在某些网站 ,当我们滑下去的时候才会显示出后面的内容
就像淘宝一样,滑下去才逐渐显示其他商品
这个就是采用 Ajax 做的
然后我们现在就是要编写这样的爬虫。
规律分析:
这个时候就要用到我们的 Fiddler 了
我们需要分析加载评论的规律
首先使用火狐浏览器随便打开一个视频,注意设置好代理
然后打开 Fiddler 抓包 ,然后再点击查看更多评论,
拿魔道祖师演示吧,毕竟我也喜欢看
就是这个位置
然后查看 Fiddler
抓到的东西就很多杂七杂八的了,
有链接啊,图片什么的,这些显然不是评论
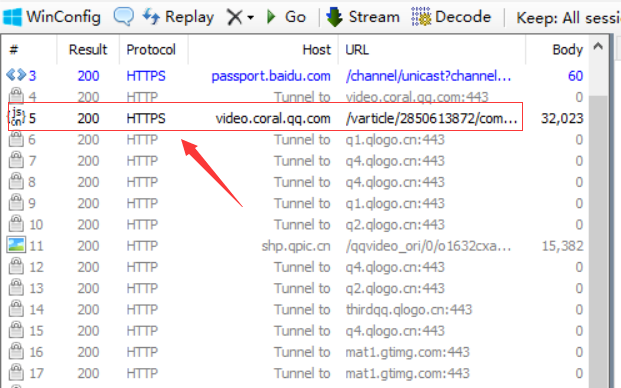
然后查看一个 js 文件 ,发现这就是我们想要的评论
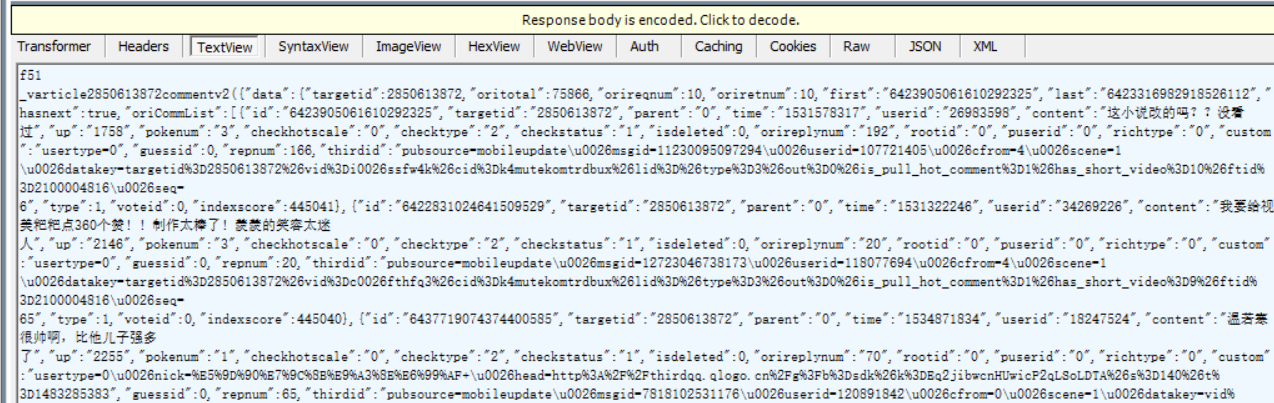
然后把评论的 url 复制出来分析规律
右键点击 js 链接,然后再选择 Copy –> Just Url
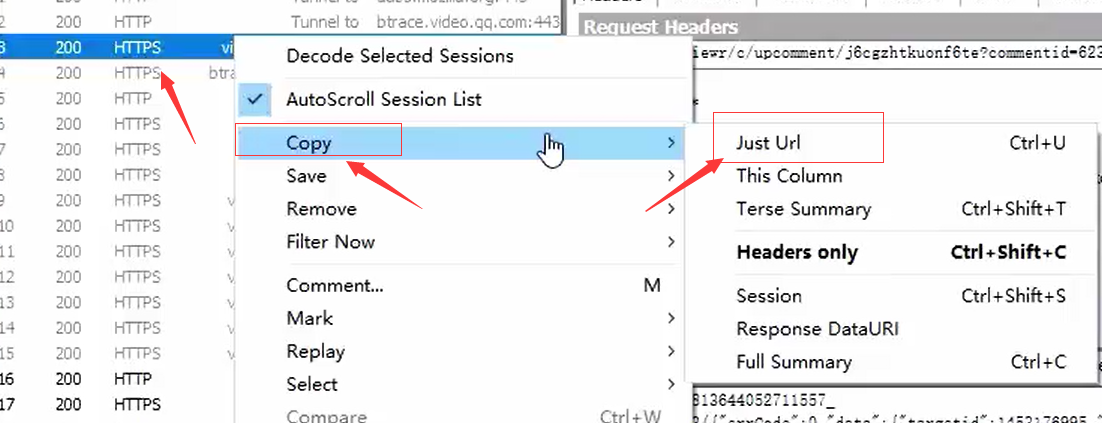
如果一条分析不了,那么我们就多加载一两条看看
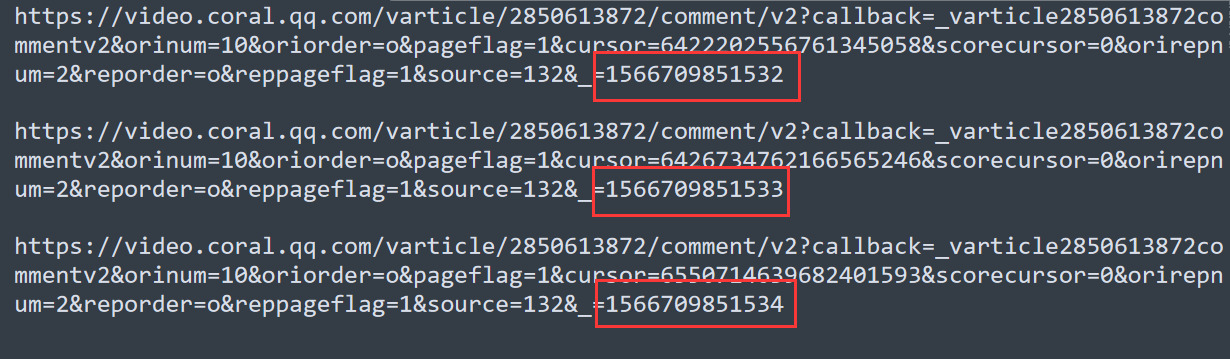
这样我们就有了三条做分析了
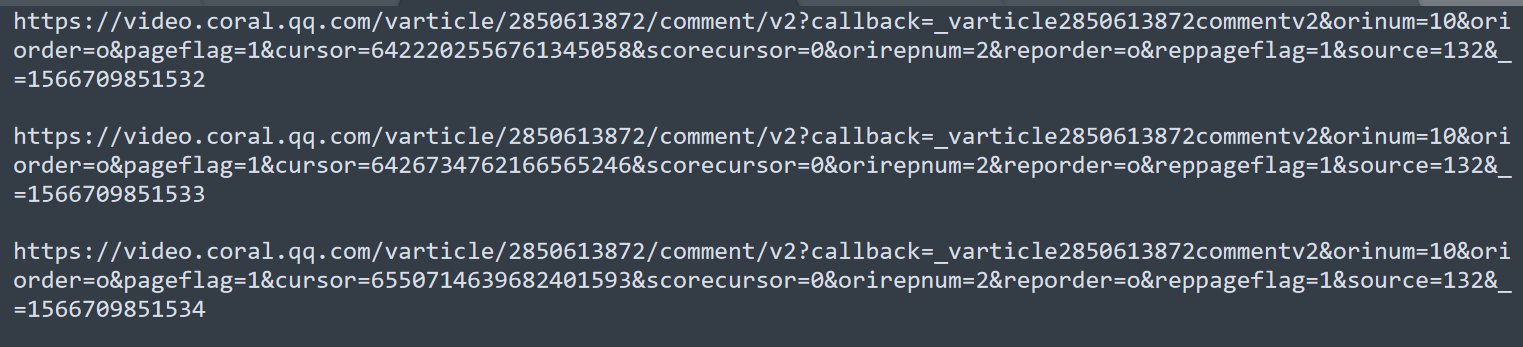
首先看这个地方,
这个应该是这部视频的 id 2850613872

接下来是评论 id
但是貌似 id 都不一样,我可以打开评论链接看看有没有规律
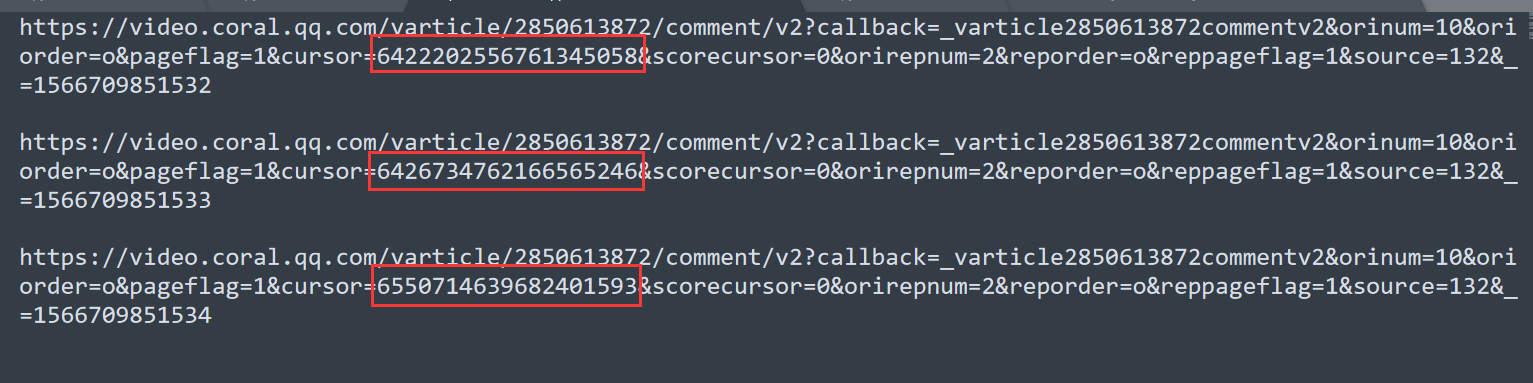
打开第一个评论链接,
然后发现第一个评论链接里的 last 6426734762166565246 正好是第二条评论链接里面的 id
然后查看其他的,发现依旧如此
然后我们就得到了一个结论,
就是第一条评论链接里面的 last id 等于 第二条评论链接里面的 id
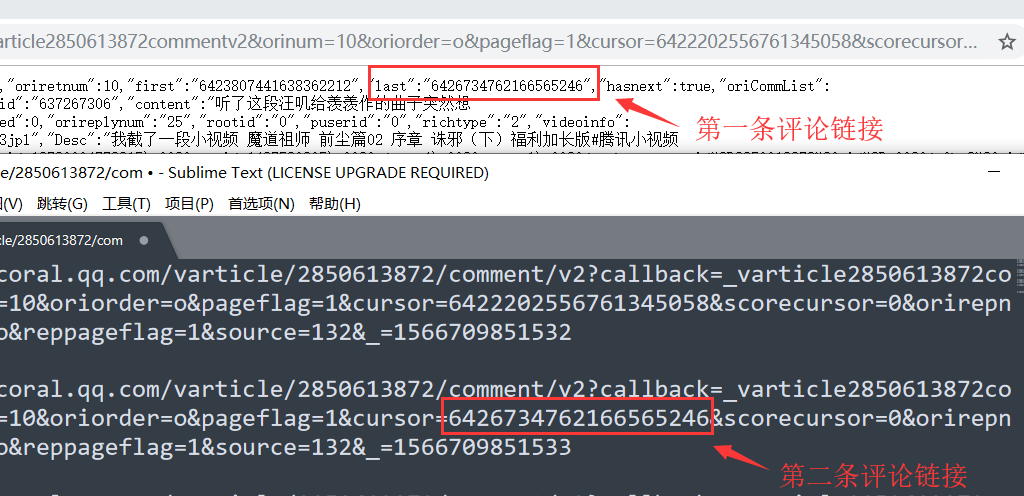
发现评论 id 的规律后,
接下来就是评论了
评论内容在 content 里面
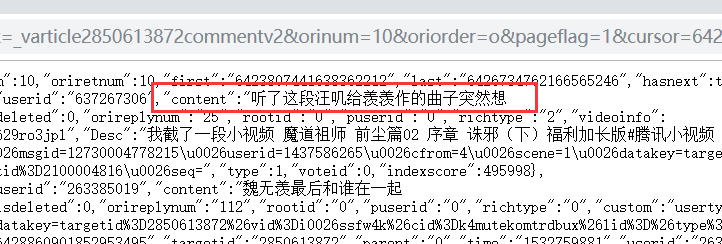
后面这个字符串的话
前十位是时间戳,后面三位没有发现有啥规律
太菜了我
推测可能是评论数
不过有没有这个字符串短时间内不影响我们获取评论内容
这个感觉就是一个时间限制,在一定时间内有效
只抓取一页的评论:
知道规律后
可以试试抓取评论内容
接下来我们尝试只抓取一个链接里面的内容
代码:
import urllib.request import re import time headers = ( "User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36" ) opener = urllib.request.build_opener() opener.addheaders = [headers] urllib.request.install_opener(opener) video_id = "2850613872" comment_id = "6422202556761345058" url = "https://video.coral.qq.com/varticle/"+video_id+"/comment/v2?callback=_varticle2850613872commentv2&orinum=10&oriorder=o&pageflag=1&cursor="+comment_id+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1566709851532" path = '"content":"(.*?)",' data = urllib.request.urlopen(url).read().decode("utf-8") resut = re.compile(path).findall(data) print(resut)
然后就获取到了一页的评论 😂😂 ❤❤ 🙃🙃 (눈_눈)(눈_눈)
😡😡 😊😊 😄😄 🤣🤣 😒😒 🤬🤬 😘😘

自动抓取全部评论:
接下来就要抓取全部评论了
思路:
获取 last id 作为下一次链接的评论 id
代码:
import urllib.request import re import time try: headers = ( "User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36" ) opener = urllib.request.build_opener() opener.addheaders = [headers] urllib.request.install_opener(opener) video_id = "2850613872" # 视频 id comment_id = "6422202556761345058" # 初始评论 id for i in range(1,6): print("第"+str(i)+"页") url = "https://video.coral.qq.com/varticle/"+video_id+"/comment/v2?callback=_varticle2850613872commentv2&orinum=10&oriorder=o&pageflag=1&cursor="+str(comment_id)+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1566709851532" content_path = '"content":"(.*?)",' # 评论内容正则 last_path = '"last":"(.*?)",' # last id 正则 content_data = urllib.request.urlopen(url).read().decode("utf-8") content = re.compile(content_path).findall(content_data) # 获取评论 last_id = re.compile(last_path).findall(content_data) # 获取 last id for j in last_id: # 获取的 last id 是列表类型,要进行类型转换 comment_id = j # print(comment_id) print(content) # 输出获取的评论 except Exception as error: print(error)
然后成功获取到评论
运行截图


![微信小程序[黑马笔记]](https://img-blog.csdnimg.cn/direct/9bffbb8c50b34f4bbe8e70db8ff5fa5a.png#pic_center)