如今,当我们谈论深度学习时,通常会将其实现与利用 GPU 来提高性能联系起来。
GPU(图形处理单元)最初设计用于加速图像、2D 和 3D 图形的渲染。然而,由于它们能够执行许多并行操作,因此它们的实用性超出了深度学习等应用程序。
GPU 在深度学习模型中的使用始于 2000 年代中后期,并在 2012 年左右随着 AlexNet 的出现而变得非常流行。 AlexNet 是由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 设计的卷积神经网络,于 2012 年赢得了 ImageNet 大规模视觉识别挑战赛 (ILSVRC)。这一胜利标志着一个里程碑,因为它证明了深度神经网络在图像分类和识别方面的有效性。使用 GPU 训练大型模型。
这一突破之后,使用 GPU 进行深度学习模型变得越来越流行,这促成了 PyTorch 和 TensorFlow 等框架的创建。
现在,我们只是在 PyTorch 中编写 .to(“cuda”) 来将数据发送到 GPU,并期望加速训练。但深度学习算法在实践中如何利用 GPU 的计算性能呢?让我们来看看吧!
神经网络、CNN、RNN 和 Transformer 等深度学习架构基本上都是使用矩阵加法、矩阵乘法和将函数应用于矩阵等数学运算来构建的。因此,如果我们找到一种方法来优化这些操作,我们就可以提高深度学习模型的性能。
那么,让我们从简单的开始吧。假设您想要将两个向量 C = A + B 相加。

在 C 中的一个简单实现是:
void AddTwoVectors(flaot A[], float B[], float C[]) {
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}
}
正如您所注意到的,计算机必须迭代向量,在每次迭代中按顺序添加每对元素。但这些操作是相互独立的。第 i 对元素的添加不依赖于任何其他对。那么,如果我们可以同时执行这些操作,并行添加所有元素对呢?
一种简单的方法是使用 CPU 多线程来并行运行所有计算。然而,当涉及深度学习模型时,我们正在处理包含数百万个元素的大量向量。一个普通的CPU只能同时处理大约十几个线程。这就是 GPU 发挥作用的时候!现代 GPU 可以同时运行数百万个线程,从而增强了海量向量上的数学运算的性能。
GPU 与 CPU 比较
尽管对于单个操作,CPU 计算可能比 GPU 更快,但 GPU 的优势依赖于其并行化能力。其原因是它们的设计目标不同。 CPU 的设计目的是尽可能快地执行一系列操作(线程)(并且只能同时执行数十个操作),而 GPU 的设计目的是并行执行数百万个操作(同时牺牲单个线程的速度)。
为了说明这一点,可以将 CPU 想象成一辆法拉利,将 GPU 想象成总线。如果您的任务是运送一个人,那么法拉利(CPU)是更好的选择。然而,如果您要运送几个人,即使法拉利(CPU)每次行程更快,公共汽车(GPU)也可以一次性运送所有人,比法拉利多次运送路线更快。因此,CPU 更适合处理顺序操作,GPU 更适合处理并行操作

为了提供更高的并行能力,GPU 设计分配更多的晶体管用于数据处理,而不是数据缓存和流量控制,这与 CPU 分配大量晶体管用于此目的不同,以优化单线程性能和复杂指令执行。
下图展示了CPU vs GPU的芯片资源分布。
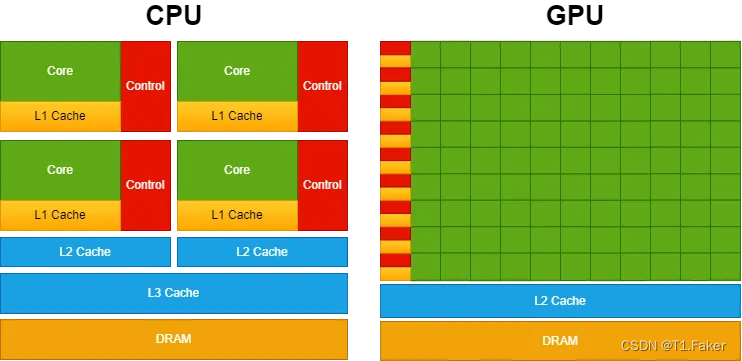
CPU 具有强大的内核和更复杂的高速缓存架构(为此分配大量晶体管)。这种设计可以更快地处理顺序操作。另一方面,GPU 优先考虑拥有大量核心以实现更高水平的并行性。
现在我们已经了解了这些基本概念,那么我们如何在实践中利用这种并行计算能力呢?
CUDA简介
当您运行某些深度学习模型时,您可能会选择使用一些流行的 Python 库,例如 PyTorch 或 TensorFlow。然而,众所周知,这些库的核心在底层运行 C/C++ 代码。此外,正如我们之前提到的,您可以使用 GPU 来加快处理速度。这就是 CUDA 发挥作用的地方! CUDA 代表统一计算架构,它是 NVIDIA 开发的用于在 GPU 上进行通用处理的平台。因此,虽然游戏引擎使用 DirectX 来处理图形计算,但 CUDA 使开发人员能够将 NVIDIA 的 GPU 计算能力集成到他们的通用软件应用程序中,而不仅仅是图形渲染。
为了实现这一点,CUDA 提供了一个简单的基于 C/C++ 的接口 (CUDA C/C++),该接口允许访问 GPU 的虚拟指令集和特定操作(例如在 CPU 和 GPU 之间移动数据)。
在进一步讨论之前,让我们先了解一些基本的 CUDA 编程概念和术语:
- 主机:指CPU及其内存;
- device:指GPU及其内存;
- kernel:指在设备(GPU)上执行的函数;
因此,在使用 CUDA 编写的基本代码中,程序在主机 (CPU) 上运行,将数据发送到设备 (GPU) 并启动要在设备 (GPU) 上执行的内核(函数)。这些内核由多个线程并行执行。执行后,结果从设备(GPU)传回主机(CPU)。
让我们回到两个向量相加的问题:
#include <stdio.h>
void AddTwoVectors(flaot A[], float B[], float C[]) {
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}
}
int main() {
...
AddTwoVectors(A, B, C);
...
}
在 CUDA C/C++ 中,程序员可以定义称为内核的 C/C++ 函数,这些函数在调用时会由 N 个不同的 CUDA 线程并行执行 N 次。
要定义内核,可以使用 global 声明说明符,并且可以使用 <<<…>>> 表示法指定执行该内核的 CUDA 线程数:
#include <stdio.h>
// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[]) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
...
// Kernel invocation with N threads
AddTwoVectors<<<1, N>>>(A, B, C);
...
}
每个线程执行内核,并被赋予一个唯一的线程 ID threadIdx ,可通过内置变量在内核中访问。上面的代码将两个大小为 N 的向量 A 和 B 相加,并将结果存储到向量 C 中。您可以注意到,CUDA 允许我们同时执行所有这些操作,而不是按顺序执行每个成对加法的循环,并行使用 N 个线程。
但在运行这段代码之前,我们需要进行另一次修改。请务必记住,内核函数在设备 (GPU) 内运行。所以它的所有数据都需要存储在设备内存中。您可以使用以下 CUDA 内置函数来完成此操作:
#include <stdio.h>
// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[]) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
int N = 1000; // Size of the vectors
float A[N], B[N], C[N]; // Arrays for vectors A, B, and C
...
float *d_A, *d_B, *d_C; // Device pointers for vectors A, B, and C
// Allocate memory on the device for vectors A, B, and C
cudaMalloc((void **)&d_A, N * sizeof(float));
cudaMalloc((void **)&d_B,