文章目录
- PromptSync: Bridging Domain Gaps in Vision-Language Models through Class-Aware Prototype Alignment and Discrimination(2024CVPR)
- 1 Introduction
- 2 Related Work
- 2.1 CLIP
- 2.2 TPT
- 3 Methodology
- 3.1 提出方法PromptSync
- 3.2 类感知原型生成(视觉原型?语言原型?)
- Q:为什么不包括class token?
- 3.3 原型判别损失
- 3.3.1 正对样本损失
- 3.3.2 负对样本损失
- Q:为什么不用计算𝑐𝑘的增强视图和其他所有类别增强视图的相似度?
- 3.3.3 最终的优化目标
- 3.4 原型对齐损失
- 3.4.1 振幅对齐损失
- 3.4.2 角度对齐损失
- 3.4.3 合并
- 3.5 算法的细节
- 3.5.1 计算原型判别损失
- 3.5.2 测试时间适应过程
- 3.5.3 多次迭代更新
- 4 实验
- 4.1 baseline对比
- 4.2 实施细节
- 4.3 领域泛化
- 4.4 Base to Novel
- 4.5 跨数据集转移性能
- 5 消融实验
- 6 性能和延迟
- 7 敏感性比较
- 8 LAION400M代理数据集分析
- 9 Conclusion
- TPT(2022 NeurIPS)
- PromptAlign(2023 NeurIPS)
PromptSync: Bridging Domain Gaps in Vision-Language Models through Class-Aware Prototype Alignment and Discrimination(2024CVPR)
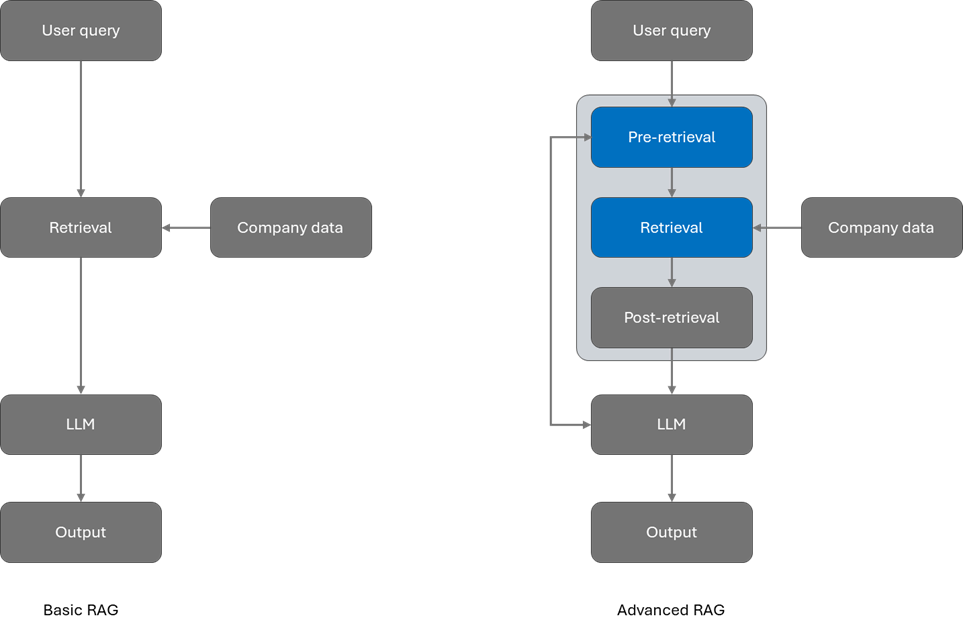
- 提出类别级的原型对齐方法,将每个测试样本与源分布对齐,减轻类间分布迁移的影响
- 我们在文本和视觉分支上都进行了提示调整
- 将测试样本的原型与预先计算的类原型对齐
- 按照从增强视图中获得的每个类的平均概率加权来调整可学习的提示令牌
1 Introduction
- 提出了一种面向类别的原型对齐技术,用于对齐每个测试样本的上下文与类别源分布基础上,从而减轻类别之间的分布偏移效应。
- 提出了面向类别的原型判别,以发现有效对齐的类别分布。此外,我们还提出了从代理源数据集进行类别原型的离线计算,用于基础V-L模型。
- 提出了针对文本和视觉分支的多模态测试时提示调整。基于从基础到新颖的泛化、领域泛化以及跨数据集转移的实证评估显示了我们方法的效率高于现有方法。

2 Related Work
clip里面取max,PromptSync变成了取平均?
2.1 CLIP

- Clip测试阶段,图像特征与文本特征做余弦相似度计算,相似度最大的即为对应的类别。
2.2 TPT

- 在过滤后的增强视图上,模型产生的向量类概率的平均值,即为平均类概率,平均类概率作为权重,对齐类原型与过滤增强试图。
3 Methodology
3.1 提出方法PromptSync
3.2 类感知原型生成(视觉原型?语言原型?)
代理数据集:用于训练模型的数据集,在本文中指定了代理数据集
原型:对于每个类别原型,定义为该类别所有样本特征向量的平均值
生成类感知原型:

- h x t h_x^t hxt:样本x在文本t上的原型向量
- h x v h_x^v hxv:样本x在视觉v上的原型向量
- h C L S , x v h_{CLS,x}^v hCLS,xv:样本x在视觉v上 [CLS] token的原型向量
- ET (x, ei):样本x的第i个token在文本编码器T的输出
- EV (x, ei):样本x的第i个token在图像编码器V的输出
- P=所有tokens的数量(包括可学习、不可学习、文本、图像)(不包括SOS、EOS、CLS)
- token:文本数据中的基本单元,通常是一个词或一个字符,每个token都会被映射成一个对应的向量表示,向量表示了token的语义信息。

Q:为什么不包括class token?
在文本原型计算时,每个类别计算都去掉了SOS、EOS、CLS,用的是(t1、t2、…、tL),那计算出来的文本原型,都是一样的?
3.3 原型判别损失
训练可学习提示,使用对比学习的方法,拉近同一类别样本在嵌入空间中的距离,将不同类别的样本推开,实现更好的样本分类和原型分布
3.3.1 正对样本损失

L
p
o
s
(
c
k
)
\mathcal{L}_{pos}(c_k)
Lpos(ck) :正对样本positive的损失,拉近同类别原型和增强视图
计算了每个增强视图𝑎𝑢𝑔与类别 𝑐𝑘的原型向量 ℎ𝑐𝑘𝑚之间的相似度,将相似度值取指数,进行加权平均
3.3.2 负对样本损失

L
n
e
g
(
c
k
)
\mathcal{L}_{neg}(c_k)
Lneg(ck) :负对样本negative的损失,推开不同类别原型和增强视图
分成三部分
- 𝑐𝑘原型向量和其他所有类别原型向量hcm的相似度
- 𝑐𝑘的增强视图和其他所有类别的原型向量hcm的相似度
- 𝑐𝑘原型向量和其他所有类别增强视图的相似度
Q:为什么不用计算𝑐𝑘的增强视图和其他所有类别增强视图的相似度?
3.3.3 最终的优化目标


L D \mathcal{L}_{D} LD :正对样本损失和负对样本损失的比率的负对数,即最终的优化目标
- 最小化ld,即为最大化求和的部分
- 最大化lpos(拉近本身与增强图像的相似度)
- 最小化lneg(减小本身与其他类别的相似性)
3.4 原型对齐损失
- Ld能够有效区分不同的类别,但无法调整测试样本的提示
- 提出测试样本及其增强视图,与源分布中类原型的对齐
- 对于每个测试样本𝑥𝑖,以及每个类别𝑐,计算测试样本𝑥𝑖的原型
- p x i m p_{xi}^m pxim与类别𝑐的类原型 𝑝𝑐𝑚之间的振幅对齐损失和角度对齐损失
- pˆp[c] :测试样本最可能的类别,均值概率,作为LA的权重,作者后面会讲到
3.4.1 振幅对齐损失
测试样本的原型与类原型之间的距离

3.4.2 角度对齐损失
测试样本的原型与类原型之间的角度相似度

我们要最大化他们的角度相似度,因此最大化L’ang
3.4.3 合并
在计算损失时,均方误差损失对于一定范围内的误差增加会给予相等的惩罚,而我们希望在小范围内的误差增加时给予更大的惩罚,因此作者将损失取对数。


其中,最大化角度相似度,因此最大化L’ang,最小化Lang

3.5 算法的细节
3.5.1 计算原型判别损失
在源数据集上计算原型判别损失需要使用 CLIP 模型的预训练数据集,CLIP 模型是在超过 4 亿个图像文本对上进行训练的,数据不公开可用。因此,为了近似源数据集,作者选择使用了 ImageNet 数据集。在 ImageNet 上计算出每个类别的原型,这些原型是离线计算的,包括了样本和其增强视图。
3.5.2 测试时间适应过程
在每次迭代的测试中
- 元训练阶段:使用原判别目标函数LD进行训练,计算梯度,得到更新后的提示
- 元测试阶段:使用更新后的提示,设置置信度阈值,过滤增强视图的预测概率,计算在F上的均值概率p,并作为LA中的权重。计算梯度。
- 计算梯度平均值,使用组合目标更新提示


3.5.3 多次迭代更新
n>1时,会累计平均梯度,然后进行最终的提示更新
4 实验
数据集:
- 作者在ImageNetV2、ImageNet-Sketch、ImageNet-A 和 ImageNet-R进行评估
- 还考虑了Photorealistic Unreal Graphics (PUG) 数据集(包括不同的纹理、大小、方向和背景)
- 对于跨数据集转移设置,作者考虑了10个不同的图像分类数据集,包括 Caltech 101、StanfordCars、Food101、Flowers102、FGVC-Aircraft、OxfordPets、SUN397、DTD、UCF101 和 EUROSAT
4.1 baseline对比
包括 CoOp、CoCoOp、TPT 、 PromptAlign、MaPLe
4.2 实施细节
- 在单个 NVIDIA A100 40GB GPU 上运行了所有实验
- 在 ImageNet 上进行了训练,使用随机选择的 16 张图像作为每个类别的训练数据
- 使用 2 个提示标记进行 3 层深度的训练
- 图像增强:使用随机裁剪、背景替换、水平翻转增强和视觉损坏,对每个测试图像进行了 127 个不同视图的增强
- 文本增强:作者使用了 WordNet 中的同义词、反义词和部分词
4.3 领域泛化

表1,对比了各种方法在不同数据集上的性能,平均值表示了对所有领域的平均性能。
表2中,着重比较了在领域泛化设置下针对分布对齐的性能,具体指标包括相机姿态、姿势、尺度、纹理、光照和世界。
4.4 Base to Novel

MaPLE+TPT后部分会下降
4.5 跨数据集转移性能

5 消融实验

表5,熵损失、对齐损失、判别损失的消融实验

表6,对齐损失的消融实验
6 性能和延迟

延迟:单个提示更新的时间(小时)
PromptSync*变体展示了更快的处理时间,而性能仅略有下降。这个结果强调了通过原型对齐实现的泛化。
7 敏感性比较

图2a,随着增强视图数量的增加,准确率上升
图2b,准确率随着提示更新步次数的增加而提高
8 LAION400M代理数据集分析
我们选择ImageNet作为可行的代理源数据集,使用LAION400M的子集
9 Conclusion
总之,PromptSync显著改善了视觉语言模型中的zero-shot泛化。我们的方法解决了类优势和方差问题,总体上比现有方法高出2.33%,在领域泛化基准上,从基础到新的泛化提高了1%,跨数据集传输提高了2.84%。这强调了PromptSync在增强视觉语言模型稳健性方面的有效性。
TPT(2022 NeurIPS)
imagenet里面没有的类别,怎么对齐?
PromptAlign(2023 NeurIPS)
多模态测试时间提示调优方法
将视觉分支中测试样本的令牌分布与完整代理源数据集的预计算统计数据对齐,而不考虑一个类分布可能具有与其他类不同的均值和方差。




![[Rust开发]在Rust中使用geos的空间索引编码实例](https://img-blog.csdnimg.cn/img_convert/dd69614c137cedd7ebf831ae232263e8.png)