概述
在本文中,我们将会 对 UUIDs 和基于时间的 UUIDs(time-based UUIDs) 进行一些探讨。
当我们在对基于时间的 UUIDs 进行选择的时候,总会遇到一些好的方面和不好的方面,如何进行选择,也是我们将要简要探讨的内容。
同时我们还会对可能会使用类库进行一些比较和探索,以便于我们更好的做出选择。
UUIDs 和 基于时间的 UUIDs
UUID 的全称是 Universally Unique Identifier,中文为通用唯一识别码。
当生成 UUID 的时候,系统总会自动生成一个 128 位的 UUID。基于 UUID 的生产算法的不同,我们会有不同的版本。
UUID 的主要目的就是用来在全世界中唯一标识一个数据,而且需要保证生成的 UUID 在全世界范围内是不重复的。因此我们可以用来标识一个上下文,包括数据库系统,计算机系统中的消息,分布式系统中的对象等等。
为了实现这个目标,我们需要确保哪怕是在同一个时间瞬间生成的 UUID 也是不相同,这样能够让我们更好的利用 UUID 在分布式计算机系统中标识存在的对象。
基于时间的 UUID,通过字面就可以了解到,这个 UUID 是基于时间的,实际上这个 UUID 存在 UUID 设计中的第一版。
这个版本是基于随机数的,使用的基数为每 100 纳秒为一个单位,时间的起点为1582年10月15日。同时还需要加上当前计算机的网卡物理地址(MAC)。
在后续的版本中,UUID (v6 和 v7)也是基于时间的 UUID 生成算法,可以说是基于 UUID v1 的更新版本。
UUID v1 因为是基于时间的,所以具有排序功能,这个在对数据库的设计上就很有帮助,当我们使用 UUID v1 来作为 PK(主键)的时候,我们就知道了,我们创建的这条记录的时间戳是什么时候,这个对我们在对数据进行调试和问题分析的时候就很有帮助了。
有优势就自然会有劣势,因为我们是基于时间创建 UUID 的,那么在同一个系统产生 UUID 冲突的可能性就会大很多,假设在同一个时间点,我们创建了很多个 UUID,那么大概率就会有出现冲突,重复出现的情况。
在本文的后部分,我们会对这个可能出现的情况进行一些探索。
另外一个原因,就是在 UUID v1 版本中使用主机地址这种做法会潜在的增加系统的安全性问题。这就是 UUID v6 尝试希望解决的问题。
对比程序
为了对可能出现的 UUID 冲突进行演示。我们尝试使用程序来对比可能出现 UUID 冲突的可能性。
这个程序,将会创建 128 个线程,在每个线程中将会生成 100,000 个 UUID。
首先我们对需要使用的变量来进行一些初始化:
int threadCount = 128;
int iterationCount = 100_000;
Map<UUID, Long> uuidMap = new ConcurrentHashMap<>();
AtomicLong collisionCount = new AtomicLong();
long startNanos = System.nanoTime();
CountDownLatch endLatch = new CountDownLatch(threadCount);
如上面的程序所表示的内容,我们定义了 128 个线程,在这 128 个线程中,我们会循环 100,000 次。
同时,我们还初始化了一个 ConcurentHashMap 把我们生成的 UUID 存储到 ConcurentHashMap 中。
同时,我们还会记录出现 UUID 冲突的次数。
为了记录程序的性能,我们对程序开始时间和程序的结束也都进行了存储。在最后我们定义了一个 latch 等待所有线程的执行完成。
当定义完成后变量后,我们就需要启动线程并对线程序进行执行。
for (long i = 0; i < threadCount; i++) {
long threadId = i;
new Thread(() -> {
for (long j = 0; j < iterationCount; j++) {
UUID uuid = Generators.timeBasedGenerator().generate();
Long existingUUID = uuidMap.put(uuid, (threadId * iterationCount) + j);
if(existingUUID != null) {
collisionCount.incrementAndGet();
}
}
endLatch.countDown();
}).start();
}
在 UUID 的创建过程中,我们使用了 fasterxml 包中的 Generators,这个 Generators 使用的是 java.util.UUID 类来创建的。
在创建 UUID v1 的使用,使用 fasterxml 是我们常用的做法。
当 UUID 创建后,我们就把创建好的 UUID 存储到 Map 中,UUID 为 map 的 Key,当我们的 UUID 重复出现冲突的时候,Map 将会提示错误,我们程序就会捕获这个错误,然后把出现错误的计数器 + 1。
endLatch.await();
System.out.println(threadCount * iterationCount + " UUIDs generated, " + collisionCount + " collisions in "
+ TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startNanos) + "ms");
在程序的最后,CountDownLatch 的 await() 方法会等待所有的线程完成。
当所有线程完成后,我们就会把结果打印在计算机屏幕上。
下面就让我们开始对程序进行运行。
12800000 UUIDs generated, 0 collisions in 16913ms
上面出现了程序的运行结果,我们可以看到并没有出现 UUID 冲突的问题。
uuid-creator
Java UUID Creator 小巧并且使用比较广泛的 UUID 生成器。
使用这个生成器能够为你生成各种 UUID,但从使用的情况上来看并不如 java-uuid-generator 使用得更加频繁。
依赖
如希望在项目中使用这个生成器,需要把这个生成器添加到依赖中。
com.github.f4b6a3 uuid-creator 5.3.7 Copy
使用
这个库提供了 3 个基于时间生成的 UUID 方法。
- UuidCreator.getTimeBased() – 遵守 RFC-4122 规范生成基于时间的 UUID
- UuidCreator.getTimeOrdered() – 使用 gregorian epoch 处理的新 UUID 格式
- UuidCreator.getTimeOrderedEpoch() – 使用 Unix epoch proposed 处理的新 UUID 格式
当我们导入包后,可以直接使用下面的方法来进行使用。
System.out.println("UUID Version 1: " + UuidCreator.getTimeBased());
System.out.println("UUID Version 6: " + UuidCreator.getTimeOrdered());
System.out.println("UUID Version 7: " + UuidCreator.getTimeOrderedEpoch());
我们可以看到生成 UUID 为我们通常认识的 UUID 格式。
UUID Version 1: 0da151ed-c82d-11ed-a2f6-6748247d7506
UUID Version 6: 1edc82d0-da0e-654b-9a98-79d770c05a84
UUID Version 7: 01870603-f211-7b9a-a7ea-4a98f5320ff8
冲突校验
我们还可以使用上面提供的生成代码放我我们开始的一部分使用的冲突校验程序中运行。
运行的结果为:
12800000 UUIDs generated, 0 collisions in 2595ms
通过这个库生成的基于时间的 UUID 我们也没有发现有冲突的情况。
Java UUID Generator (JUG)
依赖
Java UUID Generator (JUG) 在很多项目中因为要生成 UUID 而被使用,其中包括了有 生成UUID 的方法和格式化输出等一些内容。
生成的 UUID 是按照 (RFC-4122) 标准来生成的。
使用下面的代码来添加依赖,当前使用的最新版为 5.0.0
<dependency>
<groupId>com.fasterxml.uuid</groupId>
<artifactId>java-uuid-generator</artifactId>
<version>5.0.0</version>
</dependency>
使用
这个库也同时提供了 3 个方法来生成基于时间的 UUID(包括 v1,v6 和 v7)。
我们可以使用下面的方法来进行命令的调用:
System.out.println("UUID Version 1: " + Generators.timeBasedGenerator().generate());
System.out.println("UUID Version 6: " + Generators.timeBasedReorderedGenerator().generate());
System.out.println("UUID Version 7: " + Generators.timeBasedEpochGenerator().generate());
当程序完成运行后,可以从控制台中看到输出:
UUID Version 1: e6e3422c-c82d-11ed-8761-3ff799965458
UUID Version 6: 1edc82de-6e34-622d-8761-dffbc0ff00e8
UUID Version 7: 01870609-81e5-793b-9e4f-011ee370187b
校验
将新的生成程序替换掉我们原有的代码的时候,我们可以对生成进行输出校验。
12800000 UUIDs generated, 0 collisions in 15795ms
从上面的输出来看,针对代码我们并没有发现有 UUID 冲突的问题。
但是针对运行结果,生成 UUID 的时间是不同的,这是因为 JUG 的生成速度通常要慢一点,对于我们 UUID 来说如果不大量一次性生成 UUID,这个通常不会是太大的问题。
在项目中,通常需要选择项目已有的依赖,可能在现有的项目中,使用 java-uuid-generator 库的情况要相对多一点。
结论
在本文中,我们对需要生成基于时间的 UUID 进行了一些探讨。同时基于时间的不同,UUID 有不同的版本。
JDK 自己并没有提供快速的基于时间的 UUID 生成方法。
JDK 中的 UUID.randomUUID() 方法生成的是 UUIDv4 的方法。
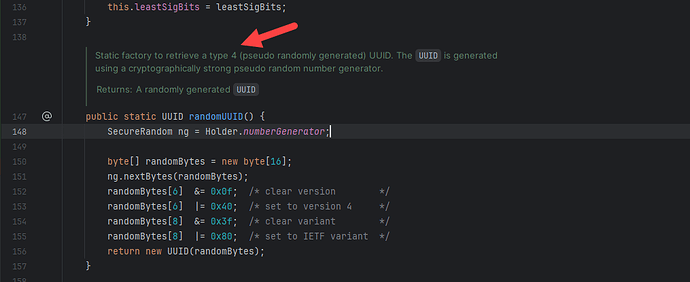
基于时间的 UUID 生成,我们通常会依赖使用第三方的类库。
创建基于时间的 UUID - Java - iSharkFly概述在本文中,我们将会 对 UUIDs 和基于时间的 UUIDs(time-based UUIDs) 进行一些探讨。 当我们在对基于时间的 UUIDs 进行选择的时候,总会遇到一些好的方面和不好的方面,如何进行选择,也是我们将要简要探讨的内容。 同时我们还会对可能会使用类库进行一些比较和探索,以便于我们更好的做出选择。 UUIDs 和 基于时间的 UUIDsUUID 的全称是 Universally Unique Identi…![]() https://www.isharkfly.com/t/uuid/15686
https://www.isharkfly.com/t/uuid/15686