利用Triple U.Net结构对冷冻切片H&E染色组织学图像进行核实例分割
- 摘要
- Introduction
- Related Works
- Dataset
- Proposed Methodology
- Dataset Preparation
- Segmentation Branch
- Loss Function
- Watershed Algorithm
Nuclei Instance Segmentation of Cryosectioned H&E Stained Histological lmagesusing Triple U.Net Architecture
摘要
细胞核实例分割在肿瘤诊断和癌症病理学研究中至关重要。H&E染色图像常用于医学诊断,但在用于图像处理任务之前需要进行预处理。两种主要的预处理方法是福尔马林固定石蜡包埋样本(FFPE)和冷冻组织样本(FS)。
尽管FFPE被广泛使用,但它耗时长,而FS样本可以快速处理。由于快速处理过程可能导致图像质量下降,分析来自快速样本制备、染色和扫描的H&E染色图像可能会遇到困难。
本文提出了一种利用H&E染色图像独特光学特性的方法。实现了一个三分支U-Net架构,每个分支都为最终的分割结果做出贡献。
该过程包括应用分水岭算法以分离重叠区域并提高准确性。三重U-Net架构包括一个RGB分支、一个苏木精分支和一个分割分支。
本研究关注一个名为CryoNuSeg的新颖数据集,这是首个包含10个人体器官30个FS切片图像的FS数据集。通过稳健的实验获得的结果在各项指标上均超过了现有技术水平。
该数据集的基准分数为AJI 52.5和PQ 47.7,这是通过实施U-Net架构实现的。
然而,所提出的三重U-Net架构实现了AJI分数67.41和PQ分数50.56。所提出的架构在AJI上比其他评估指标有更大的改进,这进一步证明了三重U-Net架构优于 Baseline U-Net模型,因为AJI是一个更严格的评估指标,它对错误预测的惩罚比正确预测的奖励要大得多。
在分水岭后处理的辅助下,使用三个分支的U-Net模型,显著超过了基准分数,AJI得分有了实质性的提升。
Introduction
癌症是全球死亡率的主要原因,仅2020年就夺去了近1000万人的生命[1]。及时实施基于证据的预防措施可以预防30至50%的癌症病例。早期癌症检测至关重要,可以提高成功治疗和康复的机会。在手术过程中,准确快速的癌症诊断对于指导即时治疗决策至关重要。
细胞核含有大部分细胞的遗传物质,一直是癌症研究的主要焦点,通常被称为癌症的“以基因为中心”的观点。致癌基因、肿瘤抑制基因的识别以及对多个细胞突变的理解已成为理解癌症启动和进展的标准前提。
在癌症诊断的背景下,从细胞组织图像中分割和提取核区域具有极其重要的意义。这个过程被称为核分割,主要在苏木精和伊红(H&E)染色的图像上进行,这是病理诊断中最广泛使用的染色技术[2]。苏木精染色使细胞核呈现紫色或蓝色,而伊红染色使细胞外基质和细胞质呈现粉红色,导致组织细胞不同部分出现明显的颜色变化。对H&E染色的组织切片进行详细分析,可以提供对每个细胞功能状况的关键洞察,使其成为诊断各种癌症的“黄金标准”[3]。评估用H&E染色的细胞图像依赖于诸如核形态、形状、类型、计数和密度等基本标准。使用数字技术自动化提取这些特征需要分割细胞核。
能够快速从核分割中准确识别肿瘤细胞对于癌症检测至关重要。已经开发了几种图像分割技术用于传统的分割任务。大多数常见方法无法完成医学图像的准确分割,尤其是核分割,因为分割细胞核需要生成具有每个细胞核精确边界的 Mask ,并且应该区分重叠区域。本文提出了三重U-Net架构,用于在CryoNuSeg数据集上执行细胞核的实例分割——这是第一个完全标注的、由FS衍生的冷冻切片和H&E染色的核数据集。所提出的算法使用三重U-Net模型而不是 Baseline U-Net模型。目的是呈现一种最先进的架构,用于高精度的核分割,以实现更精确的快速癌症诊断。
Related Works
在计算机视觉领域,图像分割是一个基本过程,它涉及将图像的像素划分为不同的区域,每个区域都被标记为特定的部分或段。分割过程至关重要,因为它使得可以提取感兴趣的区域,便于对这些区域进行深入分析和理解。随着计算能力的提升,核分割在肿瘤和癌症诊断中已成为一种优越的方法。深度学习的最新进展催生了一些强大的图像分割架构,它们的准确性之高,以至于甚至可以分割细胞核。研究行人已经探索了两种主要的图像分割方法:经典非基于AI的方法和基于AI的方法。
Classical Non-AI Based Approaches
经典非基于AI的方法包括一系列多年来被广泛研究和发展的算法。这些方法包括阈值化[4],直方图规定化[5],区域增长[6],k-means聚类[7],分水岭算法[8],活动轮廓[9],图割[10],条件随机域和马尔可夫随机域[11],以及基于稀疏性[12]的方法。尽管这些技术非常有价值,但它们的准确性有限,并且在多目标检测方面面临挑战。
AI Based Approaches
人工智能方法概述部分的开头。
Convolutional Neural Network
随着图像识别任务的兴起,对适合图像的神经网络的改进需求变得迫切。传统的前馈神经网络在这些任务上无法达到满意的准确度。因此,经过大量研究努力,出现了卷积神经网络(CNN)[13]。正如其名,CNN利用输入数据上的卷积操作。这一操作在保留图像数据中的空间信息、上下文细节和时间关系方面发挥着关键作用。因此,CNN非常适合处理更高维度的数据,尤其是图像。它们能够保留关键的空间和上下文特征,使其成为图像相关应用的理想选择。
研究行人还探索了将CNN与其他算法结合以增强分割任务的方法。一个这样的例子是将CNN与连通组件算法(CC)结合用于扫描电子显微镜(SEM)图像的分割[14]。这种混合方法在准确分割SEM图像方面显示出良好的效果,进一步证明了CNN在医学图像分析中的多样性和潜力。
2.2.2 Fully Convolutional Neural Network
传统的卷积神经网络(CNN)架构采用卷积和池化操作来下采样输入图像并学习一个紧凑的特征图。这主要是为了使整个算法在计算上可行以实现。这种下采样对于计算的可行性至关重要,特别是在简单的图像分类任务中,只需要识别目标的存在,无需精确的定位信息。然而,对于分割任务,需要定位信息来在图像中定位目标,但下采样并不保留定位信息。
为了缓解这个问题,同时使图像分割可行而不使其计算成本过高,提出了一种新的设计架构,称为“全卷积神经网络”[15]。FCN在传统CNN的下采样阶段之后引入了上采样组件,使得在语义分割中可以结合位置信息与上下文细节。已经有许多研究工作使用FCN,产生了令人印象深刻的语义分割结果。例如,[16]和[17]引入了一个图像解析器,使用FCN进行整图解析,通过单次自底向上的方法处理语义和实例分割任务。
2.2.3 U-Net
U-Net [18] 已成为生物医学图像分割中最广泛采用的模型之一,它利用了全卷积神经网络(FCNs)的架构基础。U-Net模型的特点是它的编码器-解码器结构,这有助于高效的特征提取和上采样,以获得精确的分割结果。
U-Net的编码器组件对输入图像进行下采样,类似于传统的CNN架构,生成一个紧凑的特征图。这个紧凑的特征图随后被送入解码器,解码器执行重要的上采样过程,将图像恢复到其原始分辨率。值得注意的是,U-Net在整个下采样过程中使用3x3滤波器和2x2池化层,并且每层都将特征图数量翻倍。
为了实现上采样,U-Net依赖于转置卷积的基本原理,它执行卷积操作的逆过程并扩大特征图。此外,U-Net的独特之处在于将编码器的特征图与解码器的特征图进行 ConCat 。这种 ConCat 策略在训练过程中增强了网络的了解和表示能力,从而提高了分割性能。
U-Net采用的激活函数是校正线性单元(ReLU)[19],这是神经网络架构中广受好评的选择。ReLU在多篇研究论文中证明了其效率,并有助于模型有效地捕捉生物医学图像中的复杂模式和特征。
2.2.4 Double U-Net
[20] 被介绍为U-Net架构的改进版本,它在各种分割任务上提升了性能,特别是在医学领域,比如结肠镜和皮肤镜数据集。它是两个U-Net架构相互堆叠的组合——其中一个使用预训练的VGG-19编码器,另一个U-Net被添加以更有效地捕获更丰富的语义特征。
2.2.5 Triple U-Net
这个网络[21]提出了一种新颖的架构,包含三个U-Net分支,每个分支在从全幻灯片图像(WSI)中分割细胞核的背景下都有不同的目标。特别是,RGB组件致力于以原始形式捕捉分割任务的基本特征。相反,H分支采用了一种对苏木精敏感的特征提取方法,采取了不同的方法,能够精确检测细胞核边缘,并增强网络在图像中区分重叠区域的能力。这种对苏木精敏感的轮廓特征提取对于获得冷冻切片全幻灯片图像的更准确的分割 Mask 特别有益。
所提出架构的一个关键方面是苏木精模块在苏木精和伊红(H&E)染料颜色不一致时的稳定性。因此,作者选择不应用标准化,因为这样做可能会导致不必要的信息丢失。分割分支有效地将RGB分支的原始特征与H分支的苏木精敏感轮廓特征结合起来,以预测最终的分割结果。
作者引入的苏木精感知三重U-Net标志着一个创新和原始的方法,旨在利用H&E染色图像的特定属性。这一开创性的想法源于比尔-兰伯特法则[22]的原则,该法则与物体吸收光的方式有关。所提出的模型在颜色不一致方面的稳定性提高,使得在这种情境下不需要进行颜色标准化。
此外,该架构还包括一个渐进式密集特征聚合模块,促进了特征的有效合并和学习。通过消融研究和在三个数据集上的稳健实验,严格评估了所提出方法的整体有效性,确立了其在全幻灯片图像中分割细胞核的有效性。三重U-Net所展示的令人鼓舞的结果进一步强调了其在各种医学成像应用中作为细胞核分割宝贵工具的潜力。
Dataset
全玻片成像(WSI)是指对包含细胞组织的传统玻璃幻灯片进行数字扫描。这种技术在数字病理学领域在全球范围内被广泛使用。CryoNuSeg [23] 数据集是通过从10个人体不同器官中选择30个WSIs创建的,包括肾上腺、喉、淋巴结、纵隔、胰腺、胸膜、皮肤、睾丸、胸腺和甲状腺。这些WSIs来自癌症基因组图谱[24],并通过包括来自不同扫描中心、不同疾病类型以及两性样本,确保了数据多样性。数据集中的图像放大倍数为40x。使用QuPath [25]提取固定大小的512*512像素的图像块。为了进行核分割,涉及两位受过专门训练的行人:一位是生物学家(称为标注者1),另一位是生物信息学家(称为标注者2)。两位标注者都收到了关于手动标记核实例的精确指导。两位标注者都得到了分割的明确指示。为了减少观察者内变异性,标注者1在三个月后进行了第二轮手动标记。在初步和后续轮次中,标注者1成功识别并分割了7,596和8,044个核。相比之下,标注者2分割了8,251个核。
Proposed Methodology
作者在基础论文[23]中引入了一种基于U-NET的算法,其中发布了数据集。他们使用了一种最近发布的SOTA深度学习实例分割模型作为基准分割模型。下面图1展示了整个基准算法的可视化流程。分割模型由两个子模型组成,这两个模型是独立训练的。一个基于U-Net的模型(分割U-Net)用于执行基本的语义分割,而另一个专注于每个细胞核中心之间距离的U-Net模型用于预测所有细胞核实例的距离图。训练完两个子模型后,将它们的结果合并以形成实例分割 Mask 。他们首先应用高斯平滑滤波器以获得最终的实例分割 Mask 。然后,从平滑的距离图中导出局部最大值,并用作分水岭算法的点。他们使用分割U-Net的结果作为分水岭方法的标签以确定分割 Mask 。
为了在细胞核分割中实现更高的准确度,建议用改进版的U-NET替换基准论文[23]中使用的传统U-NET。所提出的算法涉及使用三重U-NET代替U-NET,并采用分水岭算法进行后处理以执行实例分割。
所提出的架构以细胞组织图像作为输入,输出细胞核和其他细胞部分的分割区域。图2提供了所提出架构的可视化表示。图3提供了在所提出方法中使用三重U-Net模型的可视化表示。本节详细阐述了方法论,包括预处理、数据增强、特征提取、分割、评估指标和比较。
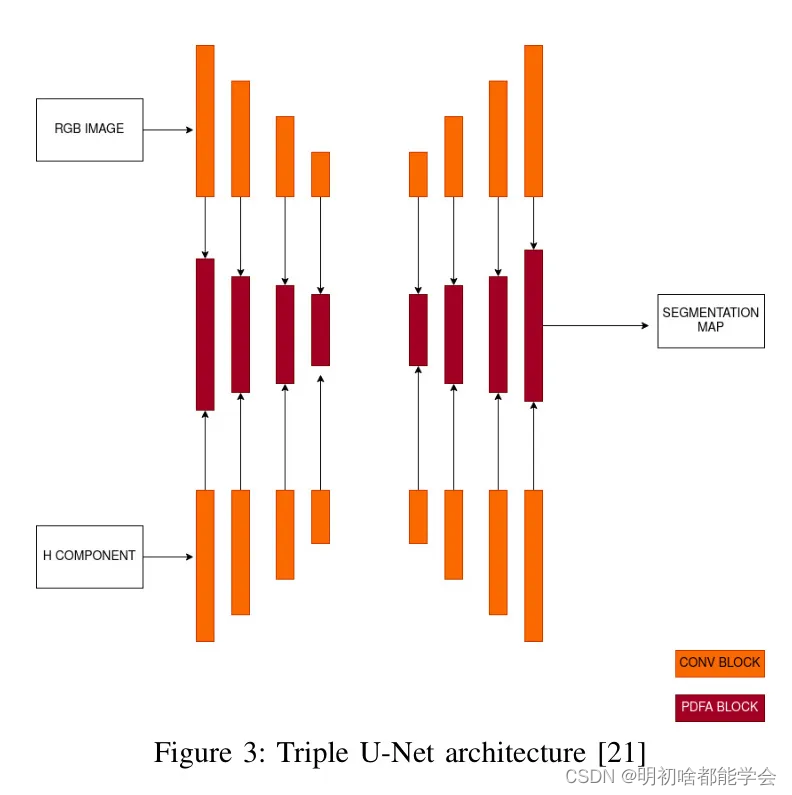
提出了一种基于三重U-Net的模型[26]用于核分割。它基本上是一个具有三个U-Net层的模型——RGB分支、H分支和分割分支。RGB分支用于原始特征提取,而H分支用于轮廓检测任务。分割分支汇总RGB和H分支的结果并预测最终结果。引入了一种称为渐进密集特征聚合(PDFA)的特征融合策略,以实现更好的特征表示融合和学习。
Dataset Preparation
4.1.1 Preprocessing
数据集包括RGB图像及其相应的二值 Mask 。二值 Mask 是细胞核和细胞体的灰度图像。细胞核被染成白色, Mask 的其余部分为黑色。通过使用二值 Mask 生成了细胞核的轮廓图。这是通过对二值 Mask 应用边缘检测并在图像中识别细胞核的边界来完成的。轮廓图仅包含白色的细胞核边界。以这种方式进行预处理,是因为Triple U-Net架构有一个称为H分支的部分,它处理来自轮廓图的边界检测信息。
4.1.2 Data Augmentation
深度学习,特别是在医学成像领域,依赖于大量的训练数据以实现最佳性能并防止过拟合。然而,由于患者隐私关切和特定组织样本的稀缺,医学数据集通常图像数量有限。为了应对这一挑战,人们使用了各种技术来创建同一图像的不同变体,这一过程称为数据增强。通过生成新的和独特的示例来训练数据集,数据增强在提高机器学习模型的性能和成果方面具有优势。
丰富且充足的数据集对提高机器学习模型的性能和准确性至关重要。在医学图像分析领域,通常通过将弹性形变应用于可用的训练图像来过度使用数据增强。这种方法使得网络能够学习对这类形变的不变性,而无需在标注的图像语料库中看到这些转换。这在生物医学分割中尤为重要,因为形变一直是组织和真实形变的一种普遍变化,且可以有效地模拟这种形变。在[27]中,数据增强对于学习不变性的价值已在无监督特征学习的范围内得到证明。使用了不同类型的数据增强,包括随机裁剪、弹性变换、旋转、翻转和平移。每张原始图像被裁剪成16个块并输入到神经网络中。
Feature Extraction
正如在前几节中讨论的,基准算法使用了U-Net模型,而提出的算法使用了三重U-Net模型。这两个模型之间的一个关键区别是特征提取方法。以下各节将讨论三重U-Net模型中存在而在基准U-Net模型中不存在的特征提取方法,以及为什么它能够带来更好的结果。首先,将讨论苏木精提取是如何工作的。
4.2.1 Hematoxylin component extraction
在所提出的方法中,利用了苏木精和伊红的一致性染色特性,其中苏木精将细胞核染成蓝色,伊红将细胞外基质和细胞质染成粉红色。为了从RGB颜色空间提取苏木精(H)成分,应用了一种基于比尔-朗伯定律[22]的颜色分解方法。通过隔离H成分,可以获得更清晰的细胞核视图。因此,这显著提高了H&E染色图像中细胞核与细胞质以及间质之间的对比度。在这篇研究论文中,这一特性被用来辅助分割任务。基本的U-Net网络并没有关注这些特性。
4.2.2 Progressive Dense Feature Aggression (PDFA) Module
在该实现的框架中,已经融合了不同的分支,分别是RGB和H,用于分别执行分割和核轮廓检测任务的特性提取。与通常采用直接拼接来融合新特征的的传统U-Net架构不同,这里实现了一个渐进式密集特征聚合(PDFA)模块,它逐步融合新特征。这种独特的特征融合技术不仅显著减少了参数数量,还增强了特征传播和复用。PDFA模块中的层数根据要融合的特征而变化;在解码阶段使用了四层,在编码阶段使用了三层,因为网络中缺少初始的跳跃特征。这种特征拼接技术非常独特,U-Net模型中并未出现。
4.2.3 RGB branch
RGB分支提取了进行分割任务所需的基础特征。它被称为“RGB分支”,是因为它能够从原始图像的RGB颜色空间中提取原始数据,提供了丰富的对于分割至关重要的语义信息。这个分支的输出通过将它们与分割的真值进行比较,并使用二元交叉熵损失进行监督,这种策略在获取分割所需的精确像素级特征方面已经取得了极大的成功。RGB分支的损失函数如下所示:
图4:PDFA模块[21]
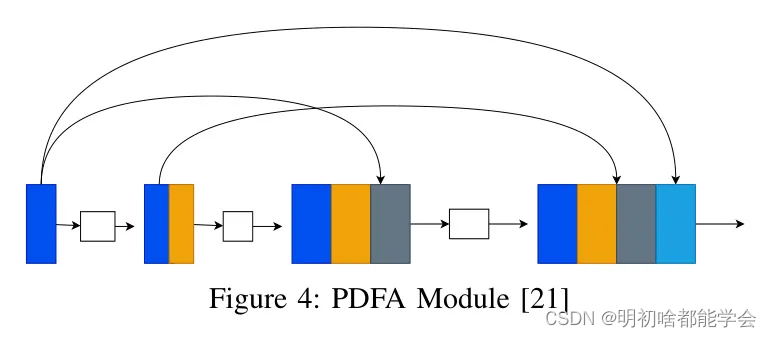
图3:三重U-Net架构[21]
LRGB=—1/N > A 1 ( J i ∗ log a i + ( 1 − g i ) ∗ log ( 1 − a i ) ) >A1(Ji * \log a_i+(1-g_i) * \log(1 -a_i)) >A1(Ji∗logai+(1−gi)∗log(1−ai)) 在这里,表示第i像素的预测概率,J表示相应的真值,N是像素的数量。
4.2.4 H branch
H分支接收染料苏木精(Hematoxylin)成分作为其输入。苏木精成分负责突出显示细胞核的轮廓。这个轮廓信息从苏木精成分中提取出来,然后由H分支用来执行轮廓检测的任务。利用这些轮廓数据,模型能够更深入地了解细胞核复杂的轮廓细节。因此,网络在分割结果的准确性上得到了提升,因为H分支帮助建立了更精确的细胞核边界。这种对轮廓的意识在默认的U-Net中是不存在的。
为了强调对细胞核轮廓信息的学习,采用了软Dice损失函数。损失函数定义如下:
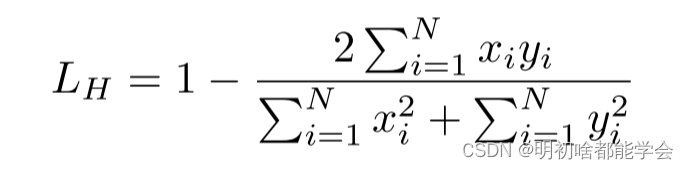
这里, X i X_i Xi表示第i个像素的预测概率, y i y_i yi是基本事实。
Segmentation Branch
分割分支在合并原始属性和苏木精敏感的轮廓特征以产生最终的分割结果方面发挥着关键作用。在这个分支中,采用了一种更复杂的方法来组合特征,称为渐进式密集特征聚合(PDFA),以增强融合过程并促进不同分支间的特征表示学习。PDFA不是简单地将所有特征直接连接起来,而是逐步将先前的特征与后续的特征相结合。
新引入的PDFA模块提供了一种比传统密集连接块更为连贯的特征融合方法。它继承了密集连接块的相关优势,包括促进特征重用、加强特征传播以及显著减少参数数量。
单个PDFA模块中的层数由需要融合的新特征的数量决定。如图4所示,解码阶段的PDFA模块由四层组成,但在编码阶段由三层组成,因为网络的开始部分没有初始的跳跃特征。
分割分支的软Dice损失如下:
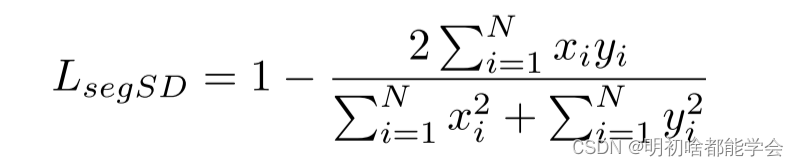
Loss Function
与基准算法不同,每个分支都使用了独立的损失函数。总损失函数是三个分支损失加权的总和:
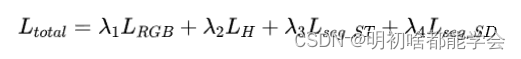
Triple U-Net相较于基本U-Net的主要优势如下:
无需进行颜色归一化
它能够生成具有高精度细胞核边界的分割结果。
引入了PDFA模块,使网络能够逐步从不同领域聚合特征。
Watershed Algorithm
三重U-Net架构从输入图像生成分割图。在这些分割图上使用基于标记的图像分割和水域算法[29]来实现改进的结果。水域算法是一种广泛用于分割的图像处理技术,特别是在区分重叠区域方面尤为重要,这对于精确实例分割是一个关键方面。该算法需要用户定义的标记,这些标记可以使用阈值技术或形态学操作来定义。
分割图可以被认为是一个地形表面,其中高强度区域表示山峰,低强度区域表示山谷。为了在分割 Mask 中分离不同的目标,使得分割图中的不同核更加清晰,算法遵循并模拟了一个用不同颜色的水填充山谷的淹没过程。孤立的低谷中的水最终会上升到开始合并的水平。当这种合并开始发生时,会在山峰顶部建立屏障以防止山峰被淹没。一旦建立屏障,它们将构成目标的边界,在这种情况下,它是核的边界。
为了防止由于分割图中可能存在各种噪声导致的过分割,采用了基于标记的水域算法[30]。在这个过程中,执行了将所有山谷点合并以及不应该合并的山谷点的规定。这是通过对已知目标分配独特标签来完成的,这些标签指示了核确实存在的区域,并赋予不同的颜色值。为背景分配一个单独的颜色,而确定性不确定的区域则用标签0标记。这就是标记创建的方式。然后应用水域算法,它产生了一组标签,每个标签对应于一个不同的目标。然后遍历每个标签,提取目标,即不同的核。这进一步改进了三重U-Net的输出,使分割图更加突出。