前言
sql查询速度比较慢容易成为性能瓶颈,这时我们可以优化我们的sql语句或数据库表
一般sql语句执行很慢的种类分为:
1.聚合查询
2.多表查询
3.表数据量过大查询
4.深度分页查询
这四种的前三种都可以通过优化sql语句来优化sql查询速度
正文
聚合查询
我们可以通过尝试新增一个临时表来解决
多表查询
可以试着优化sql语句的结构
表数据量过大查询
可以添加索引
出现回表查询
在业务允许的情况下只查询当前索引表中包含的字段(覆盖索引查询)来防止查询多个索引结构
超大索引查询
比如将
select * from tab limit 9999999,10;优化为
select * from tab t,
(select id from tab order by id limit 9999999,10) a
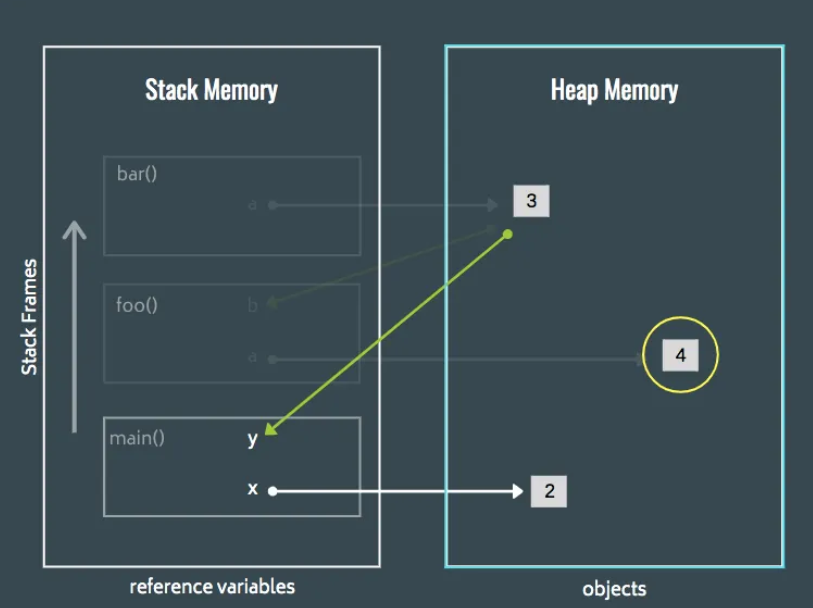
where t.id=a.id;这样先通过子查询拿到对应的id表a(覆盖索引查询),然后在通过主键查询,这样速度就会快一些
通过sql执行计划来分析并优化sql语句
我们可以给普通的sql语句前面加上desc来分析此sql语句的执行计划
执行结果如下:

possible_keys
表示当前sql中可能会使用到的索引(可能多个)
如果查询比较慢,且此值没有关联到索引,可以通过增加索引来优化查询速度
key
表示当前sql实际命中的索引
如果 possible_keys 不为 null 而 key 为 null, 则说明未命中索引,这时可以优化sql语句使其命中索引
key_len
表示索引占用的大小
key_len 和 key 可以看出是否命中了索引
Extra
额外的优化建议
type
表示这条sql的连接的类型
性能由好到差(性能好一般要在range及以上):
NULL: 表示查询的时候没有使用到表(项目中一般不会使用)
system: 查询mysql系统中自带的表(项目中一般不会使用)
const: 根据主键索引查询时(只会查询一条数据,性能好)
eq_ref: 根据主键索引或唯一索引查询时(只会查询一条数据)
ref: 使用了索引查询(可能查询出多条数据)
range: 使用了索引,但是是范围查询
index: 使用索引树扫描(全索引查询)
all: 全盘扫描(效率最低)
对Kotlin或KMP感兴趣的同学可以进Q群 101786950
如果这篇文章对您有帮助的话
可以扫码请我喝瓶饮料或咖啡(如果对什么比较感兴趣可以在备注里写出来)








![Navicat连接SQLSever报错:[08001] MicrosoftTCP Provider 远程主机强迫关闭了一个现有的连接](https://img-blog.csdnimg.cn/direct/3042b73736dc460eb532fe730002166b.png)