1. 数据集
1.1 生成数据集
要训练模型首先要准备训练数据集,对于线性模型 y=Xw+b,定义生成数据集的函数如下:
def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
# 从均值为0,标准差为1的正态分布中随机采样
# 第3个参数表示张量的形状,num_examples行,len(w)列
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b # 矩阵乘法
y += torch.normal(0, 0.01, y.shape) # 添加噪声,从均值为0标准差为0.01的正态分布中随机采样
return X, y.reshape((-1, 1)) # 将y的形状变换为列向量
torch.normal:从正态分布中随机采样。标准正态分布是对称的,虽然值的分布理论上是正负无穷大,但遵循概率分布。
对于均值为0,标准差为1的正态分布,大约有68%的数据落在均值0附近的一个标准差范围内(-1, 1),约95%的数据落在两个标准差范围内(-2, 2),约99.7%的数据落在三个标准差范围内(-3, 3)。
添加噪声目的:更好地模拟现实世界中的数据。由于测量误差、不完全的观测或其他随机因素的存在,许多现实世界的数据往往是包含噪声的。
这里人为构造包含1000个样本的数据,使用指定参数w=[2,-3.4]和指定偏移b=4.2来生成数据及标签。每个样本数据包含两个特征(与参数w向量长度相同)。
true_w = torch.tensor([2, -3.4]) # 指定参数
true_b = 4.2 # 指定偏差
features, labels = synthetic_data(true_w, true_b, 1000)
生成的数据集示例:
print('features:', features[:3],'\nlabel:', labels[:3])
> features: tensor([[ 0.9426, 0.4816],
[ 3.7041, -0.3572],
[ 0.2075, 0.5264]])
label: tensor([[ 4.4473],
[12.8080],
[ 2.8209]])
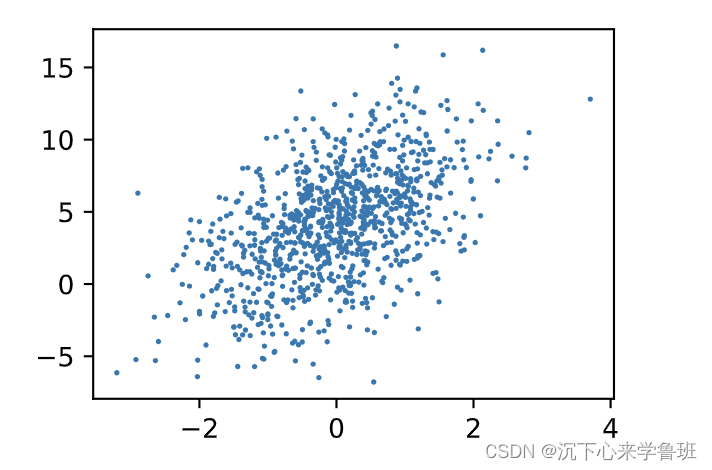
可以使用matplotlib的散点图来查看标签与特征之间的线性关系。
- plt.scatter 函数用于绘制散点图,3个参数分别为特征、标签、点的大小。
- 下面绘制标签与第一个特征的线性关系,横坐标表示特征0,纵坐标表示标签:
d2l.plt.scatter(features[:, 0].numpy(), labels.numpy(), 1);
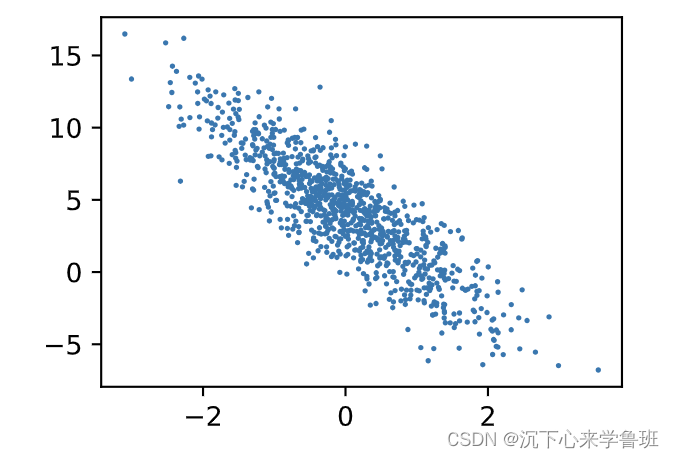
- 下面绘制标签与第2个特征的线性关系,横坐标表示特征1,纵坐标表示标签
d2l.plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
1.2 读取数据集
前文讲过,训练模型采用的是小批量随机梯度下降,通过对小批量样本计算梯度来更新我们的模型,所以我们要定义一个读取小批量数据的函数。
这里定义一个data_iter函数
- 该函数接收三个参数:批量大小、特征矩阵和标签向量。
- 采用python中的yield生成器语法支持多次调用,每次调用返回大小为batch_size的小批量特征和标签。
- random.shuffle: 通过将序列打乱,而达到随机读取样本的目的,小批量读出的数据没有特定的顺序。
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples)) # 构造一个从0开始的序列
random.shuffle(indices) # 将序列的顺序打乱
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
这里以batch_size=5示例下小批量样本读取:
batch_size = 5
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
tensor([[ 0.4795, -0.1943],
[ 1.1495, 0.6922],
[-1.1642, -1.7341],
[ 0.1394, 0.5820],
[ 0.9647, -0.7035]])
tensor([[5.8164],
[4.1540],
[7.7648],
[2.4904],
[8.5224]])
2. 模型
2.1 定义模型
本质:将模型的输入特征、参数权重和模型的输出关联起来。
在我们这个场景下,模型的输出 = 输入特征X和模型权重w的矩阵向量积,再加上偏置。
def linreg(X, w, b): #@save
"""线性回归模型"""
return torch.matmul(X, w) + b
上面的Xw是一个向量,而b是一个标量, 两者进行加法运算时,遵循广播机制,标量b会被加到向量Xw的每个分量上。
2.2 定义损失函数
计算梯度需要先定义损失函数,这里使用上一篇文章中提到的平方误差函数,y表示真实值,y_hat表示预测值。
def squared_loss(y_hat, y): #@save
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
2.3 定义优化算法
定义一个函数来实现参数优化,主要在于用计算好的梯度来更新参数,函数接受3个参数:
- params:一个包含需要被更新的参数张量列表。
- lr:学习率,用于控制参数更新的速度,即每一步更新的大小。
- batch_size:批量大小,用于计算参数的梯度和更新。
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params: # 遍历需要更新的参数
# 将参数的梯度grad乘以学习率lr,再除以批量大小 batch_size,得到参数的更新量
# 将参数的值减去更新量,实现对参数的原地更新
param -= lr * param.grad / batch_size
# 每次参数更新完毕后,梯度要清零,以免影响下次计算
param.grad.zero_()
with torch.no_grad(): 这个语句块内的计算将不会被计算图追踪。原因在于:
- 避免把对参数的更新操作记录为计算图的一部分,对梯度计算造成影响。
- 避免无用数据的保存,减少内存消耗。
3. 训练
上面已经准备好了模型训练需要的要素,下面实现训练部分。
3.1 定义模型超参
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
- num_epochs表示迭代周期次数,也就是训练多少次后终止。
- lr表示学习率,学习率设的太大会震荡,太小则可能收敛慢。
- net:网络模型,用于预测结果,使用上面定义的线性回归模型。
- loss:损失函数,用于计算梯度。
3.2 初始化参数
采用小批量随机梯度下降优化我们的模型参数之前, 先定义参数的初始值。
这里从均值为0、标准差为1.0的正态分布中采样随机数来初始化权重, 并将偏置初始化为0。
w = torch.normal(0, 1.0, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
w, b
> (tensor([[-1.1961],
[-0.3512]], requires_grad=True),
tensor([0.], requires_grad=True))
requires_grad=True 表示对张量的梯度进行跟踪和计算,打开此设置项就能够在训练过程中对张量所表示的参数进行多轮迭代优化。
3.3 运行训练
# 迭代训练次数
for epoch in range(num_epochs):
# 每次对小批量数据集作迭代
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # net做预测,loss计算损失
l.sum().backward() # 使用反向累积计算梯度
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad(): # 开始一个没有梯度跟踪的上下文环境
# 计算当前训练的参数w、b在验证集上的损失
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
运行结果:
epoch 1, loss 0.000208
epoch 2, loss 0.000051
epoch 3, loss 0.000051
对比真实参数与学习得到的参数:
print("true_w: ", true_w, ", w:", w.reshape(true_w.shape))
print("true_b: ", true_b, ", b:", b)
> true_w: tensor([ 2.0000, -3.4000]) , w: tensor([ 2.0004, -3.4002], grad_fn=<ViewBackward0>)
true_b: 4.2 , b: tensor([4.1995], requires_grad=True)
结论: 可以看到,真实参数和通过训练学到的参数确实非常接近。
3.4 不同学习率的表现
学习率lr设为1时的表现:
epoch 1, loss 0.000057
epoch 2, loss 0.000193
epoch 3, loss 0.000090
可以看到,损失函数并未收敛,结果出现了从小到大再到小的震荡。
学习率lr设为0.01时的表现:
epoch 1, loss 0.440745
epoch 2, loss 0.009315
epoch 3, loss 0.000247
可以看到,结果收敛的比0.03时要慢。
可见,学习率的设置是比较棘手的,需要反复试验进行调整。