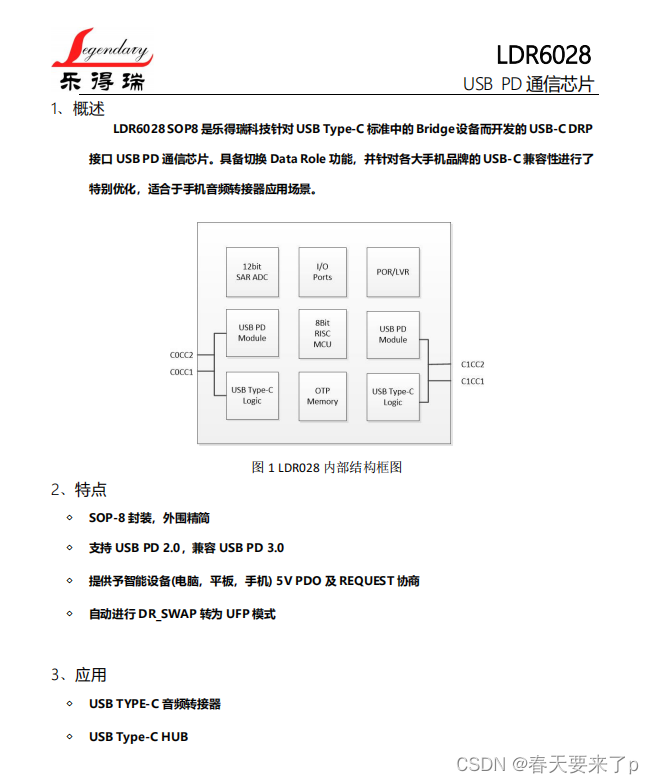
🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972
个人介绍: 研一|统计学|干货分享
擅长Python、Matlab、R等主流编程软件
累计十余项国家级比赛奖项,参与研究经费10w、40w级横向
文章目录
- 1问题背景
- 2 整体步骤
- 3 操作实战
- 3.1 第一步——加载包并读取数据
- 3.2 第二步——探索和准备数据
- 3.3 第三步——基于数据训练模型KNN模型并进行模型效果评估
- 3.4 第四步——基于数据训练模型朴素贝叶斯模型并进行模型效果评估
- 4 完整代码
该篇文章主要针对葡萄酒数据,分别采用KNN和朴素贝叶斯算法实现葡萄酒品种的多分类预测,其中涉及数据集的描述性统计、标准化处理、训练集测试集的随机划分,模型效果评估,特征主成分提取,预测效果可视化等内容。

1问题背景
对于葡萄酒数据(wine.csv),请分别使用kNN和朴素贝叶斯方法构建分类器来预测第1列中给出的品种。在50%数据的随机子集上训练分类器。然后预测其余50%数据的品种,并将其绘制在二维空间中(使用不同的pch),同时评估分类器效果。
2 整体步骤
1.加载实验所需的相关包,并读取数据文件;2.对原始数据的数据类型,数据指标情况进行探索;3.创建标准化函数,对解释变量进行标准化,并通过设置随机种子的方式,将数据集随机划分为训练集、测试集分别约占50%的两个数据集;4.分别通过训练集数据训练KNN和朴素贝叶斯模型,然后将测试集预测的葡萄酒种类绘制到前两个主成分的二维空间中(使用不同的pch);5.使用准确率和混淆矩阵的结果评估分类器效果,其中KNN模型在测试集中预测准确率达到93.18%,朴素贝叶斯模型在测试集中预测准确率达到95.45%。总体上看,在葡萄酒品种预测中,朴素贝叶斯模型的表现更好。
3 操作实战
3.1 第一步——加载包并读取数据
运行程序:
1. #加载包
2. library("class")
3. library("caret")
4. library("gmodels")
5. #读取数据
6. data<- read.csv("D:\\研\\机器学习与R语言\\wine.csv",header = T)
3.2 第二步——探索和准备数据
1)使用str()发现,该数据集共有178个观测值,14个特征(变量),同时,其涉及的数据类型有整型(int)和数值型(num),其中“cultivars”为目标变量。
> str(data) #查看数据类型
'data.frame': 178 obs. of 14 variables:
$ cultivars : int 1 1 1 1 1 1 1 1 1 1 ...
$ Alcohol : num 14.2 13.2 13.2 14.4 13.2 ...
$ Malic.acid : num 1.71 1.78 2.36 1.95 2.59 1.76 1.87 2.15 1.64 1.35 ...
$ Ash : num 2.43 2.14 2.67 2.5 2.87 2.45 2.45 2.61 2.17 2.27 ...
$ Alcalinity.of.ash. : num 15.6 11.2 18.6 16.8 21 15.2 14.6 17.6 14 16 ...
$ Magnesium : int 127 100 101 113 118 112 96 121 97 98 ...
$ Total.phenols : num 2.8 2.65 2.8 3.85 2.8 3.27 2.5 2.6 2.8 2.98 ...
$ Flavanoids : num 3.06 2.76 3.24 3.49 2.69 3.39 2.52 2.51 2.98 3.15 ...
$ Nonflavanoid.phenols : num 0.28 0.26 0.3 0.24 0.39 0.34 0.3 0.31 0.29 0.22 ...
$ Proanthocyanins : num 2.29 1.28 2.81 2.18 1.82 1.97 1.98 1.25 1.98 1.85 ...
$ Color.intensity : num 5.64 4.38 5.68 7.8 4.32 6.75 5.25 5.05 5.2 7.22 ...
$ Hue : num 1.04 1.05 1.03 0.86 1.04 1.05 1.02 1.06 1.08 1.01 ...
$ OD280.OD315.of.diluted.wines: num 3.92 3.4 3.17 3.45 2.93 2.85 3.58 3.58 2.85 3.55 ...
$ Proline : int 1065 1050 1185 1480 735 1450 1290 1295 1045 1045 ...
2)使用table()函数输出数据集葡萄酒品种情况,发现,该数据集中,葡萄酒品种共有三种,数据量分别为59,71,48。
> table(data$cultivars)
1 2 3
59 71 48
3)使用factor()将目标属性(葡萄酒品种)编码为因子类型。
> data$cultivars<-factor(data$cultivars,levels=c('1','2','3'),
+ labels=c('第一类','第二类','第三类'))
>
> str(data$cultivars)
Factor w/ 3 levels "第一类","第二类",..: 1 1 1 1 1 1 1 1 1 1 ...
4)查看不同葡萄酒品种占数据集比例,三种品种比例分别为33.1%,39.9%,27.0%。
> round(prop.table(table(data$cultivars))*100,digits = 1)
第一类 第二类 第三类
33.1 39.9 27.0
5)利用summary()查看各特征数据情况,见下图,包括每个特征的最小值,1/4分位数,中位数,均值,3/4分位数,最大值。由于KNN的距离计算很大程度上依赖输入特征的测量尺度,特征“Proline”的值范围为278~1680。可能导致后续分类存在问题,所以,应用min-max将这些特征进行标准化,将其调整到一个标准范围内。
> summary(data[c('Alcohol','Malic.acid','Ash','Alcalinity.of.ash.',
+ 'Magnesium','Total.phenols','Flavanoids','Nonflavanoid.phenols',
+ 'Proanthocyanins','Color.intensity','Hue','OD280.OD315.of.diluted.wines',
+ 'Proline')])
Alcohol Malic.acid Ash Alcalinity.of.ash.
Min. :11.03 Min. :0.740 Min. :1.360 Min. :10.60
1st Qu.:12.36 1st Qu.:1.603 1st Qu.:2.210 1st Qu.:17.20
Median :13.05 Median :1.865 Median :2.360 Median :19.50
Mean :13.00 Mean :2.336 Mean :2.367 Mean :19.49
3rd Qu.:13.68 3rd Qu.:3.083 3rd Qu.:2.558 3rd Qu.:21.50
Max. :14.83 Max. :5.800 Max. :3.230 Max. :30.00
Magnesium Total.phenols Flavanoids Nonflavanoid.phenols
Min. : 70.00 Min. :0.980 Min. :0.340 Min. :0.1300
1st Qu.: 88.00 1st Qu.:1.742 1st Qu.:1.205 1st Qu.:0.2700
Median : 98.00 Median :2.355 Median :2.135 Median :0.3400
Mean : 99.74 Mean :2.295 Mean :2.029 Mean :0.3619
3rd Qu.:107.00 3rd Qu.:2.800 3rd Qu.:2.875 3rd Qu.:0.4375
Max. :162.00 Max. :3.880 Max. :5.080 Max. :0.6600
Proanthocyanins Color.intensity Hue
Min. :0.410 Min. : 1.280 Min. :0.4800
1st Qu.:1.250 1st Qu.: 3.220 1st Qu.:0.7825
Median :1.555 Median : 4.690 Median :0.9650
Mean :1.591 Mean : 5.058 Mean :0.9574
3rd Qu.:1.950 3rd Qu.: 6.200 3rd Qu.:1.1200
Max. :3.580 Max. :13.000 Max. :1.7100
OD280.OD315.of.diluted.wines Proline
Min. :1.270 Min. : 278.0
1st Qu.:1.938 1st Qu.: 500.5
Median :2.780 Median : 673.5
Mean :2.612 Mean : 746.9
3rd Qu.:3.170 3rd Qu.: 985.0
Max. :4.000 Max. :1680.0
6)创建normalize函数,并利用lapply()将葡萄酒的各特征进行标准化处理,代码如下:
1. normalize<-function(x){
2. return ((x-min(x))/(max(x)-min(x)))
3. }
4. features<-as.data.frame(lapply(data[2:14],normalize))
7)随机化创建训练集和测试集。通过seed()设置随机种子,利sample()随机的从1~178的整数序列中选一般的值构成一个整数向量,通过使用该向量将数据集分割为50%的训练集和50%的测试数据集。同时,查看训练集和测试集数据的分割情况,发现两个数据集各葡萄酒类别占比相似,可以建立模型进行训练预测。
运行程序:
1. # 将数据集划分为训练集和测试集
2. set.seed(123) # 设置随机种子以确保结果的可重复性
3. trainIndex <- sample(178,178/2)
4. data_train<-features[trainingIndex,] #创建训练集
5. data_test<-features[-trainingIndex,] #创建测试集
6. data_train_lables<-data[trainingIndex,1] #存储因子向量型训练集类签
7. data_test_lables<-data[-trainingIndex,1] #存储因子向量型测试集类标签
运行结果:
> round(prop.table(table(data_train_lables))*100,digits = 1)
data_train_lables
第一类 第二类 第三类
33.3 40.0 26.7
> round(prop.table(table(data_test_lables))*100,digits = 1)
data_test_lables
第一类 第二类 第三类
33.0 39.8 27.3
3.3 第三步——基于数据训练模型KNN模型并进行模型效果评估
1)使用knn()函数对测试数据进行分类,初始值k设置为3,函数knn()返回一个因子向量,为测试集中每一个案例返回一个预测标签,将其命名为data_test_pred。
运行程序:
1. ##KNN分类器
2. # 使用kNN构建分类器
3. data_test_pred<-knn(train = data_train,test = data_test,cl<-data_train_lables,k=3)
2)首先利用prcomp()提取所有解释变量的前两个主成分,将其分别作为葡萄酒预测类型的X轴和Y轴进行可视化。从下图可以看出三种类别的葡萄酒数据位置存在明显的聚集现象,说明同一类别数据具有较高相似性。
运行程序:
1. ##预测结果绘图:KNN模型
2. # 选择前两个主成分进行绘图
3. pca_results <- prcomp(data_test, scale = F)
4. plot_features <- pca_results$x[, 1:2]
5. plot_data <- data.frame(plot_features, Actual =data_test_lables, Predicted_kNN =data_test_pred, Predicted_GNB=nb_pred)
6. ggplot(plot_data, aes(x = plot_data[, 1], y = plot_data[, 2], color = Predicted_kNN, shape = Predicted_kNN)) +
7. geom_point(size = 3, alpha = 0.6) +
8. scale_color_manual(values = c("red", "blue", "green")) + # 假设有三个品种,使用不同颜色
9. scale_shape_manual(values = c(1, 2, 3)) + # 使用默认的三种形状,并设置图例标题
10. labs(title = "kNN Predictions on Test Set", x = "Feature 1", y = "Feature 2") + # 删除color参数,因为我们在scale_shape_manual中设置了name
11. theme_minimal()
运行结果:
3)使用正确率和混淆矩阵评估模型优劣。根据计算KNN模型预测结果发现,在测试集中,模型预测准确率达到93.18%。具体结果如下:
> cat("kNN Accuracy:", knn_accuracy, "\n")
kNN Accuracy: 0.9318182
> #混淆矩阵
> CrossTable(x=data_test_lables,y=data_test_pred,prop.chisq = F)
Cell Contents
|-------------------------|
| N |
| N / Row Total |
| N / Col Total |
| N / Table Total |
|-------------------------|
Total Observations in Table: 88
| data_test_pred
data_test_lables | 第一类 | 第二类 | 第三类 | Row Total |
--------------|-----------|-----------|-----------|-----------|
第一类 | 29 | 0 | 0 | 29 |
| 1.000 | 0.000 | 0.000 | 0.330 |
| 0.967 | 0.000 | 0.000 | |
| 0.330 | 0.000 | 0.000 | |
-----------------|-----------|-----------|-----------|-----------|
第二类 | 1 | 30 | 4 | 35 |
| 0.029 | 0.857 | 0.114 | 0.398 |
| 0.033 | 0.968 | 0.148 | |
| 0.011 | 0.341 | 0.045 | |
-----------------|-----------|-----------|-----------|-----------|
第三类 | 0 | 1 | 23 | 24 |
| 0.000 | 0.042 | 0.958 | 0.273 |
| 0.000 | 0.032 | 0.852 | |
| 0.000 | 0.011 | 0.261 | |
-----------------|-----------|-----------|-----------|-----------|
Column Total | 30 | 31 | 27 | 88 |
| 0.341 | 0.352 | 0.307 | |
-----------------|-----------|-----------|-----------|-----------|
通过KNN模型预测效果的混淆矩阵,发现,第一类葡萄酒完全预测正确,第二类葡萄酒有一个被预测为第一类,4个被预测为第三类,有一个被预测为第一类,第三类葡萄酒有1个被预测为第二类,总体预测效果良好。
3.4 第四步——基于数据训练模型朴素贝叶斯模型并进行模型效果评估
1)使用naiveBayes()函数训练数据,将模型保存到nb_model,并使用predict将预测结果保存到nb_pred。
运行程序:
1. ##朴素贝叶斯分类器
2. nb_model <- naiveBayes(data_train, data_train_lables)
3. nb_pred <- predict(nb_model, data_test)
2)将朴素贝叶斯预测结果,绘制到二维平面发现,各类别葡萄酒分类效果明显。
运行程序:
1. ggplot(plot_data, aes(x = plot_data[, 1], y = plot_data[, 2], color = Predicted_GNB, shape = Predicted_GNB)) +
2. geom_point(size = 3, alpha = 0.6) +
3. scale_color_manual(values = c("red", "blue", "green")) + # 假设有三个品种,使用不同颜色
4. scale_shape_manual(values = c(1, 2, 3)) + # 使用默认的三种形状,并设置图例标题
5. labs(title = "kNN Predictions on Test Set", x = "Feature 1", y = "Feature 2") + # 删除color参数,因为我们在scale_shape_manual中设置了name
6. theme_minimal()
运行结果:

3)使用正确率和混淆矩阵评估模型优劣。根据计算朴素贝叶斯模型预测结果发现,在测试集中,模型预测准确率达到95.45%。具体结果如下:
> # 评估朴素贝叶斯分类器
> nb_confusion_matrix <- table(data_test_lables, nb_pred)
> nb_accuracy <- sum(diag(nb_confusion_matrix)) / sum(nb_confusion_matrix)
> cat("Naive Bayes Accuracy:", nb_accuracy, "\n")
Naive Bayes Accuracy: 0.9545455
>
> ##评估分类器:朴素贝叶斯
> ##混淆矩阵
> CrossTable(x=nb_pred,y=data_test_pred,prop.chisq = F)
Cell Contents
|-------------------------|
| N |
| N / Row Total |
| N / Col Total |
| N / Table Total |
|-------------------------|
Total Observations in Table: 88
| data_test_pred
nb_pred | 第一类 | 第二类 | 第三类 | Row Total |
-------------|-----------|-----------|-----------|-----------|
第一类 | 30 | 1 | 0 | 31 |
| 0.968 | 0.032 | 0.000 | 0.352 |
| 1.000 | 0.032 | 0.000 | |
| 0.341 | 0.011 | 0.000 | |
-------------|-----------|-----------|-----------|-----------|
第二类 | 0 | 28 | 3 | 31 |
| 0.000 | 0.903 | 0.097 | 0.352 |
| 0.000 | 0.903 | 0.111 | |
| 0.000 | 0.318 | 0.034 | |
-------------|-----------|-----------|-----------|-----------|
第三类 | 0 | 2 | 24 | 26 |
| 0.000 | 0.077 | 0.923 | 0.295 |
| 0.000 | 0.065 | 0.889 | |
| 0.000 | 0.023 | 0.273 | |
-------------|-----------|-----------|-----------|-----------|
Column Total | 30 | 31 | 27 | 88 |
| 0.341 | 0.352 | 0.307 | |
-------------|-----------|-----------|-----------|-----------|
通过朴素贝叶斯模型预测效果的混淆矩阵,发现,第一类葡萄酒有一个被预测为第二类,第二类葡萄酒有3个被预测为第三类,第三类葡萄酒有两个被预测为第2类,总体预测效果良好。
4 完整代码
1. #加载包
2. library("class")
3. library("caret")
4. library("gmodels")
5. #读取数据
6. data<- read.csv("D:\\研\\机器学习与R语言\\wine.csv",header = T)
7. str(data) #查看数据类型
8.
9. table(data$cultivars) #查看葡萄酒品种情况
10.
11. data$cultivars<-factor(data$cultivars,levels=c('1','2','3'),
12. labels=c('第一类','第二类','第三类'))
13.
14. str(data$cultivars)
15.
16. round(prop.table(table(data$cultivars))*100,digits = 1)
17. colnames(data)
18. summary(data[c('Alcohol','Malic.acid','Ash','Alcalinity.of.ash.',
19. 'Magnesium','Total.phenols','Flavanoids','Nonflavanoid.phenols',
20. 'Proanthocyanins','Color.intensity','Hue','OD280.OD315.of.diluted.wines',
21. 'Proline')])
22.
23. normalize<-function(x){
24. return ((x-min(x))/(max(x)-min(x)))
25. }
26. features<-as.data.frame(lapply(data[2:14],normalize))
27.
28.
29.
30. # 将数据集划分为训练集和测试集
31. set.seed(123) # 设置随机种子以确保结果的可重复性
32. trainIndex <- sample(178,178/2)
33. data_train<-features[trainingIndex,] #创建训练集
34. data_test<-features[-trainingIndex,] #创建测试集
35. data_train_lables<-data[trainingIndex,1] #存储因子向量型训练集类标签
36. data_test_lables<-data[-trainingIndex,1] #存储因子向量型测试集类标签
37.
38. ##查看分割情况
39. round(prop.table(table(data_train_lables))*100,digits = 1)
40. round(prop.table(table(data_test_lables))*100,digits = 1)
41.
42.
43. ##KNN分类器
44. # 使用kNN构建分类器
45. data_test_pred<-knn(train = data_train,test = data_test,cl<-data_train_lables,k=3)
46.
47. ##朴素贝叶斯分类器
48. nb_model <- naiveBayes(data_train, data_train_lables)
49. nb_pred <- predict(nb_model, data_test)
50.
51. ##预测结果绘图:KNN模型
52. # 选择前两个主成分进行绘图
53. pca_results <- prcomp(data_test, scale = F)
54. plot_features <- pca_results$x[, 1:2]
55. plot_data <- data.frame(plot_features, Actual =data_test_lables, Predicted_kNN =data_test_pred, Predicted_GNB=nb_pred)
56. ggplot(plot_data, aes(x = plot_data[, 1], y = plot_data[, 2], color = Predicted_kNN, shape = Predicted_kNN)) +
57. geom_point(size = 3, alpha = 0.6) +
58. scale_color_manual(values = c("red", "blue", "green")) + # 假设有三个品种,使用不同颜色
59. scale_shape_manual(values = c(1, 2, 3)) + # 使用默认的三种形状,并设置图例标题
60. labs(title = "kNN Predictions on Test Set", x = "Feature 1", y = "Feature 2") + # 删除color参数,因为我们在scale_shape_manual中设置了name
61. theme_minimal()
62.
63.
64. ##评估分类器:KNN
65. # 评估kNN分类器
66. knn_confusion_matrix <- table(data_test_lables, data_test_pred)
67. knn_accuracy <- sum(diag(knn_confusion_matrix)) / sum(knn_confusion_matrix)
68. cat("kNN Accuracy:", knn_accuracy, "\n")
69. #混淆矩阵
70. CrossTable(x=data_test_lables,y=data_test_pred,prop.chisq = F)
71.
72.
73.
74.
75. ggplot(plot_data, aes(x = plot_data[, 1], y = plot_data[, 2], color = Predicted_GNB, shape = Predicted_GNB)) +
76. geom_point(size = 3, alpha = 0.6) +
77. scale_color_manual(values = c("red", "blue", "green")) + # 假设有三个品种,使用不同颜色
78. scale_shape_manual(values = c(1, 2, 3)) + # 使用默认的三种形状,并设置图例标题
79. labs(title = "kNN Predictions on Test Set", x = "Feature 1", y = "Feature 2") + # 删除color参数,因为我们在scale_shape_manual中设置了name
80. theme_minimal()