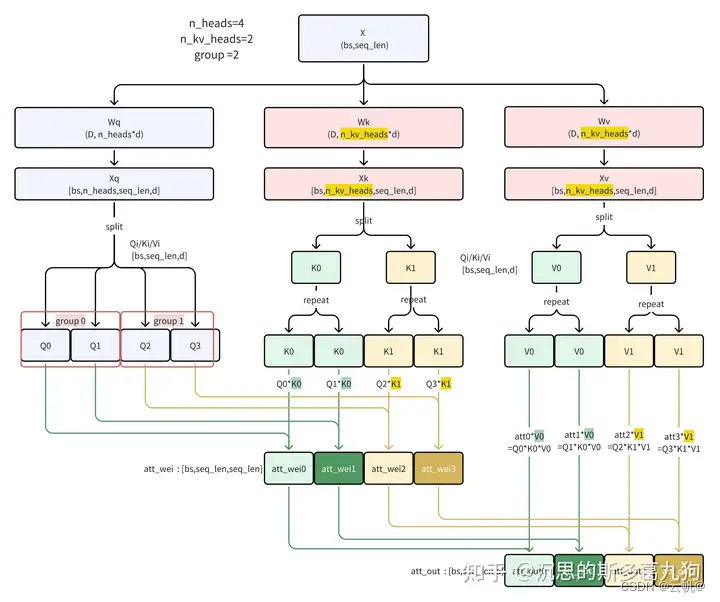
定义 demo 定义 llama3 分组数为4, chatglm2 分组数为2 . import torch
import torch.nn as nn
import math
#GQA
bs=3
seq_len =5
hidden_size= 32
n_heads=4
n_kv_heads = 2
head_dim = hidden_size//n_heads #
groups = n_heads//n_kv_heads # 4/2
print("groups=",groups)
x=torch.randn((bs,seq_len,hidden_size))
print("x:", x.shape)
wq = nn.Linear(hidden_size,n_heads*head_dim,bias=False)
wk = nn.Linear(hidden_size, n_kv_heads * head_dim, bias=False)
wv = nn.Linear(hidden_size, n_kv_heads * head_dim, bias=False)
xq,xk,xv=wq(x),wk(x),wv(x)
xq = xq.view(bs,seq_len, n_heads, head_dim).transpose(1, 2)
xk = xk.view(bs,seq_len, n_kv_heads, head_dim).transpose(1, 2)
xv = xv.view(bs,seq_len, n_kv_heads, head_dim).transpose(1, 2)
print("xq:",xq.shape) #[bs,n_heads,seq_len, head_dim]
print("xk:", xk.shape)#[bs,n_kv_heads,seq_len, head_dim]
print("xv:", xv.shape)#[bs,n_kv_heads,seq_len, head_dim]
def repeat_kv(keys: torch.Tensor, values: torch.Tensor, repeats: int, dim: int):
keys = torch.repeat_interleave(keys, repeats=repeats, dim=dim)
values = torch.repeat_interleave(values, repeats=repeats, dim=dim)
return keys, values
#复制kv head
key,val = repeat_kv(xk,xv, groups,dim=1)
print("key:", key.shape)
print("val:", val.shape)
attn_weights = torch.matmul(xq, key.transpose(2, 3)) / math.sqrt(head_dim)
print("attn_weights:", attn_weights.shape) #[bs,n_heads,seq_len,seq_len]
attn_output = torch.matmul(attn_weights, val)
print("attn_output:", attn_output.shape) # [bs,n_heads,seq_len,head_dim]


![[论文笔记]GAUSSIAN ERROR LINEAR UNITS (GELUS)](https://img-blog.csdnimg.cn/img_convert/28b6e6ca0e2cbdf1bdbbd7cb2fd3e3f5.png)