对五个下游任务进行了实验比较,包括单/多标签分类、视觉对象跟踪、像素级分割、图像到文本生成和人/车辆再识别。
论文:https://arxiv.org/abs/2404.09516
作者单位:安徽大学、哈尔滨工业大学、北京大学
更多相关工作将在以下GitHub上不断更新
https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List
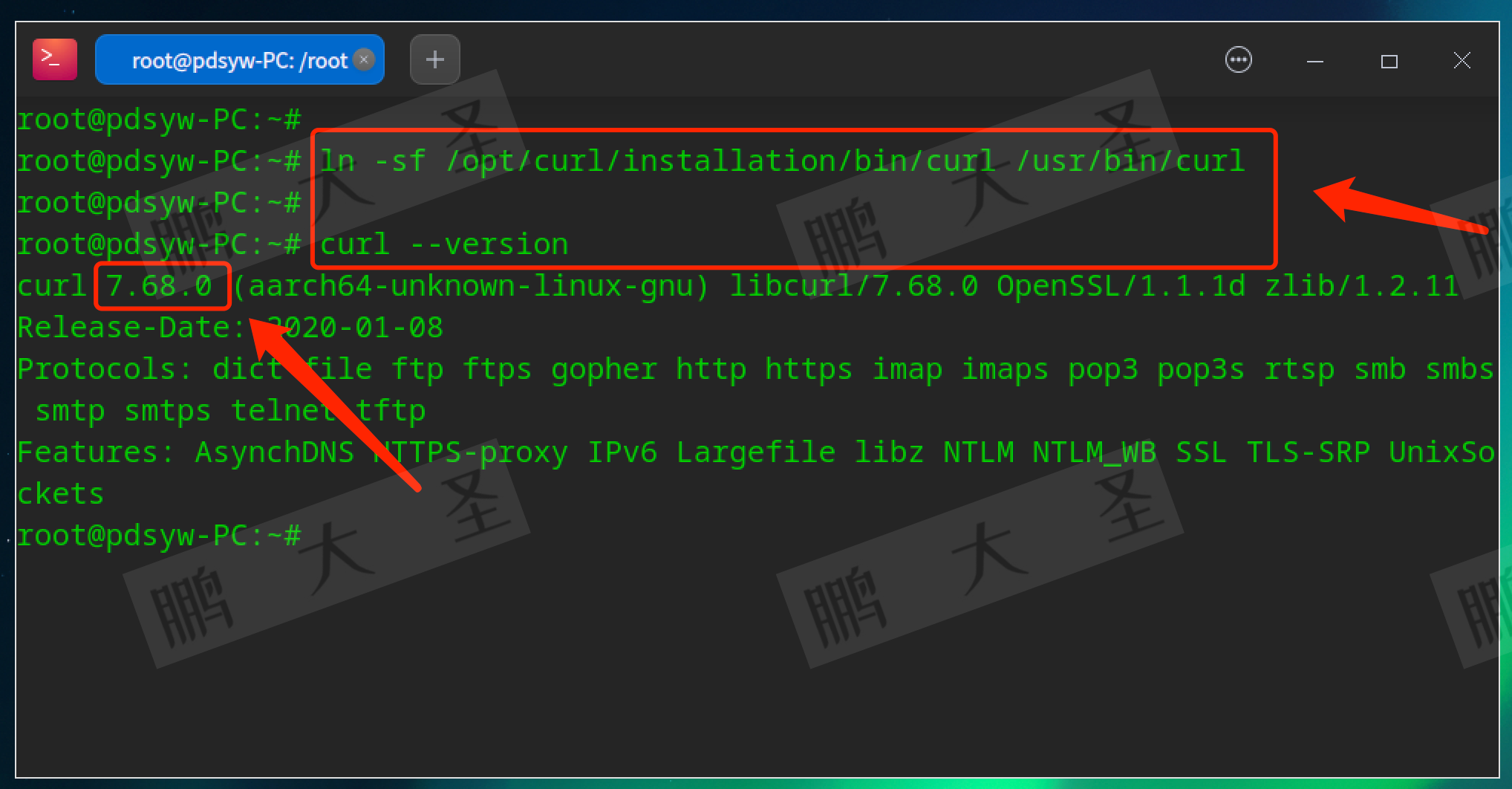
对于单标签分类问题,我们在广泛使用的ImageNet-1K[2]数据集上计算现有作品的准确率。如图12 (d)所示,我们可以发现,
基础版本的VMamba[60]和Mamba2D[68]在ImageNet1K数据集上取得了更好的结果,top-1的准确率分别为83.2%和83%。我们也很容易发现,目前基于mamba的视觉模型都是微小的、小的或基础的版本,很少预训练一个大型或巨大版本的Mamaba网络。总体性能与一些基于Transformer的模型相当,但仍然不如ImageNet分类数据集上的最先进的模型。
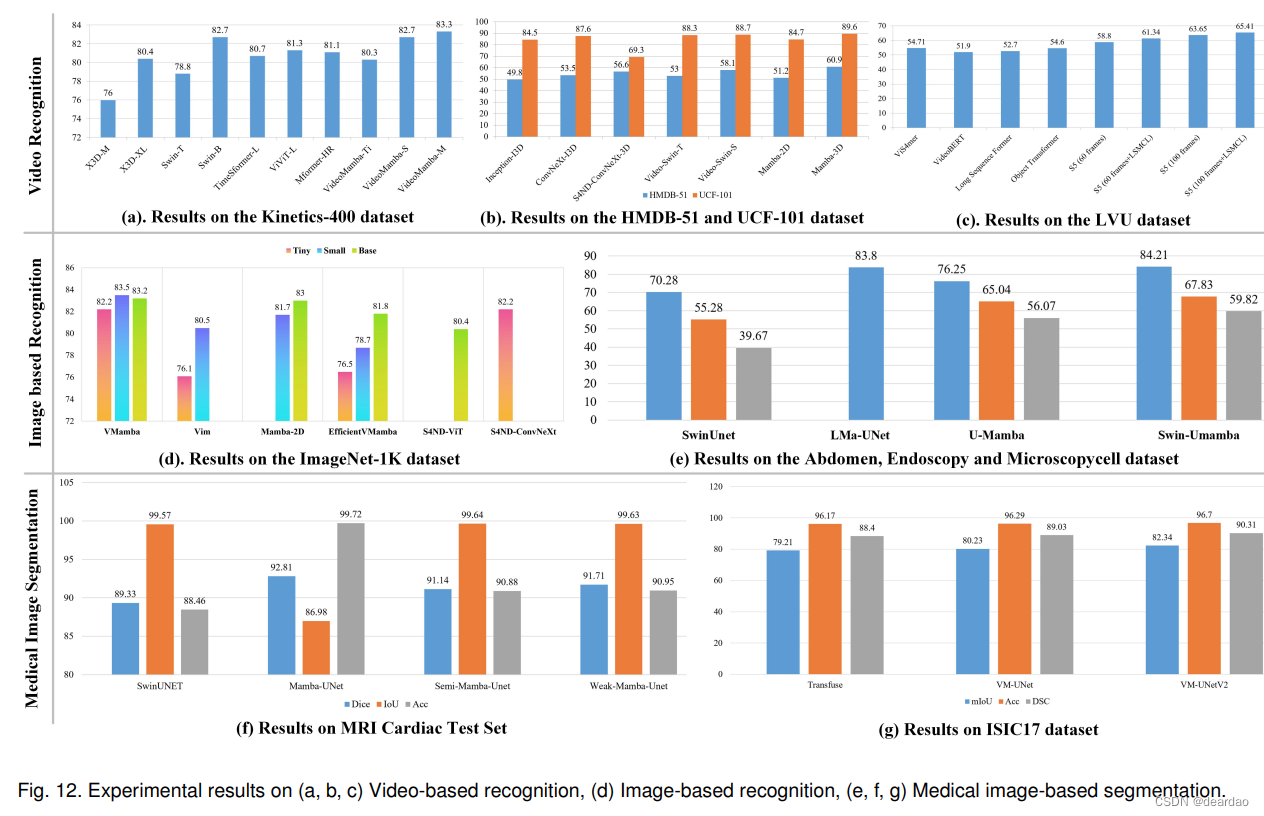
对于多标签分类,我们选择行人属性识别(Pedestrian Attribute Recognition, PAR)任务[6],在PA100K[208]和PETA[209]数据集上进行实验。PA100K数据集包含从598个场景中收集的100,000个样本,涉及26个行人属性。我们基于默认设置(8:1:1)分割训练、验证和测试子集。
PETA数据集包含61个二值属性和19,000人的照片。训练、验证和测试子集分别包含9500、1900和7600张图像。按照其默认设置,选择35个行人属性进行实验。
本实验采用ViT-S[19]和基于mamba的网络虚拟机[61]作为主干。我们遵循基于视觉语言融合的PAR框架VTB[207],该框架以行人图像和属性集为输入,并预测每个属性的逻辑分数。从表10报告的实验结果可以发现,基于Vim-S的PAR模型在PETA数据集上达到81.08/73.75/80.91/84.96/82.52,在PA100K数据集上达到80.41/78.03/85.39/88.37/86.39。这些结果明显优于基于ViT-S的模型,但仍然明显低于基于Transformer网络开发的PAR算法。例如,基于vitb的VTB在PETA和PA100K数据集上达到85.31/79.60/86.76/87.17/86.71,83.72/80.89/87.88/89.30/88.21。
视觉目标跟踪
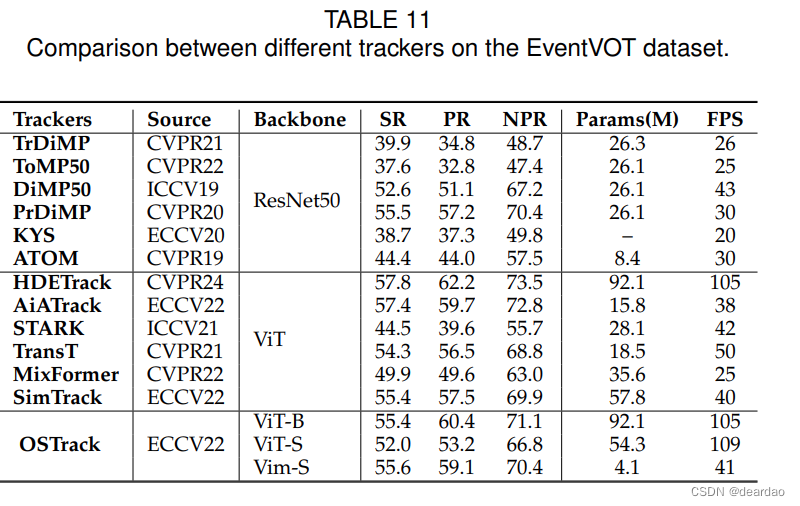
在本节中,我们比较了Mamba与Transformer,以及基于CNN的骨干基于OSTrack的跟踪任务[210]。具体来说,基于CNN的跟踪器有TrDiMP[211]、ToMP50[212]、DiMP50[213]、PrDiMP[214]、KYS[215]和ATOM [216];基于Transformer的跟踪器是HDETrack[217]、AiATrack[218]、STARK[219]、TransT[220]、MixFormer[221]和SimTrack[222]。为了实现公平的比较,我们在一个大规模的基于事件的跟踪数据集EventVOT[217]上训练和测试这些跟踪器,该数据集分别包含841、18和282个视频。详细实验结果见表11和图13。注意,比较中使用了三种广泛使用的评估指标,包括成功率(SR)、准确率(PR)和归一化准确率(NPR)。从表11中我们可以发现,使用Mamba骨干网替换ViT时,性能略有下降,但同时带来了参数数量的巨大减少(仅4.1M)。因此,我们可以得出结论,曼巴网络将是一个有前途的选择,为基于事件的跟踪。
像素级分割
最近,曼巴网络在医学图像分割中得到了广泛的应用,如图12 (e, f, g)所示。例如,基于swing - transformer的模型SwinUNet[223]在MRI心脏数据集中获得了89.33/99.57/88.46 (Dice, IoU, Accuracy)。相比之下,基于mamba的UNet实现了类似甚至更好的分段结果,如Mamba-UNet[67],半Mamba-UNet[70]和弱Mamba-UNet[72]。这些结果充分证明了曼巴结构在医学图像分割中的有效性。
Image-to-Text代
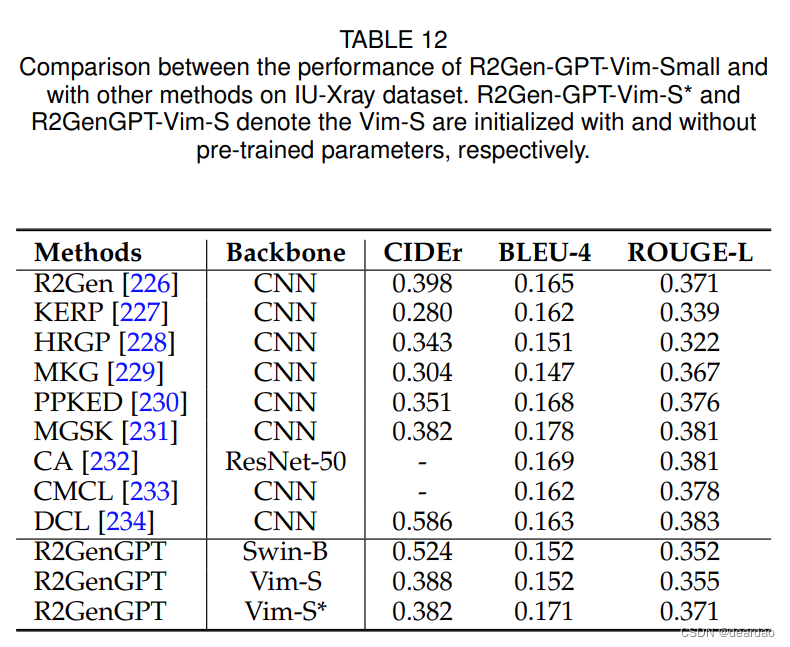
对于图像到文本的生成,我们选择x射线医学的x射线报告生成任务图像作为输入,生成医疗报告5。在实验中,我们选择R2GenGPT6作为基线,并在IU-Xray数据集上评估其性能[224]。R2GenGPT由视觉编码器(Swin Transformer[20])、线性层和大型语言模型(llama-2-7B-chat[225])组成。训练方法包括最初冻结语言模型,然后对视觉编码器和线性层进行微调。我们将Swin Transformer替换为Vim模型[61],并将结果与表12中的其他方法进行比较。由于这两个模型都使用预训练的组件,Vision Mamba在BLEU-4和ROUGE-L评分方面表现出比Swin Transformer模型更优越的性能。
人/车辆 Re-ID
如表13所示,我们对人再识别[257]和车再识别[256]两个再识别(re-ID)任务进行了实验。对于人员re-ID,使用了四个广泛使用的数据集,包括MSMT17 [258], Market1501 [259], DukeMTMC[260]和Occluded-Duke[261]数据集。从不同的场景中捕获这些数据集,并收集来自摄像机覆盖范围重叠的监控系统的样本,存在跨时间跨度、遮挡和背景干扰等挑战。对于车辆reID,使用VeRi-776[262]和VehicleID[263]数据集进行实验验证。与行人样本不同,观察视点的变化也会给车辆带来显著的外观差异,因此车辆数据集额外提供视点标签来标记车辆样本的不同视点。对于上述数据集,我们使用累积匹配特征(CMC)曲线和平均平均精度(mAP)作为评价指标。
参考TransReID[255]和Strong Baseline[264]等主流框架,我们保留了ID Loss、Triplet Loss和BN Layer,使用Vim[61]和VMamba[60]替代了CNN和Transformer主干,探索Mamba在重新识别任务中的潜力,对比结果如表13所示。Mamba模型提出的选择性扫描机制(SSM)允许低复杂度的序列建模,Vim和VMamba在此基础上进一步提出了二维图像数据的SSM建模方法。与需要复杂模块设计的基于cnn的模型相比,简单的Mamba网络已经具有有效性。即使与DeiT[265]、ViT[19]等复杂度较高的模型相比,Vim提出的双向扫描机制训练参数较少,在VehicleID数据集上也显示出了有效性。相比之下,vamba的交叉扫描机制不依赖于Transformer的结构(例如,位置嵌入和类标记),在Market1501、DukeMTMC和VeRi-776数据集上取得了可比较的结果。因此,我们期望在未来有更多基于曼巴的研究适用于重新识别任务。