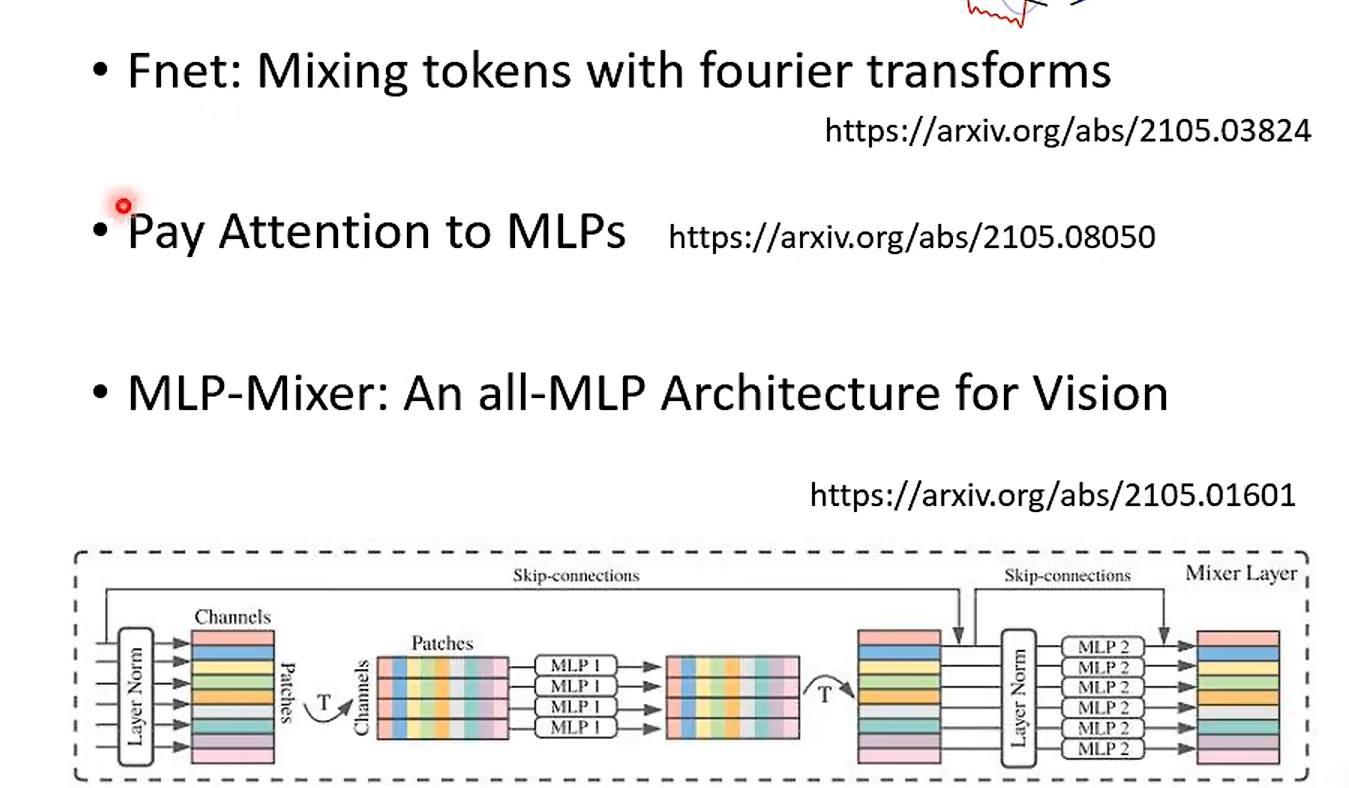
Day 23 Self - Atention 变形
关于很多个former 的故事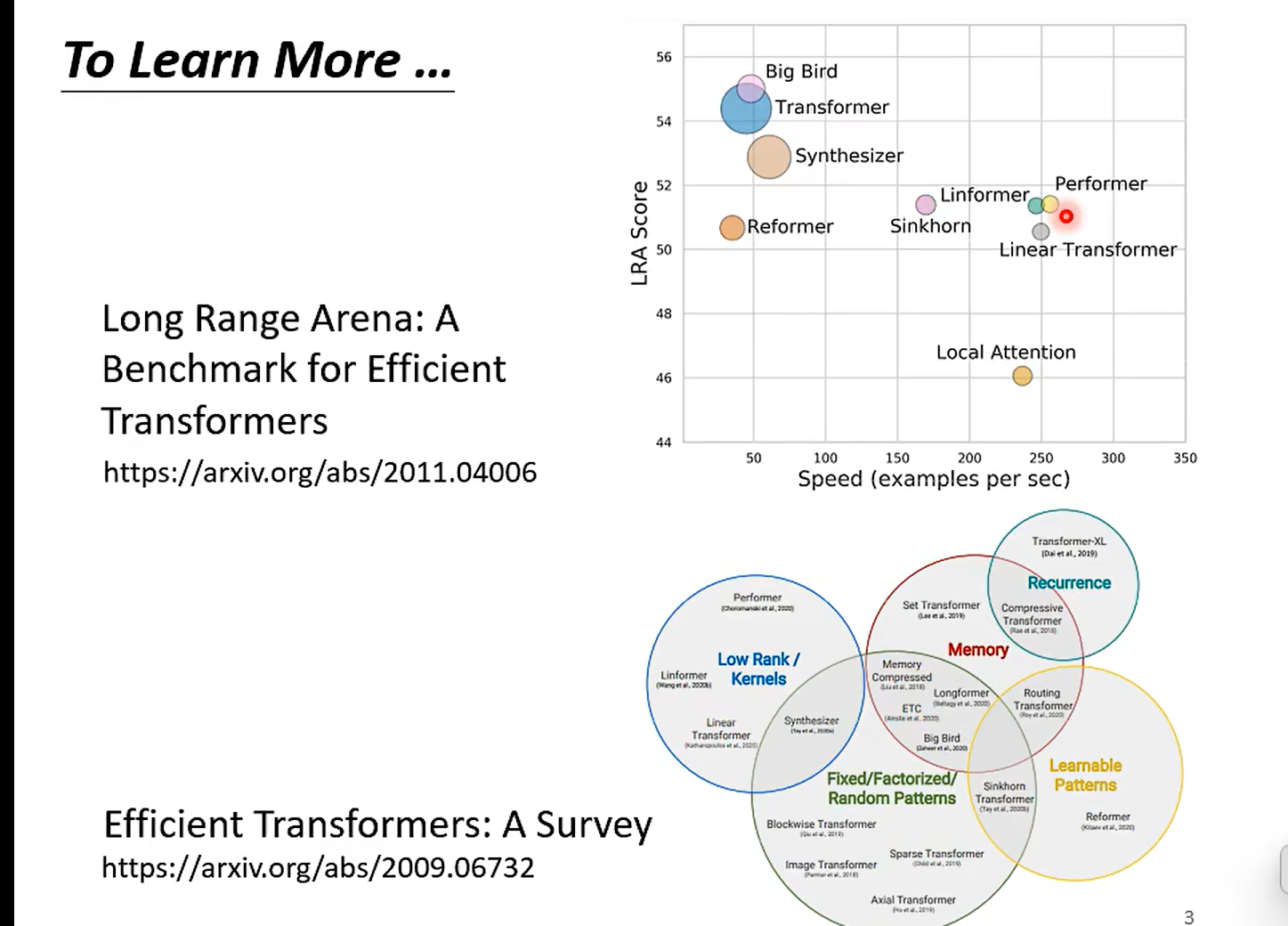
痛点:
在于做出注意力矩阵之后的运算惊人
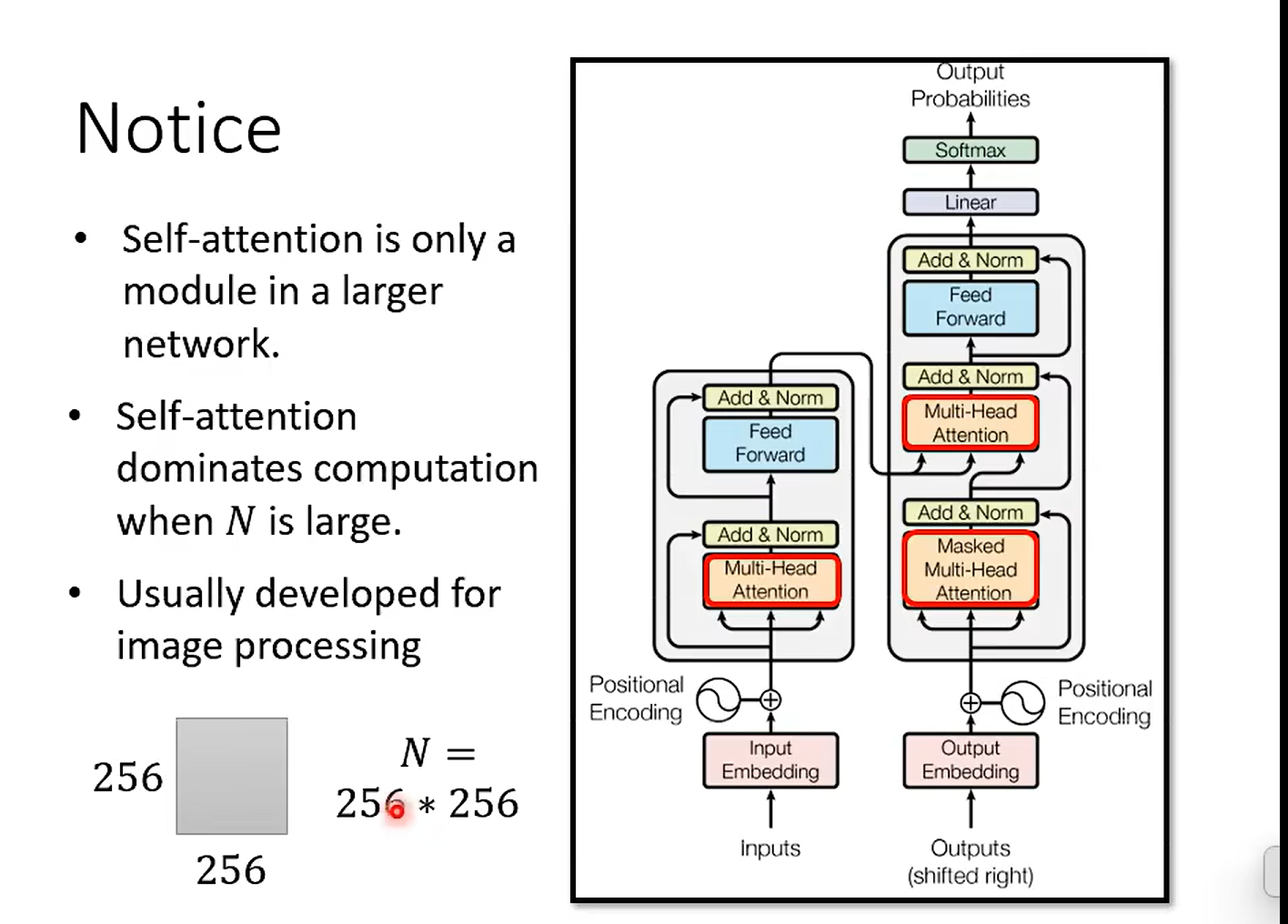
由于self - attention 一般都是在big model 的一部分,所以,一般不会对模型造成决定性的影响, 只有当model 的输入较长的时候, 例如图中: 图片处理 : 256 * 256 的输入,self-attention 就会得到一个 256 * 256 的平方的 矩阵;导致运算量巨大
methods : 使用人类的先验知识
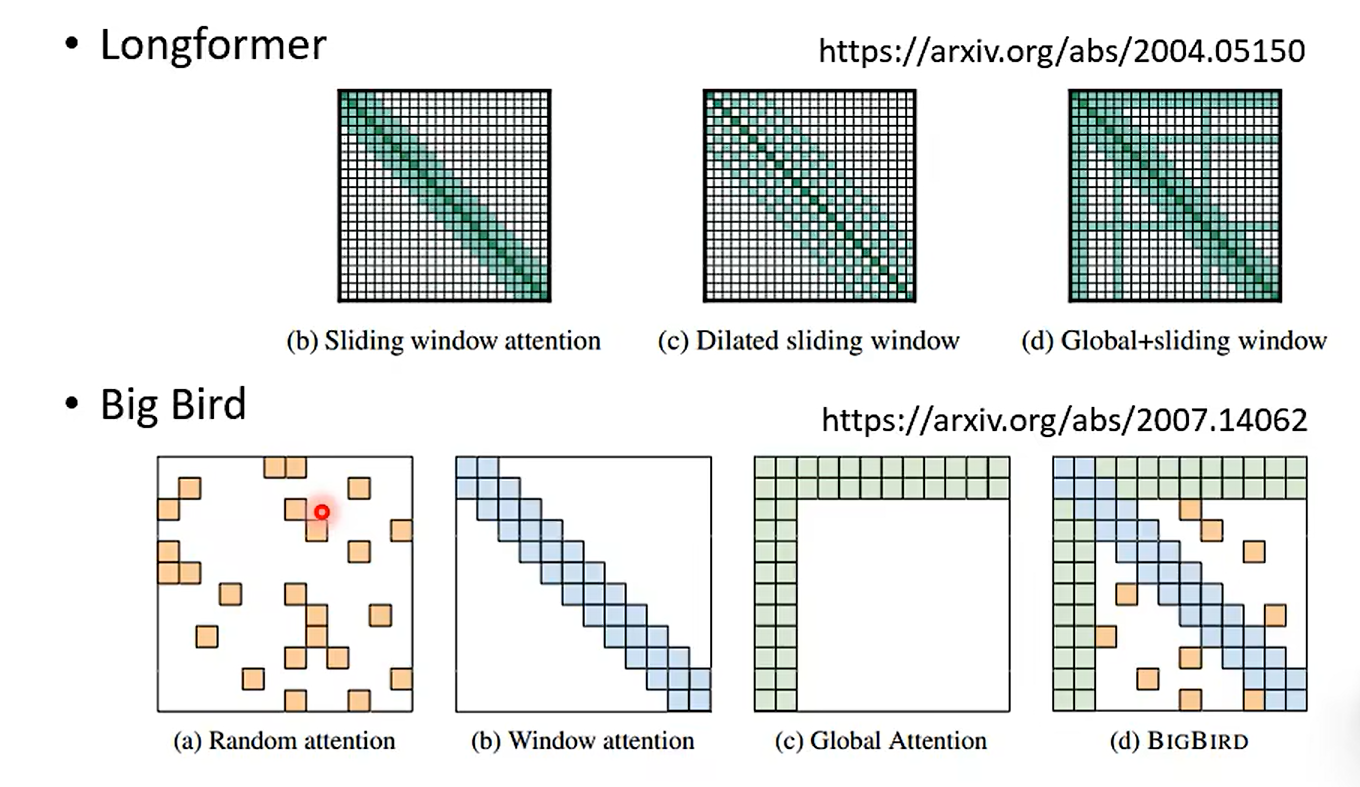
Local Attention / Truncated Attention
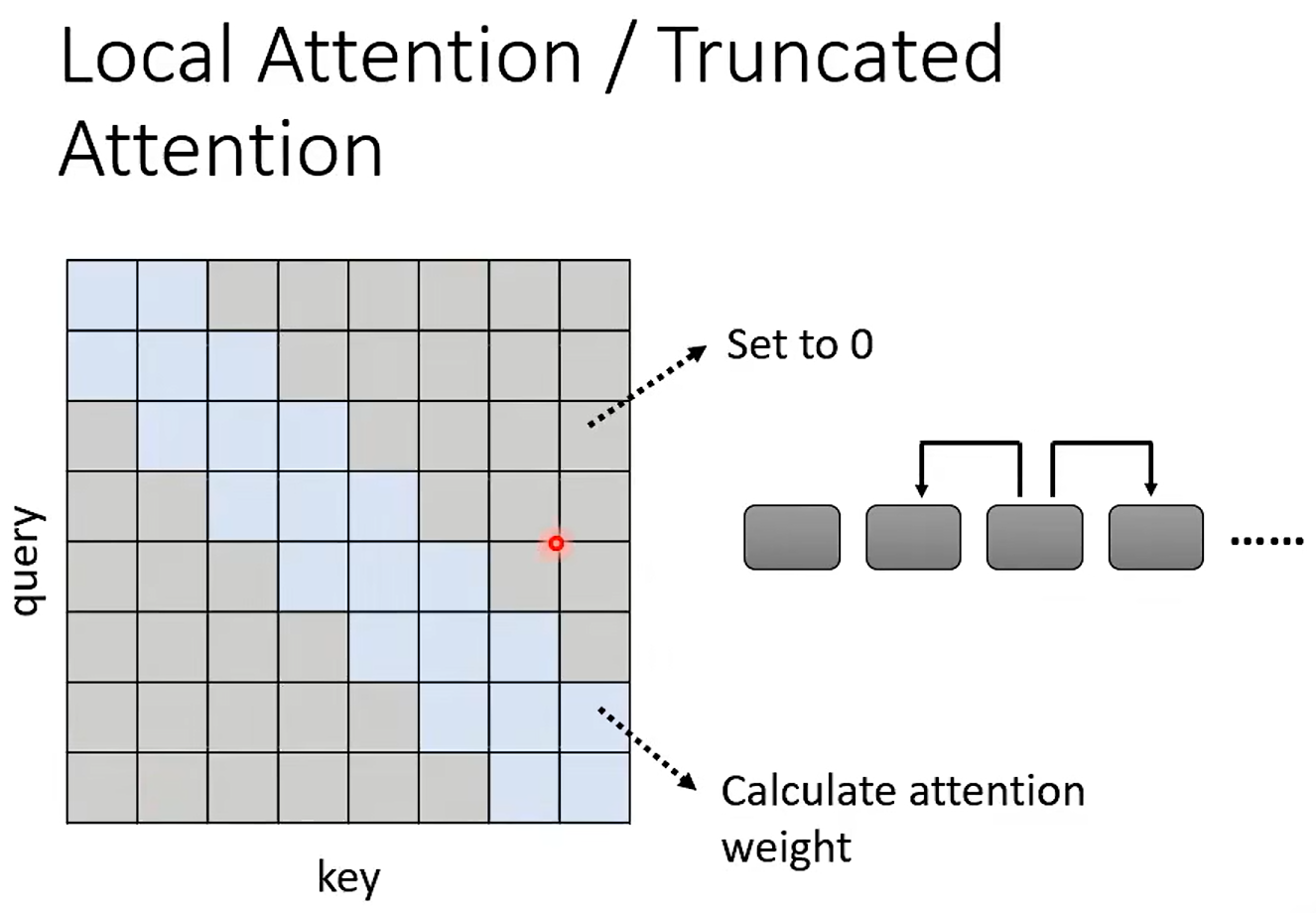
有的时候我们只需要知道左右另据;仅仅知道很小的范围;
感觉和双向RNN 差不多啊……好像还不一样,因为RNN 还是比较有时间序列的
老师说这里和CNN比较像, 可并行
Stride Attention
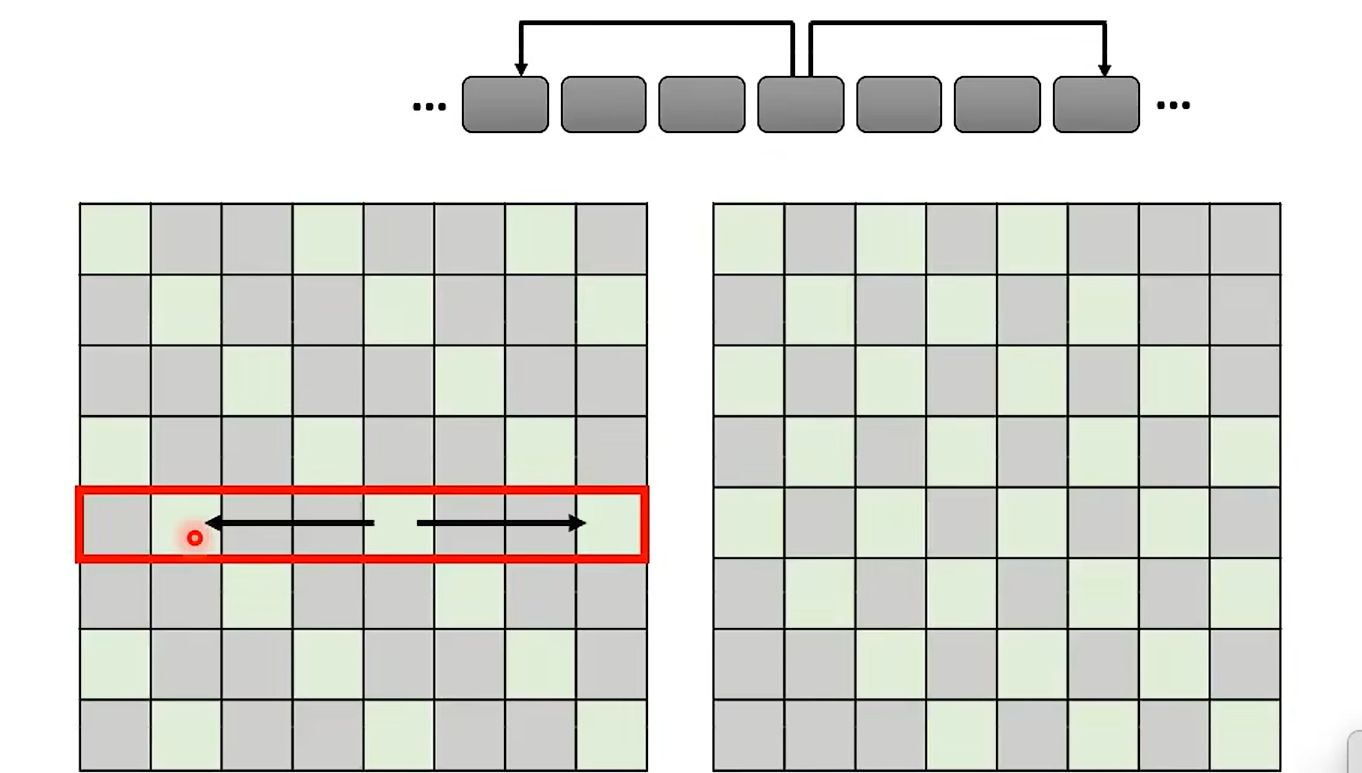
Global Attentiion
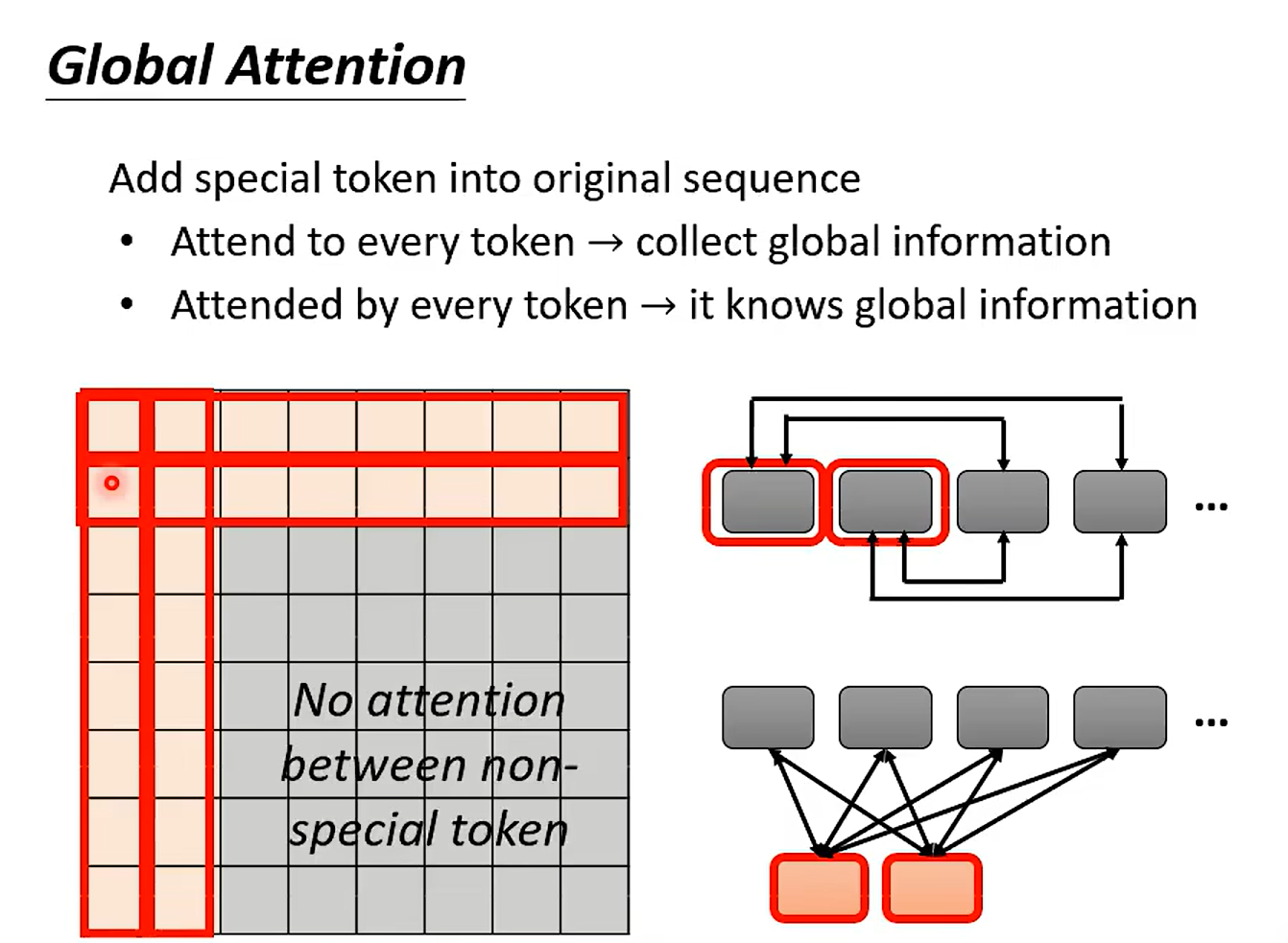
tushi 的是第一种的 attention matrix; 通过special 间接的传递信息
做多 头
//todo 这里忘记了什么是多头的概念了,多头自注意力是怎么做的来着?
Can we only focus on Critical Parts ?
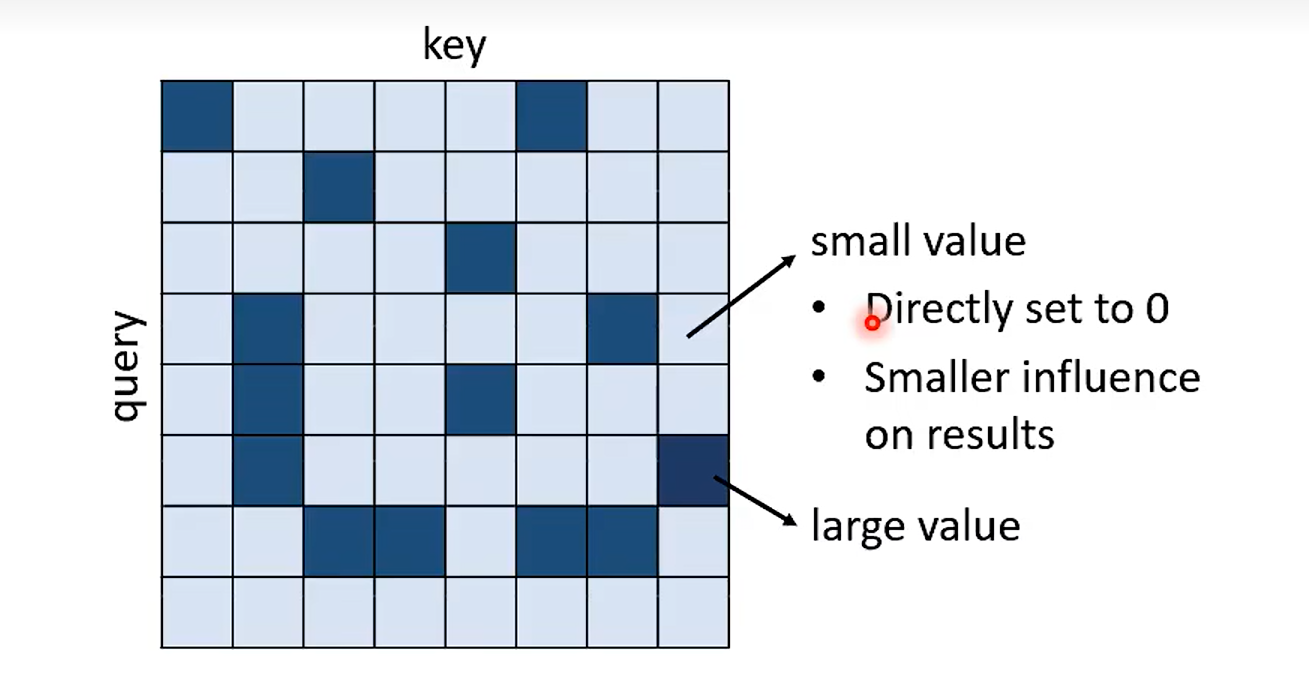
有没有办法估计一下较小的值,直接抹零?
how we do that ?
Clustering
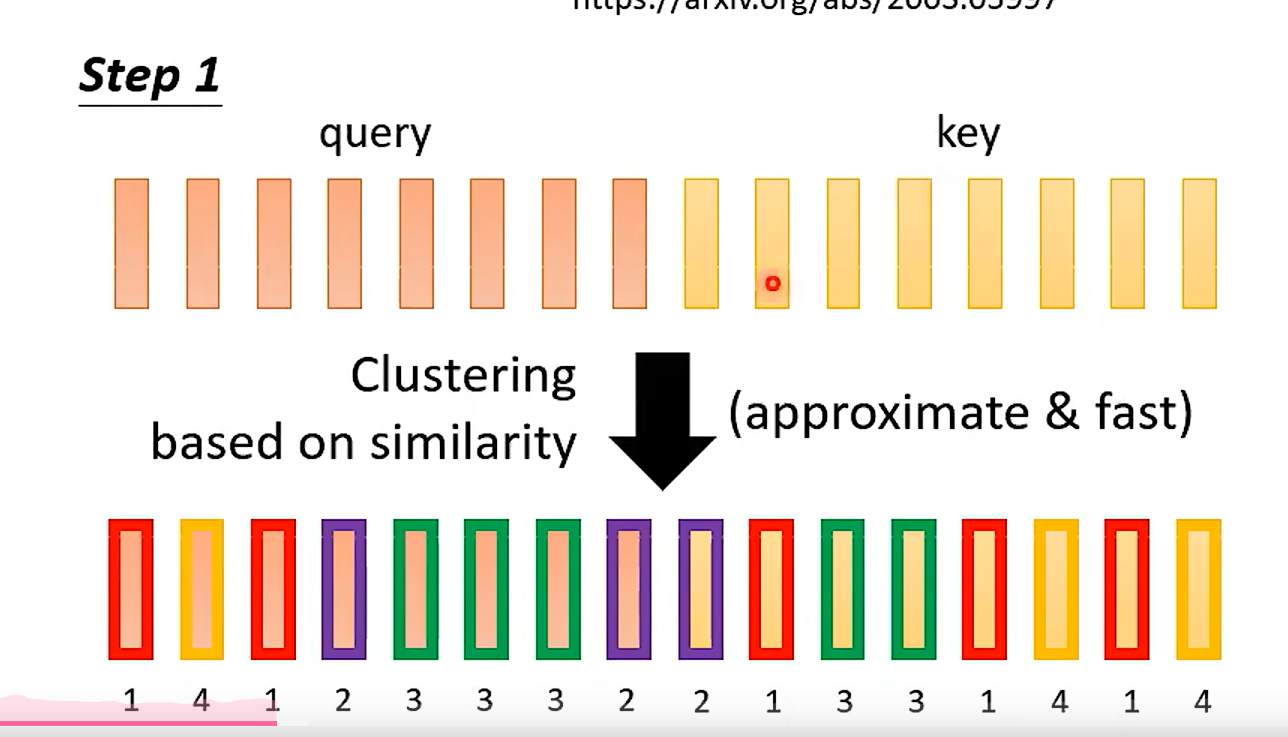
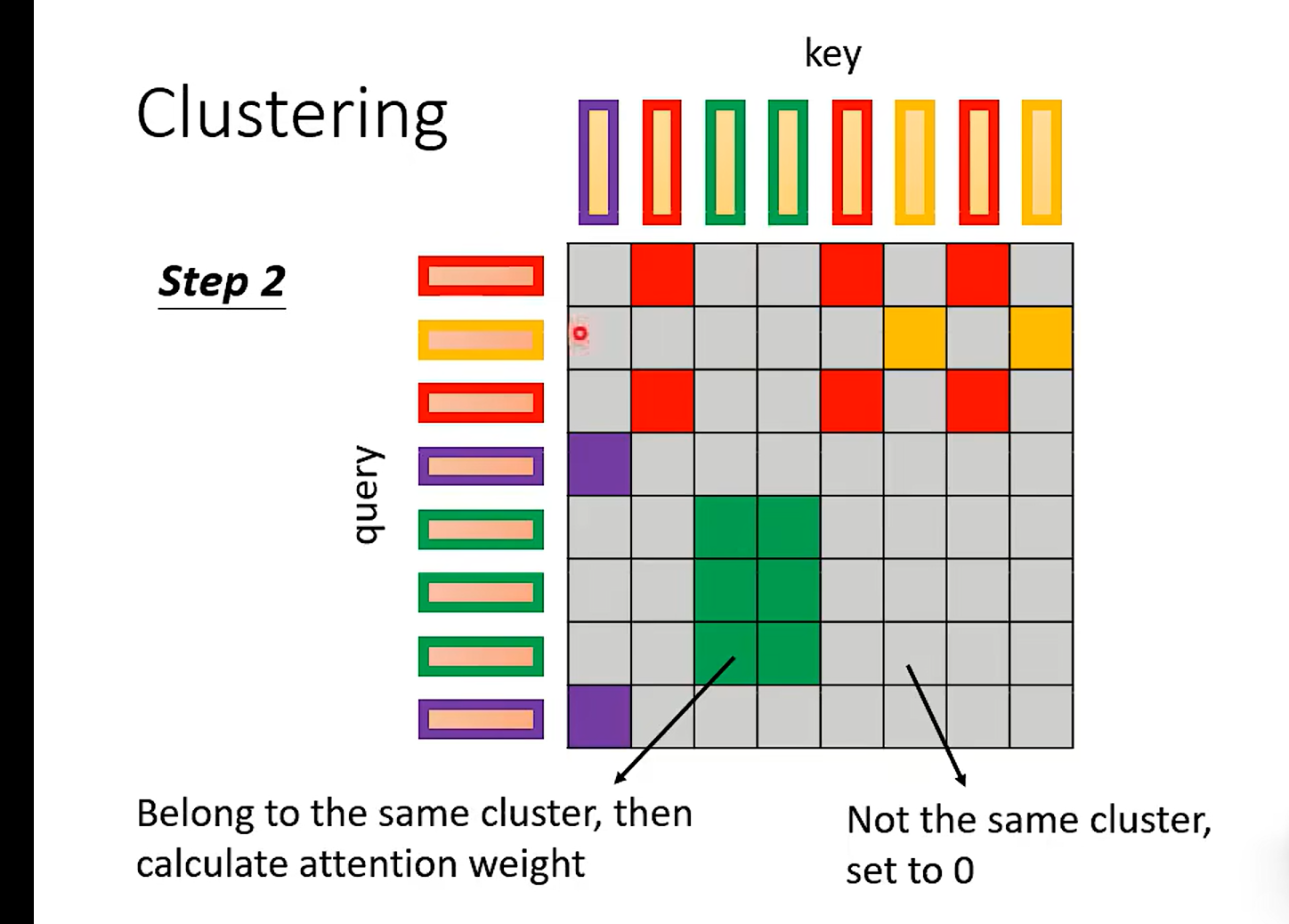
提问:
- 为什么是计算相似的而不是计算不同的以保持模型的多样性, 久像 pca 那样
- 自注意力机制算的是不是相似程度的矩阵?
- 如果是的话, 这样做为什么就能得到sequence 的全局信息了?
这里我突然蒙圈了,这里wei’啥是 4* N * N * 4呢? 而不是反过来,换句话说, 这个矩阵的大小为啥是序列的长度,而不是向量的维度
// todo 这是因为自注意力机制的目的是计算序列中每个元素对于序列中每个其他元素的注意力得分,所以我们需要一个 N×N 的矩阵来表示这些得分。每个元素都有一个对应于其他所有元素的得分,包括自己。
md 明白了, 还是需要有一个人来给自己点拨点拨呀
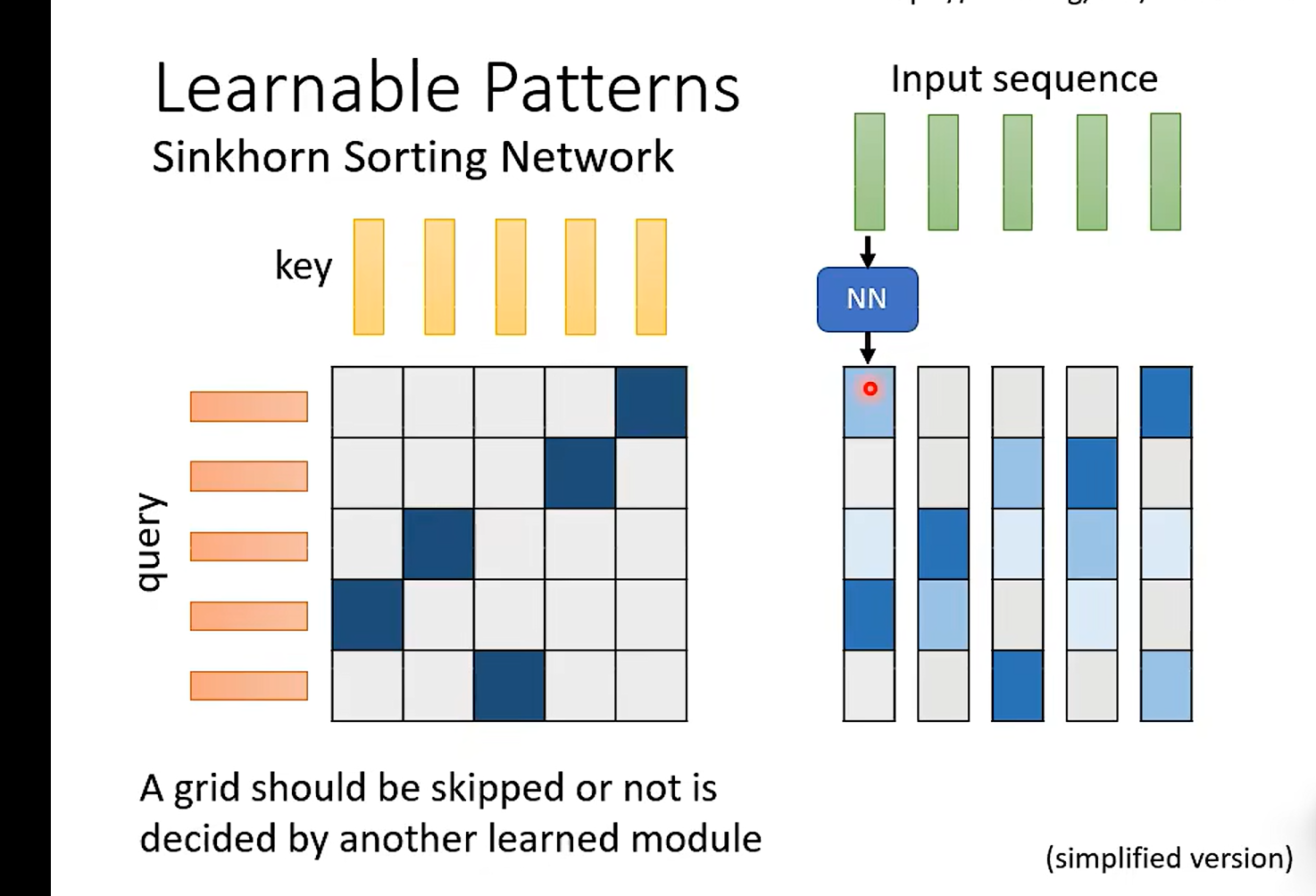
特色就是新弄了一个network ;没讲的是如何从右边到左边binary 的 map
台大学生提问: 这里真的有加速吗?其实我也满想问的,奈何时间不允许啊!!!
NN 里面只会产生一个10*10 的解析度较低的matrix
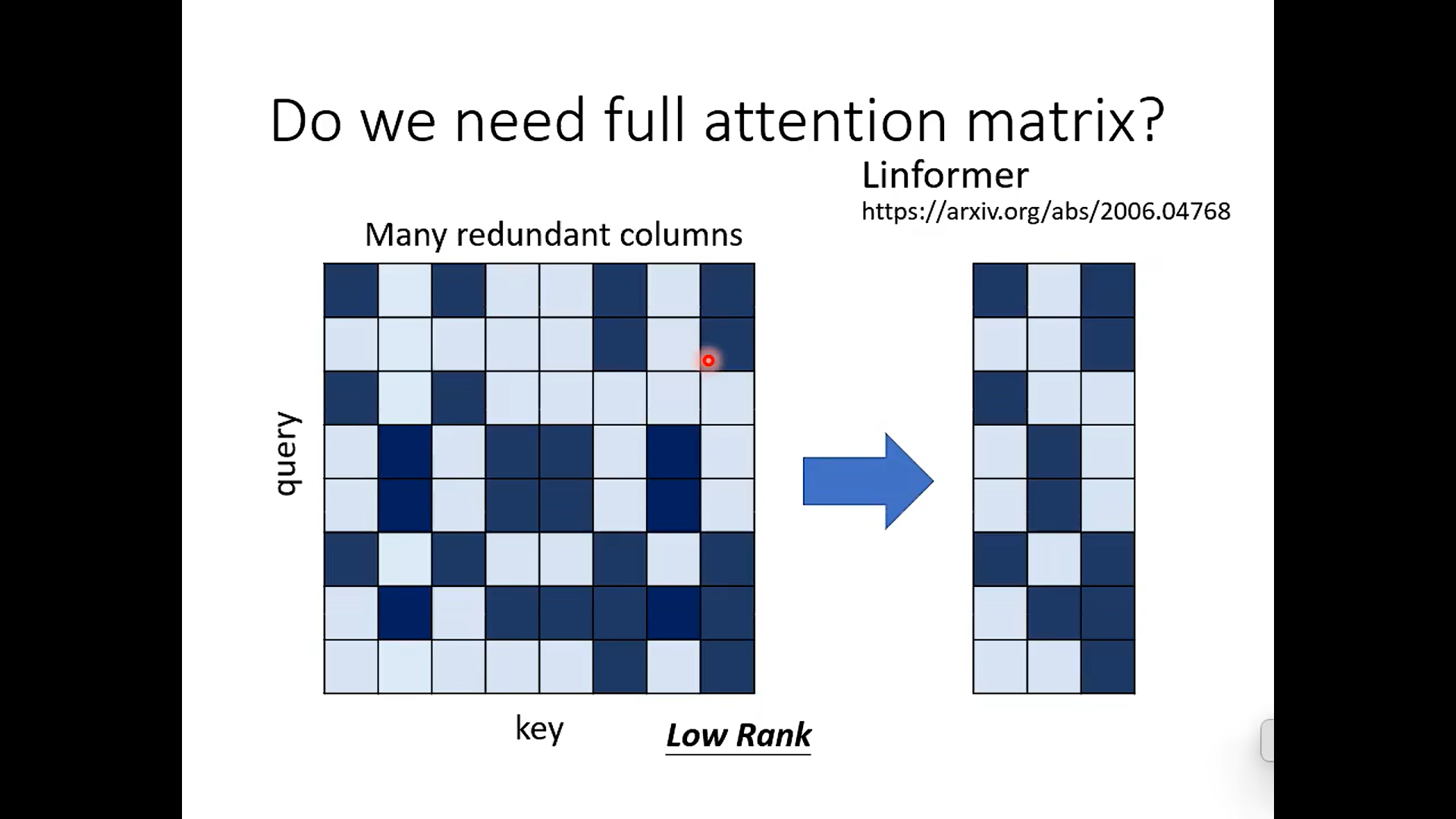
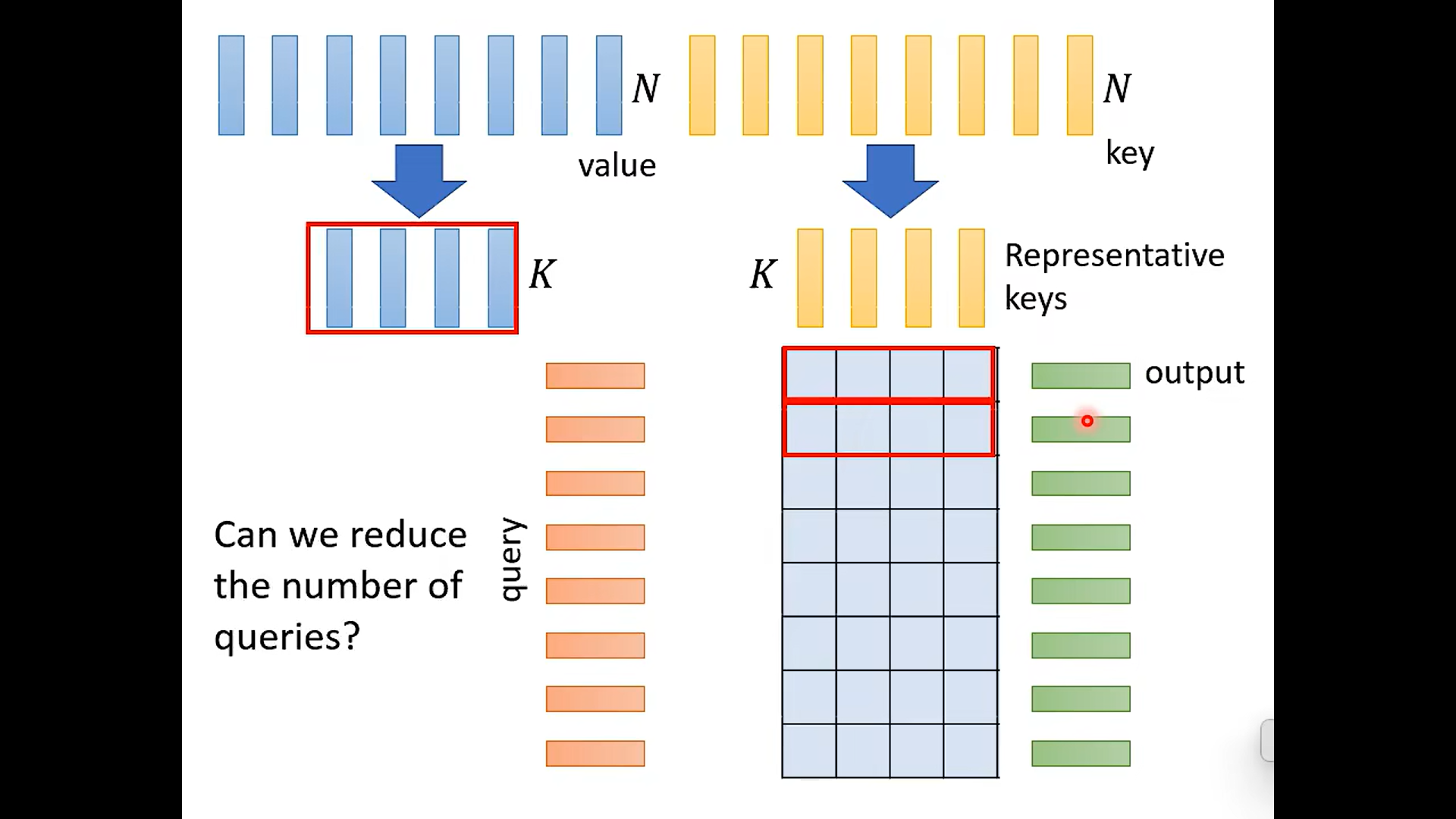
这里的value 表示什么意思? 是不是输入?
//todo
注意这里为什么不也用 有代表性的 query ?
会改变我的output , 导致不能使得squence的每一个part 都有一个lable 被分出 ,例如词性标注
提问:为什么是 QKV ? 而不是KQV?
好啦 这个问题其实有点蠢了, 当你KQV 的时候 ,你的K 就变成了 Q ;Q 就变成了K ;和你做函数的代换法的时候 用 u 代表变量 x 的行为没什么两样啦
Reduce numbers of Key
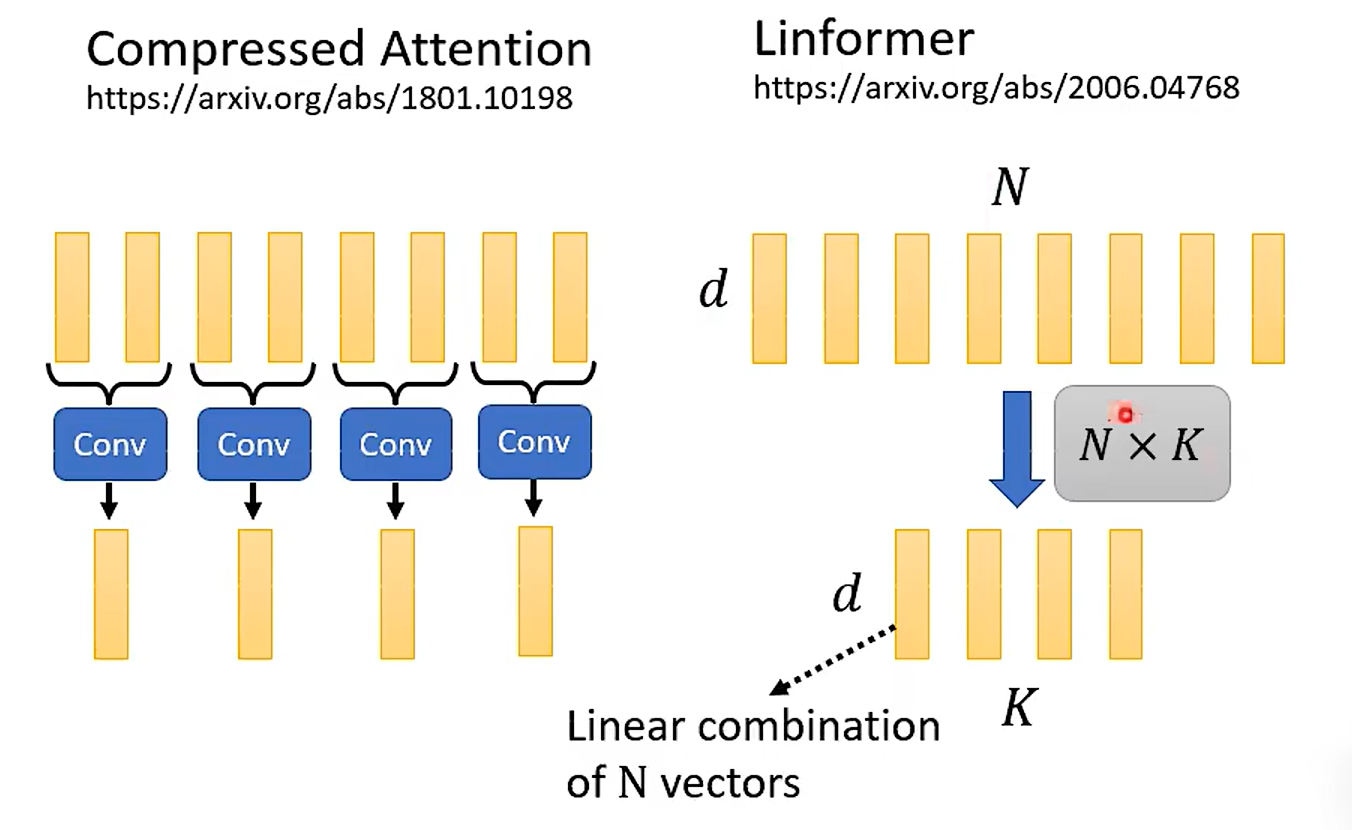
做不同方式的线性组合, 其实我的想法 那么也很简单, 用pca 做一下,说不定也可以, 反正就是减少运算量嘛~
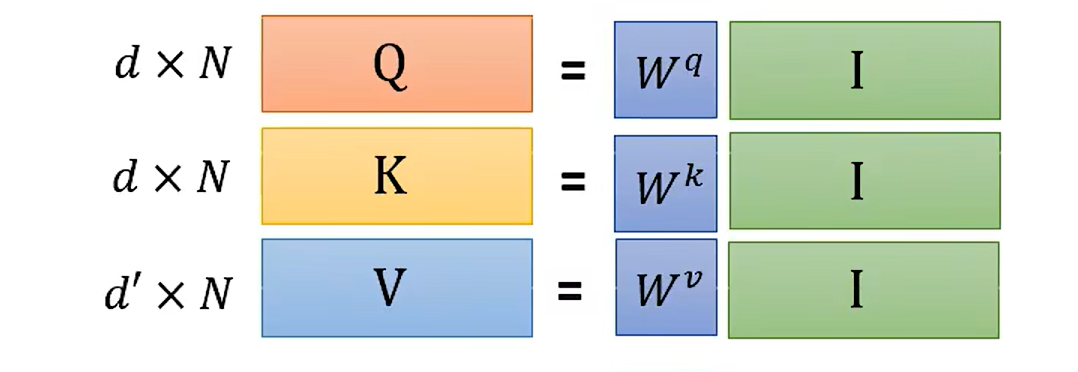
为啥这里的v 可以和 其他的维度不同?
emmm 比较简单了
- 1N * N * 3 = 1 3
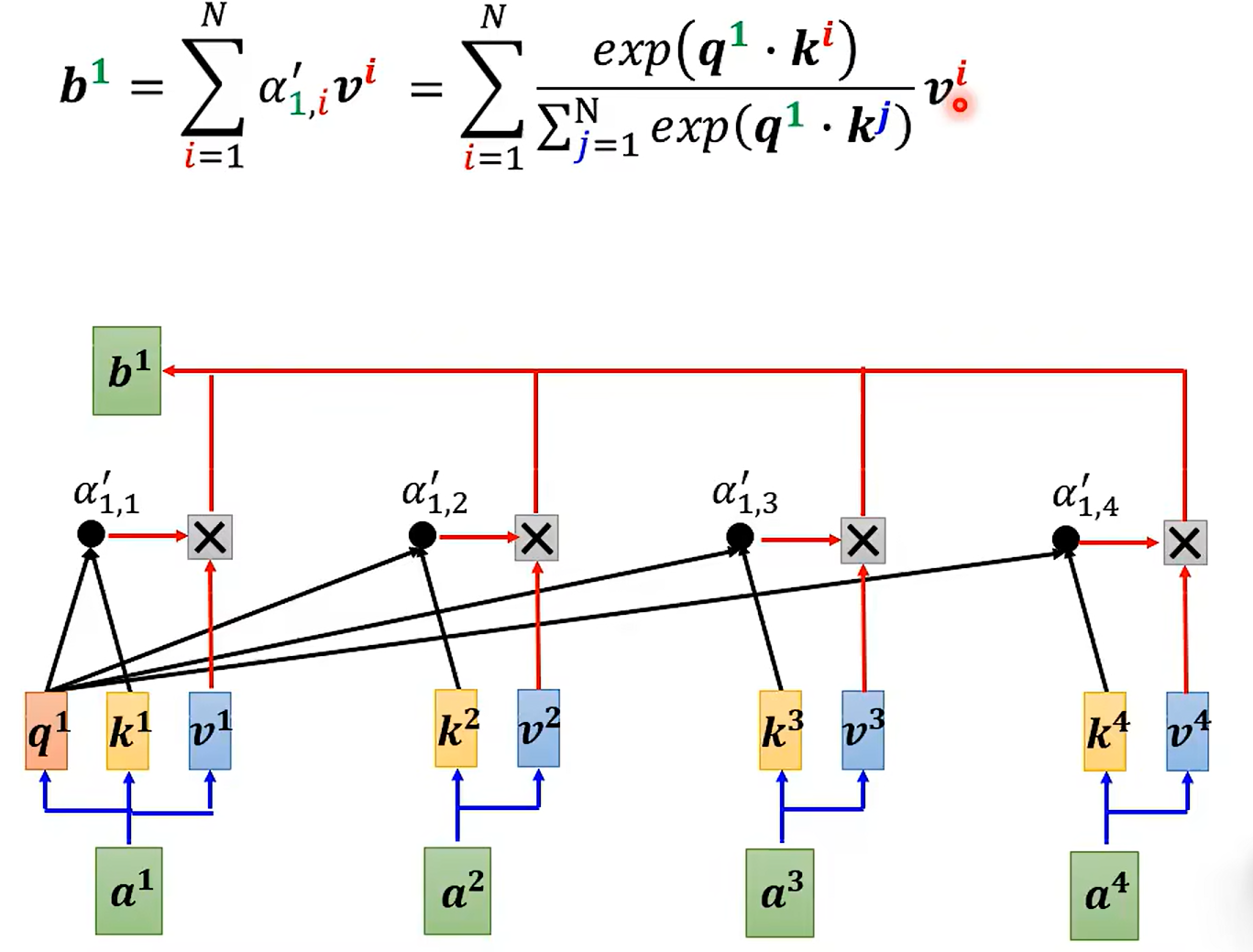
- b = Σ \Sigma Σ a‘ * V
可以看到 V 只需要×一个数字, 当然就不需要一样啦
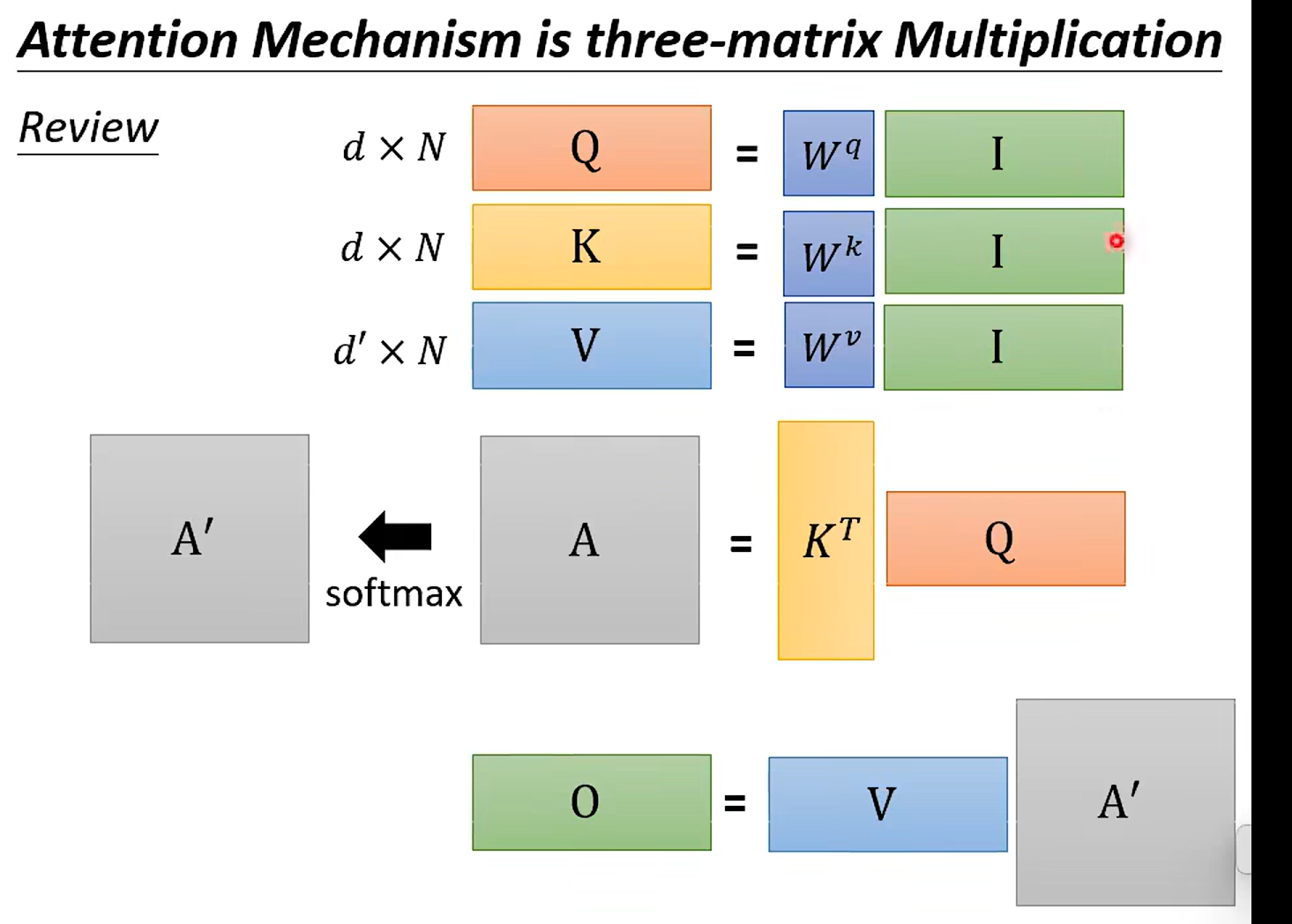
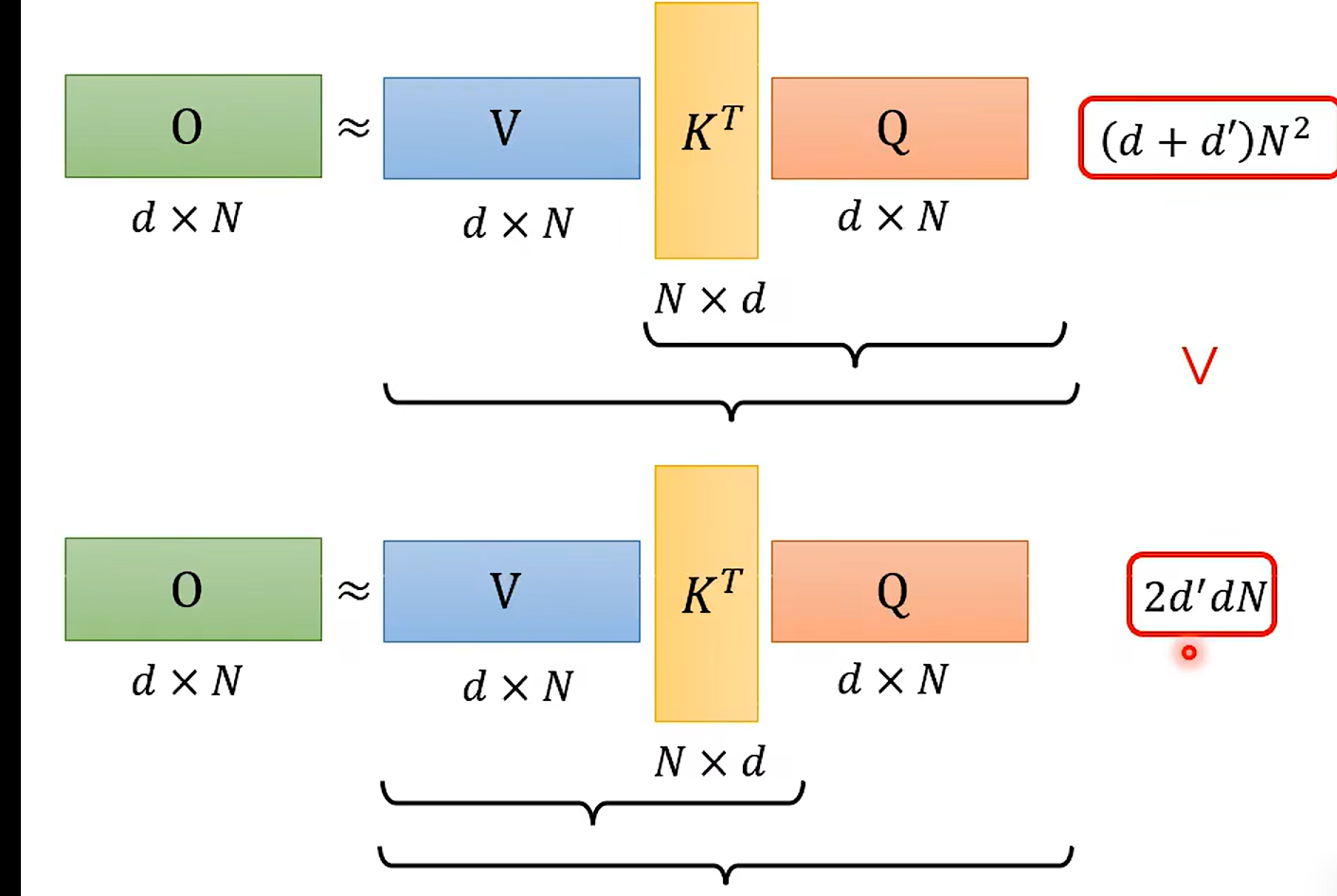
好吧 V K T Q 其实差不多就是输出了(如果我们忽略掉, KQ 之后 的softmax ,md 我也忘了这里的作用了)
将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过softmax的内在机制更加突出重要元素的权重;
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制的关键点在于,Q、K、V是同一个东西,或者三者来源于同一个X,三者同源。通过X找到X里面的关键点,从而更关注X的关键信息,忽略X的不重要信息。
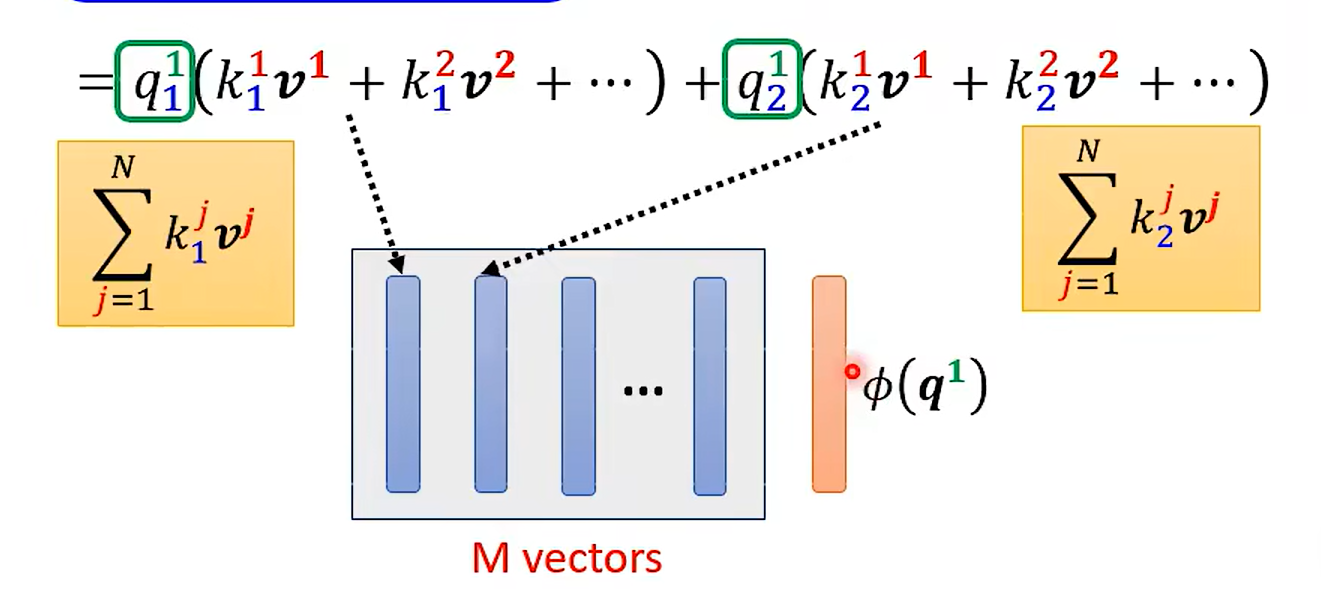
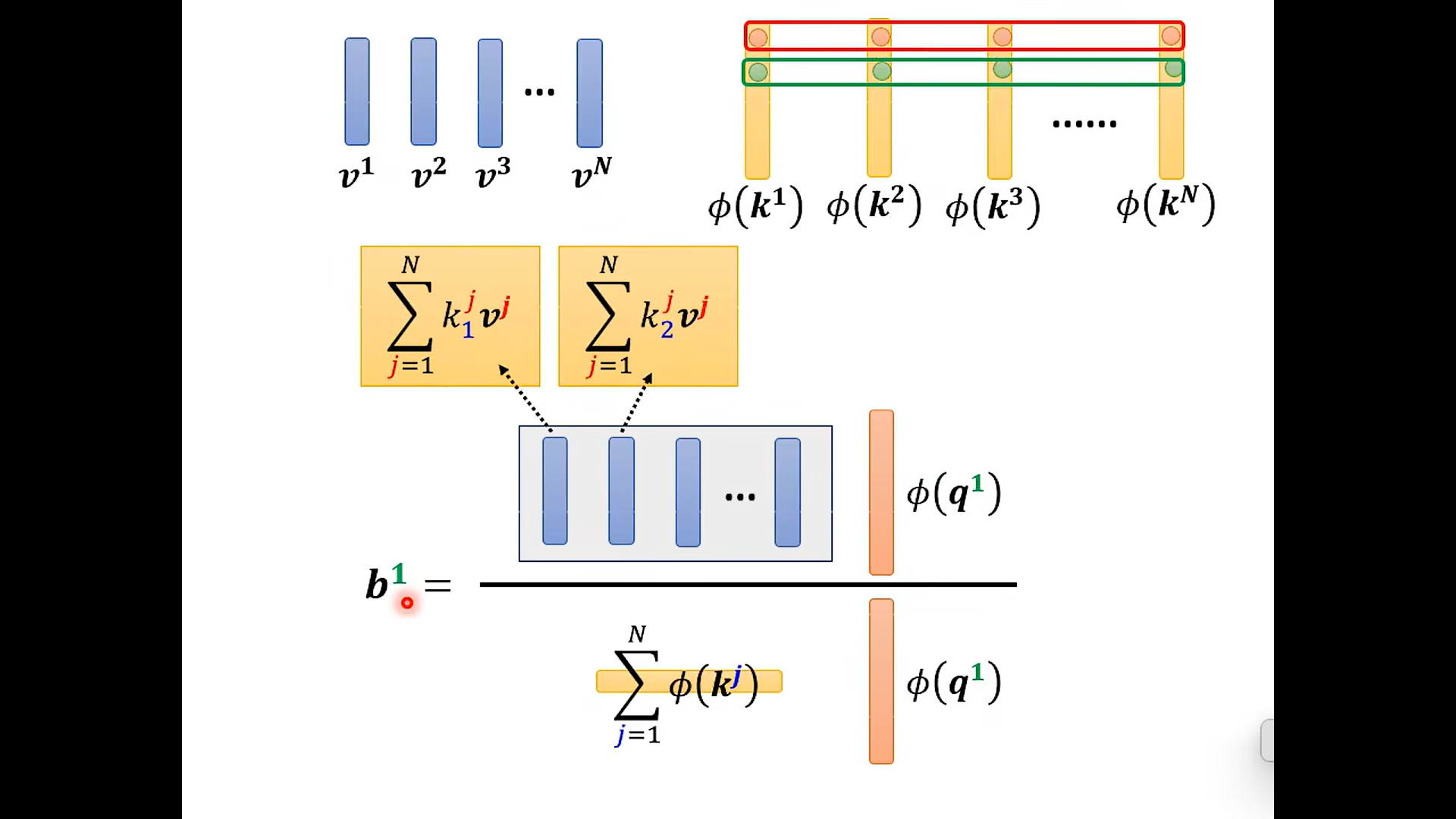
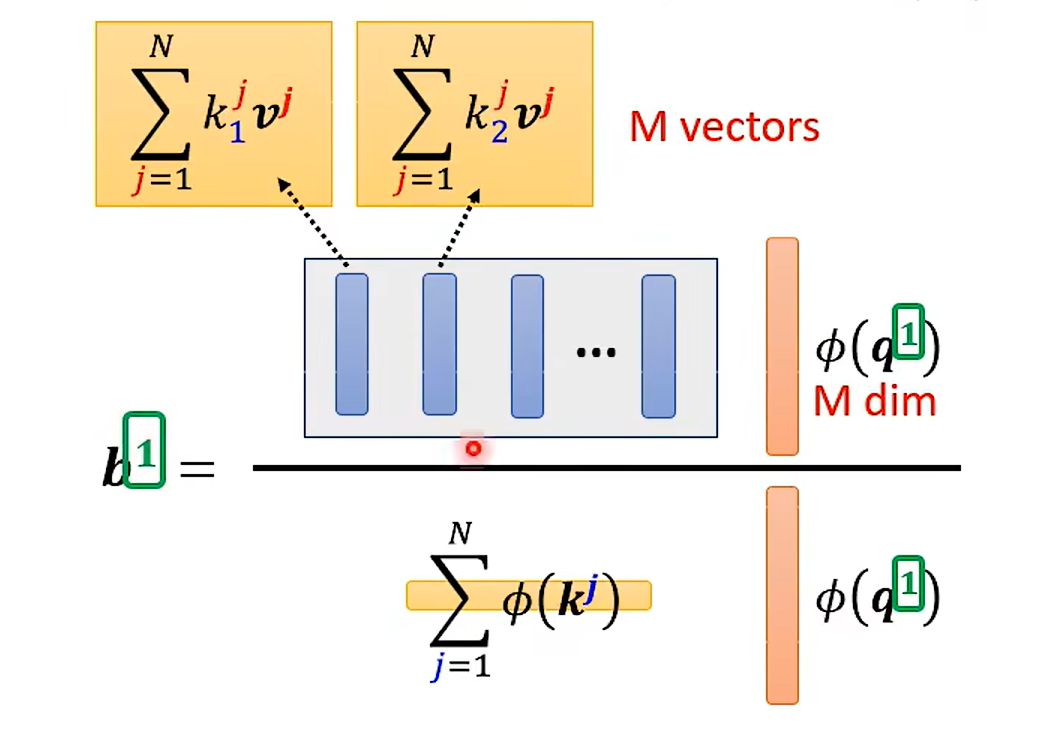
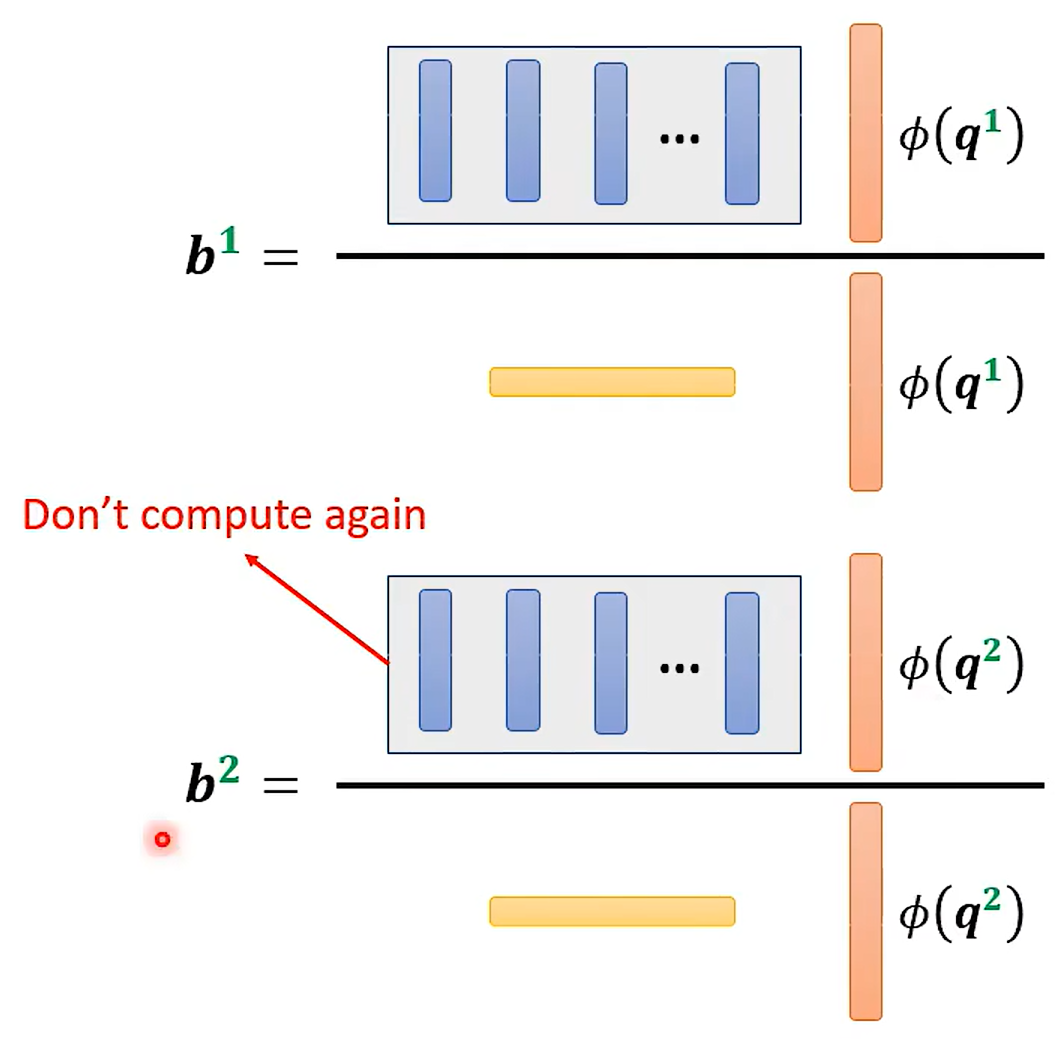
Change the orders --Linear Transformer
这里先假设没有softMax 的情况哈
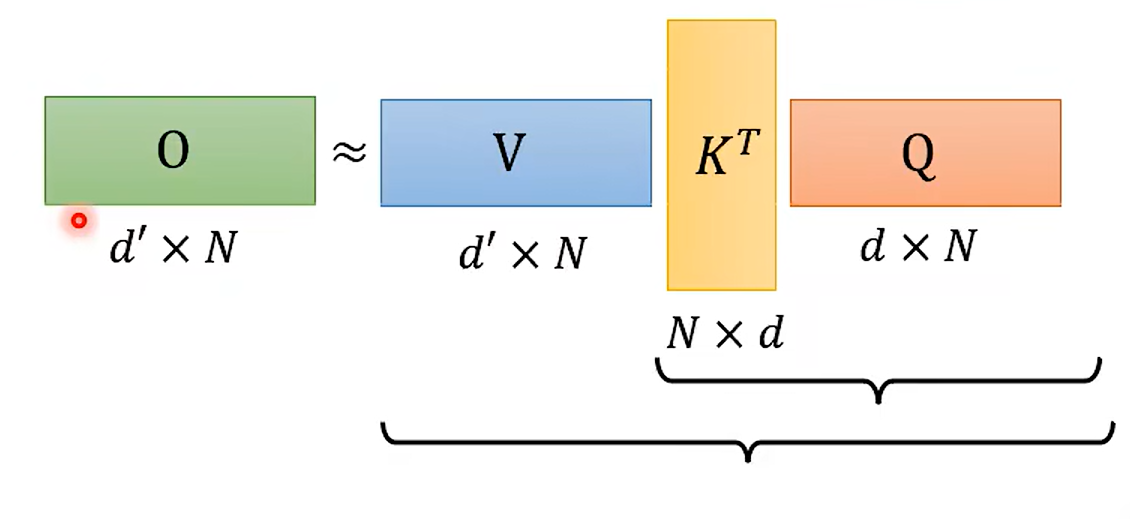
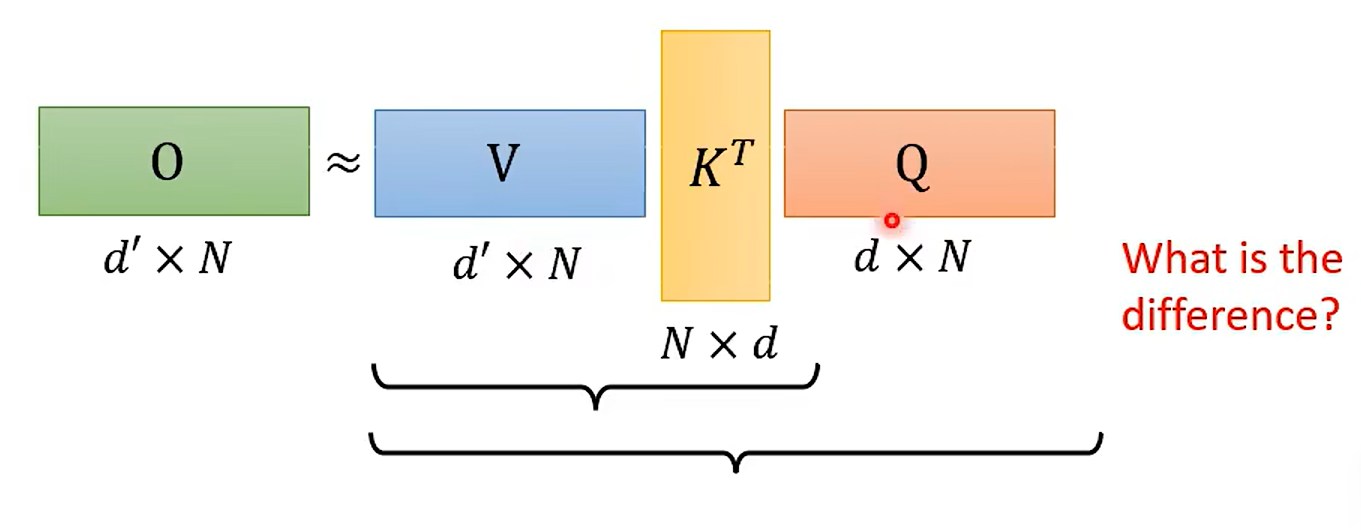

md 推荐 线性代数 – 李宏毅了 要开始;
ps 好像赚钱买mac 啊 ……
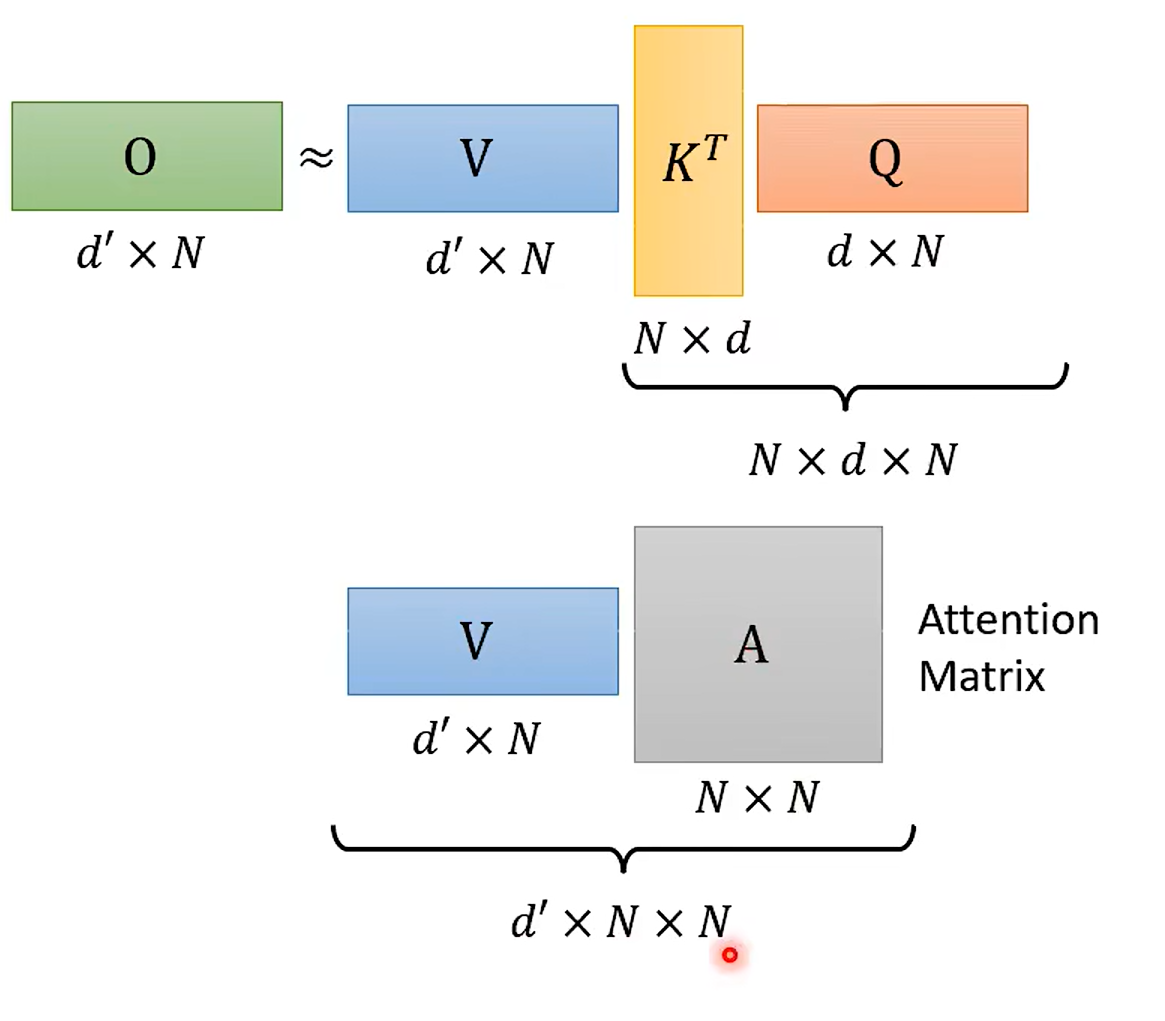

交换后:
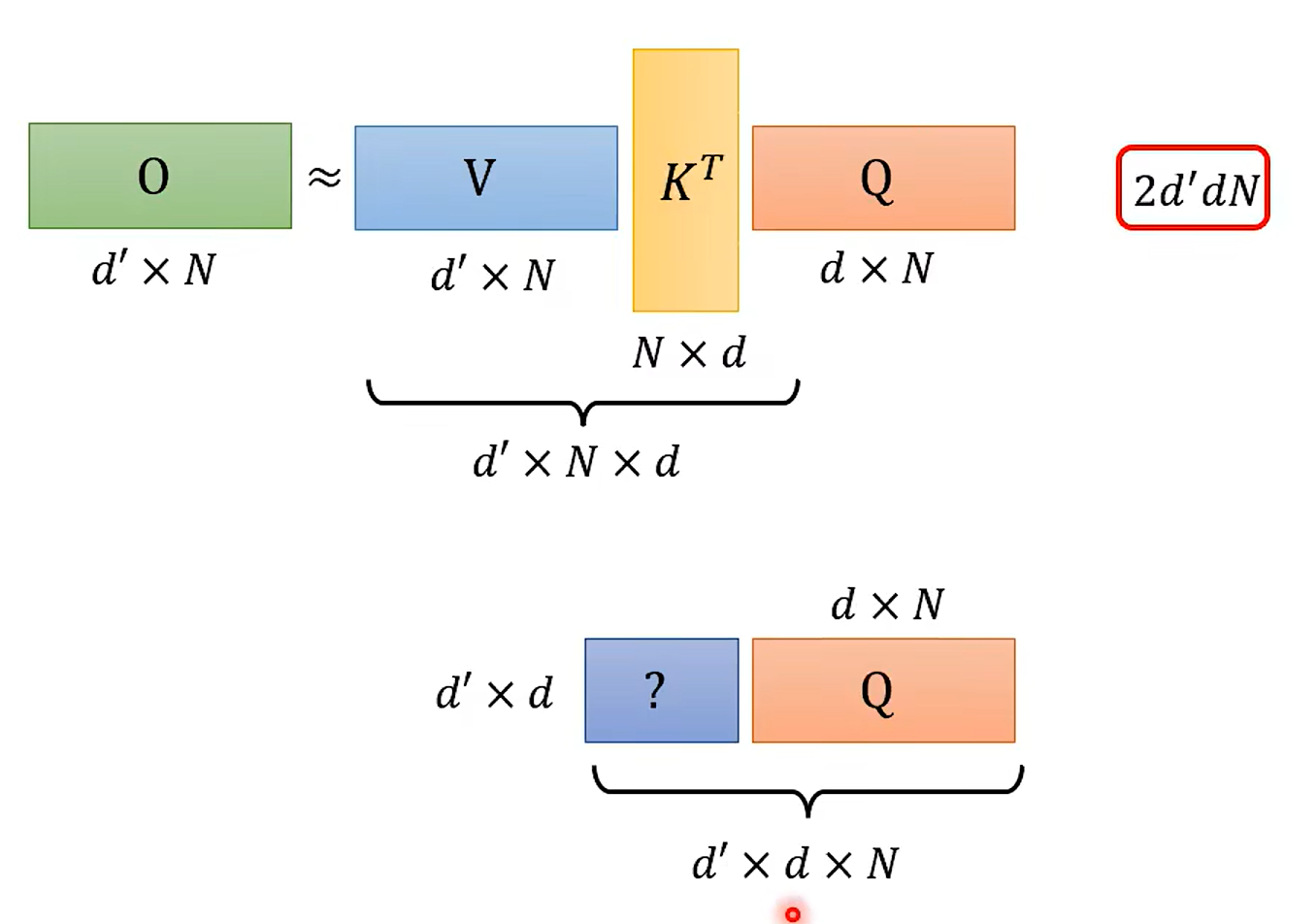
好家伙 改了一下乘法的次数 变了这么多;
but……

while when how we add the softMax
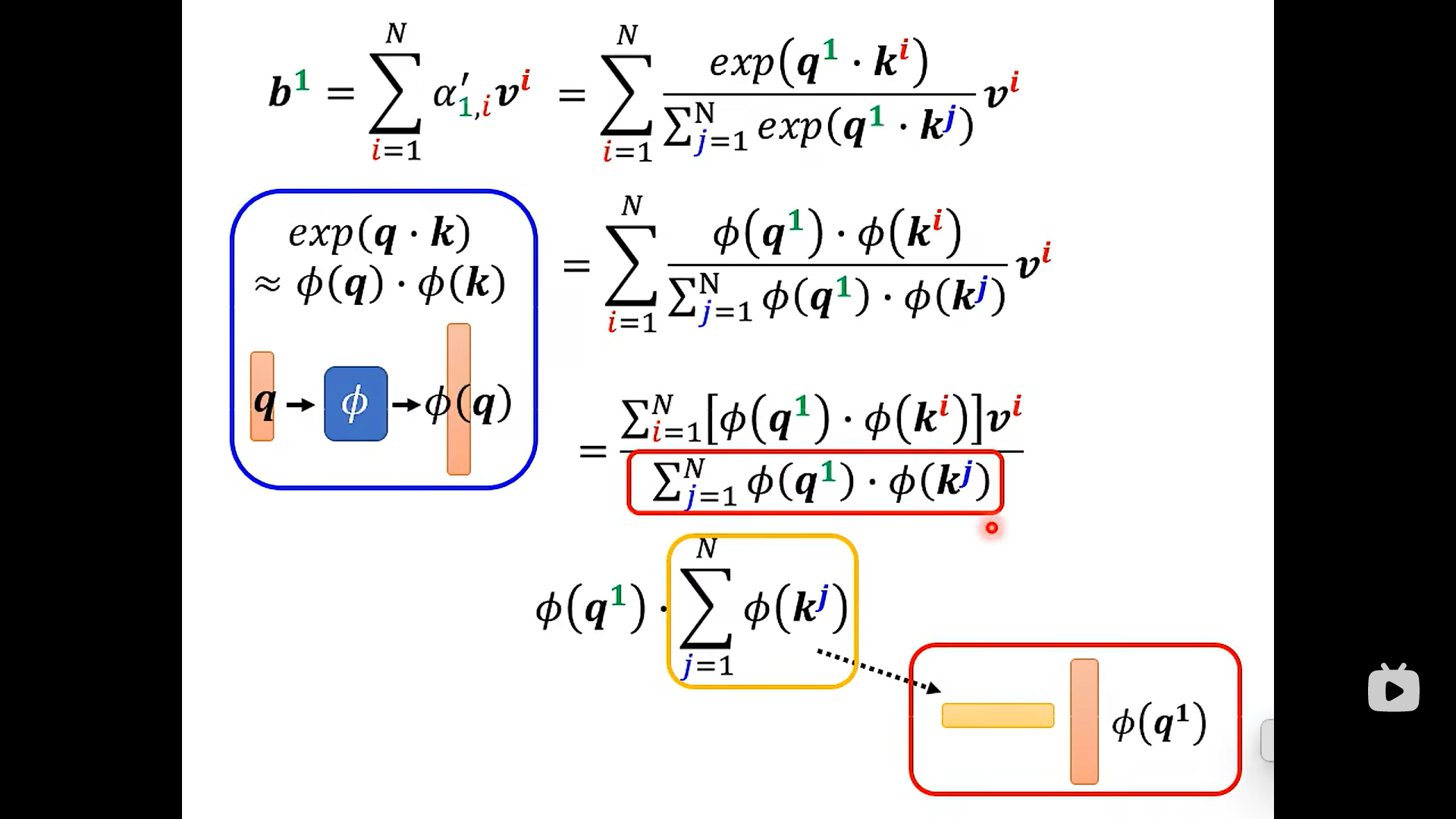

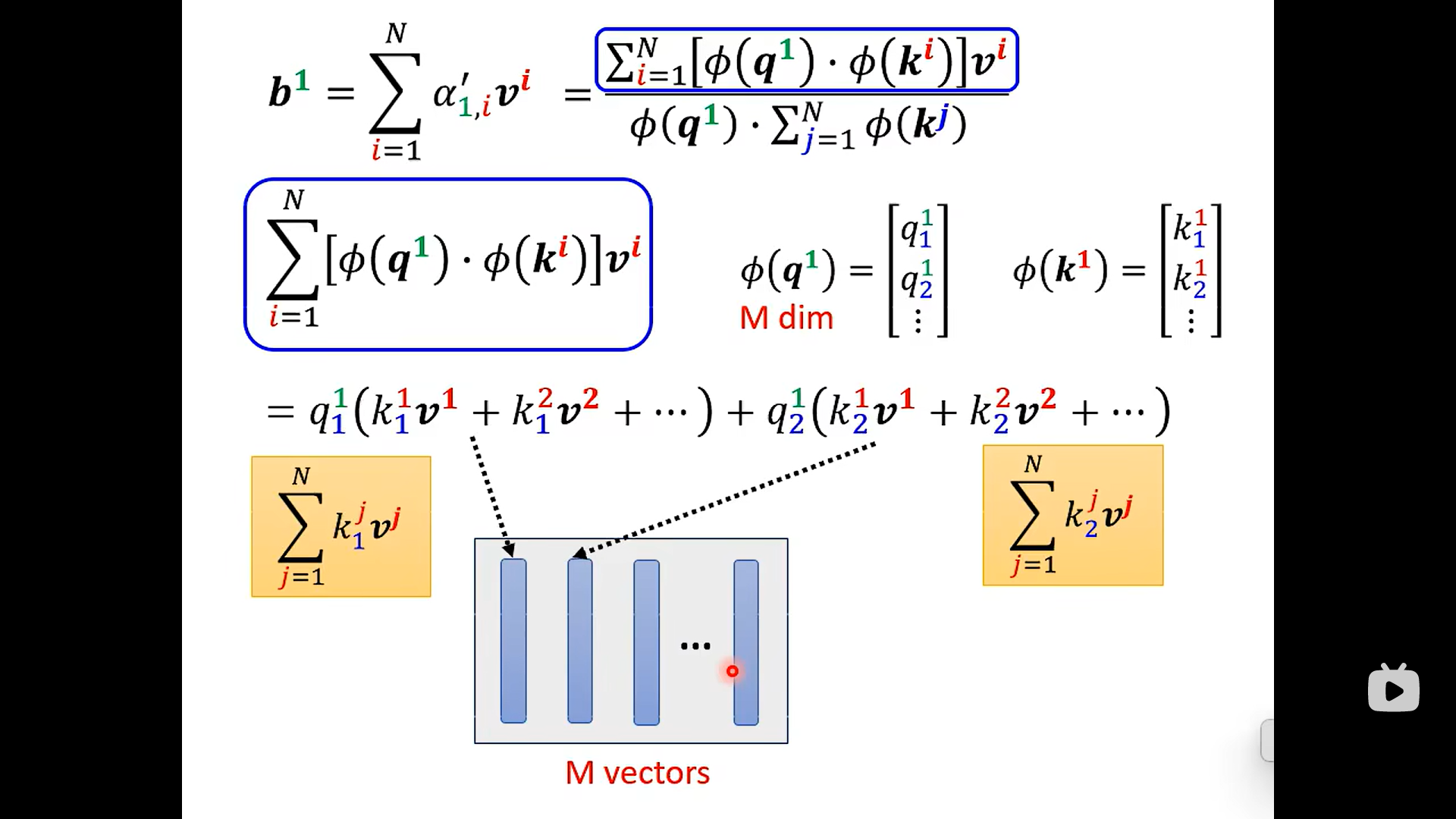
Lets put soft Max back ……
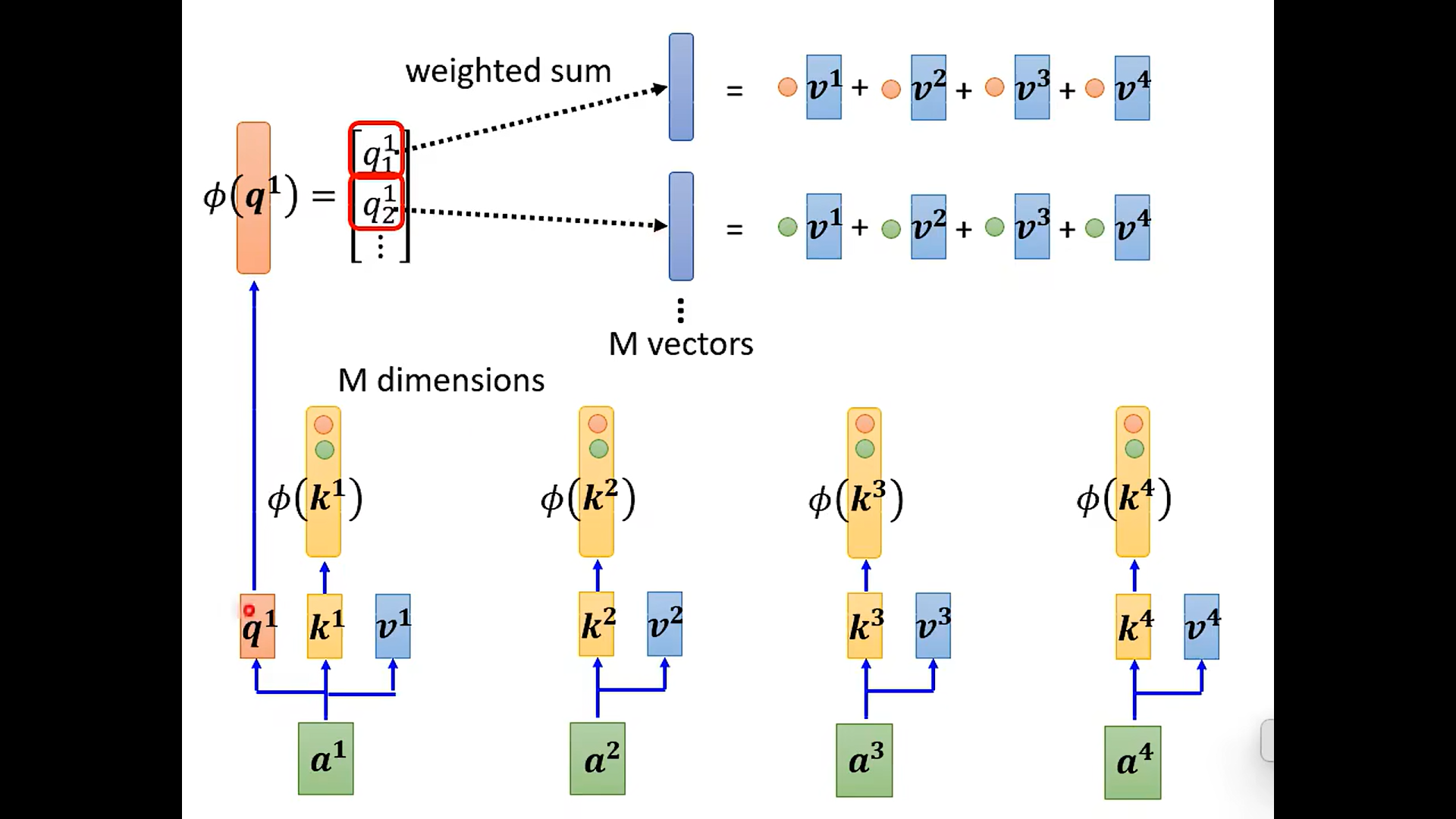
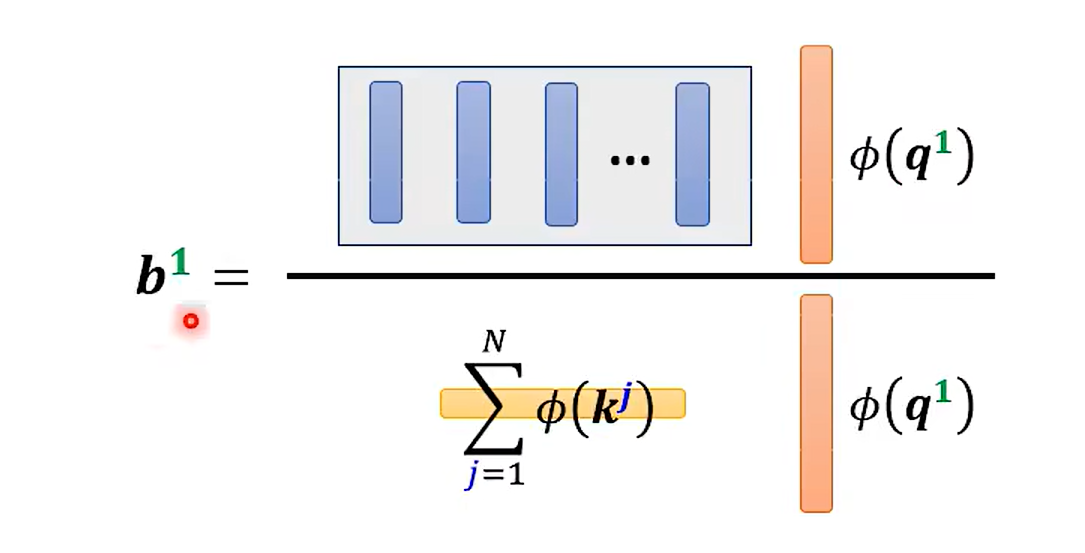
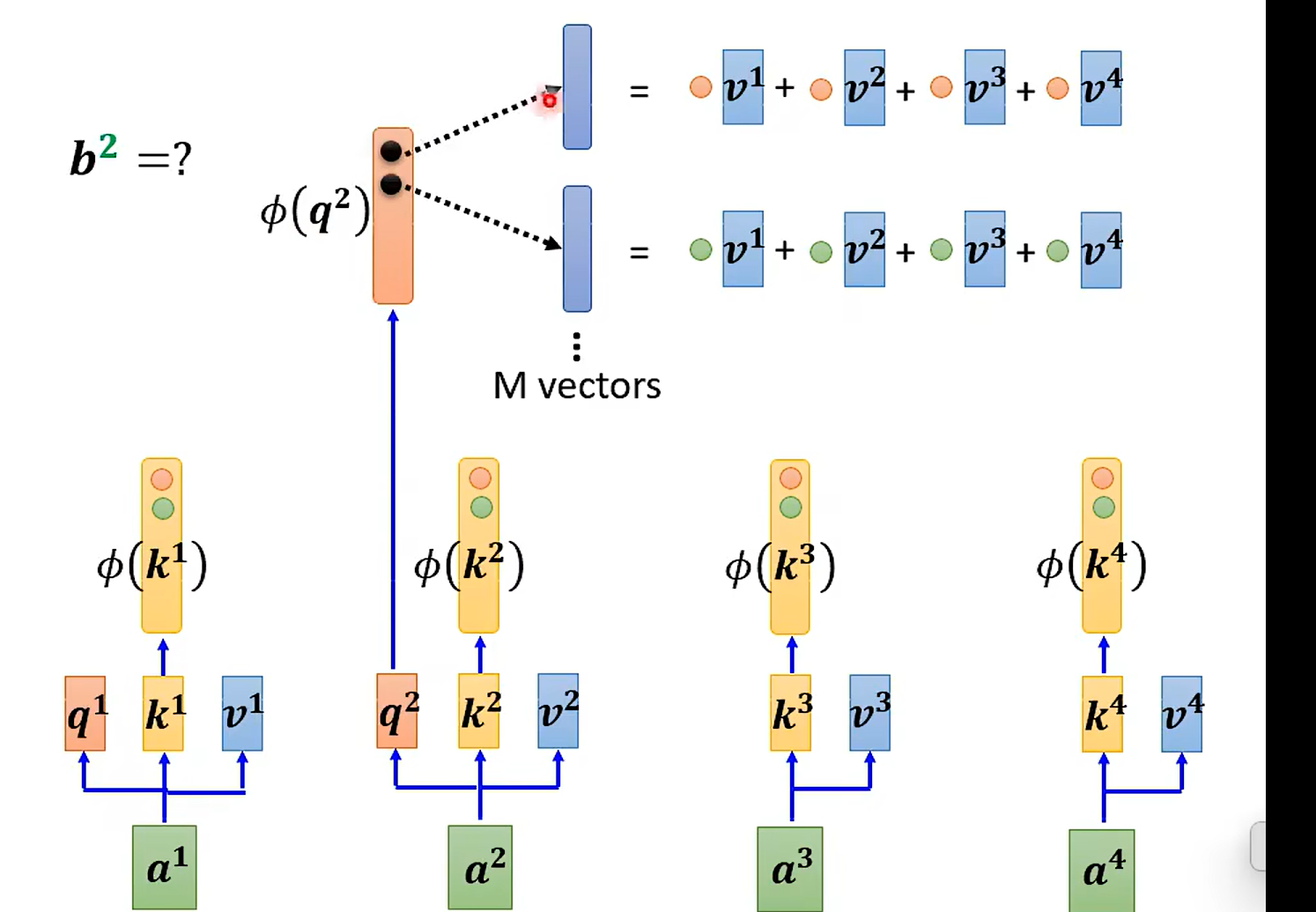
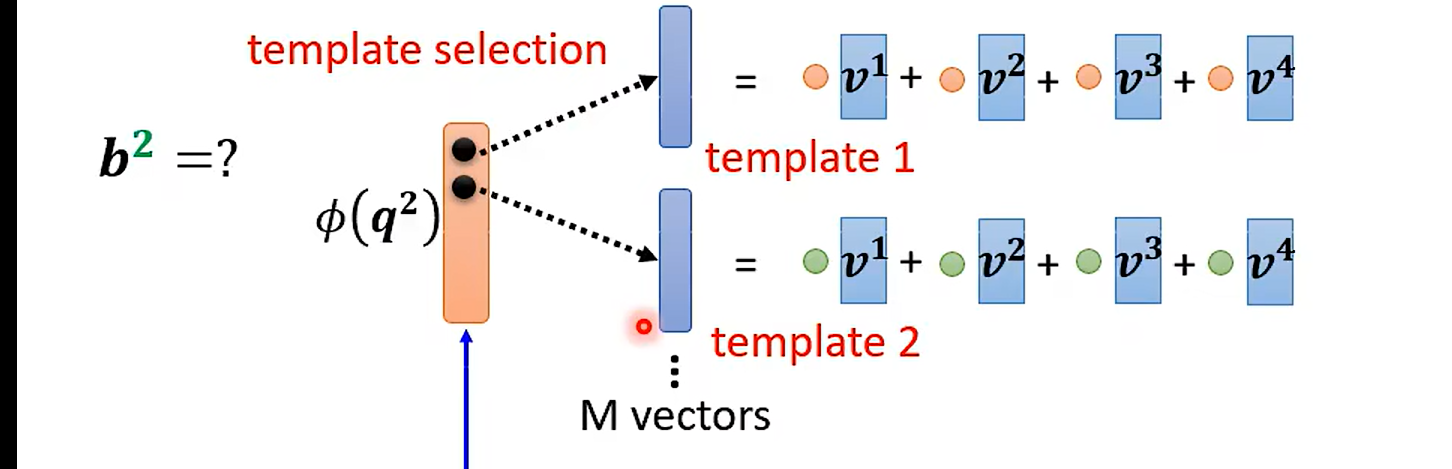
template == pattern
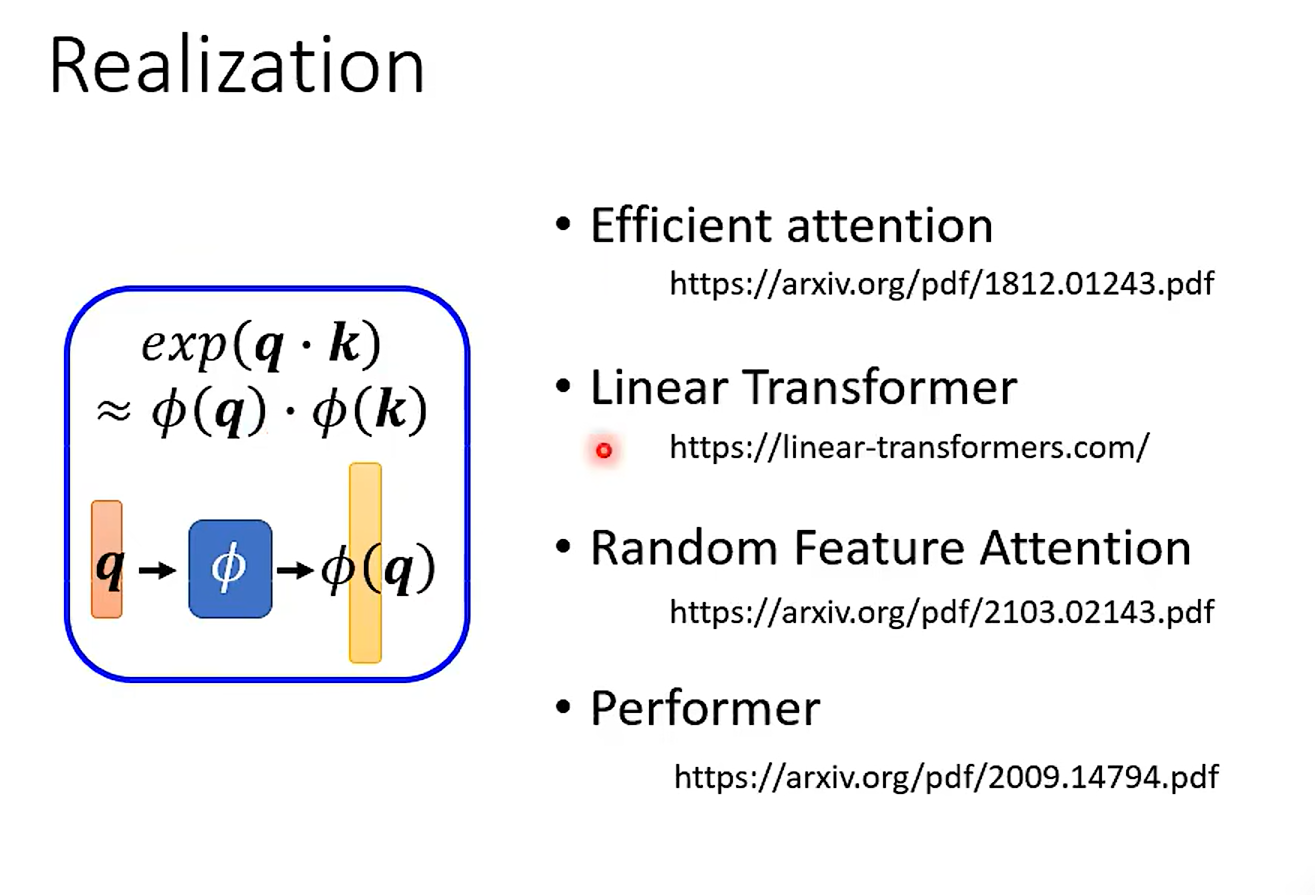
how to 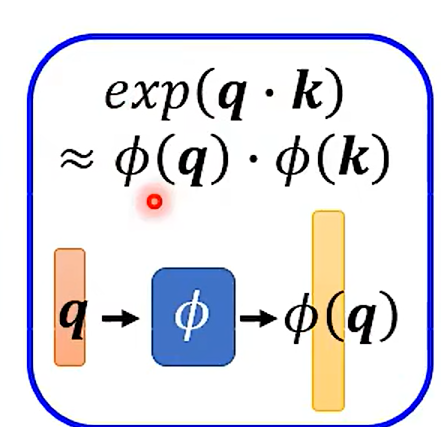
Synthesizer
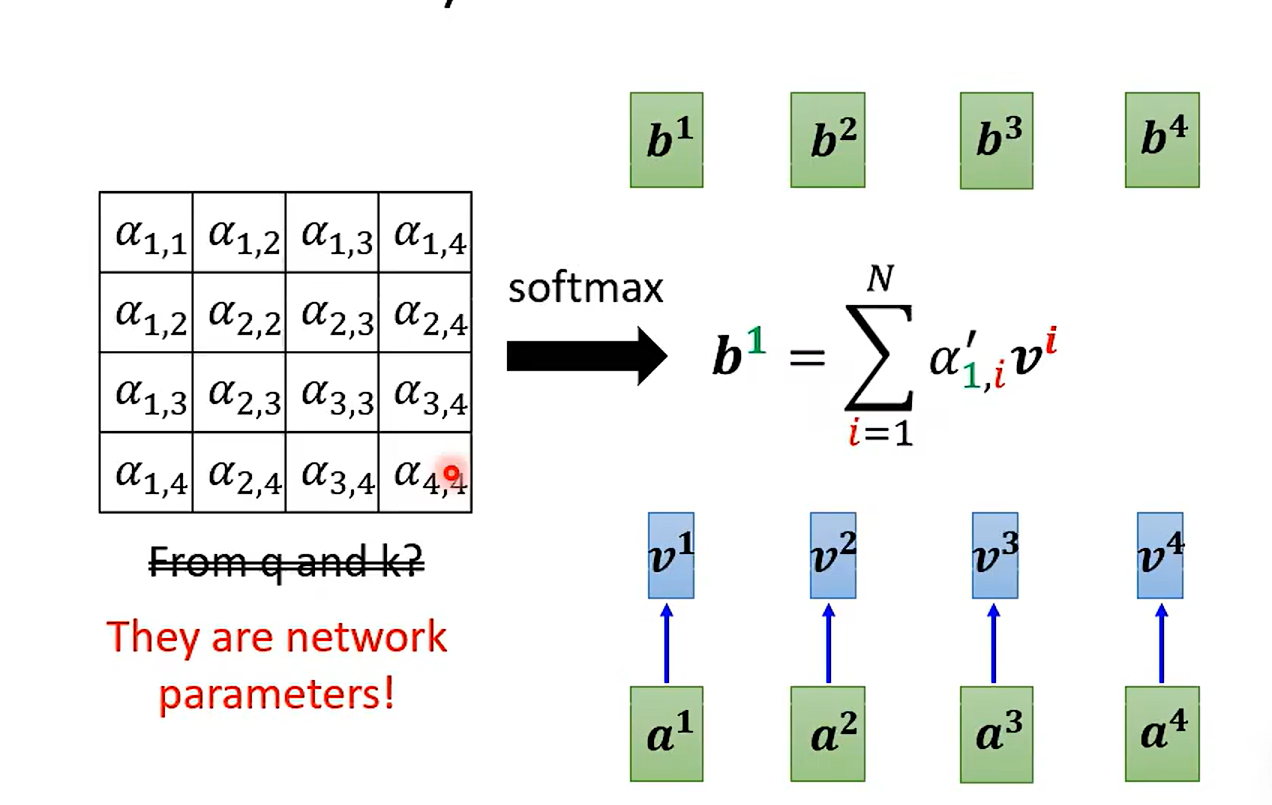
重新思考 attention weight 的价值到底是怎么样的
Attention -Free?