关于注意力机制要解决2个问题,一是怎么做在哪个层面上做,二是注意力系数如何得到,由谁产出。注意力机制应用广泛的本质原因是求和的普遍存在,只要是有求和的地方加权和就有用武之地。DIN/DIEN把注意力机制用在用户行为序列建模是为了得到更好的用户特征表示,注意力机制还可以出现在其他很多环节起到各种作用。
在推荐模型用到的各种特征里,用户特征大于物料特征,行为特征大于画像特征。
从做法上引入注意力机制方法可以分为如下几种:
- 加权和:这是最简单最常见的,只要原先结构中存在向量求和都可以变为加权和,比如AFM
- 按元素/特征/模块乘:虽然把注意力系数乘上去了,但不做求和这种做法可以认为体现了重要性的差异,比如LHUC、SeNet的思路
- 以QKV形式做特征抽象表达,特指Transformer里的做法
- target attention:Q从target item中取,KV从行为序列中抽取,参考Din,只刻画了target item与候选物品的交叉,忽略了行为序列内部各元素之间的依赖关系
- self attention:从行为序列中抽取QKV,从行为序列中提取用户兴趣向量,表征用户交互历史的迁移和相关性
- 双层attention建模序列关系:先self attention,后target attention,从行为序列中提取出来的用户兴趣向量,既能反映候选物料与历史记忆之间的相关性,又能反映不同历史记忆之间的依赖性。

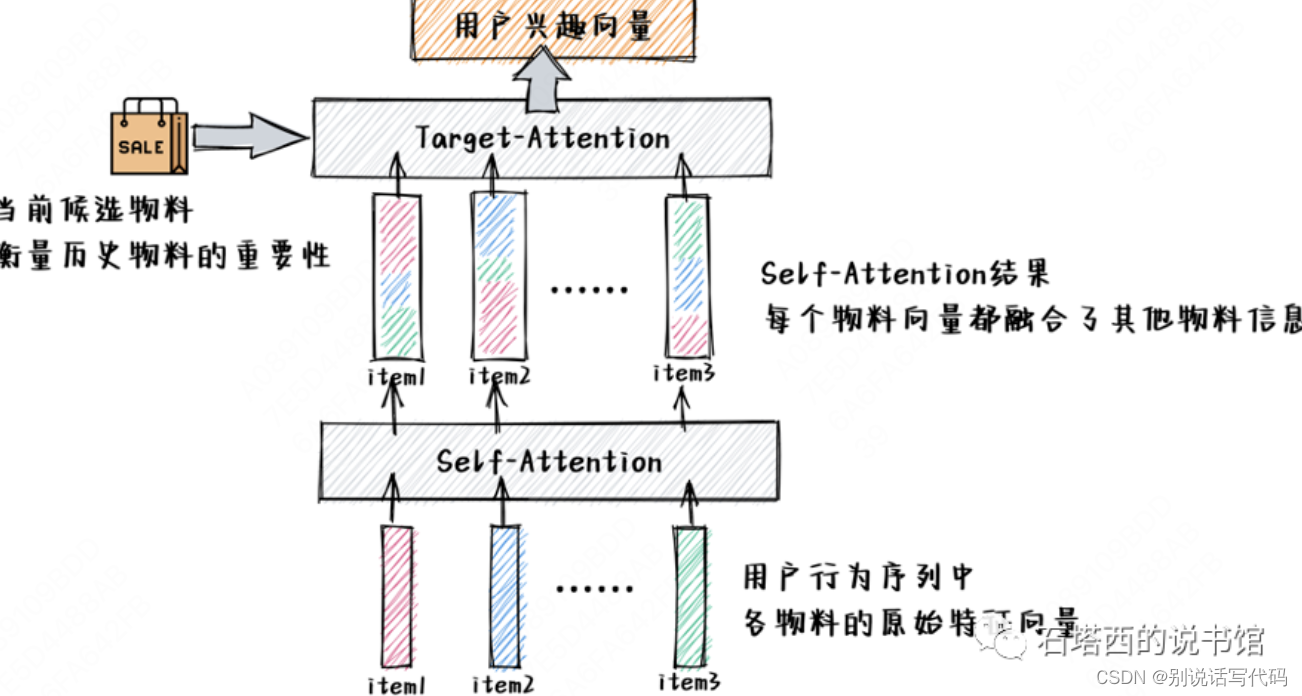
从作用上就丰富多彩了,总结如下几种:
- 凸显用户兴趣峰,比如DIN、DIEN
- 特征进一步细化/抽象的工具,比如SeNet、AutoInt
- 对模块进行分化(作为分化模块的工具),注意力机制下常见操作是根据输入不同生成不同的权重,来决定后面模块中突出的是谁,抑制的是谁。反过来说只要注意力系数的分布是一成不变的,后续模块也会对输入陈升特殊的倾向。某种输入产生了大注意力系数那对应位置模块相当于更多承担了这种输入预测,比如MMOE

![[嵌入式系统-53]:嵌入式系统集成开发环境大全](https://img-blog.csdnimg.cn/direct/bacd86ae5fc147faa9cc17f0eb48fc70.png)