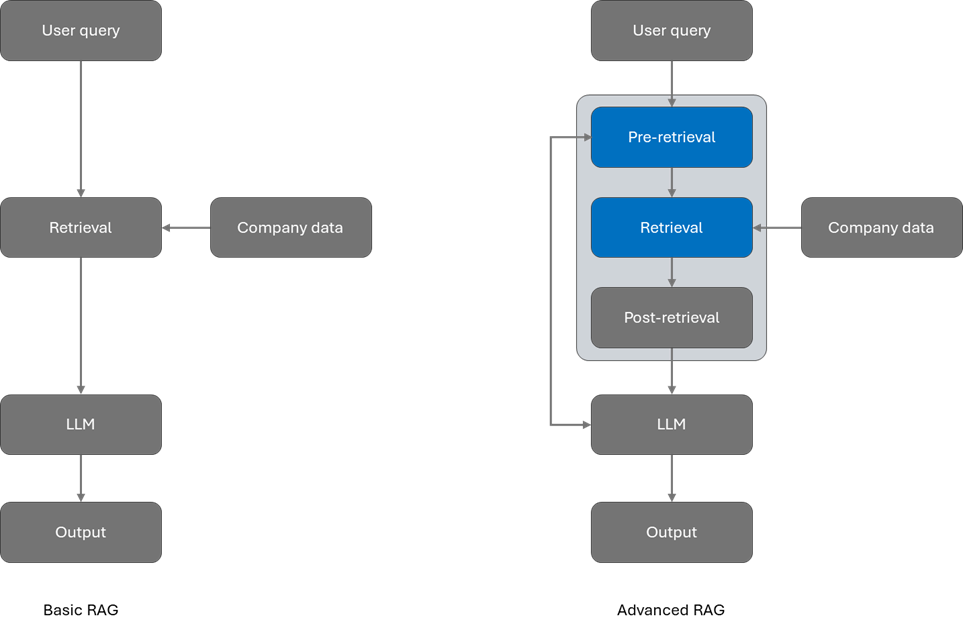
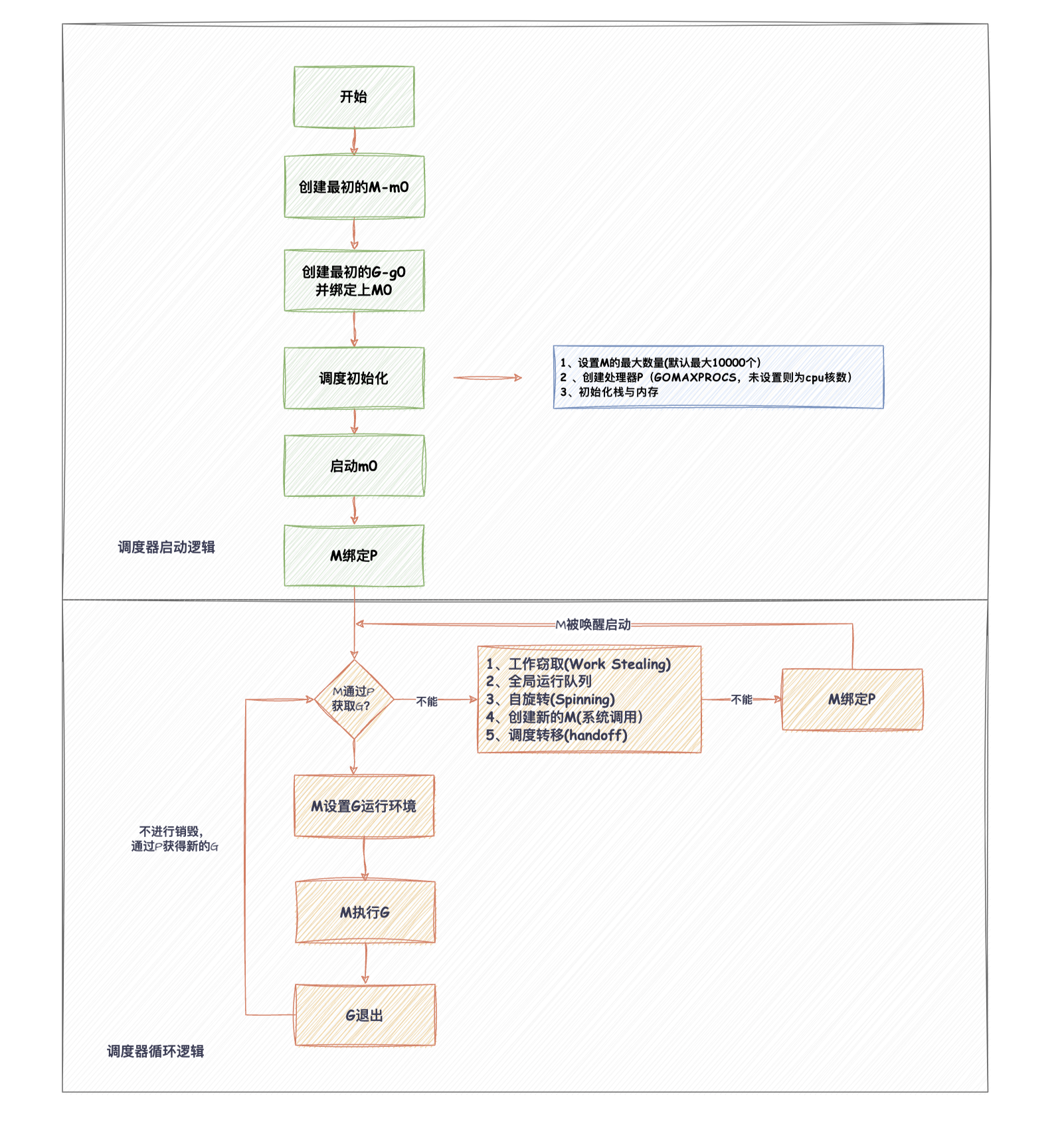
1.Calcite介绍
Calcite是一个动态数据库管理框架,具备数据库管理系统的功能
Calcite具备SQL解析、校验、优化、生成、连接查询等功能
Calcite能够为不同平台和数据源提供统一的查询引擎
2.Calcite能力
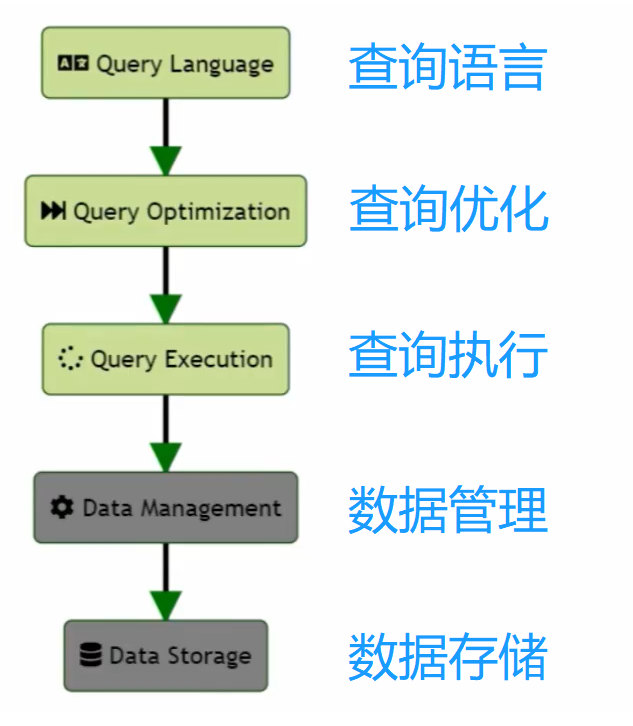
比如,对于HBase而言,没有SQL查询的能力,但是具备数据管理和数据存储的能力
对于ES而言,它也不具备SQL查询的能力,但是具备数据管理和数据存储的能力
也就是说,对于常见的数据库管理系统,都会具备(上图中灰色部分)数据管理和数据存储的能力,可能不具备SQL查询的能力。
可以通过Calcite为它们赋予SQL查询的能力,Calcite具备(上图中绿色部分)查询语言、查询优化、查询执行的能力。
Calcite在设计之初就确定了只关注和实现上图中绿色部分,而把灰色部分留给了各个外部的存储引擎和计算引擎。
由于数据的多样性,通常灰色部分是比较复杂的,Calcite抛弃了灰色部分,更加专注地实现上层通用的模块。
3.Calcite核心功能
完整的数据库管理系统分为 查询语言、查询优化、查询执行、数据管理、数据存储 5个模块
Calcite专注于实现上层3个通用模块
Calcite功能模块的划分足够合理、独立,使用时不需要完整集成3个模块,可以单独引用某一个模块
4.Calcite集成

上图展示了不同大数据框架对Calcite的引用情况
对Hive而言,Hive的 JDBC Driver 和 SQL Parser and Validator 都是自己实现的,只用到了Calcite的优化模块 Relational Algebra
对Flink而言,FlinkSQL的 JDBC Driver、SQL Parser and Validator、 Relational Algebra 都使用了Calcite进行实现
5.Calcite特性
支持标准SQL语言,可以通过自定义语法兼容多种特殊引擎语法
通过适配器,可以支持连接任何数据源
支持对SQL进行解析,并进行优化
支持物化视图
支持流式查询
6.SQL引擎之旅
提交一条SQL查询后,SQL会经历怎样的处理流程呢?
会经历 解析 -> 校验 -> 优化 -> 执行

Parser:Calcite通过 Java CC 将 SQL 解析成未校验的抽象语法树AST
Validate:检验Parser产生的抽象语法树是否合法,如验证 结构Schema、字段Field、函数是否存在、格式是否正确,验证完成之后生成逻辑执行计划RelNode树
Optimize:优化逻辑执行计划RelNode树,优化主要分为两类:RBO和CBO,优化后将其转换为物理执行计划
Execute:将物理执行计划转换成为特定平台的执行程序
7.Calcite相关组件
Catalog:定义SQL语义相关的元数据和命名空间,其实就是表和字段的一些元数据信息
SQL Parser 解析器:解析SQL,将其转换为抽象语法树AST
SQL Validator 校验器:通过Catalog里面存储的元数据信息,来校验抽象语法树AST,验证抽象语法树所查询的表、字段是不是存在
Query Optimizer 优化器:将抽象语法树转换为逻辑执行计划,并对其进行优化
SQL Generator 生成器:反向将执行计划转换为SQL语句 或 其他执行程序
8.Calcite架构图
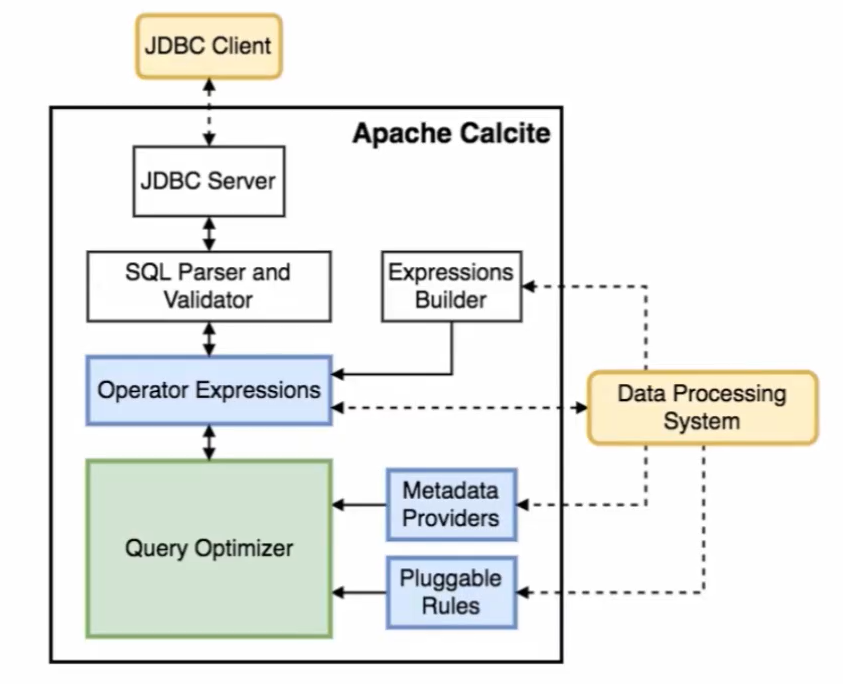
Operator Expressions <—> Query Optimizer:接受原始的查询计划,输出优化后的查询计划
Metadata Providers:提供元数据,元数据就是一些Catalog信息。
提供的不是校验SQL需要的库、表、字段、Schema信息,而是是针对优化规则所需要用到的统计信息,比如表里面有多少个分区,表数据有多少个行,表的数据量有多少
Pluggable Rules:优化规则
根据统计信息和优化规则运用关系代数,关系演算这些等价关系,进行执行计划的优化
虚线:Calcite可以扩展的部分,可以与外部系统进行连接
桔色框:可以理解为外部系统,桔色框与蓝色框有虚线的连接,也就是说,桔色框可以扩展三个蓝色框,能够为优化器提供更加准确的元数据信息,更加符合的优化规则,来利用Calcite优化器产生最优的查询计划
以Hive为例,Hive只用了Calcite的优化能力,Hive MetaStore作为元数据的提供方,Hive为Calcite优化器提供了自己外部的元数据,优化规则,以及生成的Operator Expressions
这张架构图从上往下,就可以与SQL的处理流程关联起来:
- 用户通过JDBC Client提交一条SQL
- Calcite首先对SQL进行解析和验证,将SQL转换为抽象语法树
- 将抽象语法树转换为逻辑执行计划,在图中表现为Operator Expressions
- 优化器根据生成的逻辑执行计划和外部提供的统计信息、优化规则,对逻辑执行计划进行优化,生成性能比较好的逻辑执行计划
- 转换为物理执行计划
从图中可以看出,Calcite最核心的部分就是优化器,优化器需要三部分的输入,分别为优化前的逻辑执行计划、统计信息、优化的匹配规则
Calcite内置了上百种优化规则来对关系表达式进行优化,同时也支持自定义一些优化规则
9. Calcite集成
Calcite的使用非常灵活,可以使用Calcite的全部功能,也可以使用Calcite的部分功能。比如可以只使用Calcite的解析功能,或者只使用Calcite的优化功能,所以对于Calcite的使用一般有这两种场景:
- 使用Calcite的全部功能

在这张图中,Calcite作为独立运行的进程,后台通过适配器与外部存储系统进行连接,前台通过JDBC接口,使用SQL语言和用户进行交互
在这个场景中,Calcite作为一个中间件,为一些没有或缺乏SQL查询语言的存储系统,比如HBase,Kafka,ES,Redis等,提供SQL查询语言
Calcite可以在内部将用户提交的查询进行优化,运行在自己的进程里面,在优化的过程中,将用户的查询转换成对应数据存储所需要的查询,下推到对应的数据系统进行查询,查询完成之后再将查询结果返回给用户
- 使用Calcite的部分功能
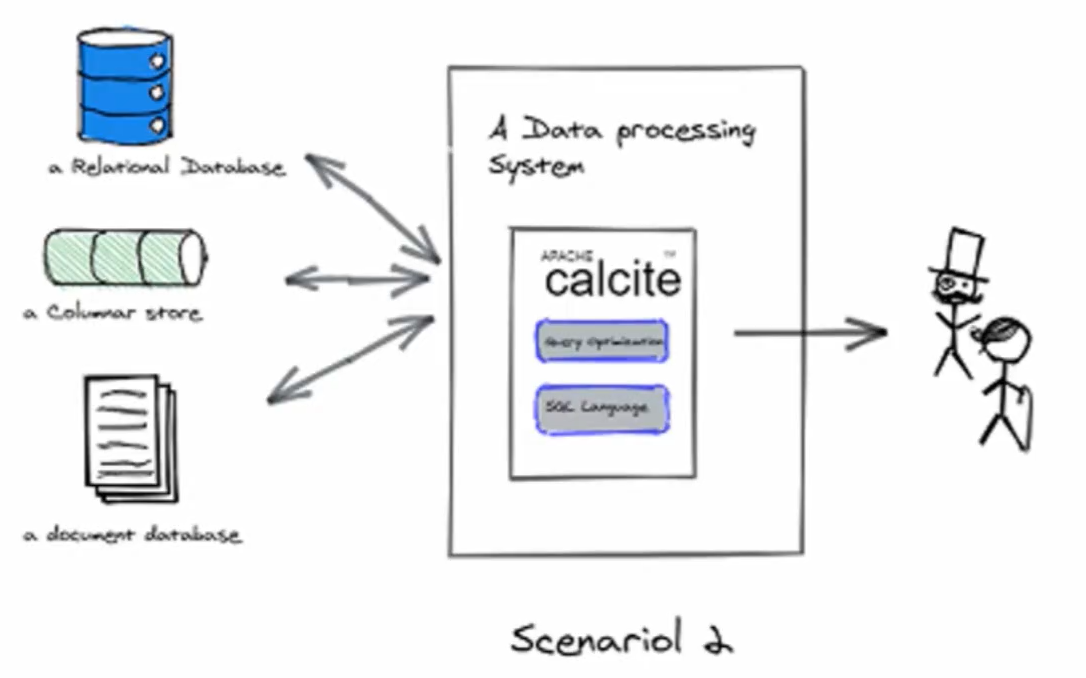
Calcite作为一个嵌入式的组件运行在查询引擎里
可以看到图中,中间是一个数据处理系统,它只应用了Calcite的一个或两个核心功能,查询引擎自己连接后台的数据源,使用自己的集群,用分布式的形式去进行查询,也就是说,查询引擎能够自己获取数据和执行查询,它只需要Calcite来提供查询语言和优化查询的能力,比如Hive、Spark、Flink等等
以Flink为例,Flink有多种算子,可以连接多种异构的数据源,用于数据的获取,Flink自己就是一个计算引擎,能够自己去读取数据,计算数据,Flink有丰富的算子可以将数据进行过滤,放大,缩小,变形等,用于各种各样的计算需求
但是它需要一种对用户友好的,对于流批数据语义统一的查询语言,便于用户来编写查询,所以引入了Calcite,通过Calcite,将SQL转换成执行计划,转换成Flink的作业图,让用户的SQL以最小的代价运行在Flink的集群中
这种场景是Calcite最受欢迎,最擅长的场景。相比于连接数据源,Calcite更擅长的是制造查询语言,解析查询,查询优化

上图就是在第二种集成场景下,Calcite和Data processing System的交互过程:
- 用户提交一条SQL,SQL经过Calcite进行处理,生成逻辑执行计划
- 对执行计划进行优化,优化就要依赖于计算引擎提供的一些信息,包括新算子替换、优化规则、元数据,通过这三类数据结合Calcite本身的优化能力,产出优化后的逻辑执行计划
- 转换为计算引擎支持的查询步骤,对数据进行查询
计算引擎只引用了Calcite对SQL处理的能力
10. SQL解析
SQL解析包含三个过程:词法分析、语法分析、输出抽象语法树
SQL解析是将一个输入的字符串,变换成描述这个字符串的“结构体”,这个结构体是能够准确被计算机识别的
- 词法分析

-
词法分析就是按照定义好的词法,将输入的字符集转换为单词
-
先对待解析的格式进行初始的定义,比如,abc认定为标识符,'abc’认定为字符串,123认定为数值,select、from认定为关键字
-
根据规定好的初始定义,将SQL转换成对应的词法:
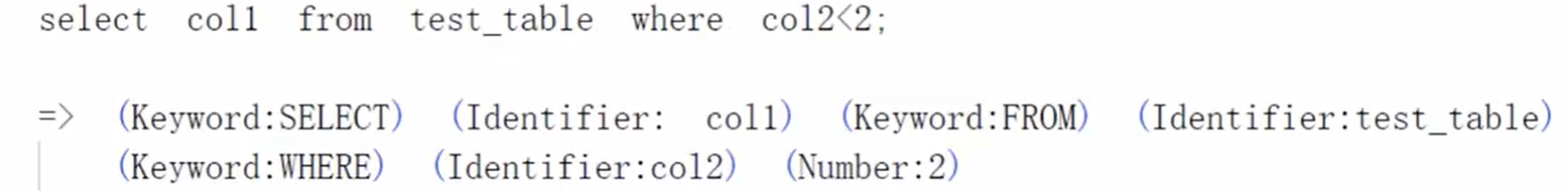
- 语法分析
经过词法解析,得到了一系列的单词,得到单词后,就可以进行语法分析了
也就是说,词法分析的结果作为语法分析的输入,语法分析在词法分析的基础之上,来判断用户输入的单词是不是符合语法的逻辑
语法分析之后得到抽象语法树,抽象语法树是用户输入SQL语句的树形表现形式
树上的每一个节点,都是词法分析的一个单词,树的结构体现了语法
抽象语法树是随语法分析过程构造的,当语法分析正常结束以后,语法分析器就会输出一颗抽象语法树,用户的输入和抽象语法树的结构是一一对应的
自此,用户输入的SQL也就会变成一个结构体,也就是抽象语法树,如下图所示:

- 语义分析
接下来,就可以根据生成的抽象语法树来理解SQL想要干什么,语义分析是SQL解析当中最为复杂,最有难度的一步,涉及到SQL的标准、SQL的优化等等。如果想要转换为MapReduce程序,还需要理解MapReduce相关的概念
SQL的语义分析分为两大块:逻辑分析,物理分析
逻辑分析基本上是一个纯代数的分析过程,与底层的分布式环境无关
物理分析是将逻辑分析的结果进行一些变换,与底层的执行环境有密切的关系
SQL执行顺序(面试常见),如图所示,按照标号顺序执行:
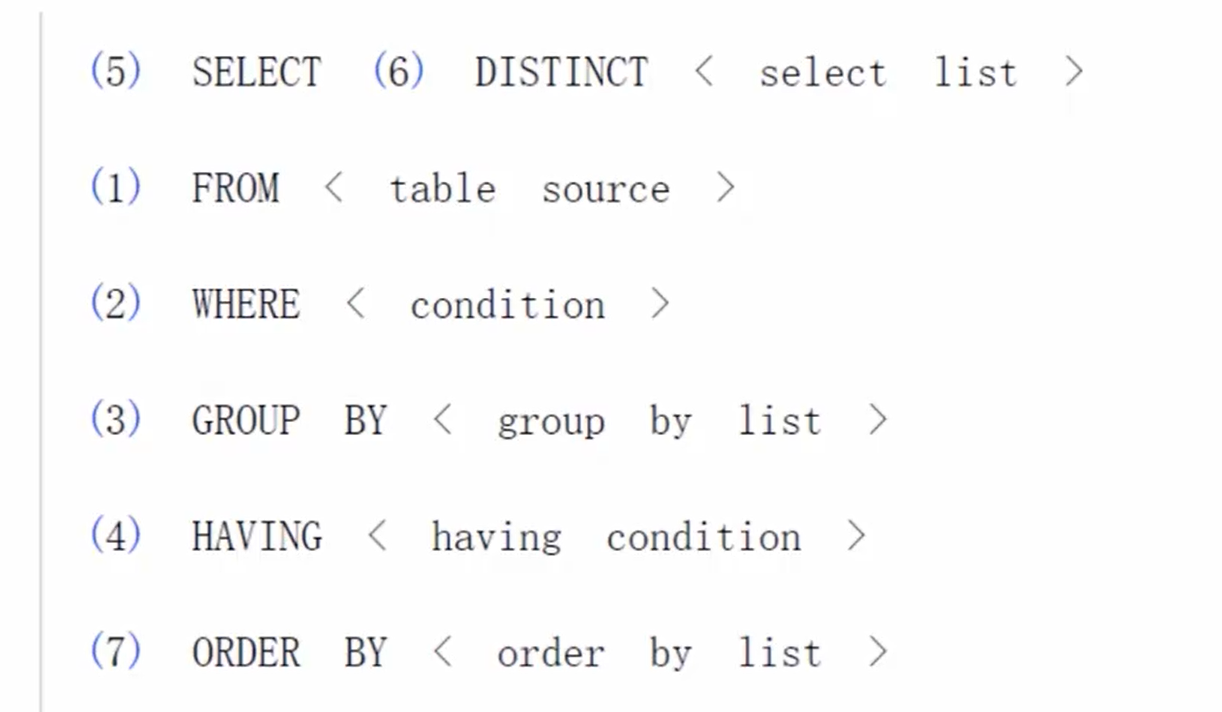
- 逻辑执行计划
SQL算子是SQL执行时不可拆分的单位

语义分析会根据抽象语法树及元信息构建 RelNode 树,也就是最初版本的逻辑查询计划
(RelNode树就是逻辑查询计划。RelNode树是由一系列RelNode节点组成的树状结构,每个RelNode节点表示一个逻辑操作,如扫描表、投影、过滤等。RelNode树描述了查询的逻辑结构)
一个逻辑查询计划实际上就是由这些查询算子组成的有向无环图。在这个有向无环图中,每一个算子都描述了SQL操作中的不同动作,由算子组成的有向无环图描述了数据流的方向
11.SQL优化
- 优化逻辑执行计划
优化方式分类:
RBO:基于规则优化。基于已经制定好的优化规则,对关系表达式进行转换,生成最优的执行计划。是一种经验式的优化方法
CBO:基于代价优化。根据优化规则对关系表达式进行转换,生成多个执行计划,根据统计信息和代价模型计算出每个执行计划的代价,从中挑选代价最小的执行计划作为最终的执行计划
CBO明显优于RBO,因为RBO只认规则,对于数据并不敏感。在实际中,数据的量级会严重影响同样SQL的性能,所以仅仅通过RBO生成的执行计划很有可能不是最优的
而CBO依赖于统计信息和代价模型,统计信息的准确与否,代价模型是否合理,都会影响CBO选择最优的执行计划
新的优化方式:
动态CBO:在执行计划生成的过程当中,根据下一步代价动态优化
随着大数据技术的发展,静态CBO没有办法满足优化的需要了,因为静态的统计信息没有办法提供准确的参考。在执行计划生成的过程当中,动态地进行统计才能得到最优的执行计划
优化规则
无论RBO还是CBO,实际上都是对逻辑执行计划应用一些优化规则。通过优化规则对关系表达式进行等价转换,寻找最优的执行计划
常见的CBO优化规则有:列裁剪、投影消除、最大最小消除、谓词下推等
逻辑算子
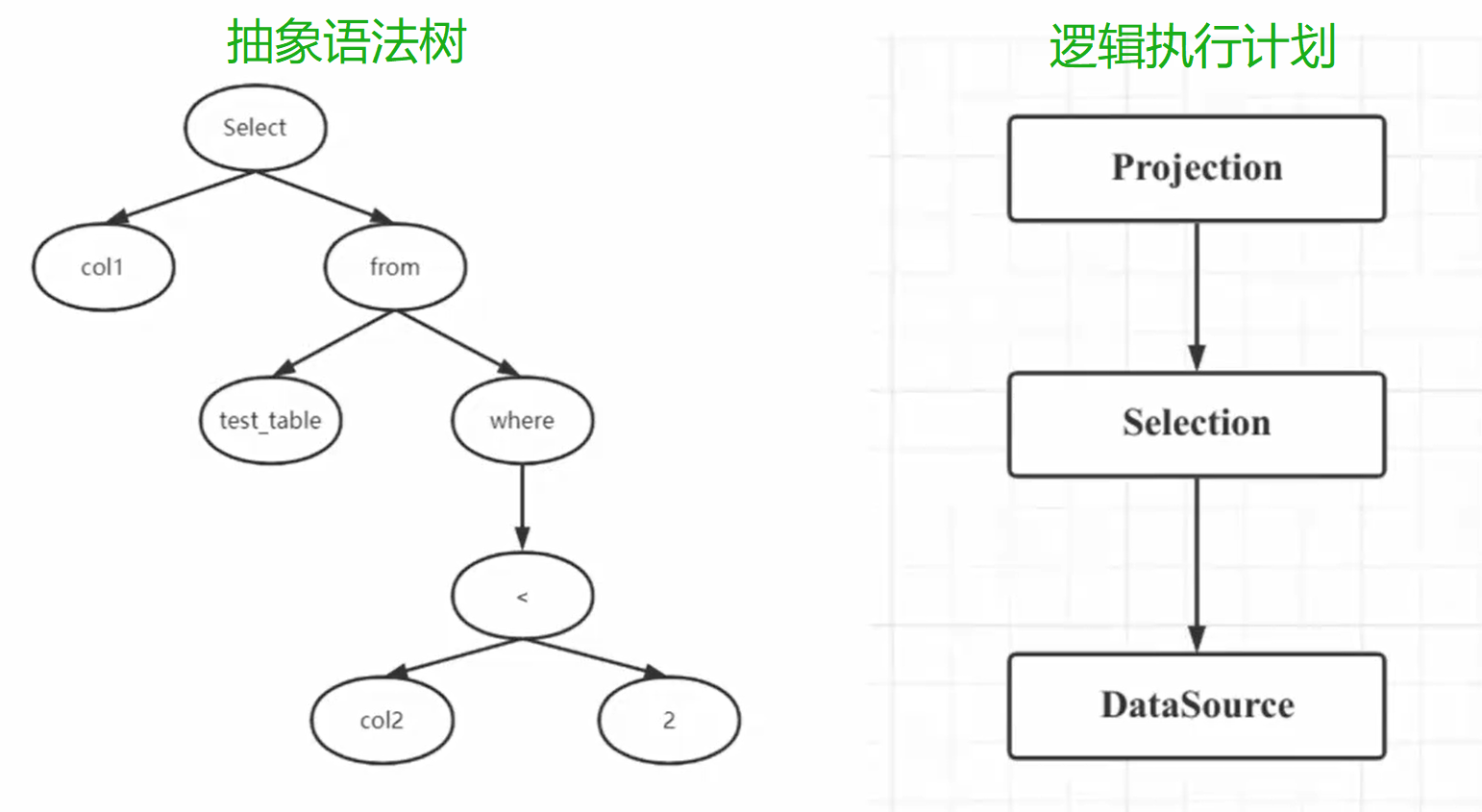
从上图可以看到,涉及到三个逻辑算子,分别是Projection、Selection、DataSource
DataSource:数据源,也就是SQL语句中的表
Selection:选择,where后的过滤条件
Projection:投影,指搜索的列
Join:连接,inner join、left join、right join等
Sort:排序,无序的数据通过这个算子处理后,输出有序的数据
Aggregation:聚合,按照某些列进行分组,进行一些聚合操作
物理算子
有逻辑算子,肯定就有物理算子,对应的就是物理执行计划
物理算子和逻辑算子的不同在于,一个逻辑算子可能对应多种物理算子
比如,Join的物理算子有Hash Join、MergeSort Join等。DataSource可以扫描全表,也可以利用索引读取数据。都对应着多个物理算子
数据查询慢,需要加索引,要确保逻辑查询计划所对应的物理查询计划要走我们加的索引,这样才能提高查询速度。
也就是说,DataSource逻辑算子生成物理执行计划的时候,对应的物理算子要走索引才行
12.RBO优化规则
- 列裁剪
对于没有用到的列,没有必要读取它们的数据去浪费IO。列裁剪通过只读取需要的数据减少IO操作来达到优化的目的
列裁剪的算法就是自顶向下遍历一遍所有的算子,
某个算子需要用到的列=自己需要的列+父节点需要的列
这样就可以得到整个SQL语句需要的列,读取数据的时候只读取需要的列即可
- 投影消除
投影消除是把不必要的Projection给消除掉
Projection算子投影的列跟子节点的输出列一样,那么这个投影操作就可以消除
例:select a,b from t1
如果t1中只有a,b两列,也就是如果DataSource的输出和它上层的Projection算子需要投影的列是一样的,执行TableSCAN之后就没有必要再做一次Projection操作了,上层的Projection是可以被消除掉的
如果Projection的子节点还是Projection,那么可以被消除
例:select a from(select a,b,c from t1)t2
这条语句有两个Projection,分别是最上层的Projection,只含有a一列,它的子节点Projection,含有a,b,c三列
Projection a,b,c就是一个废操作,可以被消除掉
- 常量折叠和常量传播
常量折叠:编译优化时,能够计算出结果的表达式替换为常量
例:select * from t1 where a>3+5
3+5可以由常量进行替换,替换成a>8
常量传播:编译优化时,将能够计算出结果的变量替换为常量
常量折叠处理不了变量被多次赋值的情况
例:where a>5 and a<4
我们一眼就能看出来,上述情况不存在,但没有经过优化的SQL会进行全表的扫描,所以需要对它进行处理,对a>5和a<4进行条件常量传播,消除无用的节点,判断是否存在结果
- 谓词下推
将外层查询where子句中的谓词移入到所包含的较低层次的查询块,提前进行数据过滤,更好的使用索引
例:
select *
from t1,t2
where t1.a > 3
and t2.b > 5
假设t1表和t2表都有100条数据,如果不进行谓词下推,就需要把t1表和t2表做笛卡尔积,再根据条件进行过滤。如果进行谓词下推,则是先过滤数据,再做笛卡尔积
尽量把过滤条件下推到子节点上,这样可以避免访问很多的数据,达到优化效果
对于DataSource算子,就直接将过滤条件推给各个DataSource算子。对于Join算子,收集连接的条件,区分出哪些是来自于左节点,哪些是来自右节点,将这些条件分别向左右节点进行下推
谓词下推也是有边界的,不能一直对谓词进行下推,不能推过limit节点。先Selection后limit n 和 先limit n后Selection的结果是不一样的
13.SQL优化执行过程
- RBO执行过程
Transformation:遍历关系表达式,满足特定的优化规则进行转换
Build Physical Plan:把优化过的逻辑执行计划转换成物理执行计划
- CBO执行过程
Exploration:根据优化规则进行等价转换,生成多个逻辑执行计划
Build Physical Plan:生成多个物理执行计划
Find Best Plan:计算各个物理执行计划的Cost,选出Cost最小的执行计划
- 动态CBO
CBO:先生成执行计划,后统计代价
动态CBO:边生成执行计划,边统计代价
14.CBO核心步骤
- 采集数据源的基本信息:包括表级别指标和列级别指标
每个节点输出的数据大小、数据条数、数据类型、数据分布,这是表级别指标
列的类型,以及每一列的最大值,最小值,每一列的长度,这是列级别指标
通过采集这些指标来计算每个算子的代价,去评估到底需要耗费多少资源
支持CBO的系统一般都实现了相关信息统计的方法,如Hive Matastore
如orc列式存储格式也存储了统计信息
- 定义核心算子的基数推导规则:根据统计信息预估节点代价
推导规则是在当前子节点的统计信息基础之上,来计算父节点相关统计信息,对于不同的算子,推导规则肯定是不一样的。根据表级别的指标和列级别的指标做一个预估,进行代价的计算
- 核心算子实际代价计算:从 CPU Cost 和 IO Cost 两方面分析实际代价
根据统计信息和推导规则所预估出的数据的条数,数据的大小,数据的分布等,来计算出各个执行计划执行的成本,执行成本就从CPU和IO两个维度进行体现
- 选择最优的执行路径:根据计算代价选择最优的执行路径
实际选择的并不一定是代价最小的执行路径,原因是可执行的执行路径太多了,如果把所有的路径都计算一遍,需要耗费大量的时间,SQL的优化也就没有意义了
CBO就是选择一条相对稳定而且代价较小的执行路径,这样就能在很短的时间内,达到SQL的优化目的


![[Rust开发]在Rust中使用geos的空间索引编码实例](https://img-blog.csdnimg.cn/img_convert/dd69614c137cedd7ebf831ae232263e8.png)