参考链接:
https://www.jianshu.com/p/805b76c9d229
https://blog.csdn.net/chenhaogu/article/details/132677778
- 基本理论
TensorRT是一个高性能的深度学习推理优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现在已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。目前的TensorRT库支持C ++或者Python API部署。
使用训练框架执行推理很容易,但是与使用TensorRT之类的优化解决方案相比,相同GPU上的性能往往低得多。训练框架倾向于实施强调通用性的通用代码,而当优化它们时,优化往往集中于有效的训练。TensorRT通过结合抽象出特定硬件细节的高级API和优化推理的实现来解决这些问题,以实现高吞吐量,低延迟和低设备内存占用。TensorRT 就是对训练好的模型进行优化,由于TensorRT就只包含推理优化器,优化完的网络不再需要依赖深度学习框架,可以直接通过TensorRT 部署在NVIDIA的各种硬件中。
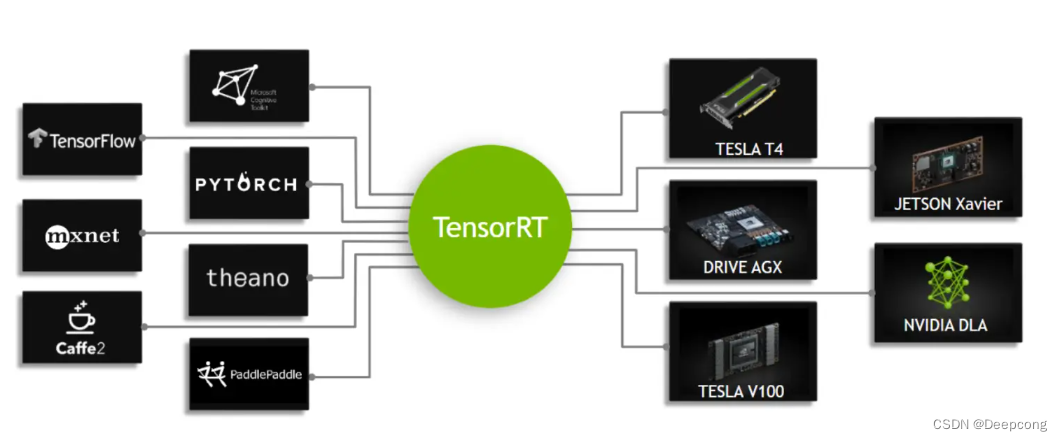
TensorRT的解决方案是:
权重与激活精度校准:通过将模型量化为 FP16或INT8来更大限度地提高吞吐量,同时保持高准确度。 层与张量融合 :通过融合内核中的节点,优化GPU 显存和带宽的使用。 内核自动调整:基于目标 GPU 平台选择最佳数据层和算法。 动态张量显存:更大限度减少显存占用,并高效地为张量重复利用内存。 多流执行:用于并行处理多个输入流的可扩展设计。
通过这些方法,TensorRT能够在不损失精度的情况下显著的提升模型的推理性能。
- TensorRT流程
TensorRT 部署流程主要有以下五步:
- 训练模型
- 导出模型为 ONNX 格式
- 选择精度
- 转化成 TensorRT 模型
- 部署模型
在TensorRT中,对象的生命周期可以概括为以下几个主要阶段:
-
创建对象:在TensorRT中,可以创建多种不同类型的对象,例如IBuilder、INetworkDefinition、ICudaEngine等。这些对象用于构建、定义和优化神经网络模型。
-
构建网络:在创建INetworkDefinition对象后,可以使用TensorRT提供的API来构建神经网络。这包括添加输入和输出层,定义中间层和操作,设置张量的维度和数据类型等。
-
优化网络:在构建网络后,可以通过调用IBuilder对象的方法来优化网络。这些方法包括执行层次融合、内存优化、精度校准等技术,以减少推理时间和内存占用。
-
构建引擎:在优化网络后,可以使用IBuilder对象的buildCudaEngine方法来构建ICudaEngine对象。这是TensorRT运行时使用的引擎对象,它包含了优化后的网络和执行推理所需的GPU代码。
-
序列化引擎:构建引擎后,可以将ICudaEngine对象序列化为一个文件,以便以后加载和重用。这可以通过调用ICudaEngine对象的serialize方法来完成。
-
加载引擎:当需要执行推理时,可以通过反序列化引擎文件来加载ICudaEngine对象。这将创建一个可以执行推理的运行时环境。
-
执行推理:一旦引擎加载完成,可以使用ICudaEngine对象的方法将输入数据提供给模型,并获取输出结果。推理过程在TensorRT的运行时环境中进行,利用GPU的并行计算能力来加速推理速度。
-
释放资源:在完成推理任务或不再需要TensorRT对象时,应该显式地释放和销毁TensorRT对象。这可以通过调用相应对象的析构函数或销毁方法来完成。
#include <iostream>
#include <NvInfer.h>
#include <NvOnnxParser.h>
int main() {
// 创建TensorRT的Builder对象
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
// 创建TensorRT的网络定义对象
nvinfer1::INetworkDefinition* network = builder->createNetwork();
// 构建网络结构,例如添加输入和输出层、定义操作等
nvinfer1::ITensor* input = network->addInput("input", nvinfer1::DataType::kFLOAT, nvinfer1::Dims{1, 3, 224, 224});
// 添加中间层和操作
// 优化网络,执行层次融合、内存优化等
builder->setMaxWorkspaceSize(1 << 20); // 设置工作空间大小
builder->setFp16Mode(true); // 启用FP16精度
// 构建Cuda引擎
nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);
// 序列化引擎以保存到文件
nvinfer1::IHostMemory* serializedEngine = engine->serialize();
std::ofstream engineFile("model.engine", std::ios::binary);
engineFile.write((const char*)serializedEngine->data(), serializedEngine->size());
engineFile.close();
// 释放资源
engine->destroy();
network->destroy();
builder->destroy();
return 0;
}