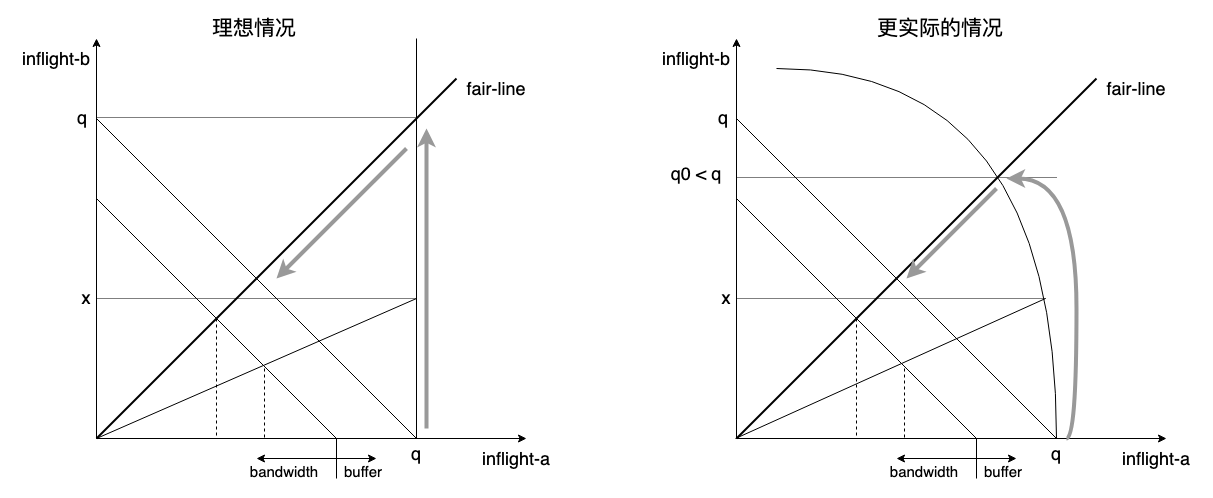
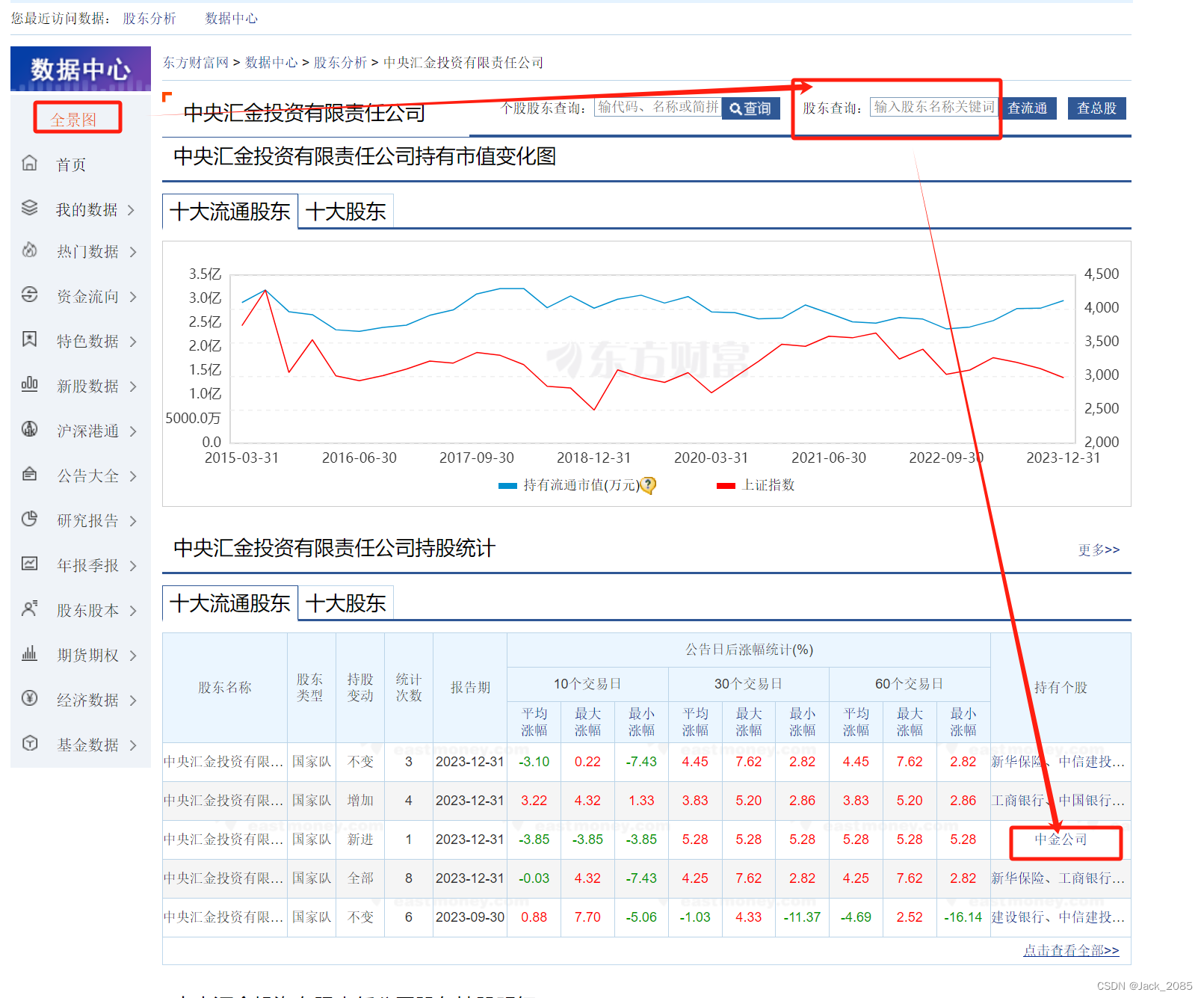
文章汇总
动机
本文的一个思想就是:尽管新类的标签并不能“恰如其分”地表示基数据集中的样本,但是很多基数据集的样本会包含与新类中相似的对象,例如,基数据集中的老虎和新类中的猫有相似的特征,那么就有60%的概率将老虎打上猫的标签;或者基数据集中的图片与新类中的图片有背景相似,比如“car”和“pedestrians”即车和行人的背景可能都是街道,那么打完伪标签后,两幅图的标签很有可能相同。
而我们通过伪标签数据集来微调整个模型,训练网络识别基数据集上的这些相似特性或背景线索,从而将representation转向对新类识别有用的特征。
此外,由于基数据集中样本数据相比新类来说丰富,起到大量非参数化数据增强的作用,能够产生general representation,避免过拟合问题,同时也克服了小样本学习中固有的数据稀缺问题。
流程解读

Pretraining
很正常的预训练步骤,用庞大的基类数据集base训练出backbone和分类器:
![]()
Episode training:step1
拿novel数据集来训练出一个预测的标签空间为novel的标签空间的分类器
值得注意的是,这里是不变的,而
的初始参数为
进行softmax之前的参数。
![]()
Episode training:step2
作为backbone,分类器,两者参数都不变,而是直接拿base的数据来生成软伪标签
Episode training:step3
拿novel数据集训练backbone和分类器:

分别为x与伪标签的损失,x与实际标签的损失。
本人对这篇文章的疑问
少样本图像分类的目标不是要去一个识别出一份训练中没有出过的新类数据集novel domain吗?可是这篇文章把novel domain的数据拿来训练了,这是否违背了少样本图像分类的本意?
摘要
少样本分类需要适应从大型带注释的基础数据集中学习到的知识,以识别新的未见过的类,每个类由几个标记的示例表示。在这种情况下,在大数据集上预训练一个具有高容量的网络,然后在少数例子上对其进行微调,会导致严重的过拟合。同时,在从大型标记数据集中学习的“冻结”特征之上训练简单的线性分类器无法使模型适应新类别的属性,从而有效地导致欠拟合。
在本文中,我们提出了这两种流行策略的替代方法。首先,我们的方法使用在新类上训练的线性分类器对整个大型数据集进行伪标签。这有效地“幻觉”了大型数据集中的新类,尽管新类别不存在于基本数据库中(新类和基本类是不相交的)。然后,除了新数据集上的标准交叉熵损失外,它还使用伪标记基础样本上的蒸馏损失对整个模型进行微调。这一步有效地训练网络识别上下文和外观线索,这些线索对小说类别识别有用,但使用整个大规模基础数据集,从而克服了少样本学习固有的数据稀缺性问题。尽管方法很简单,但我们表明,我们的方法在四个建立良好的少量分类基准上优于最先进的方法。
介绍
深度学习已经成为大数据场景的主要学习范式,并在广泛的应用领域取得了令人印象深刻的成果,包括计算机视觉[23]、自然语言处理[10]和生物信息学[41]。然而,要使深度学习模型适应标记样本较少的环境仍然很困难,因为大容量模型本质上容易过度拟合。
少样本学习通常在情景学习范式下进行研究,该范式通过从大型基础数据集的一小部分类别中重复采样少量示例来模拟训练过程中的少样本设置。在这些训练集上进行优化的元学习算法[15,36,22,49,44]推动了少样本分类领域的发展。然而,最近的研究[7,11,48]表明,纯粹的迁移学习策略往往更具竞争力。例如,Tian等人[48]提出首先在基本数据集上预训练一个大容量分类模型,然后使用少数新示例在这个预训练的表示上简单地学习一个线性分类器。通过多次蒸馏迭代[17],或者同时结合熵最大化、旋转自我监督、知识蒸馏等几种损失,可以进一步提高转移模型的少样本性能[35]。
在本文中,我们采用迁移学习方法。然而,我们并没有将表征冻结为从基类中学习到的特征[48,35,39],而是对整个模型进行了微调。由于仅使用少数示例来调整网络会导致严重的过拟合(正如我们的缩减所证明的那样),我们建议通过重用整个基本数据集来优化模型,但只有在将原始标签与对应于新类的伪标签交换之后。这是通过在基本数据集上运行一个简单的线性分类器来实现的,这个分类器是在少数新类别的示例上训练的。分类器有效地“幻觉”了基础图像中新类的存在。尽管我们在基本数据集的类别与新类别完全脱节的情况下对我们的方法进行了经验评估,但我们证明了这种大规模伪标记数据能够有效地调整整个模型以识别新类别。优化是使用伪标记基础数据集上的蒸馏和少数样本上的交叉熵最小化的组合来进行的。图1概述了我们提出的方法。
直觉是,尽管新奇类在基本图像中没有“适当地”表示,但许多基本示例可能包含与新奇类相似的对象,这些对象由定义属于新奇类的概率的软伪标签编码。例如,假设老虎的基本图像与“家猫”的外观相似,伪标签可能会给它们分配0.6的概率,使其属于新类别“家猫”。或者,它可能会为基础图像分配大的新类伪标签概率,因为它的真实基础类别与小说类共享相似的上下文背景,例如“汽车”和“行人”,它们都可能出现在街景中。使用蒸馏目标(结合少数新图像示例的交叉熵损失)对这些软伪标签上的整个模型进行微调,训练网络识别在基础数据集上的相似或相同线索。因此,将表示转向对识别新类别有用的特征。此外,由于基础数据集是大规模的,这些示例服务于大量非参数数据增强的作用,产生相当一般且不会过拟合的表示,从而克服了少拍学习固有的数据稀缺性问题。我们邀请读者回顾我们的技术附录(TechApp)的标签幻觉可视化部分中的可视化和解释,以进一步了解我们系统的行为。这些可视化证实了我们方法背后的直觉,即得分最高的基本图像往往包含与小说类对象共同出现的上下文元素。例子包括前景对象有相似的外观few-shot图像(例如,图1中的雪橇犬形象TechApp),或基地的例子包括与新类的形状类似于类对象(例如,图2中的绿曼巴TechApp,类似于线虫的形状),甚至实例匹配的空间布局(例如,烟草商店和立式钢琴的图片也有类似的空间布局的书店在图3类TechApp)。
图1:我们提出的方法在一个说明性设置中的概述,涉及5个新类别的1-shot分类。预训练从标记的基础数据集中学习主干模型和分类头
。骨干用于计算后续阶段的嵌入,而分类头被丢弃。在episode训练中,步骤1)使用支持集和固定嵌入Θ在新域学习一个线性分类器
。步骤2)使用固定嵌入
和分类器
对基数据集相对于新域的标签空间进行伪标签。步骤3)结合蒸馏和交叉熵最大化,使用支持集和伪标记的基础数据集重新学习嵌入和分类器。注意,基本数据集和支持集不共享任何类。
我们注意到,伪标记在半监督学习中已经被广泛使用,其中未标记的样本与标记的样本属于同一类[45,6,34]。伪标记也适用于少数镜头设置[24,50],但仍然适用于经验设置,即未标记数据集中包含新类。我们工作的新颖之处在于表明伪标记的优势甚至扩展到极端的设置,其中基类集和新类集完全不相交。我们还注意到,我们的工作不同于换向的few-shot学习[50,11],后者需要在训练过程中使用未标记示例的测试集。相反,我们的方法在一个纯粹的归纳设置中运行,在每个集中,只有一小部分新的标记示例和基本数据集用于微调。
方法
问题陈述
我们现在正式定义了本工作中考虑的少样本分类问题。我们采用了通用的设置,假设存在一个大规模的标记基础数据集,用于判别学习对随后的新类识别有用的表示。设是基数据集,标签是
。为了实现良好的表示学习,我们假设类的数量
和示例的数量
都很大。我们用
表示新颖数据集。基类和新颖类是不相交的,即
。我们假设对少样本分类模型的训练和测试是按episode组成的。在每episode的i中,给予少样本学习者一个支持集
,涉及K个新颖类和从
中采样的每个类的N个样例(N非常小,通常在1到10之间)。然后对查询集
,其中包含与D中支持i的相同K类的示例。因此,查询/支持集分别充当少量训练/测试集。在每集episode的i中,在给定
中的少数训练样例的情况下,few-shot学习器适应从大规模数据库
中学习到的表示/模型来识别新的类。
学习在基础数据集上的嵌入表示
首先,我们的目标是从base数据集中学习一个嵌入模型,该模型将很好地转移和推广到下游的少样本问题。我们遵循Tian等人[48]的方法(表示为RFS),有区别地地训练一个由主干和最终分类层
组成的卷积神经网络。参数
共同优化
-way基分类问题,使用数据集
:
![]()
其中为交叉熵损失。先前的工作表明,通过知识蒸馏[48]、旋转自我监督[35]或通过对图像变换集强制表示等价和不变性[39],可以进一步提高参数
编码的嵌入表示的质量。在本文提出的实验中,我们遵循SKD[35](使用自监督蒸馏)和IER[39](利用不变和等变表示)的嵌入学习策略。然而,请注意,我们的方法独立于用于嵌入学习的具体方法。
幻想在基本数据集中出现新的类
为了根据新类对基本数据集进行伪标记,我们首先在支持集上训练一个分类器。对于元学习阶段的每一episode 中i,我们使用少样本支持集在固定特征嵌入模型
上学习一个线性分类器
。
![]()
需要注意的是,在之前的文献[48,35,39]中,是直接对查询集
求值,从而得到最终的少样本分类结果。相反,这里我们使用生成的模型
根据第个episode中新类的本体重新标记基本数据集。我们用
的向量(softmax之前的输出)表示通过将学习到的分类器应用于
的示例生成的logits向量,即
。这些软伪标签用于通过知识蒸馏重新训练整个模型,如下所述。
微调整个模型以识别新的类
最后,我们使用包含相同比例的支持和基类样例的mini-batch对整个模型(即主干和分类器)进行微调。基础示例的损失函数是知识蒸馏[20],而支持示例的目标最小化是交叉熵(CE)。换句话说,我们在两种损失的混合上优化模型的参数
其中表示幻觉伪标签,
为模型预测与温度T缩放的伪标签之间的KL散度,
是超参数,权衡了这两个损失的重要性。由于支持集非常小(在某些设置中,每episode包括五个新颖类,每个新颖类只有一个示例),我们使用数据增强来生成每个支持图像的多个视图,以便获得足够的示例来填充mini-batch的一半。具体来说,我们采用了之前作品[48,35,39]的标准设置,并使用随机裁剪,颜色抖动和随机翻转来生成多个视图。
最后,在查询集上计算得到的模型
。最后的结果是通过对所有episode的平均准确率来报告的。我们注意到,虽然伪标签和调优的操作是分开且按顺序呈现的,但在实践中,对于某些数据集,我们发现为迷你批处理中加载的基本示例动态生成目标伪标签更有效,而不必将它们存储在磁盘上。
实验

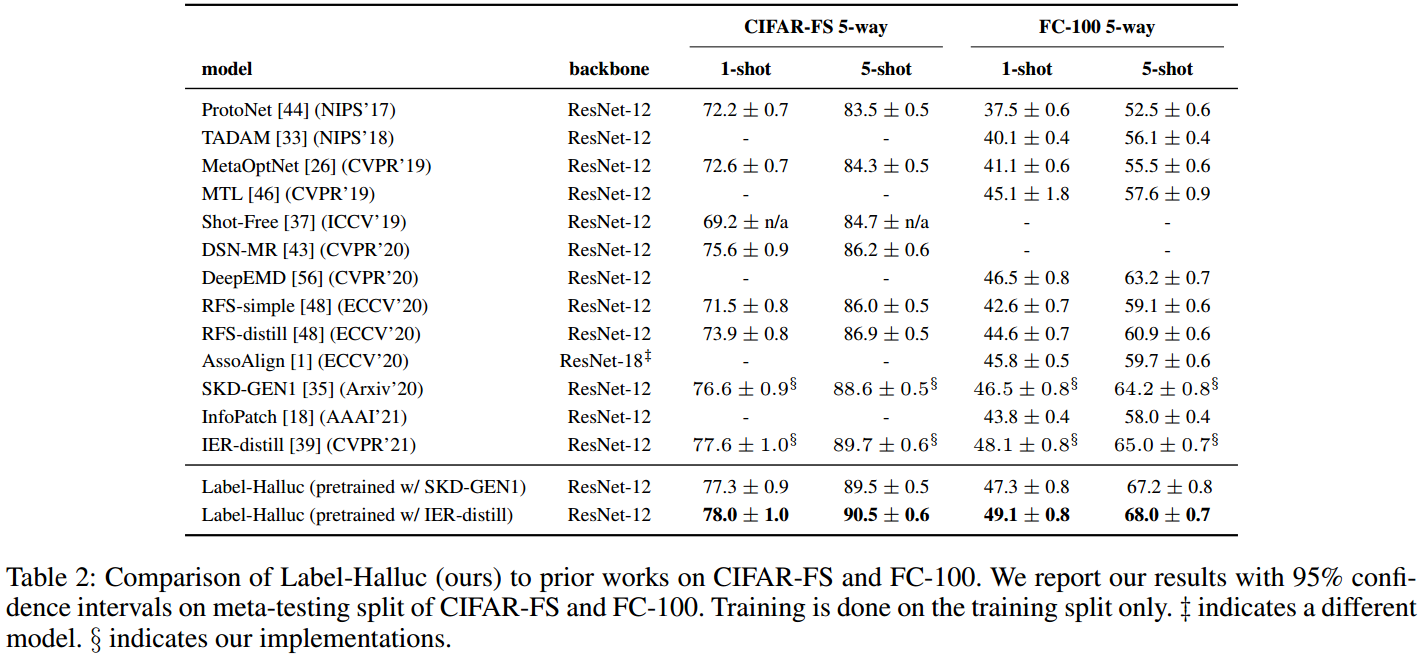
结论
我们提出了一种简单的标签幻觉策略,以便从新类的少样本样本中有效地微调大容量模型。在四个已建立的少量分类基准上的结果表明,即使在基本数据集的标签和新示例的标签完全不相交的极端情况下,我们的过程也达到了最先进的精度,并且通过微调或在预训练表征之上执行线性分类的方法,始终优于流行的迁移学习策略。
参考资料
论文下载(2022 AAAI)
https://arxiv.org/abs/2112.03340
代码地址
GitHub - yiren-jian/LabelHalluc: [AAAI 2022] Label Hallucination for Few-Shot Classification







![[华为OD] 给航天器一侧加装长方形或正方形的太阳能板 100](https://img-blog.csdnimg.cn/direct/51754d605de44c40aec2e6d0fecada95.png)