首先,恭喜各位也恭喜自已学习爬虫基础到达圆满级,今后的自已python爬虫之旅会随着网络发展而不断进步。回想起来,我学过请求库requests模块、解析库re模块、lmxl模块到数据保存的基本应用方法,这一次的学习python爬虫之旅收获很多,也希望通过记录的方式一步一步的成长。
接下来我会根据我现有的理论体系来实战。不断突破境界
一般来说,我们在网络生活中都会在搜索引擎中会直接或间接的看到不同的社会内容,而爬取热搜榜下的内容通常会用在不同的创景,主要有以下作用:
- 市场分析:通过分析热搜榜,企业可以了解当前的热门话题和趋势,从而调整市场策略或推广活动。
- 社会研究:研究者可以利用热搜数据来研究社会动态、公众兴趣和行为模式3。
- 新闻机构:新闻媒体可以利用热搜榜快速捕捉热点新闻,及时报道。
- 数据可视化:通过数据可视化技术,将热搜数据以图表、散点图等形式展示,使信息更加直观易懂。
- 舆情监控:政府或企业可以监控热搜榜,及时了解公众关注的焦点,进行有效的舆情管理。
- 内容创作:内容创作者可以根据热搜榜上的热门话题创作相关内容,吸引更多的关注和流量。
- 学术研究:学者可以利用热搜数据进行语言学、传播学等领域的研究。
- 技术开发:技术人员可以通过实践爬虫技术,提升自己在网络编程、数据解析和自动化处理方面的能力。
第一步: 选定目标网站,分析网站的请求数据,目标网址为热搜榜

下图与上图都是出自同一处请求标头

可以得知上面的数据,我们可以直接构建和添加相应的代码如下
cookies = {
'Hm_lvt_1d9b8e4e110b54c48922093ef42f94fe': '1647522958', #跟踪用户会话状态,该值表示用户活动时间
'PHPSESSID': 'e5ne2vg34tkfkjseuduod1q5ss', #会话标识符,用于存储会话信息,如登录状态
'Hm_lpvt_1d9b8e4e110b54c48922093ef42f94fe': '1647523063', #跟踪用户会话状态,该值表示用户最后一次活动时间
'UM_distinctid': '17f9806e4e4886-0e3b4c1d996d63-977173c-1fa400-17f9806e4e535f', #用户唯一标识符,用于统计用户的访问次数
'CNZZDATA1278227787': '951014879-1647514960-%7C1647514960',#网站统计代码,用于统计网站的访问次数
}
headers = {
'Connection': 'keep-alive',#保持连接
'Cache-Control': 'max-age=0',#不缓存
'Upgrade-Insecure-Requests': '1',#允许https
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',#浏览器标识
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',#接受类型
'Accept-Language': 'zh-CN,zh;q=0.9',#语言
}
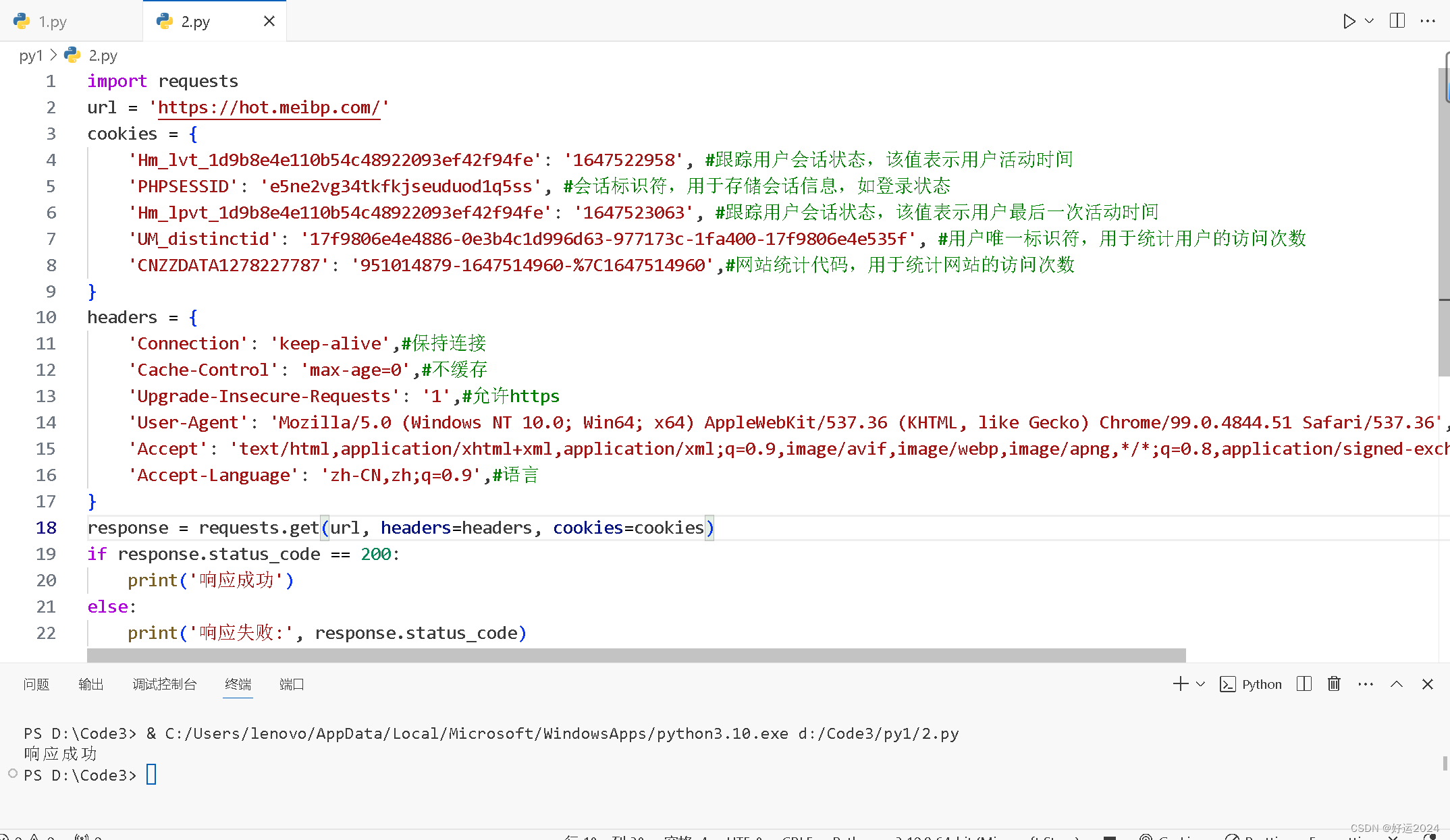
第二步:输出响应信息,以表明爬虫响应成功,代码如下
import requests
url = 'https://hot.meibp.com/'
cookies = {
'Hm_lvt_1d9b8e4e110b54c48922093ef42f94fe': '1647522958', #跟踪用户会话状态,该值表示用户活动时间
'PHPSESSID': 'e5ne2vg34tkfkjseuduod1q5ss', #会话标识符,用于存储会话信息,如登录状态
'Hm_lpvt_1d9b8e4e110b54c48922093ef42f94fe': '1647523063', #跟踪用户会话状态,该值表示用户最后一次活动时间
'UM_distinctid': '17f9806e4e4886-0e3b4c1d996d63-977173c-1fa400-17f9806e4e535f', #用户唯一标识符,用于统计用户的访问次数
'CNZZDATA1278227787': '951014879-1647514960-%7C1647514960',#网站统计代码,用于统计网站的访问次数
}
headers = {
'Connection': 'keep-alive',#保持连接
'Cache-Control': 'max-age=0',#不缓存
'Upgrade-Insecure-Requests': '1',#允许https
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',#浏览器标识
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',#接受类型
'Accept-Language': 'zh-CN,zh;q=0.9',#语言
}
response = requests.get(url, headers=headers, cookies=cookies)
if response.status_code == 200:
print('响应成功')
else:
print('响应失败:', response.status_code)
输出结果
第三步:分析网站页面结构,确认需要提取的数据元素为热搜类别、标题和链接
先确定热搜类别元素,图下

可以看到热搜类别在a元素中,但是我们选择的是多个类型的热搜,可以使用 XPath 语法来解析 HTML 文档,并从中提取特定数据的 Python 代码。构造代码如下
divs = html.xpath('//div[@class="items"]/div[@class="row"]/div')然后确定热缩类别下的信息和链接,图下

可以看到选中的页面元素在div元素下,其他热搜信息也都在相同的结构中,可以使用循坏遍历语句
第四步,构建代码
divs = html.xpath('//div[@class="items"]/div[@class="row"]/div')
for div in divs:
cat = div.xpath('./a/@title')
for a in div.xpath('./div/div/a'):
result = {
"热搜类别": "".join(cat),
"标题": "".join(a.xpath('./@title')),
"链接": "".join(a.xpath('./@href'))
}
print(result)第五,构建完整代码
import requests #导入requests模块
from lxml import etree #导入lxml模块
# 定义cookie
cookies = {
'Hm_lvt_1d9b8e4e110b54c48922093ef42f94fe': '1647522958',
'PHPSESSID': 'e5ne2vg34tkfkjseuduod1q5ss',
'Hm_lpvt_1d9b8e4e110b54c48922093ef42f94fe': '1647523063',
'UM_distinctid': '17f9806e4e4886-0e3b4c1d996d63-977173c-1fa400-17f9806e4e535f',
'CNZZDATA1278227787': '951014879-1647514960-%7C1647514960',
}
# 定义请求头
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
# 发送请求
response = requests.get('http://hot.meibp.com/', headers=headers, cookies=cookies, verify=False)
# 解析响应内容
html = etree.HTML(response.text)
# 定位到热搜列表
divs = html.xpath('//div[@class="items"]/div[@class="row"]/div')
# 遍历热搜列表
for div in divs:
cat = div.xpath('./a/@title') # 热搜类别
for a in div.xpath('./div/div/a'): # 热搜标题和链接
result = {
"热搜类别": "".join(cat),
"标题": "".join(a.xpath('./@title')),
"链接": "".join(a.xpath('./@href'))
}
print(result)输出结果

可以看到控制台输出信息成功
当然这个代码可以自行添加
import json
with open('data.json', 'w') as file:
file.write(json.dumps(result, indent=2))不过有时候做数据分析的时候,一般都是在目录文件下生成,所以我们可以通过接JSON和CSV文件组合使用,代码如下
import requests
from lxml import etree
import json
import csv
cookies = {
'Hm_lvt_1d9b8e4e110b54c48922093ef42f94fe': '1647522958', #跟踪用户会话状态,该值表示用户活动时间
'PHPSESSID': 'e5ne2vg34tkfkjseuduod1q5ss', #会话标识符,用于存储会话信息,如登录状态
'Hm_lpvt_1d9b8e4e110b54c48922093ef42f94fe': '1647523063', #跟踪用户会话状态,该值表示用户最后一次活动时间
'UM_distinctid': '17f9806e4e4886-0e3b4c1d996d63-977173c-1fa400-17f9806e4e535f', #用户唯一标识符,用于统计用户的访问次数
'CNZZDATA1278227787': '951014879-1647514960-%7C1647514960',#网站统计代码,用于统计网站的访问次数
}
headers = {
'Connection': 'keep-alive',#保持连接
'Cache-Control': 'max-age=0',#不缓存
'Upgrade-Insecure-Requests': '1',#允许https
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',#浏览器标识
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',#接受类型
'Accept-Language': 'zh-CN,zh;q=0.9',#语言
}
# 发送请求
response = requests.get('https://hot.meibp.com/', headers=headers, cookies=cookies, verify=False)
html = etree.HTML(response.text)
# 定位到热搜列表
divs = html.xpath('//div[@class="items"]/div[@class="row"]/div')
# 调整数据结构
rows = [] # 存储热搜数据
for div in divs: # 遍历每一个热搜
cat = "".join(div.xpath('./a/@title')) # 热搜类别
for a in div.xpath('./div/div/a'):
title = "".join(a.xpath('./@title')) # 热搜标题
link = "".join(a.xpath('./@href')) # 热搜链接
rows.append([cat, title, link])
# 将数据写入 CSV 文件
with open('data.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["热搜类别", "标题", "链接"]) # 写入表头
writer.writerows(rows) # 写入数据行
print("数据已成功写入 data.csv 文件")
输出结果

这样的话比较美观多了,引用数据比较方便。
好了,今日分享到此一游,我是好运,想要好运。