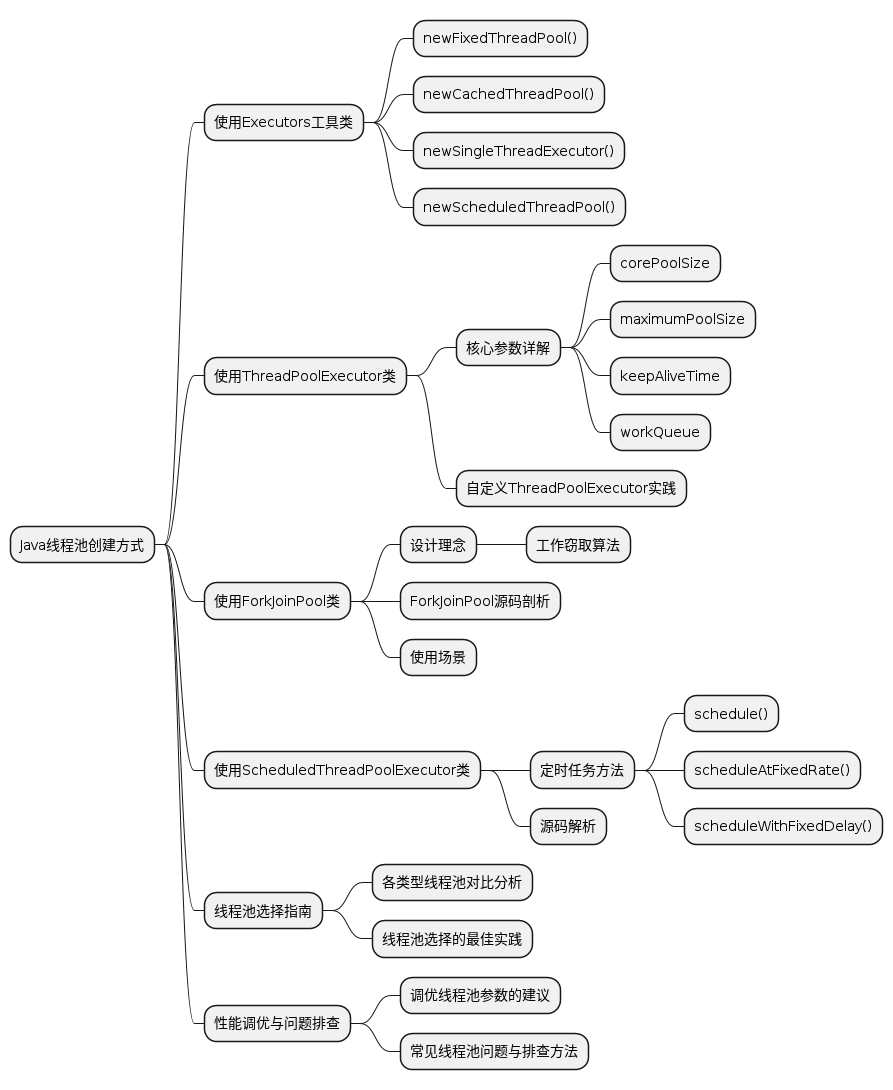
使用Executors工具类创建线程池
Executors的主要方法与默认配置
Executors 工具类是 Java 中创建线程池的标准方法之一,它提供了许多静态方法来创建不同类型的线程池。以下是一些常用的 Executors 方法及其作用:
- newFixedThreadPool(int nThreads): 创建一个可重用固定线程数的线程池。
- newCachedThreadPool(): 创建一个根据需要创建新线程的线程池,但会在之前构建的线程可用时重用它们。
- newSingleThreadExecutor(): 创建一个使用单个 worker 线程的 Executor,确保按顺序执行任务。
- newScheduledThreadPool(int corePoolSize): 创建一个线程池,它可以安排在给定延迟后运行命令,或定期执行命令。
默认配置 解释:
- newFixedThreadPool 与 newSingleThreadExecutor 在默认设置下,都使用无界的工作队列,这意味着如果所有线程都在忙,新任务将在队列中等待无限长的时间。
- newCachedThreadPool 可以无限制地创建线程,这可能会创建过多的线程,消耗过多的系统资源。
- newScheduledThreadPool 建议只用于执行延时或定期任务。
分析Executors源码透视线程池创建过程
让我们深入分析 newFixedThreadPool 方法的源码,了解具体的创建过程:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
该方法调用了 ThreadPoolExecutor 的构造函数,设定了核心线程数 (corePoolSize) 和最大线程数 (maximumPoolSize) 都为用户指定的 nThreads。它使用一个无界的 LinkedBlockingQueue 作为工作队列,这意味着除非线程池关闭,否则线程池中的线程永远不会因为空闲而被回收。
从源码中我们可以看到,虽然 Executors 提供了便捷的创建线程池的方法,但默认的配置并不适合所有场景。特别是在任务频繁提交的情况下,无界队列可能会导致内存溢出。同时,0L 作为 keepAliveTime 参数的值,表示非核心线程不会因为空闲而被终止。
使用ThreadPoolExecutor类创建线程池
ThreadPoolExecutor构造函数解析
ThreadPoolExecutor 是线程池的核心实现类,它提供了创建一个多功能线程池的方式。构造函数中包含几个关键的参数,了解这些参数对于正确使用线程池至关重要:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize: 核心线程数 —— 即使它们是空闲的,也会始终存在于线程池中。
- maximumPoolSize: 最大线程数 —— 线程池可支持的最大线程数量。
- keepAliveTime 和 unit: 非核心线程的空闲存活时间,一旦超过这个时间非核心线程将被终止。
- workQueue: 用于在执行任务之前保存任务的队列,这是一个阻塞队列。
- threadFactory: 执行程序创建新线程时使用的工厂。
- handler: 当任务太多来不及处理,或线程池关闭时,用于处理被拒绝的任务。
自定义ThreadPoolExecutor实践
为了展示如何自定义 ThreadPoolExecutor,以下是一个简单的示例:
ThreadPoolExecutor executor = new ThreadPoolExecutor(
4, // corePoolSize
10, // maximumPoolSize
60L, // keepAliveTime
TimeUnit.SECONDS, // unit
new LinkedBlockingQueue<>(100), // workQueue
Executors.defaultThreadFactory(), // threadFactory
new ThreadPoolExecutor.AbortPolicy() // handler
);
在这个例子中,我们创建了一个核心线程数为4,最大线程数为10,并且非核心线程的存活时间为60秒的线程池。工作队列是容量为100的 LinkedBlockingQueue。当队列满时,执行策略是 AbortPolicy,即抛出 RejectedExecutionException 异常。
源码视角分析ThreadPoolExecutor工作原理
ThreadPoolExecutor 的核心工作原理涉及几个重要的步骤:
- 新任务提交到线程池时,首先会检查核心线程是否全部运行,如果没有,会尝试创建一个新的核心线程。
- 如果核心线程已满,新任务会被加入工作队列。
- 如果工作队列已满,会尝试创建新的非核心线程。
- 如果非核心线程数已达到最大值,任务会根据拒绝策略进行处理。
整个过程是由多个组件协调完成,确保线程池的高效和稳定运行。
使用ForkJoinPool类创建线程池
ForkJoinPool的设计理念
ForkJoinPool 是专门为了优化处理递归和分治算法任务而设计的一个线程池类。不像 ThreadPoolExecutor 使用一个共享队列,ForkJoinPool 为每个工作线程提供了一个双端队列(deque),用以存储任务。这种设计可以减少线程间竞争,提高效率。
它的关键特性包括工作窃取(work-stealing)算法,工作线程可以从其他线程的队列中窃取任务来执行。这能更好地利用CPU,提高并行度。
ForkJoinPool源码剖析与使用场景
让我们来看一段使用 ForkJoinPool 的代码示例:
ForkJoinPool pool = new ForkJoinPool();
pool.execute(() -> {
// 分解及执行并发任务
});
// 通常使用递归任务 - RecursiveAction 或 RecursiveTask
ForkJoinPool 最典型的使用场景是分解复杂任务为更小的任务,然后并行执行。它通常结合 RecursiveAction(没有返回值的任务)或 RecursiveTask(有返回值的任务)来使用;这两个类提供了 fork() 和 join() 方法,帮助我们实现任务的分解和结果的合并。
基于源码的角度,ForkJoinPool 实现了 ForkJoinWorkerThread,每个线程包含有一个任务队列。当线程中的任务执行完毕后,它会尝试从其他线程的队列窃取任务,保持高效率的执行。
下面是 ForkJoinPool 的构建方式:
ForkJoinPool fjp = new ForkJoinPool(
Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, //异常处理
false //asyncMode
);
在上面的例子中,我们创建了一个与可用处理器一样多的线程数量的 ForkJoinPool。通过设置 asyncMode 为 false,我们确保了使用 LIFO(后进先出)顺序处理任务,这对于大部分计算密集型任务来说效率更高。
使用ScheduledThreadPoolExecutor类创建线程池
ScheduledThreadPoolExecutor用法简介
ScheduledThreadPoolExecutor 是 ThreadPoolExecutor 的一个扩展,用于在给定的延迟之后执行命令,或者定期地执行命令。此类是设计为执行线程池中任务的定时或周期性调度。
下面是一些常用的方法:
- schedule(Runnable command, long delay, TimeUnit unit): 在指定的延迟后执行任务。
- scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit): 在指定的延迟之后开始,定期地执行任务。
- scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit): 在指定的延迟之后开始,以固定的延迟执行任务。
深入ScheduledThreadPoolExecutor源码
ScheduledThreadPoolExecutor 使用了一个优先级队列 DelayedWorkQueue 来对任务进行排序,确保即将执行的任务位于队列的头部。以下是 ScheduledThreadPoolExecutor 延时执行任务的一个简单实例:
ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(1);
executor.schedule(() -> System.out.println("Task executed after 3 seconds"), 3, TimeUnit.SECONDS);
在这个例子中,我们创建了一个单线程的 ScheduledThreadPoolExecutor 实例,并提交了一个在三秒后执行的任务。
源码视角的讲解将涉及 ScheduledThreadPoolExecutor 是如何管理和执行这些安排好的任务。例如,当调用 schedule 方法时,任务将被封装为一个 ScheduledFutureTask 对象并插入到 DelayedWorkQueue 中。
定时任务与延迟执行策略
在 ScheduledThreadPoolExecutor 中,定时任务和延迟执行策略对应于两种核心方法:scheduleAtFixedRate 和 scheduleWithFixedDelay。scheduleAtFixedRate 用于执行固定频率的重复任务,即无论任务执行多长时间都尝试保持固定的时间间隔。而 scheduleWithFixedDelay 确保两次执行之间有固定的延迟,不管任务执行花费了多少时间。
线程池的选择指南
在面对不同的应用场景时,选择合适的线程池至关重要。具体选择哪种线程池,通常需要基于任务的性质以及应用的需求。
各类型线程池对比分析
- FixedThreadPool: 适用于需要限制当前运行线程数量的场景,适用于资源消耗比较均匀时的任务。
- CachedThreadPool: 适用于有许多短期异步任务的程序,能更快地响应外界的请求。
- SingleThreadExecutor: 适用于需要保证执行顺序的任务,可以依次按照任务的提交顺序执行。
- ScheduledThreadPool: 适用于需要周期性执行任务的场景,比如计划任务、定时任务。
- ForkJoinPool: 特别适用于需要大量使用分治策略和并行计算的场景,可以充分利用多核处理器的计算能力。
线程池选择的最佳实践
最佳实践建议您考虑以下因素:
- 任务的类别(CPU 密集型、IO 密集型、混合型)
- 任务的优先级(是否需要快速响应)
- 任务的执行时间(长期还是短期)
- 资源的限制(如内存和处理器)
为了更有效率地使用线程池,通常建议自定义 ThreadPoolExecutor,这让你有机会根据自己的实际需求来调优线程池的参数。
性能调优与问题排查
调优线程池参数的建议
调整线程池大小最直接的规则是考虑到可用硬件资源和预计的任务负荷:
- 对于CPU密集型任务,理想的线程数量大约是CPU可用核心的数量。
- 对于IO密集型任务,则可以配置更多的线程,因为IO操作不会占用太多CPU。
另外,合适的工作队列大小和合理的拒绝策略也很关键,这可以为系统过载提供缓冲,避免资源耗尽。
常见线程池问题与排查方法
- 线程池过大:可能会导致系统资源不足,解决办法是减小 maximumPoolSize。
- 线程池过小:可能会导致任务排队等候,影响性能,解决办法是根据任务类型增大线程池大小。
- 任务执行时间过长:可以考虑对任务进行分解,以减少单个任务对线程池的占用时间。
- 内存泄漏:可能是由于长生命周期的对象被线程池引用导致的,需要使用JVM工具检测和排查。