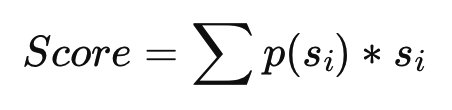1. Java与编译相关的三个概念:
首先了解三个概念
- 前端编译
- 解释执行
- 编译执行
▌1.1、前端编译
编译器(javac)将源文件(.java)编译成java字节码文件(.class)的步骤是前端编译。
▌1.2、解释执行
在JVM加载字节码后,每次执行方法调用时,JVM都会将字节码翻译成机器码,然后执行机器码,这个过程叫解释执行。
解释执行为了提升启动效率,并没有在启动时将字节码全部翻译成机器码,所以启动效率较高
但是,
由于字节码不行执行,要机器码才能执行,所以,执行时要进行字节码翻译,所以执行效率相对较低
▌1.3、编译执行
什么是编译执行?
与解释执行相反,JVM加载字节码的时候,直接将字节码转换为机器码,在执行方法调用时直接执行机器码,不需要做翻译工作,这样的过程叫编译执行。
编译执行的问题是什么呢?
和解释执行相反,编译执行在启动时将字节码全部翻译成机器码,所以启动效率较低
但是
编译执行时省去了翻译的步骤,所以执行效率相对较高
2. 架构师视角:架构上, JVM 如何实现 启动速度、执行速度的双优?
解释执行的特点是:启动效率高、执行效率低
编译执行的特点是:启动效率低、执行效率高
JVM如何实现双高呢?实现,启动效率高、执行效率也高。
▌2.1、如何平衡启动速度和执行的速度
为了平衡启动和执行的效率,JVM结合解释执行和编译执行的特点,进行综合和平衡,形成了一种折中的性能优化策略。
JVM以解释执行,编译执行为辅,达到启动速度和执行速度的最优化。
那些代码需要编译执行呢?热点代码。
JVM 并不对全部代码进行编译执行,仅仅对热点代码进行编译优化,这样的执行过程叫即时编译
▌2.2、什么是“热点代码”(Hot Spot Code)?
当JVM发现某个方法或代码块运行特别频繁的时候,就会认为这是“热点代码”(Hot Spot Code)。
然后JIT会把部分“热点代码”翻译成本地机器相关的机器码,并进行优化,然后再把翻译后的机器码缓存起来,以备下次使用。
把翻译后的机器码缓存在哪里呢? 这个 机器码缓存,叫做 Code Cache。
当JVM下次遇到相同的热点代码时,跳过解释的中间环节,直接从 Code Cache加载机器码,直接执行,无需 再编译。
所以,JIT总的目标是发现热点代码, 热点代码变成了提升性能的关键,Java官方给自家开源的JVM取字为hotspot JVM,也就是这么来的。
说得更大白话一点,Java官方把识别“热点代码”(Hot Spot Code)这个任务,写在名字上,作为毕生的追求。
所以,JVM总的策略为:
- 对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;
- 另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,并且缓存起来,后面省略编译的过程,直接从缓存当中取得机器码,从而以达到理想的运行速度。
2.3 架构师视角解读:JVM中的缓存架构
“热点代码”(Hot Spot Code)编译后,放入到 Code Cache中,当JVM下次遇到相同的热点代码时,直接从 Code Cache加载机器码,跳过中间的编译环节,无需再编译。
从架构的角度来说,这里应用到了尼恩常说的3高架构的三板斧之一: 缓存架构。
可见,JVM和WEB应用实现高并发的手段,是非常类似的。JVM为了实现高性能和高并发,也会使用缓存架构。
大家知道,CPU内部,为了提升性能,也用了缓存架构,并且是多级缓存架构。
同时,在缓存架构中, 热点数据非常重要。
在WEB应用的缓存架构中,识别热点数据(HotKey),是提升三级缓存命中率的 核心环节。我们会通过有效的 识别组件,识别其中的HotKey。
这种HotKey的理论和思想,在JVM中的缓存架构也是想通的。
JVM中的缓存架构中,不能什么都缓存,需要缓存的同样是他的 HotKey, 这里叫做 Hot Spot Code,仅仅换了一个名字而已。
所以,正如尼恩 三高架构的思想所云,缓存架构 都是相通的:
- 高并发WEB三级缓存架构里边,有hotkey和本地高速缓存
- JVM架构里边有Hot Spot和 Code Cache
3. 即时编译:
▌3.1、即时编译器
JVM包含多个即时编译器,主要有C1和C2,还有个Graal (实验性的)。
多个即时编译器, 都会对字节码进行优化并生成机器码。
但是不同的即时编译器,优化的程度不同:C1会对字节码进行简单可靠的优化,C2会对字节码进行激进优化。
- C1会对字节码进行简单可靠的优化,包括方法内联、去虚拟化、冗余消除等,编译速度较快,可以通过-client强制指定C1编译
- C2会对字节码进行激进优化,包括分支频率预测、同步擦除等,可以通过-server强制指定C2编译
如果没有强制指定,JVM默认会使用分层编译模式。
▌3.2、分层编译模式
JVM不会直接启用C2,而是先通过C1编译收集程序的运行状态,再根据分析结果判断是否启用C2。
分层编译模式下, 虚拟机执行状态由简到繁、由快到慢分为5层
- 0 层,解释执行(Interpreter)
- 1 层,使用 C1 即时编译器编译执行,无profiling
- 2 层,使用 C1 即时编译器编译执行,带基本的 profiling(仅方法调用次数及循环回边执行次数的profiling)
- 3 层,使用 C1 即时编译器编译执行,带完全的 profiling
- 4 层,使用 C2 即时编译器编译执行
什么是profiling ?
profiling是C0/C1在编译过程中收集程序执行状态的过程
收集的执行状态记录为profile (概述/ 印象),包括分支跳转频率、是否出现过空值和异常等,主要用于触发C2编译。
如何实现呢?
profiling 是指在程序执行过程中,JVM织入的一些协助收集数据的辅助代码,这些织入的辅助代码,收集能够反映程序执行状态的数据。这里所收集的数据我们称之为程序的 profile。
profiling 在思想上,非常类似于 Java Agent 的字节码增强。 只是 Java Agent 的字节码增强发生在 字节码 层面,profiling 的指令织入,发生在 机器码的层面。
至于profiling 的指令织入,织入了啥? 咱们不需要深究,除非不想再从事Java开发,而是去用C++ 开发 JVM。 否则,不用关系 织入了啥,了解这个思想就行。
什么是完全的 profiling?
除了 基本的 profiling(仅方法调用次数及循环回边执行次数的profiling)外,
还包括分支 profile(针对分支跳转字节码,包括跳转次数和不跳转次数)以及receiver type(针对成员方法调用或类检测,如checkcast,instanceof,aastore字节码)的类型profile
分层编译5层执行状态之间的关系 ,具体如下图:
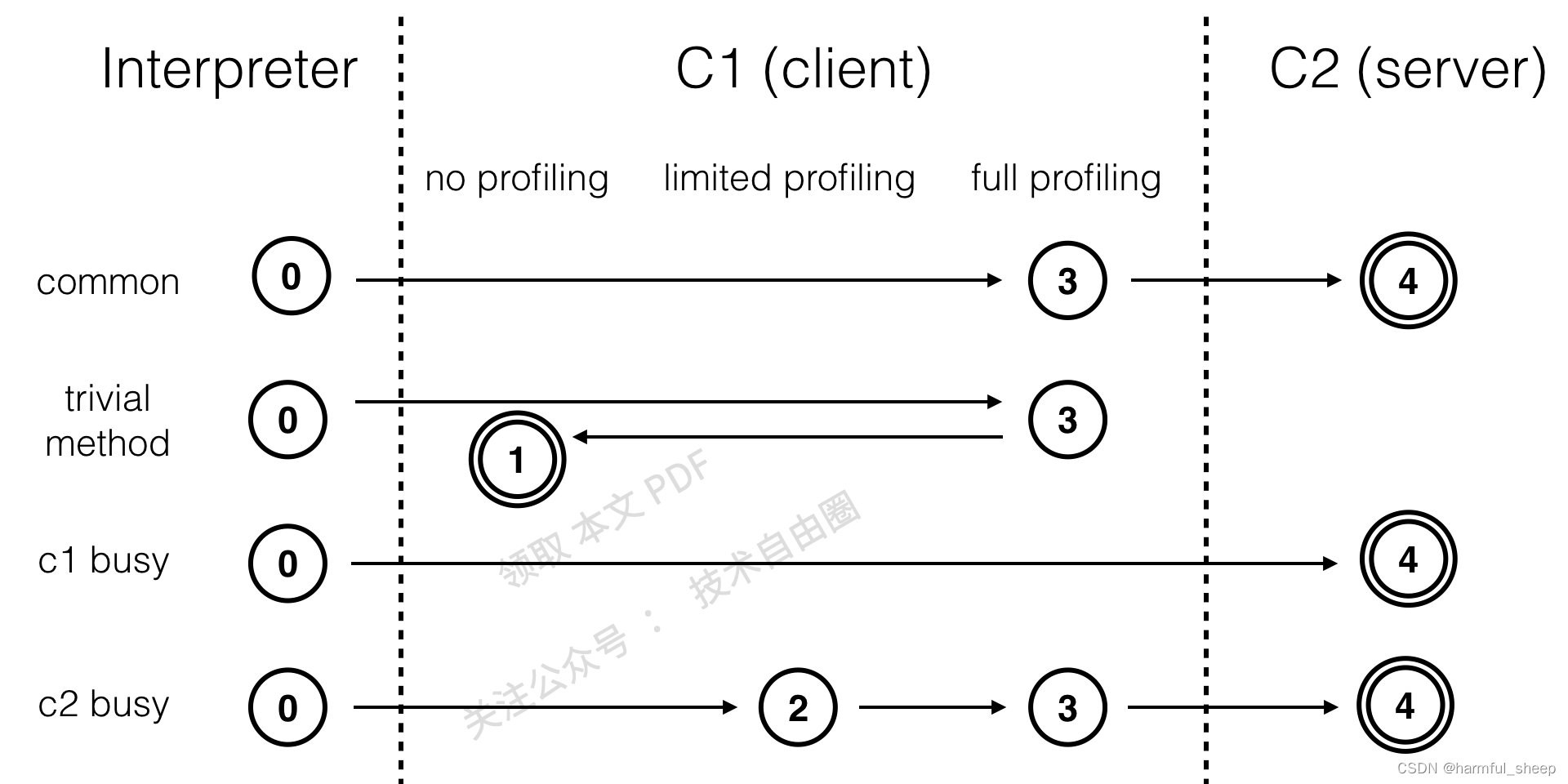
第一条执行路径,指的是通常情况下,一个方法先被解释执行(level 0),然后被C1编译(level 3),再然后被得到profile数据的C2编译(level 4)
第二条执行路径,指的是编译对象非常简单的情况下,如getter和setter,虚拟机认为通过C1编译或通过C2编译并无区别,就会在3层编译后,直接由C1编译且不插入profiling代码(level 1)。
第三条执行路径,指的是C1繁忙时,JVM会在解释执行时收集profiling,而后直接由 4 层的 C2 编译。
第四条执行路径,指的是C2繁忙时,先由2层的C1编译再由3层的C1编译,这样可以减少方法在3层的执行时间,最终再交给C2执行。
注意:这个收集的动作,叫做profiling,这个收集的结果,叫做profile。
分层编译中的 0 层、2 层和 3 层都会进行 profiling,织入的一些协助收集数据的辅助代码, 收集能够反映程序执行状态的数据。
其中,最为基础的便是 2层进行的 profiling,它只需要统计方法的调用次数以及循环回边的执行次数,当统计之和超过阈值就会触发即时编译。
所以,方法的调用次数以及循环回边的执行次数 达到阈值,这部分的代码,就会被识别成为—— 热点代码。
0 层和 3 层相较于 2层复杂一些,需要收集用于 4 层 C2 编译的数据。
比如说分支跳转字节码的分支 profile(branch profile),包括跳转次数和不跳转次数,
比如 receiver 类型 profile(receiver type profile):非私有实例方法调用指令、强制类型转换 checkcast 指令、类型测试 instanceof 指令,和引用类型的数组存储 aastore 指令。
上述数据分为两大类:分支 profile 和类型 profile。
根据图片中的编译途径可知,分层编译下,无论何种情况,大概率都要进行分支 profile 和类型 profile 的收集。
但是,需要注意的是,有利必有弊: 分支 profile 和类型 profile 的收集,将给应用程序带来不少的性能开销。
据统计,正是因为这部分额外的 profiling,导致的一个结果是:
3 层 C1 代码(带完全的profile)的性能比 2 层 C1 代码(带基本的 profiling)低 30%。
那么这些耗费巨大代价收集而来的 profile 具体有什么作用呢?
答案是:
C2 可以根据收集得到的数据进行猜测,从而作出比较激进的优化。
当然:4层的C2代码有一个前提,就是 假设接下来的执行,同样会C1 代码按照所收集的 profile 进行。
▌3.3、触发即时编译的时机
当方法调用次数profile或循环次数profile达到阈值时,会触发即时编译
阈值可以通过VM选项设置
-XX:TierXInvocationThreshold
-XX:TierXMINInvocationThreshold
-XX:TierXCompileThreshold除了和上面的这些选项值有关,即时编译的触发,还跟待编译方法的数目和编译线程的总数有关。
编译线程的数量是处理器动态指定的,参数为
-XX:+CICompilerCountPerCPU这个参数,默认开启。
也可以通过VM选项强制指定编译线程总数:
-XX:+CICompilerCount=NJVM会将这些线程以1:2的比例分配给C1和C2
▌3.4、去优化
去优化是当C2编译的机器码假设失败时,将即时编译切换回解释执行的过程。
在生成的机器码中,即时编译器将在假设失败的位置上插入一个陷阱(trap)。
该陷阱实际上是一条 call 指令,调用至 Java 虚拟机里专门负责去优化的方法。
与普通的 call 指令不一样的是,去优化方法将更改栈上的返回地址,不再返回即时编译器生成的机器码中。
去优化的过程相当复杂。由于即时编译器采用了许多优化方式,其生成的代码和原本的字节码的差异非常之大。
去优化的过程中,需要将当前机器码的执行状态,转换至某一字节码之前的执行状态,并从该字节码开始执行。
这便要求即时编译器在编译过程中,记录好这两种执行状态的映射。
当根据映射关系创建好对应的解释执行栈桢后,Java 虚拟机便会采用 OSR 技术,动态替换栈上的内容,并在目标字节码处开始解释执行。
此外,在调用 Java 虚拟机的去优化方法时,即时编译器生成的机器码可以根据产生去优化的原因,来决定是否保留这一份机器码,以及何时重新编译对应的 Java 方法。
- 如果去优化的原因与优化无关,即使重新编译也不会改变生成的机器码,那么生成的机器码可以在调用去优化方法时传入 Action_None,表示保留这一份机器码,在下一次调用该方法时重新进入这一份机器码。
- 如果去优化的原因与静态分析的结果有关,例如类层次分析,那么生成的机器码可以在调用去优化方法时传入 Action_Recompile,表示不保留这一份机器码,但是可以不经过重新 profile,直接重新编译。
- 如果去优化的原因与基于 profile 的激进优化有关,那么生成的机器码需要在调用去优化方法时传入 Action_Reinterpret,表示不保留这一份机器码,而且需要重新收集程序的 profile。
▌4. 方法内联:
在即时编译方法时,将目标方法的方法体取代方法调用的过程叫方法内联,
方法内联 增加了编译的代码量,但是降低了方法调用带来的入栈出栈的成本
▌4.1、静态方法内联
即时编译器会根据方法调用层数,目标方法的调用次数及字节码大小等决定该方法是否允许被内联
- -XX:CompileCommand配置中的inline指令指定的方法会被强制内联,dontinline和exclude指定的方法始终不会被内联
- @ForceInline注解的jdk内部方法会被强制内联,@DontInline注解jdk内部方法始终不会被内联
- 方法的符号引用未被解析、目标方法所在类未被初始化、目标方法是native方法,都会导致方法无法内联
- C2默认不支持9层以上的方法调用(-XX:MaxInlineLevel),以及1层的直接递归调用(-XX:MaxRecursiveInlineLevel)
- 自动拆箱总会被内联,Throwable类的方法不能被其他类内联等
▌4.2、动态方法内联
即时编译器需要将动态绑定的虚方法转化为直接调用,才能进行方法内联,这样的过程叫虚方法的去虚化
- 根据字节码生成的IR图确定调用者类型的过程叫基于类型推导的完全去虚化
- 根据JVM中已加载的类找到接口的唯一实现的过程叫基于类层次分析的完全去虚化
- 根据编译时收集的类型profile,依次匹配方法调用者的动态类型与profile中的类型
▌逃逸分析:
当方法内部定义的对象被外部代码引用时,称为该对象逃逸,JVM对对象的分析过程叫逃逸分析
根据逃逸分析,即时编译器会在编译过程中对代码做如下优化:
- 锁消除:当一个锁对象只被一个线程加锁时,即时编译器会把锁去掉
- 栈上分配:当一个对象没有逃逸时,会将对象直接分配在栈上,随着线程回收,由于JVM的大量代码都是堆分配,所以目前JVM不支持栈上分配,而是采用标量替换
- 标量替换:当一个对象没有逃逸时,会将当前对象打散成若干局部变量,并分配在虚拟机栈的局部变量表中
▌即时编译的其他优化:
字段读取优化:缓存多次读取的数据,减少出入栈次数
public String register(User user,String username,String password){
user.username = username;
return user.username + password;
}
class User{
private String username;
}public String register(User user,String username){
String s = user.username; //user.username被缓存成了s
s = username;
return s + password;
}字段存储优化:将被覆盖的赋值操作优化掉,减少无用的入栈
private void test(){
int a = 1;
a = 2;
}
private void test(){
int a = 2;//a=1被优化掉了
}循环无关代码外提:避免重复执行表达式,减少出入栈次数
private void test(String s){
String password;
for (int i=0;i<10;i++){
password = s.replaceAll("/","");
System.out.println(i);
}
}
private void test(String s){
String password = s.replaceAll("/","");//与循环无关的代码被编译器外提了
for (int i=0;i<10;i++){
System.out.println(i);
}
}循环展开:将相同的循环逻辑多次重复在一次迭代中,以减少循环次数
private void test(int[] arr){
int sum=0;
for (int i=0;i<8;i++){
sum +=arr[i];
}
}
private void test(int[] arr){
int sum=0;
for (int i=0;i<8;i+=2){//循环次数减少
sum +=arr[i];
sum +=arr[i+1];//重复循环体内相同逻辑
}
}循环的自动向量化:对循环中地址连续的数组操作,会按顺序批量出入栈(这段是伪代码)
private void test(int[] arr1,int[] arr2){
for (int i=0;i<arr1.length;i++){
arr1[i] = arr2[i];
}
}
private void test(int[] arr1,int[] arr2){
for (int i=0;i<arr1.length;i+=4){
arr1[i:i+4] = arr2[i:i+4];//可以看成是在循环展开的基础上,将多个数组一块出入栈
}
}