+------------------------+
| m_axi_gmem | b | anonymous | Could not widen since type i32 size is greater than or equal to the max_widen_bitwidth threshold of 0 | 214-353 | mult/src/func.cpp:17:5 |
| m_axi_gmem | a | anonymous | Could not widen since type i32 size is greater than or equal to the max_widen_bitwidth threshold of 0 | 214-353 | mult/src/func.cpp:13:5 |
+--------------+----------+-----------+-------------------------------------------------------------------------------------------------------+------------+------------------------+推断的突发总结,这部分列出了识别出的突发传输请求的摘要信息:
- HW Interface:硬件接口名称是m_axi_gmem。
- Loop:循环名称,这里标记为anonymous,我们没有对循环命名。
- Direction:数据传输的方向,分别有read(读取)和write(写入)。
- Length:FIFO buffer 长度为50。
- Width:数据宽度是32位。
- Location:提供了代码中突发发生位置的具体信息。
未命中的推断的突发或者扩宽的情况:
Could not widen since type i32 size is greater than or equal to the max_widen_bitwidth threshold of 0
![]()
当 HLS 工具可看到突发访问时,会尝试自动调整端口宽度大小,以改善突发访问能力。m_axi 接口端口最大值的可调值为 512 位。由于IDE工具默认值设为零,此处并未优化。
3.4 MAXI 资源消耗
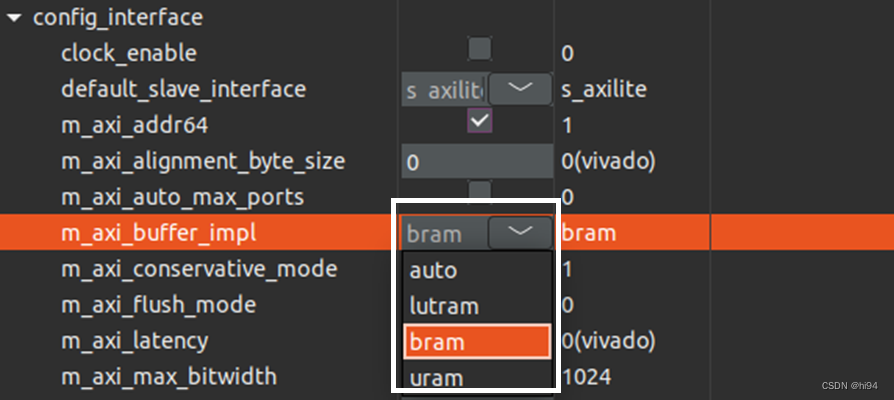
M_AXI 适配器的器件资源耗用量是所有写入模块(FIFO_wreq module 模块、buff_wdata、和 FIFO_ resp 的大小)总和与所有读取模块总和相加所得。FIFO 大小的计算方式为“位宽 × 深度”。
默认情况下,此 FIFO 将作为 BRAM 来实现,但可在 LUTRAM 或 URAM(由 config_interface
-maxi_buffer_impl 指定)中实现。
4. 理解 Volatile
4.1 标准C/C++中的 volatile
volatile 用于告知编译器某个变量可能会在程序的正常执行流之外被修改,确保编译器不会对访问该变量的代码进行过度优化,从而避免潜在的数据不一致问题。
编译器对代码进行优化的方式有很多,例如:
指令重排:编译器可能会对指令进行重新排序,以提高代码执行效率。但是,在涉及 volatile 变量的情况下,编译器会保持对这些变量的操作顺序,确保正确的执行顺序。
读写优化:当编译器遇到非 volatile 变量时,可能会通过寄存器缓存变量值或者将多次读写操作合并为一次操作来提高性能。但是,当变量被声明为 volatile 时,编译器会确保每次读写操作都会直接访问内存,而不会进行这些优化。
int x = 0;
void foo() {
x = 5;
int y = x;
}
在这个例子中,编译器可能会认为在赋值 x = 5; 之后,x 的值一定是 5。
所以它可能会直接优化 int y = x; 为 int y = 5;
然而,如果 x 被声明为 volatile,编译器就不会进行这种优化,因为它会认为 x 在两次访问之间可能已经被修改。这种情况在多线程编程或者嵌入式系统中尤为重要。
4.2 HLS 中的 volatile
在函数接口上多次访问指针时,volatile 限定符会影响 RTL 中执行的读取或写入操作次数。虽然 volatile 限定符会影响层级内所有函数中的此行为,但 volatile 限定符的影响主要常见于顶层接口中。
对往来 volatile 变量的访问权限均为保留权限。这意味着:
- 无突发访问
- 无端口拓宽
- 无死码消除
任意精度类型不支持使用易变 (volatile) 限定符执行算术运算。对于使用 volatile 限定符的所有任意精度数据类型,必须将其指定为非易变数据类型,才可在算术表达式中使用。
5. 总结
本文介绍了在使用 Vitis HLS 进行高层次综合时,利用 AXI4 存储器映射 (m_axi) 接口进行数据传输的方法和优势。首先,对于 MAXI 接口的认识和概述进行了阐述,MAXI 接口作为主动、全局、存储器级别的接口,提供了在 FPGA 内部和外部存储器之间高效传输数据的能力。接着,通过代码示例详细展示了如何在函数接口中使用 MAXI 接口进行数据传输,以及如何利用突发模式提高数据传输效率。文中还介绍了全局存储器和本地存储器的特点以及 MAXI 接口的优势,如独立的读写通道、突发访问的支持以及未完成传输事务的管理。此外,还对查看 MAXI 报告和理解其中的信息进行了解释,以及 MAXI 资源消耗和 volatile 关键字在 HLS 中的作用。综合来看,通过合理地利用 MAXI 接口,可以实现 FPGA 内部与外部存储器之间的高效数据交换,从而优化加速器的性能和资源利用率。