前言
数据结构篇---C语言实现数据结构
C语言的基础知识:数组 函数 结构体 指针 动态内存分配。
顺序表
从数据结构的角度看待数组
int arr[10];数组是一个基本的数据结构吗?
这里以一维数组为例。
从数据来看:这个数组存储10个整型数据。
从结构上:数据在内存中连续存储,地址随下标增加而增大。
所以数组也是一个数据结构。
顺序表的概念
顺序:按照一定的顺序,连续。
表:集合,相同事物的集合体。
连续,相同事物?这也符合数组的概念。那么顺序表和数组有什么关系呢?
顺序表底层就是数组,你认为顺序表就是数组也没问题。
已经有数组了为什么单独引入顺序表这个数据结构?
学了数组你能实现以下简单的操作
1.修改数组元素的数据。
2.排序。调用qsort函数,或者独立实现一种排序算法
3.数组传参。
4.用数组下标或者指针访问某个元素。
那么以下的操作你可曾实现过?
1.在数组的某个位置插入某个数据。
2.删除数组某个位置的数据。
3.查找数组中的某个数据。
很遗憾,数组并没有很简单的功能实现这些操作,初学时我们要自己用循环实现。
但我们如今开始学习数据结构了,顺序表就实现了这些算法。
顺序表提供了很多现成的的方法,数组要操作可能需要操作者自己实现的代码,顺序表已经实现了代码,可以立即使用。
结论:顺序表是数组的plus版。
线性表
下面挖掘一下广度。顺序表也只是一棵树的枝叶,我们要对他进行溯源,就是下面的线性表。
我们拆分一下这个词,线性表。
线性:即直线。具有直线的性质,直线是逻辑上的直线,不是物理上的直线。线性表的数据,一定对外表现出一条直线,(我们观察到的)。物理上指内存上的存储,即数据在内存存储是否为一条直线(连续存储)不关心。
表:集合。
线性表是一个(逻辑)线性结构的集合。
顺序表在逻辑上是线性的,所以顺序表是一种线性表。
顺序表在内存空间也是连续的,但线性表不要求空间连续。
那么是线性表但空间上不连续,又是什么数据结构呢?这里留个悬念。
总结:
线性表 逻辑上:线性(连续);物理结构(可连续可不连续)。
顺序表 逻辑上:线性;物理结构 连续。
顺序表的分类
顺序表分为静态顺序表和动态顺序表。
1.静态顺序表
前面说过顺序表的概念了。
限定条件:静态,意味着固定了,不变。
数组在创建时元素个数确定了,这个数组就固定了,称为定长数组。
虽然数组总的元素大小固定,但这数组每个元素不一定全部存入有效的数据,引入size记录有效数据的个数。
因此这里给出静态顺序表的定义:
#define MAX 100 //宏定义明示常量
typedef int SLDataType;//方便替换类型,比如你要存放double类型,只需把int更改为double
typedef struct seqlist {
SLDataType arr[MAX];//定长数组
int size;//记录当前的有效数据
}SL;
2.动态顺序表
限定条件:动态,灵活,"数组"大小可以变动。
C语言提供了动态内存分配相关的函数,方便程序员灵活操作空间,实现动态增容的目的。由于开辟的空间是连续,我们可以用指针把它当数组处理。
typedef int SLDataType;
typedef struct seqlist {
SLDataType* arr;//需要一个SLDataType类型指向动态开辟内存的指针
int size;//记录有效数据的个数
int capacity;//记录当前开辟的内存大小能存入多少个SLDataType类型的元素个数。
}SL;size要小于capacity即当前的有效数据小于总的容量大小,如果size==capacity,说明当前动态空间已经用完了,下次要增加值需要动态扩容,即realloc函数。
3.对比两种顺序表,分析优缺点。
动态顺序表和静态顺序表各有其优缺点,下面是对两者的详细对比:
静态顺序表:
优点:
空间确定性:静态顺序表在声明时即分配了固定大小的内存空间,这确保了其存储空间的确定性,便于管理和使用。
内容有效性,虽然是定长数组,但使用者知道静态顺序表大致会用多少空间,利用率高效。
缺点:
空间灵活性差:静态顺序表的大小在初始化时已经确定,无法在运行过程中动态地增加或减少。
动态顺序表:
优点:
空间灵活性高:动态顺序表的大小可以在运行时根据需要动态地增加或减少,这使得它更加灵活,能够适应不同规模的数据存储需求。
缺点:
内存管理复杂:动态顺序表要手动管理内存,包括分配和释放内存空间。如果管理不当,可能会引发内存泄漏问题。
性能上损耗:动态地分配和释放内存,动态顺序表在运行时可能会带来一些额外的开销,如内存分配,内存回收。
总结:看应用场景。
没有孰优孰劣,在数据量固定且空间需求明确的情况下,静态顺序表可能更加合适;而在数据量不确定或需要动态调整存储空间的情况下,动态顺序表可能更为适用。
顺序表的实现
这里以动态顺序表的实现为例,因为其实现相对有难度。
思考一下,我们要实现顺序表的那些功能?
动态顺序表放这儿方便看
typedef int SLDataType;
typedef struct seqlist {
SLDataType* arr;//需要一个SLDataType类型指向动态开辟内存的指针
int size;//记录有效数据的个数
int capacity;//记录当前开辟的内存大小能存入多少个SLDataType类型的元素个数。
}SL;SL s;//先创建一个顺序表出来有了一个顺序表,第一步肯定是初始化吧。
接下来要用其实现某些功能了,即增删查改。
增:将数据存入顺序表,可以分头插,尾插,任意位置插入数据。
删:将数据从顺序表删除,有头删,尾删,指定位置删除。
查:即查找顺序表中某个元素是否存在。
改:修改顺序表指定位置的元素。
最后一步,如果顺序表不再使用了,记得销毁,将内存返还给操作系统。
采用的多文件实现,后面会附上源代码

顺序表的初始化
void SLInit(SL* ps)
{
ps->arr = NULL;
ps->size = ps->capacity = 0;
}顺序表的销毁
void SLDestroy(SL* ps)
{
if (ps != NULL)//传入结构体指针不为空
{
free(ps->arr);//释放动态开辟的内存
}
//跟初始化操作一样。
ps->arr = NULL;//ps->arr记得原来开辟的起始地址,但现在已经回收内存,需要置空
ps->size = ps->capacity = 0;//当前的有效数据个数和总的数据大小归为0;
}
顺序表的打印
为了便于测试过程检验每个函数的各个逻辑是否准确,每次打印出调用函数后的顺序表数据。
//遍历打印一遍顺序表,循环终止条件比较好理解就不赘述了。
void SLPrint(SL* ps)
{
assert(ps);
int i = 0;
for (i = 0; i < ps->size; i++)
{
printf("%d ", ps->arr[i]);
}
printf("\n");
}
顺序表的尾插
void SLPushback(SL* ps, SLDataType x)
{
//1.排除参数为空指针的情况
assert(ps);
//2.检查空间是否足够
//没开辟空间(因为初始化时没给顺序表开辟空间)
//当前开辟的空间满了,需要扩容。
//写一个检查空间并进行扩容的函数
SLCheckCapacity(ps);//后面会说
ps->arr[ps->size] = x;
++ps->size;
}动态增容函数设计
void SLCheckCapacity(SL* ps)
{
//检查该结构体指针是否为空
assert(ps);
//没开辟空间和空间不够的条件是ps->size==ps->capacity;
if (ps->size == ps->capacity)
{
//创建一个变量没开辟空间给一个初始的空间大小,否则增容到原来的两倍
int newCapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;
//1.既要能开辟空间又能增容的:realloc函数
//2.由于realloc函数可能会失败,返回NULL,创建临时变量存储并检测这个值是否为空指针。
SLDataType* tmp = (SLDataType*)realloc(ps->arr, newCapacity*sizeof(SLDataType));
//检测
if (tmp == NULL)
{
perror("realloc fail");
exit(-1);//异常退出。
}
//开辟或者增容成功了.
ps->arr = tmp;
ps->capacity = newCapacity;//开辟或增容后空间大小要修改。
}
}顺序表的头插
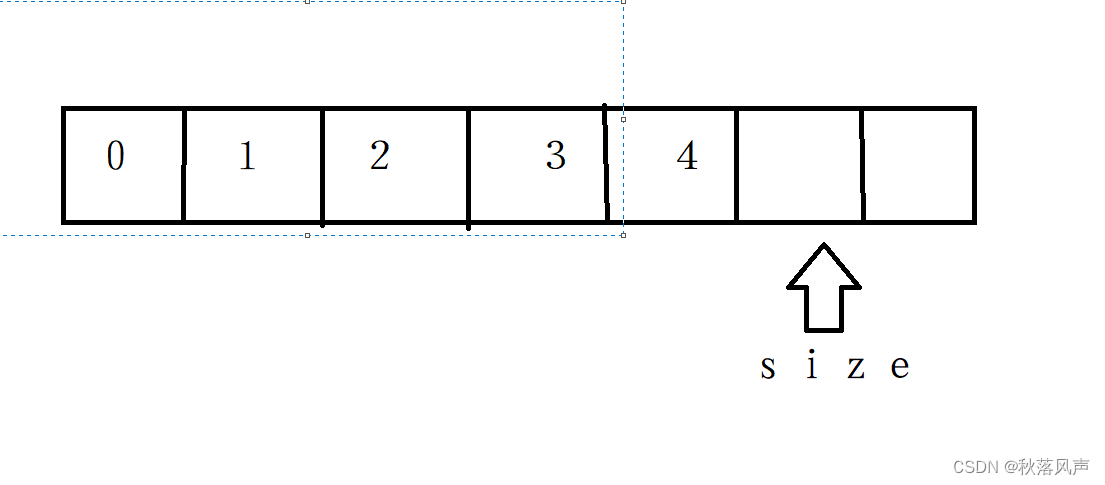
这里是容量为6的顺序表,要实现头插只需将size前的每个元素逐一往后移。
void SLPushfront(SL* ps, SLDataType x)
{
assert(ps);//判断空指针
SLCheckCapacity(ps);//检查空间大小是否足够
for (int i = ps->size; i>0; i--)
{
ps->arr[i] = ps->arr[i - 1];//终止条件:ps->arr[1]=ps->arr[0];
}
//后移结束,可以进行头插了。
ps->arr[0] = x;
//每次插入一个元素要有效数据加1;
ps->size++;
}顺序表的尾删
//由于是删除数据,只需一个参数。
//执行删除操作时,顺序表要不为空表。
void SLPopBack(SL* ps)
{
assert(ps);//判断空指针
assert(ps->arr);//判断顺序表不为空表,即当前存在有效数据
--ps->size;//当前有效数据减一即可。
}顺序表的头删
//由于是删除操作,只需传一个参数。
//只需第二个元素覆盖第一个元素,第三个覆盖第二个,从前往后依次。
void SLPopFront(SL* ps)
{
assert(ps);
int i = 0;
for (i = 1; i<ps->size; i++)
{
ps->arr[i - 1] = ps->arr[i];
//循环终止条件
//ps->arr[0]=ps->arr[1]
//ps->arr[ps->size-2]=ps->arr[size-1];
}
--ps->size;//由于每次删除一个数据,所以记得有效数据减少一。
}顺序表在指定位置之前的插入

//在pos位置之前插入数据
//由于插入数据,要知道插入到数据是多少,所以需要传参。
//由于插入数据,要检查当前空间是否足够,需要调用SLCheckCapacity函数
//由于指定位置,要知道位置是多少,也需要传参,还需注意其合法性。
void SLInsert(SL* ps, int pos, SLDataType x)
{
assert(ps);
assert(pos >= 0 && pos < ps->size);
SLCheckCapacity(ps);
int i = 0;
for (i = ps->size; i > pos; i--)
{
ps->arr[i] = ps->arr[i - 1];
}
ps->arr[pos] = x;//在指定位置之前插入,即该位置放新数据,原来的位置及之后的数据整体往后挪。
ps->size++;//插入了一个元素,有效数据加一。
}顺序表在指定位置删除元素
//由于删除数据,对比插入数据,就只要两个参数
void SLErase(SL* ps, int pos)
{
assert(ps);//空指针
assert(pos >= 0 && pos < ps->size);//判断位置区间的有效性
//不用检查空间
int i = 0;
//跟处理头删一样,但这次位置不是0了。
for (i = pos; i < ps->size - 1; i++)
{
ps->arr[i] = ps->arr[i + 1];//最后一次循环,ps->arr[ps->size-2]=ps->size[ps->size-1]
}
--ps->size;
}修改函数
没什么难度。
void SLmodify(SL* ps, int pos, SLDataType x)
{
assert(ps);
ps->arr[pos] = x;
}查找函数
//遍历一边当前的有效数据。
//找到了返回下标,没找到(遍历完)返回一个负数,这里是为-1;
int SLFind(SL* ps, SLDataType x)
{
assert(ps);
int i = 0;
for (i = 0; i < ps->size; i++)
{
if (x == ps->arr[i])
{
return i;
}
}
return -1;
}源代码
seqlist.h
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLDataType;
//动态顺序表
typedef struct SeqList
{
SLDataType* arr;
int size; //有效数据个数
int capacity; //空间大小
}SL;
//typedef struct SeqList SL;
//顺序表初始化
void SLInit(SL* ps);
//顺序表的销毁
void SLDestroy(SL* ps);
void SLPrint(SL* ps);
//检查空间是否足够
void SLCheckCapacity(SL* ps);
//头部插入删除 / 尾部插入删除
void SLPushBack(SL* ps, SLDataType x);
void SLPushFront(SL* ps, SLDataType x);
void SLPopBack(SL* ps);
void SLPopFront(SL* ps);
//指定位置之前插入/删除数据
void SLInsert(SL* ps, int pos, SLDataType x);
void SLErase(SL* ps, int pos);
//修改函数,查找函数。
void SLModify(SL* ps, int pos,SLDataType X);
int SLFind(SL* ps, SLDataType x);seqlist.c
#define _CRT_SECURE_NO_WARNINGS 1 #include"seqlist.h" //顺序表的初始化 void SLInit(SL * ps) { ps->arr = NULL; ps->size = ps->capacity = 0; } //顺序表的销毁 void SLDestroy(SL* ps) { if (ps != NULL)//传入结构体指针不为空 { free(ps->arr);//释放动态开辟的内存 } //跟初始化操作一样。 ps->arr = NULL;//ps->arr记得原来开辟的起始地址,但现在已经回收内存,需要置空 ps->size = ps->capacity = 0;//当前的有效数据个数和总的数据大小归为0; } //遍历打印一遍顺序表,循环终止条件比较好理解就不赘述了。 void SLPrint(SL* ps) { assert(ps); int i = 0; for (i = 0; i < ps->size; i++) { printf("%d ", ps->arr[i]); } printf("\n"); } //尾插 void SLPushBack(SL* ps, SLDataType x) { //1.排除参数为空指针的情况 assert(ps); //2.检查空间是否足够 //没开辟空间(因为初始化时没给顺序表开辟空间) //当前开辟的空间满了,需要扩容。 //写一个检查空间并进行扩容的函数 SLCheckCapacity(ps);//后面会说 ps->arr[ps->size] = x; ++ps->size; } void SLCheckCapacity(SL* ps) { //检查该结构体指针是否为空 assert(ps); //没开辟空间和空间不够的条件是ps->size==ps->capacity; if (ps->size == ps->capacity) { //创建一个变量没开辟空间给一个初始的空间大小,否则增容到原来的两倍 int newCapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity; //1.既要能开辟空间又能增容的:realloc函数 //2.由于realloc函数可能会失败,返回NULL,创建临时变量存储并检测这个值是否为空指针。 SLDataType* tmp = (SLDataType*)realloc(ps->arr, newCapacity * sizeof(SLDataType)); //检测 if (tmp == NULL) { perror("realloc fail"); exit(-1);//异常退出。 } //开辟或者增容成功了. ps->arr = tmp; ps->capacity = newCapacity;//开辟或增容后空间大小要修改。 } } //头插 void SLPushFront(SL* ps, SLDataType x) { assert(ps); SLCheckCapacity(ps); //先让顺序表中已有的数据整体往后挪动一位 for (int i = ps->size; i > 0; i--) { ps->arr[i] = ps->arr[i - 1];//arr[1] = arr[0] } ps->arr[0] = x; ps->size++; } //尾删 //由于是删除数据,只需一个参数。 //执行删除操作时,顺序表要不为空表。 void SLPopBack(SL* ps) { assert(ps);//判断空指针 assert(ps->arr);//判断顺序表不为空表,即当前存在有效数据 --ps->size;//当前有效数据减一即可。 } //头删 // 由于是删除操作,只需传一个参数。 //只需第二个元素覆盖第一个元素,第三个覆盖第二个,从前往后依次。 void SLPopFront(SL * ps) { assert(ps); int i = 0; for (i = 1; i < ps->size; i++) { ps->arr[i - 1] = ps->arr[i]; //循环终止条件 //ps->arr[0]=ps->arr[1] //ps->arr[ps->size-2]=ps->arr[size-1]; } --ps->size;//由于每次删除一个数据,所以记得有效数据减少一。 } //在pos位置之前插入数据 //由于插入数据,要知道插入到数据是多少,所以需要传参。 //由于插入数据,要检查当前空间是否足够,需要调用SLCheckCapacity函数 //由于指定位置,要知道位置是多少,也需要传参,还需注意其合法性。 void SLInsert(SL* ps, int pos, SLDataType x) { assert(ps); assert(pos >= 0 && pos < ps->size); SLCheckCapacity(ps); int i = 0; for (i = ps->size; i > pos; i--) { ps->arr[i] = ps->arr[i - 1]; } ps->arr[pos] = x;//在指定位置之前插入,即该位置放新数据,原来的位置及之后的数据整体往后挪。 ps->size++;//插入了一个元素,有效数据加一。 } //由于删除数据,对比插入数据,就只要两个参数 void SLErase(SL* ps, int pos) { assert(ps);//空指针 assert(pos >= 0 && pos < ps->size); //不用检查空间 int i = 0; //跟处理头删一样,但这次位置不是0了。 for (i = pos; i < ps->size - 1; i++) { ps->arr[i] = ps->arr[i + 1];//最后一次循环,ps->arr[ps->size-2]=ps->size[ps->size-1] } --ps->size; } void SLModify(SL* ps, int pos, SLDataType x) { assert(ps); ps->arr[pos] = x; } //遍历一边当前的有效数据。 //找到了返回下标,没找到(遍历完)返回一个负数,这里是为-1; int SLFind(SL* ps, SLDataType x) { assert(ps); int i = 0; for (i = 0; i < ps->size; i++) { if (x == ps->arr[i]) { return i; } } return -1; }
test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"seqlist.h"
void SLTest(void)
{
SL s;
//初始化
SLInit(&s);
//自己测试各个函数逻辑是否正确。
//顺序表的销毁
SLDestroy(&s);
}
int main()
{
SLTest();
return 0;
}
尾声
数据结构篇其一---顺序表,结束!