文章目录
- 一、LLM 基准测试
- LLM 排行榜
- 二、评估指标
- 1、传统指标
- 2、非传统指标
- 2.1 基于嵌入的方法
- 2.2 其他基于语言模型的指标
- 2.3 LLM 辅助方法
- GPTScore
- G-Eval
- 3、可能的陷阱
- 三、评估基于LLM的应用
- 1、选择评估指标
- 2、评估 评估方法
- 3、构建您的评估集
- 四、工具
- 1、OpenAI 评估
- 2、Ragas
- 五、挑战
- 六、结论
翻译整理自:All about evaluating Large language models
https://explodinggradients.com/all-about-evaluating-large-language-models
LLM 的出现为解决以前认为不可能的问题开辟了途径。大量基于LLM 的应用就证明了这一点。但有一个问题仍然是个谜:如何有效评估基于LLM的应用?
我们将通过本文尝试解开这个谜团,了解用于对 LLM 进行基准测试的方法,并讨论 SOTA 方法、可用框架以及评估基于 LLM 的应用程序时面临的挑战。
一、LLM 基准测试
LLM 主要在开放的特定任务数据集上进行评估,以分析他们执行总结、开卷问答等各种任务的能力。如表中所示,有几个可用的公共基准。
LLM 基准测试中使用的指标因任务而异。大多数任务都是使用传统指标(例如精确匹配)进行评估的,我们将在下一节中介绍。
| Benchmark | Number of tasks |
|---|---|
| Beyond the Imitation Game Benchmark (BIG-bench) | 214 |
| lm-evaluation harness | 200+ |
| Super GLUE | 9 |
| GLUE | 9 |
| Abstraction and Reasoning corpus | 400 |
| Inverse scaling prize |
使用这些基准的主要问题之一是,模型可能在训练或微调阶段暴露于数据集。
这违反了评估集 应排除训练数据 的基本规则。
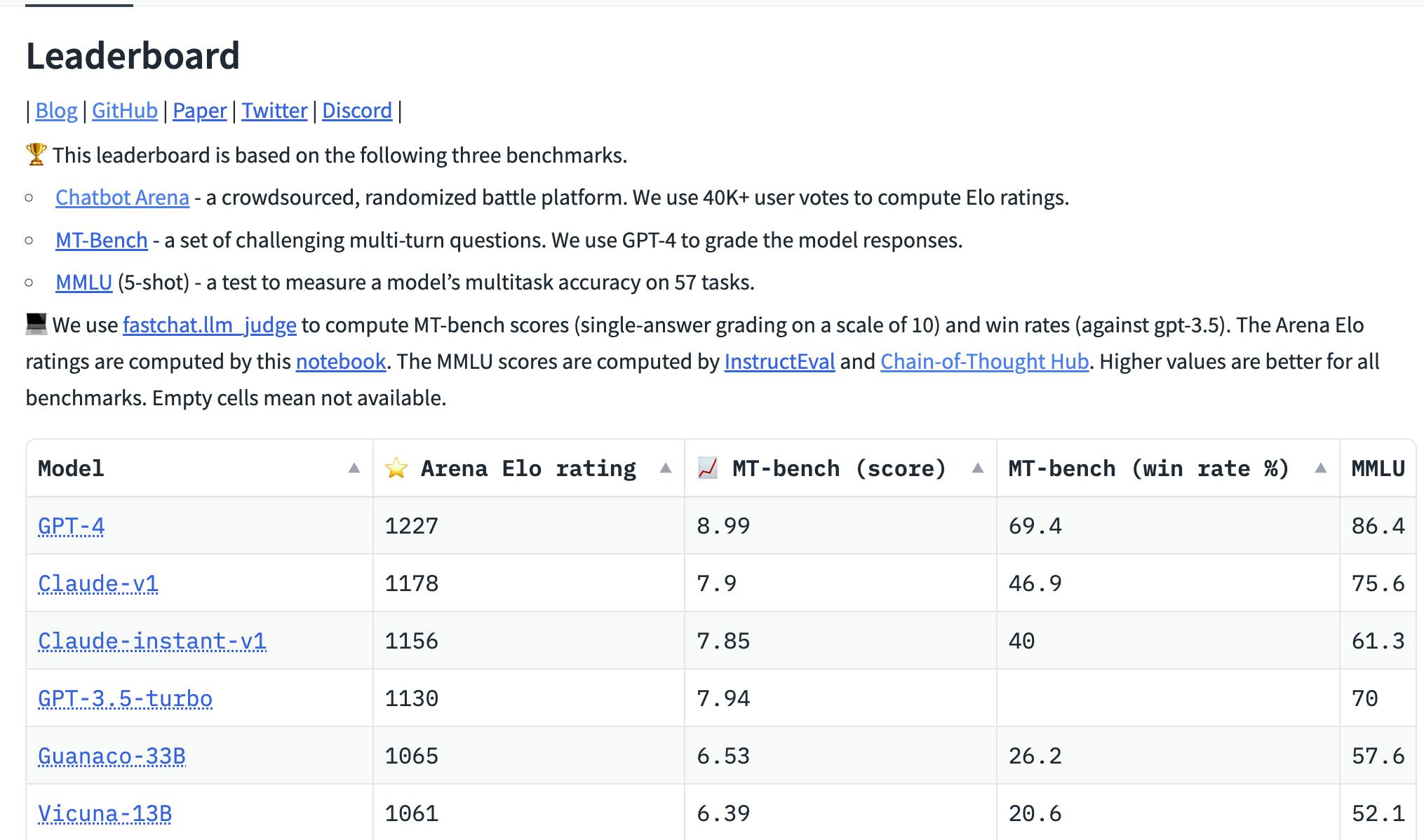
LLM 排行榜
LLM 排行榜为不同基础和指令微调的LLM 提供了活生生的基准。
虽然基础LLM 是在开放数据集上进行评估的,但其指令微调版本主要是使用基于 Elo 的评级系统进行评估。
- Open LLM leaderboard:在 LM 评估工具之上提供了一个包装器
- HELM:根据各种开放数据集和指标 评估 Open LLMs 。
- Chatbot Arena:指导微调LLM 的 Elo 评级
二、评估指标
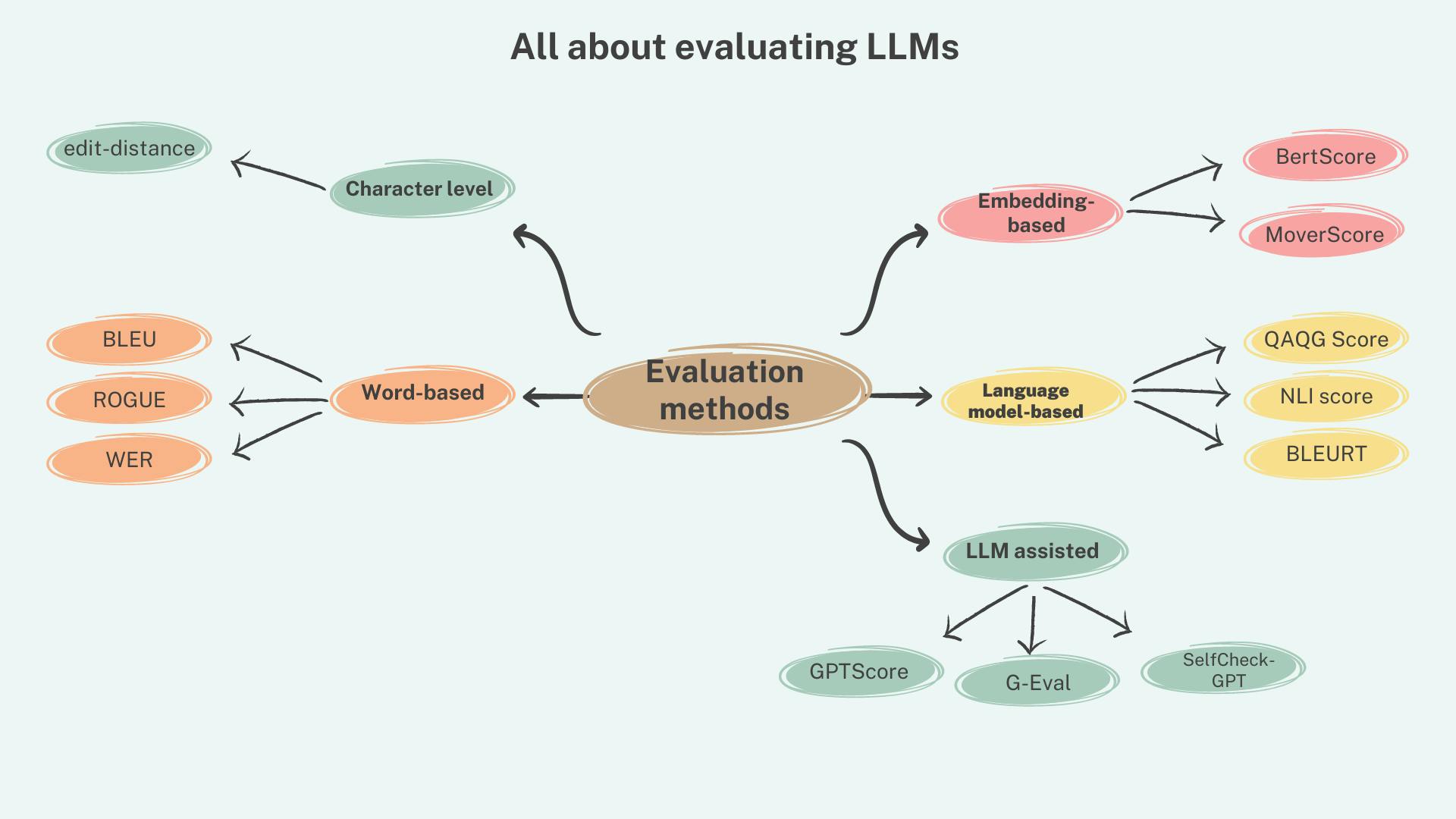
LLM的评估指标大致可分为传统指标和非传统指标。
传统的评估指标依赖于 文本中单词和短语的排列和顺序,并在存在参考文本(基本事实)的情况下组合使用以比较预测。
非传统指标利用语言模型的 语义结构 和 功能来评估生成的文本。
这些技术可以在有或没有参考文本的情况下使用。
1、传统指标
在本节中,我们将回顾一些流行的传统指标及其用例。这些指标在 字符/单词/短语级别上运行。
- WER(单词错误率):有一系列基于 WER 的指标,用于测量编辑距离 𝑑 (𝑐, 𝑟),即将候选词转换为候选词所需的插入、删除、替换以及可能的转置次数。
参考字符串。 - 精确匹配: 通过将生成的文本与参考文本进行匹配来衡量候选文本的准确性。
任何与参考文本的偏差都将被视为不正确。
这仅适用于提取和简短答案的情况,其中预计与参考文本的偏差最小或没有偏差。 - BLEU (Papineni et al.): 根据生成文本中有多少 ngram 出现在参考文本中来评估候选文本。
这最初是为了评估机器翻译系统而提出的。
可以使用几何平均值 (BLEU-N) 计算和组合多个 n-gram 分数 (2gram/3gram)。
由于它是基于精度的指标,因此不会惩罚漏报。
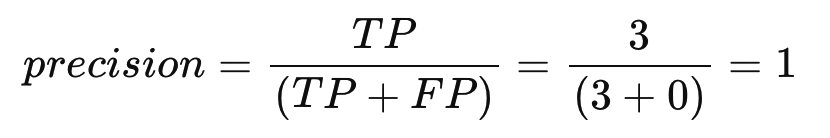
- ROGUE ( Lin et al. 2004 ):这与 BLEU-N 的 n 元匹配计数类似,但基于召回率。
ROGUE 的变体,ROUGE-L 测量一对句子之间的 最长公共子序列 (LCS)。
除此之外,还有其他指标,如 METEOR、通用文本匹配器(GTM)等。
这些指标受到很大限制,与当前大型语言模型的生成能力不相符。
尽管这些指标目前仅适用于具有简短、提取或多选答案的任务和数据集,但这些方法或衍生物仍然在许多基准测试中用作评估指标。
2、非传统指标
用于评估生成文本的非传统指标可以进一步分类为 基于嵌入的方法 和 LLM 辅助的方法。
基于嵌入的方法利用深度学习模型 LLM 辅助方法,生成的标记或句子向量来形成范例,并利用语言模型的功能来评估候选文本。
2.1 基于嵌入的方法
这里的关键思想是利用深度学习模型中文本的向量表示来比较候选文本和参考文本,这些模型代表丰富的语义和句法信息。
使用余弦相似度等方法量化候选文本与参考文本的相似度。
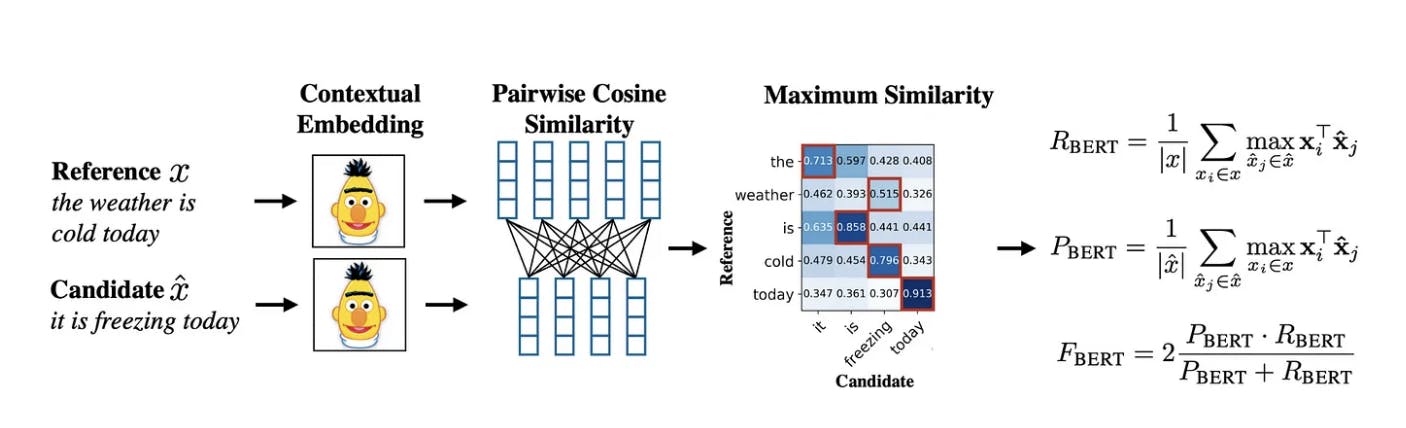
- BERTScore (Zhang et al. 2019):这是一种基于双编码的方法,即将候选文本和参考文本分别输入到深度学习模型中以获得嵌入。
然后使用标记级嵌入来计算成对余弦相似度矩阵。
然后,选择候选者参考中最相似标记的相似度分数,并用于计算精确度、召回率和 f1 分数。
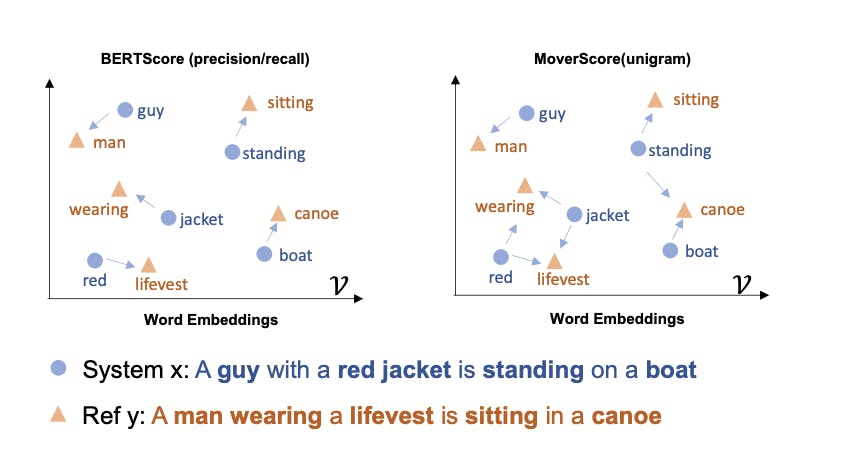
- MoverScore(Zhao et al. 2019):使用词移动者距离的概念,这表明嵌入词向量之间的距离在某种程度上具有语义意义(向量(king)-向量(queen)=向量(man))并使用上下文嵌入计算 n 元语法之间的欧几里得相似度。
与允许一对一硬匹配单词的 BERTscore 相比,MoverScore 允许多对一匹配,因为它使用 软/部分对齐。
尽管基于嵌入的方法很稳健,但它们假设训练和测试数据是相同分布的,但情况可能并非总是如此。
2.2 其他基于语言模型的指标
- Entailment Score:该方法利用语言模型的自然语言推理能力来判断NLG。
该方法有不同的变体,但基本概念是通过使用 NLI 模型 根据参考文本生成蕴含分数 来对生成进行评分。
这种方法对于确保文本摘要 等基于文本的生成任务的忠实度非常有用。

- BLEURT (Sellam 等人):引入了一种将表达性和鲁棒性结合起来的方法,通过在大量合成数据上预训练完全学习的指标,然后根据人类评分对其进行微调。
该方法利用 BERT 模型来实现这一点。
为了概括用于评估任何新任务或领域的模型,提出了一种新的预训练方法,其中涉及对合成数据的额外预训练。
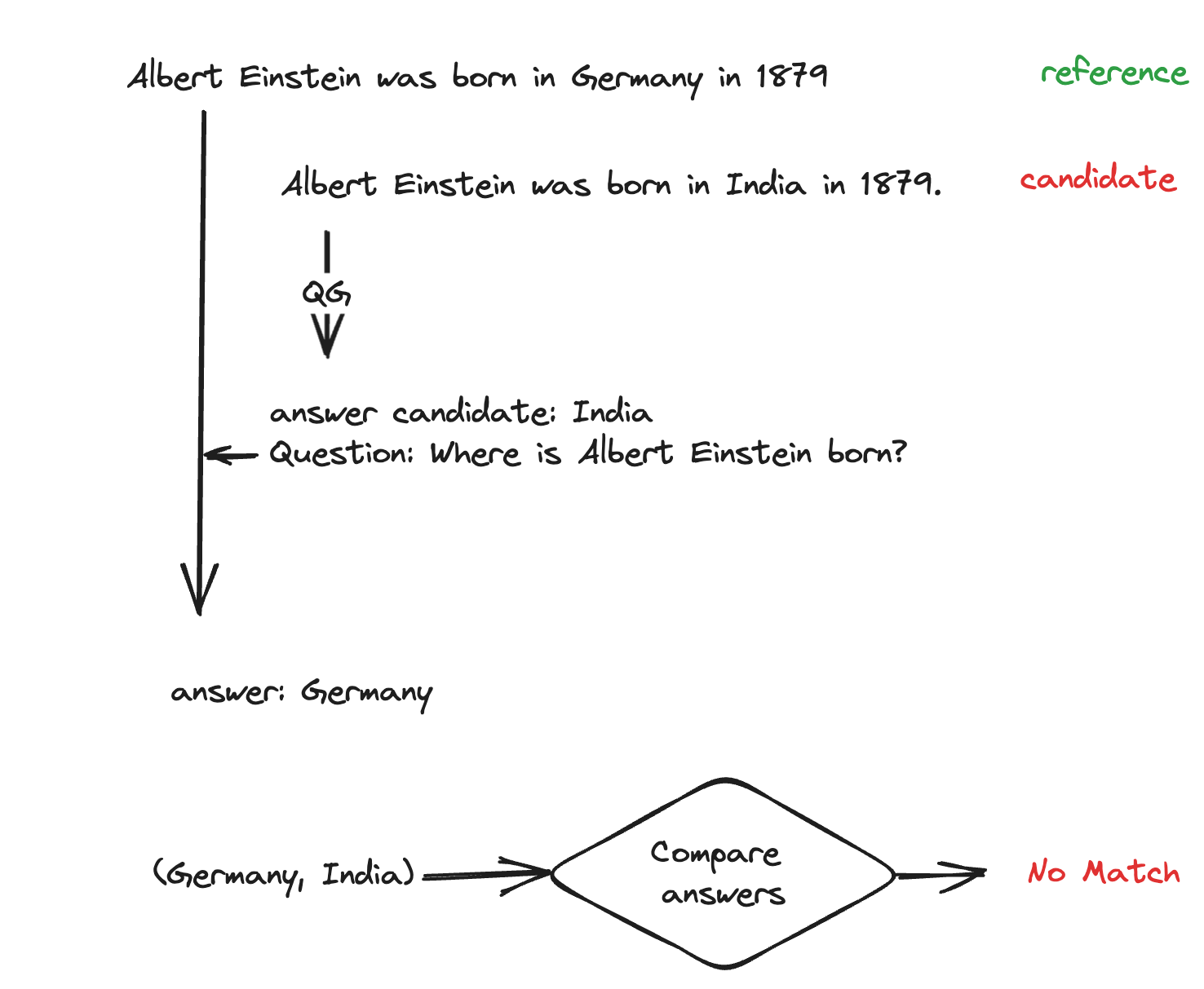
收集来自维基百科的文本片段,然后使用单词替换、回译等技术进行增强,以形成合成对 ( x , x ′ ) (x,x') (x,x′),然后针对 BLUE、ROGUE 分数、回译概率、自然等目标进行训练语言推理等 - 问答 - 问题生成(QA-QG) (Honovich et. al): 此范式可用于衡量任何候选内容与参考文本的一致性。
该方法的工作原理是,首先根据候选文本形成(候选答案、问题)对,然后比较和验证给定参考文本的同一组问题生成的答案。
2.3 LLM 辅助方法
顾名思义,本节讨论的方法利用大型语言模型来评估 LLM 生成。
这里需要注意的是,要利用LLM 的能力并形成范式,以最大限度地减少LLM 可能存在的不同偏见的影响,例如更喜欢自己的输出而不是其他LLM 的输出。
GPTScore
Fu et. al 2023 : https://arxiv.org/pdf/2302.04166.pdf
是最早使用 LLM 作为评估者的方法之一。
这项工作探讨了LLM 评估生成文本的多个方面(如信息性、相关性等)的能力。
这需要定义一个评估模板时间 $ T(.) $ 适合每个所需的方面。
该方法假设LLM 将为更高质量的生成分配更高的令牌概率,并使用生成目标文本(假设)的条件概率作为评估指标。
对于任何给定的提示 d、候选响应 h、上下文 S 和方面 a,GPT 分数由下式给出
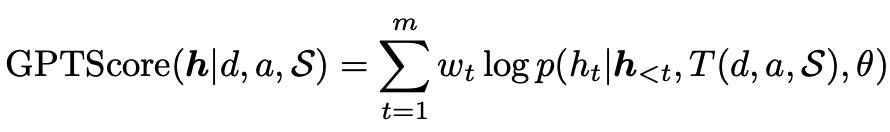
G-Eval
Liu et al. 2023 : https://arxiv.org/abs/2303.16634
也是与 GPTscore 非常相似的方法,因为生成的文本是根据标准进行评估的,但与 GPTscore 不同的是,G-Eval 直接通过显式指示模型在 0 到 5个范围 之间为生成的文本分配分数来执行评估。
众所周知,LLM 在分数分配过程中存在一些偏差,例如偏爱整数分数 和 偏向给定范围内的特定数字(例如 0-5 范围内的 3)。解决输出分数乘以token概率 𝑝(i)
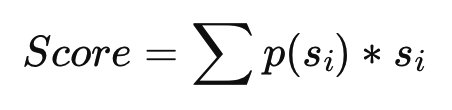
尽管这两种方法都可以用于包括事实性在内的多方面评估,但SelfCheckGPT (Manakul 等人,2023)中提出了一种在没有参考文本的情况下检测和量化幻觉的更好方法,该方法利用了一个简单的想法,即如果LLM 拥有由于对给定概念的了解,样本响应可能是相似的并且包含一致的事实。
为了衡量生成的响应之间的信息一致性,可以使用 QA-QG 范式、BERTScore、蕴含分数、n-gram 等。
3、可能的陷阱
随着高性能大型语言模型的出现,趋势正朝着使用LLM本身来评估NLG的方向发展。
虽然这种方法已被证明与人类判断具有高度相关性(Wang et al. 2023),但这种方法存在一些问题
- 初步研究)一些工作揭示了这种方法的缺陷。像(Wang et al. 2023)这样的研究表明,LLM 存在位置偏差,因为它更喜欢在特定位置做出更好的反应。
- LLM 还表明,在为候选人的回答分配分数时更喜欢整数。
- LLM 本质上也是随机的,这使得它们在单独调用时为相同的输出分配不同的分数。
- 当用于比较答案时,我们发现 GPT4 更喜欢其回答风格,甚至胜过人类编写的答案。
三、评估基于LLM的应用
1、选择评估指标
LLM 应用的评估指标是根据交互模式和预期答案类型来选择的。
与LLM的互动主要有三种形式
- knowledge-seeking:LLM 会提出问题或说明,并期望得到真实的答案。
例如,印度有多少人口? - Text grounded:LLM 提供文本和说明,并期望答案完全基于给定的文本。
例如,总结给定的文本。 - 创造力:LLM 会提出问题或说明,并期望得到创造性的答案。
例如,写一个关于阿育王王子的故事。
对于每一个交互或任务,预期的答案类型可以是抽取式、抽象式、简短形式、长形式或多选。
例如,对于LLM 在科学论文摘要(文本基础+抽象)中的应用,结果与原始文档的忠实性和一致性是非常重要的。
2、评估 评估方法
一旦制定了适合您的应用的评估策略,您应该先评估您的策略,然后再相信它可以量化您的实验性能。
通过量化评估策略与人类判断的相关性来评估评估策略。
- 获取或注释包含 黄金人类注释分数的测试集
- 使用您的方法对测试集中的各代进行评分。
- 使用 Kendall 等级相关系数 等相关性度量来衡量人工注释分数和自动分数之间的相关性。
0.7 或以上的分数通常被认为足够好。这也可用于提高评估策略的有效性。
3、构建您的评估集
在形成任何机器学习问题的评估集时要确保的两个基本标准是
- 数据集应该足够大以产生具有统计意义的结果
- 它应该尽可能代表整个生产中预期的数据。
为基于 LLM 的应用形成评估集可以逐步完成。
还可以利用LLM 通过一些镜头提示来生成评估集的查询,自动评估器等工具可以帮助实现这一点。
具有基本事实的评估集管理既昂贵又耗时,并且维护这样一个针对数据漂移的黄金注释测试集是一项非常具有挑战性的任务。
如果无监督的LLM 辅助方法与您的目标没有很好地相关,那么可以尝试一下。
参考答案的存在有助于提高某些方面(例如事实性)评估的有效性。
四、工具
1、OpenAI 评估
Evals是一个用于评估 LLM 世代的开源框架。
使用此框架,您可以根据您定义的参考基准事实评估指令的完成情况。
它提供了修改和添加数据集以及新的完成(例如,思想链)的灵活性。
评估数据集应采用所示格式
https://gist.github.com/shahules786/ef5d85b997c977dbf22140103ae2dd62
{"input": [{"role": "system", "content": "Complete the phrase as concisely as possible."},
{"role": "user", "content": "ABC AI is a company specializing in ML "}], "ideal": "observability"}
精确匹配等指标 用于计算完成的准确性。
2、Ragas
Ragas是一个专门针对检索增强生成的评估框架。
它使用 SOTA LLM 辅助方法来量化 RAG 管道在事实性、相关性等多个方面的性能。
您还可以使用 llama_index 等框架来评估您构建的管道的性能,而无需使用带注释的评估数据集。
from ragas import evaluate
from datasets import Dataset
import os
os.environ["OPENAI_API_KEY"] = "your-openai-key"
# prepare your huggingface dataset in the format
# Dataset({
# features: ['question','contexts','answer'],
# num_rows: 25
# })
dataset: Dataset
results = evaluate(dataset)
# {'ragas_score': 0.860, 'context_relavency': 0.817,
# 'factuality': 0.892, 'answer_relevancy': 0.874}
五、挑战
评估自然语言生成仍然是一个开放的研究领域。
我们想要在这里评估的许多属性都是非常主观的,例如无害性、有用性等,并且在一组预定义的带注释的任务之外衡量事实性是一项非常具有挑战性的任务。
对于企业来说,由于数据和概念漂移等因素,构建和维护这样的评估数据集也可能非常昂贵且耗时。
六、结论
在产品化之前评估基于 LLM 的应用 应该是 LLM 工作流程的关键部分。
这将充当质量检查 并帮助您随着时间的推移 提高管道的性能。
通过本文,我们讨论并回顾了实现此目的的大多数可能方法。
请在评论部分告诉我您的想法,如果您喜欢类似的内容,请在Twitter上与我保持联系。
2024-04-29(一)