文章目录
- 前言
- 一、Executive Summary
- 1.1 Spectre-v2: Branch Predictor Poisoning
- 1.2 Mitigating Spectre-v2 with Retpolines
- 1.3 Retpoline Concept
- 二、Background
- Exploit Composition
- 三、(Un-)Directing Speculative Execution
- 四、Construction (x86)
- 4.1 Speculation Barriers
- 4.2 jmp 间接跳转
- 4.3 call 间接跳转
- 五、Out-of-line construction (x86)
- 5.1 寄存器 indirect thunk
- 5.2 Linux 内核中的RETPOLINE
- 5.2.1 __indirect_thunk_start / end
- 5.2.2 RETPOLINE / THUNK
- 5.2.3 JMP_NOSPEC / CALL_NOSPEC
- 5.2.4 eBPF retpolines
- 5.2.5 Linux 示例
- 5.2.6 Linux deal with Meltdown/Spectre
- 六、Correctness Details
- 6.1 Return stack underflow
- 6.2 Binaries with shared linkage
- 七、Performance Details
- 7.1 Overhead
- 7.2 Pause usage in support loop
- 7.3 Alignment
- 八、Available Implementations
- Appendix
- Return stack refill (x86)
- Example construction with alignment prefixes
- 参考资料
前言
Spectre-v2 第二种变体:利用间接分支。借鉴了返回导向编程(ROP)的思想,在这种变体中,攻击者从受害者的地址空间中选择一个指令片段(gadget),并影响受害者通过推测执行(speculative execution)来执行该指令片段。与ROP不同,攻击者不依赖于受害者代码中的漏洞。相反,攻击者通过训练分支目标缓冲器(Branch Target Buffer,BTB)来误导间接分支指令到指向该指令片段的地址,从而导致该指令片段的推测执行。虽然不正确的推测执行对CPU的正常状态的影响最终会被恢复,但对缓存的影响却不会被恢复,从而允许该指令片段通过缓存侧信道泄露敏感信息。
为了误导BTB,攻击者会找到受害者地址空间中指令片段(gadget)的虚拟地址,然后执行间接分支到该地址。这种训练是从攻击者的地址空间进行的。攻击者的地址空间中的指令片段地址上的内容并不重要;唯一需要的是攻击者在训练期间的虚拟地址与受害者的虚拟地址匹配(或者是别名)。实际上,只要攻击者处理异常情况,即使在攻击者的地址空间中的指令片段的虚拟地址上没有映射任何代码,攻击仍然可以生效。
相关的处理器架构知识请参考:Spectre-v1 简介以及对应解决措施
一、Executive Summary
谷歌正在研究一种新型漏洞的缓解策略,这些漏洞是由Project Zero团队发现的,会影响到推测执行。我们想分享一个我们开发的用于防范“分支目标注入”(也称为“Spectre”)的二进制修改技术。这个技术基于许多CPU实现了一个专门用于函数返回的预测器。当可用时,这个预测器具有高优先级,可以构建一个对基于推测攻击安全的间接分支。
注意:虽然下面的具体细节和示例有些是针对x86特定的,但构建所依据的思想是普遍适用的。
1.1 Spectre-v2: Branch Predictor Poisoning
现代微处理器:该漏洞影响使用分支预测机制以提高性能的现代微处理器。
恶意应用程序:恶意或不良应用程序故意操纵处理器的间接分支预测器。
预测器训练:恶意应用程序通过重复执行指向特定目标地址的间接分支来"训练"间接分支预测器,这些目标地址通常称为"gadget"代码。Gadget代码通常由现有指令的短序列组成。
错误推测:处理器错误地进行推测,并基于接受的训练预测将间接分支转到gadget代码。
恶意控制:恶意用户控制分支的偏移量,使其能够将现有的特权代码重新用作gadget。这可能导致以更高权限执行意外的指令。
分支预测模糊性:该攻击的成功依赖于分支预测硬件未能完全消除分支目标的模糊性。这种情况发生在不同的分支共享相同的预测器条目时。
共享预测器条目:恶意用户代码中的虚拟地址被构造为与其他应用程序或以更高权限运行的操作系统(OS)内核中的分支重叠。通过这样做,攻击者操纵分支预测器以预测gadget代码的执行。
提取特权数据:一旦执行了gadget代码,攻击者可以利用类似的缓存访问模式进一步利用漏洞。这种提取技术类似于Spectre变体1漏洞。
在这一部分,我们演示了攻击者如何操纵间接分支,并利用导致的间接分支错误预测来读取另一个上下文(例如另一个进程)中的任意内存。在各种架构的程序中,间接分支是常用的。如果延迟确定间接分支的目标地址,例如由于缓存未命中,那么推测执行往往会继续在先前代码执行时预测的位置上进行。
在Spectre第二变体中,攻击者通过恶意目标地址来误导分支预测器,使得推测执行在攻击者选择的位置上继续进行。下图中有所说明,其中分支预测器在一个上下文中(被误)训练,并在另一个上下文中应用预测。具体而言,攻击者可以将推测执行误导到在合法程序执行过程中永远不会出现的位置。由于推测执行会留下可测量的副作用,这对于攻击者来说是一种极为强大的手段,例如即使没有可利用的条件分支错误预测,也能暴露受害者的内存。
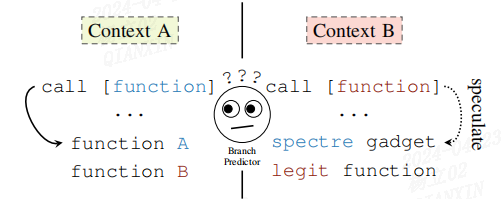
分支预测器在攻击者可控的上下文A中被(误)训练。在上下文B中,分支预测器根据来自上下文A的训练数据进行预测,从而导致在攻击者选择的地址上进行推测执行,该地址对应于受害者地址空间中Spectre指令片段的位置。
在一个简单的示例攻击中,我们考虑一个试图读取受害者内存的攻击者,在间接分支发生时对两个寄存器具有控制权。这在实际的二进制文件中经常发生,因为处理外部接收数据的函数通常在寄存器包含攻击者控制的值时进行函数调用。通常情况下,这些值被被调用函数忽略,而是简单地推送到函数前导部分的堆栈中,并在函数尾部恢复。
攻击者还需要找到一个"Spectre gadget",即一个代码片段,其推测执行将受害者的敏感信息传输到一个隐蔽通道中。对于这个示例,一个简单而有效的指令片段可以由两条指令组成(它们不一定需要相邻),其中第一条指令将由攻击者控制的寄存器R1寻址的内存位置加到攻击者控制的寄存器R2上(或进行异或、减法等操作),然后是任何访问R2中地址的内存的指令。在这种情况下,该指令片段使得攻击者能够通过R1控制泄漏哪个地址,并通过R2控制泄漏的内存如何映射到由第二条指令读取的地址。在我们测试的CPU上,该指令片段必须位于受害者可执行的内存中,以便CPU进行推测执行。然而,由于大多数进程中映射了几兆字节的共享库,攻击者有足够的空间在其中寻找指令片段,甚至无需搜索受害者自己的代码。
根据攻击者所知道或控制的状态、攻击者寻找的信息所在的位置(例如寄存器、栈、内存等)、攻击者控制推测执行的能力、可用于形成指令片段的指令序列以及可以从推测操作中泄漏信息的通道,还有许多其他攻击可能发生。例如,如果攻击者可以简单地诱发推测执行到一个从寄存器指定的地址中获取内存并将其加载到缓存中的指令,那么在寄存器中返回一个秘密值的加密函数可能会变得可利用。同样,尽管上面的示例假设攻击者控制两个寄存器,但攻击者对单个寄存器、栈上的值或内存值的控制足以形成某些指令片段。
在许多方面,攻击类似于返回导向编程(ROP),只是正确编写的软件也存在漏洞,指令片段的持续时间有限但不需要正常终止(因为CPU最终会识别到推测错误),并且指令片段必须通过侧信道泄漏数据,而不是显式地返回。尽管如此,推测执行可以执行复杂的指令序列,包括从栈中读取数据、进行算术运算、分支(包括多次分支)和读取内存。
x86处理器上的错误训练分支预测器。攻击者从自己的上下文中对分支预测器进行错误训练,以诱使处理器在运行受害者代码时推测性地执行小工具。攻击过程模仿了受害者的分支模式,导致分支被误导。
此外,在攻击者和受害者进程中的相同虚拟地址处放置了一个错误训练跳转。注意,这可能不是必要的,例如,如果CPU仅基于跳跃地址的低位对预测进行索引。当对分支预测器进行错误训练时,我们只需要模拟虚拟地址;物理地址、时间和进程ID似乎无关紧要。由于分支预测不受其他核上操作的影响,因此必须在同一CPU核上进行任何错误训练。
分支预测因子从跳到非法目的地的过程中学习。尽管在攻击者的过程中触发了异常,但可以很容易地捕捉到,例如,在Linux上使用信号处理程序或在Windows上使用结构化异常处理程序。与之前的情况一样,分支预测器随后将进行预测,将其他进程发送到相同的目的地地址,但在受害者的虚拟地址空间(即小工具所在的地址空间)中。
1.2 Mitigating Spectre-v2 with Retpolines
"Retpoline"序列是一种软件构造,可以将间接分支与推测执行隔离开来。它可以应用于保护敏感的二进制文件(如操作系统或虚拟化程序实现)免受针对其间接分支的分支目标注入攻击。
“Retpoline"这个名字是"return”(返回)和"trampoline"(蹦床)的混成词。它是使用返回操作构建的蹦床构造,也象征性地确保与之相关的推测执行会无休止地"反弹"。
(1)微码缓解措施是一种有效的方法,但由于实现复杂,成本较高。许多处理器核心没有方便的逻辑来禁用分支预测器,因此需要通过"IBRS"(Indirect Branch Restricted Speculation)机制来禁用核心内部的独立逻辑。在内核进入时,可能需要花费数千个周期来执行这些操作。
(2)Google决定尝试一种纯软件方法的替代解决方案。如果间接分支是导致问题的根源,那么解决方案就是避免使用它们。为此,他们引入了"Retpolines"(返回跳板)的概念,用于替换间接分支的使用。Retpolines通过设置一个虚假的函数调用栈,并在间接调用的位置上执行"返回"操作,来绕过分支预测机制。
这种纯软件方法的解决方案相对较为简单,但可能会对性能产生一定的影响。然而,它提供了一种避免分支预测器污染攻击的替代方案。
然而,Retpolines对操作系统和用户提出了一些挑战:
• 需要重新编译软件,可能需要进行动态修补以在未来的处理器核心上禁用。
Retpolines的使用需要对软件进行重新编译,以适应这种新的解决方案。在未来的处理器核心上禁用Retpolines可能需要进行动态修补,以确保软件在不同的处理器上正常运行。
• 缓解措施应该是临时的,自动在未来的芯片上禁用。
由于Retpolines是为了临时缓解漏洞而设计的,它们应该在未来的芯片上自动禁用。这要求操作系统或处理器能够自动检测到芯片是否支持Retpolines,并在不再需要此缓解措施时禁用它们。
• 处理器核心使用返回栈缓冲区(RSB)来猜测函数的返回路径。
处理器核心通过使用返回栈缓冲区(RSB)来猜测函数的返回路径。这种猜测是为了提高性能。然而,为了避免恶意干扰,需要显式地管理(填充)RSB。管理RSB可以防止恶意代码利用其进行攻击。
• 当RSB下溢发生时,某些核心将使用替代的预测器。
在某些情况下,RSB可能会发生下溢(underflow)。当发生RSB下溢时,某些核心将使用替代的预测器来执行预测,以避免潜在的安全问题。
总之,尽管Retpolines提供了一种解决方案来应对间接分支的安全漏洞,但它们对操作系统和用户提出了一些挑战。重新编译软件、动态修补、管理RSB以及处理RSB下溢等问题需要得到妥善处理,以确保系统的安全性和稳定性。
1.3 Retpoline Concept
对于基于推测执行的侧信道安全问题,缓解措施可分为两类:直接操作推测执行硬件或间接控制推测行为。直接操作硬件通常通过微码更新或操作硬件寄存器来实现。间接控制是通过软件构造来限制或约束推测执行。Retpoline 是一种混合方法,因为它需要更新的微码来使某些处理器型号上的推测执行硬件行为更可预测。然而,retpoline 主要是一种软件构造,利用对底层硬件的特定了解来缓解分支目标注入(Spectre 变种 2)攻击。
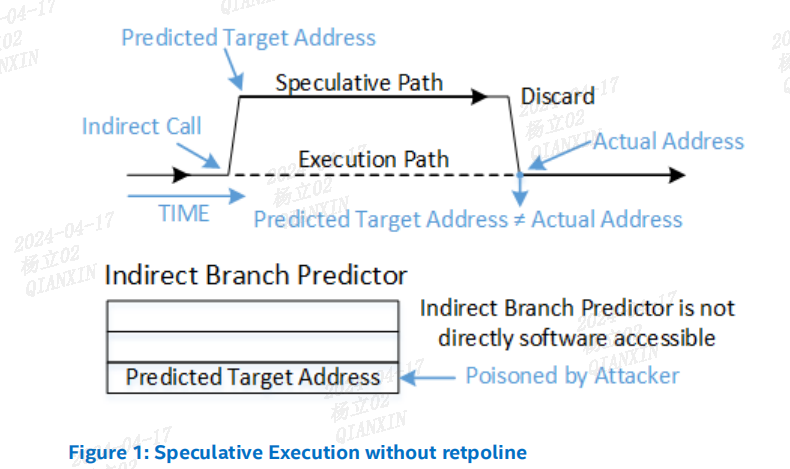
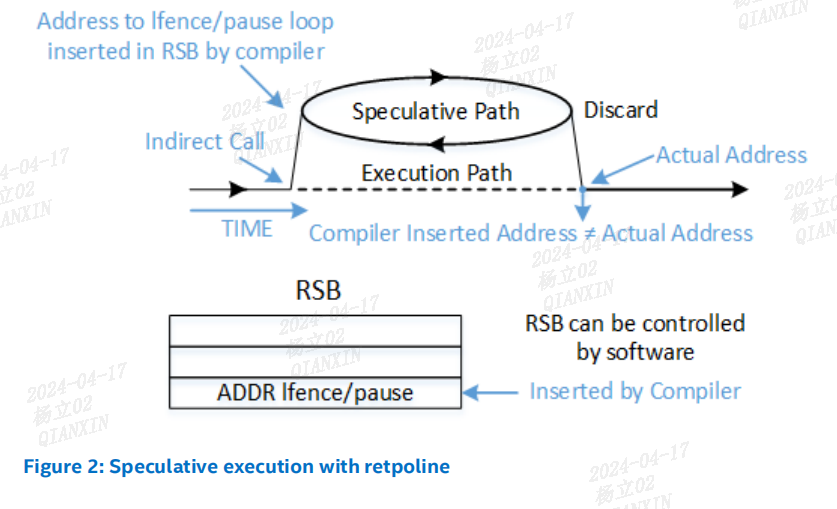
分支目标注入(Spectre 变种 2)攻击依赖于对间接分支的推测目标进行影响。间接的 JMP 和 CALL 指令会查询间接分支预测器,以将推测执行定向到分支最可能的目标。间接分支预测器是一个相对较大的硬件结构,操作系统不能轻易地管理它。为了避免试图管理或预测它的行为,retpoline 是一种绕过间接分支预测器的方法。请参考图 1 和图 2,了解在实施 retpoline 之前和之后的间接分支预测流程。
RET 指令的预测与 JMP 和 CALL 指令不同,因为 RET 首先依赖于返回栈缓冲器(Return Stack Buffer,RSB)。与间接分支预测器不同,RSB 是一个后进先出(LIFO)的堆栈,CALL 指令会将条目“推入”堆栈,而 RET 指令会将条目“弹出”。这种机制可以通过可预测的软件控制进行管理。
对于RSB:比如调用 call 指令时会把 call 指令的下一条指令的地址放入到返回栈缓冲器RSB中,使用分支目标缓冲器来预测 call 指令的目标地址。调用 RET 指令时,会使用返回栈缓冲器中最新的地址来预测 RET 指令的地址。
二、Background
class Base {
public:
virtual void Foo() = 0;
};
class Derived : public Base {
public:
void Foo() override { … }
};
Base* obj = new Derived;
obj->Foo();
在回顾一下,间接分支是指其目标必须在运行时确定的分支,常见的例子包括多态代码或跳转表。在上面的例子中,当调用虚拟方法Foo()时,需要进行动态查找以确定匹配的实现位置。在这种情况下,硬件可能会尝试猜测,而不是等到确定目标之前阻塞推测执行。
不同硬件实现在进行分支预测时所采用的策略各不相同,通常为了减少复杂性并提高性能,它们之间没有进行安全领域的隔离。尽管这种缺乏隔离性曾被用于通过探测预测器的状态来推断其他领域的布局,但以前并没有已知的可观察到的数据副作用。
请注意,通过这些攻击发现可观察到的数据副作用对于安全具有重要影响。这意味着攻击者有可能利用这些副作用来提取敏感信息或操纵系统行为。
为了解决这些漏洞,至关重要的是开发增强安全领域之间隔离性的缓解技术和策略,并防止通过可观察到的数据副作用泄露信息。
现在已经发现了数据副作用,因此可以敌对地偏置对Foo()的推测执行,以便临时地进行类似Variant 1中的“越界检查绕过”这样的操作。
重要的是,这种导向性可能发生在以下情况下:
在同一CPU上的用户和内核执行之间
在同一CPU上的进程之间
在虚拟机和它们的虚拟化程序之间
在SMT或CPU兄弟之间的执行(预测硬件可能是共享的)
虽然这确实描绘了一个暗淡的景象,但攻击者必须克服两个重要的障碍:
(1)被指向的受害者间接执行的gadget必须存在于受害者的地址空间中。这意味着攻击者需要详细了解受害者的二进制文件和其当前的地址空间布局。如果没有这些信息,确定要利用的适当gadget将变得更加困难。
(2)必须存在一种渠道,可以观察到上述gadget的副作用。在没有攻击者可访问的与受害者之间的共享内存映射的情况下,这变得更加具有挑战性。没有这样的通道,攻击者将难以收集必要的信息或观察到被利用的gadget的效果。
果不满足这两个条件中的任何一个,攻击的复杂性将大大增加。尽管这种情况对于大多数二进制文件来说是有益的,但有几类软件更容易满足这些先决条件。主要的例子是主机操作系统:在这里,即使不知道确切的操作系统版本,仍然存在大量的共同点可以进行有针对性的攻击(例如,在Linux或Windows版本之间)。此外,在这个例子中,应用程序自己的地址空间代表了与托管操作系统共享的通道,可以用来清除第二个障碍。(值得注意的是,硬件保护技术如SMAP在这种情况下可能被绕过,因为操作系统的直接映射可以用作触发缓存出现的别名。)
很遗憾,在构建这种软件时,避免使用间接分支是不切实际和不合理的。这意味着我们需要一种有效的方法来构建一个间接分支,该分支在其执行结束时不受外部操纵的影响。
Exploit Composition
使用分支目标注入(Spectre变种2)的攻击由五个特定要素组成,所有这些要素都是成功利用的必要条件。对于非安全敏感的传统应用软件,在应用缓解措施之前,需要仔细评估这五个要素。
(1)攻击的目标(受害者)必须具有某些需要攻击获取的秘密数据。对于操作系统内核而言,这包括用户权限之外的任何数据,例如内核内存映射中的内存。
(2)攻击需要有一种引用秘密数据的方法。通常,这是受害者地址空间中的一个指针,可以使其引用秘密数据的内存位置。在攻击和受害者之间传递一个指针的明显通信渠道是满足这个条件的一种直接方式。
(3)在受害者的代码执行期间,攻击的引用必须可用于包含易受攻击的间接分支的部分代码中。例如,如果攻击的指针值存储在一个寄存器中,攻击者的目标是使得推测执行跳转到一个代码序列,其中该寄存器被用作移动操作的源地址。
(4)攻击必须成功地影响这个间接分支,使其在推测执行时出现错误预测,并执行一个由攻击者选择的gadget。这个gadget通过一个侧信道(通常是缓存时间)泄露秘密数据。
(5)这个gadget必须在“推测窗口”内执行,在处理器确定gadget的执行是错误预测之前,该窗口关闭。
“retpoline” 缓解措施被用于缓解 Spectre 变种 2 攻击中易受攻击的间接分支(第 4 个要素),对其他要素没有影响。但由于攻击依赖于满足所有五个要素,移除第 4 个要素足以阻止分支目标注入(Spectre 变种 2)攻击。
三、(Un-)Directing Speculative Execution
问题的关键在于,如果我们想将控制权转移到运行时目标,我们最终必须执行某种形式的间接分支。
jmp *%rax; /* indirect branch to the target referenced by %rax */
虽然像序列化这样的策略可能会减少尚未加载%rax的执行窗口(例如,考虑之前未完成的加载),但这里的推测执行是硬件本身的属性。我们无法直接指示CPU我们要将控制权转移到%rax中包含的地址,但其推测执行可能无法猜测该地址是什么。即使它可以立即解析。
这就需要采用一种不同的方法:虽然我们无法在软件中阻止推测执行,但如果我们能够控制它会怎样呢?就像潜在的攻击者可能使用分支目标注入来操纵硬件预测逻辑一样,如果我们能够执行自己的注入,并确保它优先于任何潜在的外部操纵,会怎么样呢?
请记住,函数返回本身就是一种间接分支。然而,与其他间接分支不同,函数返回的目标可以直接缓存以进行准确的未来预测,位于函数调用点。还有一个有用的特点是查找可以被实现为围绕调用和返回的简单堆栈。由于这种方法成本低、准确度高且频率高,因此在某种形式上非常常见。具体的例子包括Intel CPU上的返回堆栈缓冲区(RSB)、AMD CPU上的返回地址堆栈(RAS)和ARM上的返回堆栈。
以下是针对x86类型架构的确切构造,但除了使用返回预测来控制推测执行路径的核心思想外,没有其他关键依赖。
四、Construction (x86)
在x86架构中,函数调用和返回是使用call和ret指令来实现的。call接受一个目标地址(可以是直接或间接地址),并将执行分支到该目标地址,而ret则返回(到call指令后面的指令 – call指令的下一条指令的地址)最近的函数调用。在实现中,call会将返回目标地址推送到堆栈中,然后执行分支。
这里的关键属性是硬件对于返回目标地址的缓存(RSB)和实际目标地址(维护在堆栈上)是不同的。RSB条目是硬件的细节,对于底层应用程序来说是不可见的。然而,我们可以通过操纵RSB的生成来控制推测执行,同时修改可见的堆栈上的值,以指示如何实际 retired 分支。
这里对于间接跳转类型的分支类型,目标地址通过来自寄存器,可能经常变化,分支目标缓冲器很难预测。但是,对于大部分间接跳转分支指令是用于进行子程序调用的 call/return 指令,这两条指令有规律可循。
对于 call 指令可以使用分支目标缓冲器(Branch Target Buffer ,BTB)来预测。
对于 return 指令可以使用返回栈缓冲器(Return Stack Buffer,RSB)中最新地地址来预测。
每条call指令每次调用子程序比如 printf()函数 是固定的,printf()函数是标准的库函数,它的入口地址是固定的,不同的函数调用了 printf()函数,虽然这些函数调用call指令的PC值不同,但是目标地址是固定的,即printf()函数的入口地址,因此使用分支目标缓冲器(Branch Target Buffer ,BTB)可以比较准确地预测 call 指令地目标地址,因此对应目标PC固定可用BTB进行预测。
但对于子程序可能很多地方都需要调用它,故子程序的返回地址可能会发生变化,但是return指令的目标地址总是最近一次执行call指令的下一条指令。因此我们可以设计一个后进先出存储器(LIFO)保存最近执行call指令的下一条指令地址,该存储器的工作原理与软件中的堆栈一样,故称为返回栈缓冲器(Return Stack Buffer,RSB),都是现代处理器中几乎必须要使用的。
4.1 Speculation Barriers
retpoline 序列中包含的指令可能存在性能方面的考虑(LFENCE 和 PAUSE)。尽管如此,retpoline 仍然具有吸引人的性能特性。
LFENCE 的架构规范定义了在所有前面的指令完成之前它不执行,并且在 LFENCE 完成之前不会开始执行后续指令。这个规范限制了处理器实现在 LFENCE 周围可以执行的推测执行,可能会影响处理器性能,但同时也创造了一种工具来缓解推测执行的侧信道攻击。
尽管 LFENCE 和 PAUSE 可能会对处理器性能产生一定影响,但 retpoline 仍然可以具有吸引人的性能特性,因为它提供了一种有效的方式来缓解推测执行的侧信道攻击。
然而,这种架构定义的推测控制行为仅在处理器实际执行(retires)LFENCE 时才需要。一个在推测执行中实际上从未执行(retires)的 LFENCE 可能具有较小的性能影响,因为推测行为不是由架构定义的。LFENCE(以及 retpoline 构造中影响推测执行的其他指令)只在推测执行中执行,因此可能不会显示出通常与推测屏障相关的性能影响。这使得 retpoline 能够对推测执行产生影响,而不会带来传统上直接影响推测的指令所带来的开销。
4.2 jmp 间接跳转
现在我们来具体构建这个方法。首先,让我们考虑一个间接分支到*%r11。然后,我们将使用这个作为构建间接调用的基本模块。
部署retpoline需要用不易受攻击的retpoline序列替换易受攻击间接分支。最简单的retpoline序列是对单个间接JMP指令的替换。
Before retpoline:
jmp *%r11
使用Indirect branch thunk来修复 jmp 间接跳转Spectre-v2漏洞。
方法就是:就像潜在的攻击者可能使用分支目标注入来操纵硬件预测逻辑一样,如果我们能够执行自己的注入,并确保它优先于任何潜在的外部操纵。
After retpoline:
call set_up_target; (1) //生成RSB条目
capture_spec: (4)
pause;lfence //无害的无限循环供CPU推测
jmp capture_spec;
set_up_target:
mov %r11, (%rsp); (2) //修改返回堆栈以强制“返回”到目标
ret; (3) //推测执行会使用步骤1生成的RSB条目
在本例中,跳转到存储在%r11寄存器中的指令地址。在没有retpoline的情况下,处理器的推测执行通常参考间接分支预测器,并且可以推测到由漏洞控制的地址(满足Exploit Composition这一节列出的分支目标注入(Spectre变体2)漏洞组合的五个元素中的元素4)。
这个retpoline序列的推测性执行是:步骤(3)ret 指令。
retpoline序列更为复杂,分几个阶段工作,以将推测性执行与非推测性执行分开:
- 直接调用set_up_target函数;这个调用在编译时是已知的,不会触发推测目标解析。这会生成具有返回目标为capture_spec的不同堆栈和RSB条目。
call set_up_target = push capture_spec + jmp set_up_target
call指令执行时,将call指令的下一条指令capture_spec的地址作为返回地址压入到栈中,然后跳转到set_up_target执行,即将程序计算器(PC)设置为set_up_target的起始位置。
call指令执行时,是一个函数执行,会生成函数调用栈。
capture_spec是一个 lable,其地址也就是pause;lfence指令的地址。
-
修改由步骤1 call 指令生成的堆栈上的条目,将其rsp指向%r11。将将栈顶指针rsp修改为真正的跳转目标r11。
需要注意的是,这不会影响上面生成的RSB条目,其目标仍然是capture_spec。 -
返回到我们最初的调用位置。
ret = pop(capture_spec的地址) + jmp (capture_spec的地址)
ret指令执行时,从栈中弹出call指令的下一条指令capture_spec的地址,把程序计算器(PC)设置为capture_spec的地址。
ret间接跳转会引起推测执行,根据return stack预测器给出的预测结果,会推测执行(4),而
(4)处的指令序列会把推测执行引诱到一个无限pause循环中。
如果正在推测执行,CPU 使用步骤 1 中创建的 RSB 条目,并跳转到 “: pause ; lfence”。它陷入一个无限循环中。关于此序列的重要性,可以参考"Speculation Barriers" 部分了解更多细节。
a:推测执行会使用步骤1生成的RSB条目,并在第4步的循环中被捕获。这些指令只会由推测路径执行。
b:最终我们的返回指令被实际retired,堆栈上的值被用来定位实际的新指令指针,并丢弃在第4步循环中的推测执行带来的无害结果。
即(4)处的指令序列会把推测执行引诱到一个无限pause循环中。当ret指令retire时,从栈顶弹出真正的目标地址到rip,然后取消已经陷入到pause循环中的推测执行。因此,即使恶意代码已经事先污染了RSB中的表项,至少indirect thunk本身的实现是不会成为被利用的目标的。
- 最终,CPU 发现推测的 RET 与内存中的栈值不一致,推测执行被停止。执行跳转到 *%r11。
重要的是,在上述的执行过程中,并没有任何时候可以通过外部攻击者来控制推测执行,同时实现我们间接跳转的目标。
通过仔细地操作堆栈和RSB条目,我们可以在程序本身的范围内控制推测执行的路径。这种内部控制确保推测执行按照所期望的间接分支目标进行,而不受外部攻击者试图操纵推测执行的影响。
这个过程中,我们通过利用推测执行的特性,成功地控制了程序的执行路径。在推测执行的过程中,通过修改堆栈上的值,我们实现了对目标地址的控制。而在实际退休时,我们使用堆栈上的值来定位实际的指令指针,并丢弃推测执行带来的结果。
4.3 call 间接跳转
间接CALL更为复杂,但使用相同的方法,如下所示:
Before retpoline:
call *%r11
After retpoline:
使用indirect call thunk来修复 call 间接跳转Spectre-v2漏洞。
jmp set_up_return;
inner_indirect_branch:
call set_up_target; }
capture_spec: }
pause;lfence }
jmp capture_spec; } Indirect branch sequence.
set_up_target: }
mov %r11, (%rsp); }
ret; }
set_up_return:
call inner_indirect_branch; (1)
… continue execution (2)
在这里我们使用了两个函数调用 calls 。与间接分支不同,函数调用的情况下,我们的目标需要能够最终返回控制权。外部的函数调用设置了将用于此目的的返回框架,而内部使用上面的间接分支构造来执行实际的控制转移。这具有特别好的属性,即(1)所安装的RSB条目和堆栈上的目标既有效又被使用。这允许正确预测返回,使得我们模拟的间接跳转成为唯一引入的开销。
接下来详细描述:
Before retpoline:
call *%rax
After retpoline:
1: jmp label2
label0:
2: call label1
capture_ret_spec:
3: pause ; lfence
4: jmp capture_ret_spec
label1:
5: mov %rax, (%rsp)
6: ret
label2:
7: call label0
8: … continue execution
(1)“1: jmp label2” 跳转到 “7: call label0”。
(2)“7: call label0” 将 “8: … continue execution” 的地址推入栈和 RSB,然后跳转到:
(3)“2: call label1” 将 “3: pause ; lfence” 的地址推入栈和 RSB,然后跳转到:

(4)“5: mov %rax, (%rsp)” 获取间接调用的目标地址(存储在 %rax 寄存器中),并将其覆盖在存储在栈中的返回地址上。此时,内存中的栈和 RSB 不同。
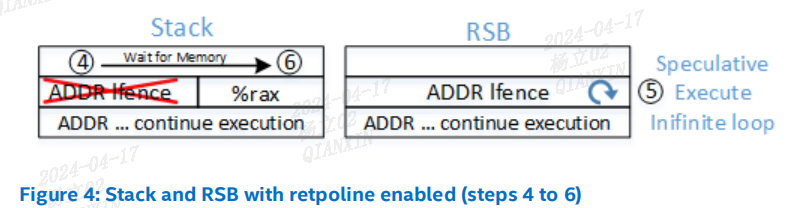
(5)“6: ret”。如果正在推测执行,CPU 使用步骤 3 中创建的 RSB 条目,并跳转到 “3: pause ; lfence”。它陷入一个无限循环中。关于此序列的重要性,可以参考"Speculation Barriers" 部分了解更多细节。
(6)最终,CPU 发现推测的 RET 与内存中的栈值不一致,推测执行被停止。执行跳转到间接调用的目标地址:*%rax,该地址在步骤 4 中放置在栈上。
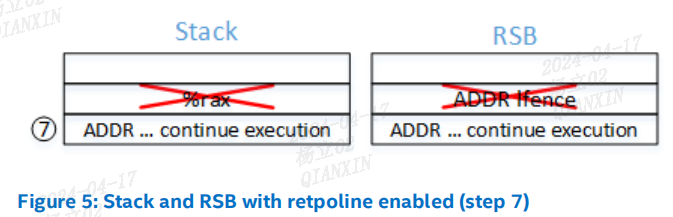
(7)间接调用的目标返回,消耗了在步骤 2 中放置在 RSB 和内存栈中的条目。
五、Out-of-line construction (x86)
5.1 寄存器 indirect thunk
上述构造可以作为任何间接分支的就地替换。它与共享代码(或其他重新定位的代码)兼容,因为新的序列是位置无关的。通过共享跳板序列的协调,可以改进该构造,使得间接调用不需要逐个复制上述构造。挑战在于我们需要一个向量来将间接目标传递给跳板,因为加载必须在控制转移之后进行。可以通过“每个目标”跳板来实现这一点,将目标编码到入口点中。
这种方法中,"每个目标"跳板是一组共享的跳板序列,每个跳板都对应一个特定的间接目标。在跳板的入口点,可以将目标地址编码到跳板的具体实现中。当需要进行间接跳转时,只需将目标的索引或标识传递给相应的跳板,跳板会根据索引或标识在内部解码并跳转到正确的目标地址。
这种方法的好处是,它避免了每个间接调用都需要复制整个构造的问题,而是共享了一个跳板序列。通过使用跳板的索引或标识来传递目标,可以高效地进行间接跳转。
在部署 retpoline 时的一种选择是让编译器在每个需要进行缓解的间接分支处插入完整的 retpoline 序列。然而,这会使代码变得比实际需要的更大,因此首选的选项是让程序自身在一个中心位置提供 retpoline 序列,然后让编译器引用这些序列。这样可以减少冗余的代码生成,并提高代码的可维护性和可移植性。例如,程序可能在名为retpoline_r11_trampoline的位置提供上面 4.2节和4.3节 中所示的序列。
Retpoline将这些间接跳转/调用指令分别替换为对“使用r11寄存器作为跳转目标的通用indirect thunk”的跳转和调用:
| Out of line construction | |
|---|---|
| jmp *%r11 call *%r11 | jmp retpoline_r11_trampoline; call retpoline_r11_trampoline; |
该程序还可以为许多可能的调用指令可能性提供重新轮询序列,例如用于对存储在每个通用寄存器中的目标进行调用。
这种方法在每个间接调用点提供了更紧凑的指令序列,并将 retpoline 实现集中到一组受控的位置上。支持运行时修补的程序(如 Linux 内核)可以评估系统是否容易受到分支目标注入(Spectre 变体 2)的攻击。如果系统不容易受到攻击(例如在旧处理器或实施了增强型 IBRS 缓解措施的未来处理器上),程序提供的 retpoline 序列可以被替换为非缓解序列。
通过这种方式,可以根据系统的安全需求和处理器的支持情况,在运行时灵活地选择使用缓解措施或非缓解措施的 retpoline 序列,从而在性能和安全之间做出权衡。
Shared Trampoline:
retpoline_r11_trampoline:
call set_up_target;
capture_spec:
pause;
jmp capture_spec;
set_up_target:
mov %r11, (%rsp);
ret;
以上的序列可以复制以支持偏移量编码,例如 retpoline_60_rcx_trampoline,它会加载 0x60 + (%rcx)。另外,编译器也可以只使用单个序列,在调用外部跳板之前,在一个一致的目标(例如,已知寄存器)中实现目标地址。
对于支持偏移量编码的情况,可以通过复制和修改现有的序列来实现。例如,可以复制原始的构造序列,并在加载目标地址之前添加一个偏移量。这样,在跳转之前,可以通过计算偏移量并与目标寄存器的值相加,来得到最终的目标地址。
另一种方法是编译器可以在调用外部跳板之前,将目标地址存储在一个已知的寄存器中。这样,在调用跳板之前,可以使用这个已知的寄存器中的值来构造跳板的参数。这样一来,就不需要在跳板内部解码目标地址,而是直接使用已知寄存器中的值作为目标地址。
编译器或者内核可以实现将所有可能的寄存器当做间接跳转/调用目标的indirect thunk,比如为rax, rdx, rcx, rbx, rsi, rdi, rbp, r8, r9, r10, r11, r12, r13, r14和r15寄存器都各自实现一个特定寄存器的indirect thunk。但由于使用内存地址作为间接跳转/调用目标的indirect thunk理论上太多,不可能为每一种可能的地址都实现一个indirect thunk,因此需要编译器能够将所有用内存地址作为间接跳转/调用目标的指令转换为使用寄存器作为目标的间接跳转/调用指令。
# uname -r
5.15.0-101-generic
# cat /boot/config-5.15.0-101-generic | grep CONFIG_RETPOLINE
CONFIG_RETPOLINE=y
# cat /proc/kallsyms | grep __x86_indirect_thunk
ffffffffa6402380 T __x86_indirect_thunk_array
ffffffffa6402380 T __x86_indirect_thunk_rax
ffffffffa64023a0 T __x86_indirect_thunk_rcx
ffffffffa64023c0 T __x86_indirect_thunk_rdx
ffffffffa64023e0 T __x86_indirect_thunk_rbx
ffffffffa6402400 T __x86_indirect_thunk_rsp
ffffffffa6402420 T __x86_indirect_thunk_rbp
ffffffffa6402440 T __x86_indirect_thunk_rsi
ffffffffa6402460 T __x86_indirect_thunk_rdi
ffffffffa6402480 T __x86_indirect_thunk_r8
ffffffffa64024a0 T __x86_indirect_thunk_r9
ffffffffa64024c0 T __x86_indirect_thunk_r10
ffffffffa64024e0 T __x86_indirect_thunk_r11
ffffffffa6402500 T __x86_indirect_thunk_r12
ffffffffa6402520 T __x86_indirect_thunk_r13
ffffffffa6402540 T __x86_indirect_thunk_r14
ffffffffa6402560 T __x86_indirect_thunk_r15
5.2 Linux 内核中的RETPOLINE
大多数间接分支是由编译器在构建二进制代码时生成的。因此,部署 retpoline 需要重新编译需要进行缓解的软件。支持 retpoline 的编译器可以避免生成任何存在漏洞的间接 CALL 或间接 JMP 指令,而是使用 retpoline 序列。当然,对于由编译器生成的代码以外的代码(例如内联汇编),程序员必须手动插入 retpoline 序列。
CONFIG_RETPOLINE
5.2.1 __indirect_thunk_start / end
// linux-5.15/arch/x86/kernel/vmlinux.lds.S
#ifdef CONFIG_RETPOLINE
__indirect_thunk_start = .;
*(.text.__x86.indirect_thunk)
__indirect_thunk_end = .;
#endif
// linux-5.15/arch/x86/include/asm/nospec-branch.h
extern char __indirect_thunk_start[];
extern char __indirect_thunk_end[];
# cat /proc/kallsyms | grep _indirect_thunk
ffffffffa640237f T __indirect_thunk_start
ffffffffa6402380 T __x86_indirect_thunk_array
ffffffffa6402380 T __x86_indirect_thunk_rax
ffffffffa64023a0 T __x86_indirect_thunk_rcx
ffffffffa64023c0 T __x86_indirect_thunk_rdx
ffffffffa64023e0 T __x86_indirect_thunk_rbx
ffffffffa6402400 T __x86_indirect_thunk_rsp
ffffffffa6402420 T __x86_indirect_thunk_rbp
ffffffffa6402440 T __x86_indirect_thunk_rsi
ffffffffa6402460 T __x86_indirect_thunk_rdi
ffffffffa6402480 T __x86_indirect_thunk_r8
ffffffffa64024a0 T __x86_indirect_thunk_r9
ffffffffa64024c0 T __x86_indirect_thunk_r10
ffffffffa64024e0 T __x86_indirect_thunk_r11
ffffffffa6402500 T __x86_indirect_thunk_r12
ffffffffa6402520 T __x86_indirect_thunk_r13
ffffffffa6402540 T __x86_indirect_thunk_r14
ffffffffa6402560 T __x86_indirect_thunk_r15
ffffffffa64026c2 T __indirect_thunk_end
5.2.2 RETPOLINE / THUNK
// linux-5.15/arch/x86/include/asm/cpufeatures.h
#define X86_FEATURE_RETPOLINE ( 7*32+12) /* "" Generic Retpoline mitigation for Spectre variant 2 */
#define X86_FEATURE_RETPOLINE_AMD ( 7*32+13) /* "" AMD Retpoline mitigation for Spectre variant 2 */
// linux-5.15/arch/x86/lib/retpoline.S
.section .text.__x86.indirect_thunk
.macro RETPOLINE reg
ANNOTATE_INTRA_FUNCTION_CALL
call .Ldo_rop_\@
.Lspec_trap_\@:
UNWIND_HINT_EMPTY
pause
lfence
jmp .Lspec_trap_\@
.Ldo_rop_\@:
mov %\reg, (%_ASM_SP)
UNWIND_HINT_FUNC
ret
.endm
.macro THUNK reg
.align 32
SYM_FUNC_START(__x86_indirect_thunk_\reg)
ALTERNATIVE_2 __stringify(ANNOTATE_RETPOLINE_SAFE; jmp *%\reg), \
__stringify(RETPOLINE \reg), X86_FEATURE_RETPOLINE, \
__stringify(lfence; ANNOTATE_RETPOLINE_SAFE; jmp *%\reg), X86_FEATURE_RETPOLINE_AMD
SYM_FUNC_END(__x86_indirect_thunk_\reg)
.endm
.......
// linux-5.15/arch/x86/include/asm/nospec-branch.h
/*
* Despite being an assembler file we can't just use .irp here
* because __KSYM_DEPS__ only uses the C preprocessor and would
* only see one instance of "__x86_indirect_thunk_\reg" rather
* than one per register with the correct names. So we do it
* the simple and nasty way...
*
* Worse, you can only have a single EXPORT_SYMBOL per line,
* and CPP can't insert newlines, so we have to repeat everything
* at least twice.
*/
#define __EXPORT_THUNK(sym) _ASM_NOKPROBE(sym); EXPORT_SYMBOL(sym)
#define EXPORT_THUNK(reg) __EXPORT_THUNK(__x86_indirect_thunk_ ## reg)
这段代码展示了一些宏定义,用于创建x86间接跳转thunk和Retpoline序列。
(1)RETPOLINE 宏定义了一个用于创建Retpoline序列的代码块。它包含以下步骤:
ANNOTATE_INTRA_FUNCTION_CALL:在函数内部调用之前进行注释。
call .Ldo_rop_\@:调用.Ldo_rop_\@标签处的代码段。
.Lspec_trap_\@:无操作(Unwind Hint)、暂停(pause)、屏障(lfence)和跳转至.Lspec_trap_\@标签处,用于防止Spectre攻击。
.Ldo_rop_\@:将寄存器\reg的值存储在栈中,然后返回。
(2)THUNK 宏定义了一个用于创建x86间接跳转thunk的代码块。它包含以下步骤:
.align 32:以32字节对齐。
SYM_FUNC_START:定义了一个以__x86_indirect_thunk_\reg为名称的函数起始点。
ALTERNATIVE_2:根据处理器的支持情况选择合适的指令序列。
SYM_FUNC_END:定义了函数的结束点。
这些宏的目的是创建一个安全的间接跳转thunk和Retpoline序列。间接跳转thunk用于保护间接跳转指令,而Retpoline序列用于防御Spectre攻击。
5.2.3 JMP_NOSPEC / CALL_NOSPEC
// linux-5.15/arch/x86/include/asm/nospec-branch.h
/*
* This should be used immediately before an indirect jump/call. It tells
* objtool the subsequent indirect jump/call is vouched safe for retpoline
* builds.
*/
.macro ANNOTATE_RETPOLINE_SAFE
.Lannotate_\@:
.pushsection .discard.retpoline_safe
_ASM_PTR .Lannotate_\@
.popsection
.endm
/*
* JMP_NOSPEC and CALL_NOSPEC macros can be used instead of a simple
* indirect jmp/call which may be susceptible to the Spectre variant 2
* attack.
*/
.macro JMP_NOSPEC reg:req
#ifdef CONFIG_RETPOLINE
ALTERNATIVE_2 __stringify(ANNOTATE_RETPOLINE_SAFE; jmp *%\reg), \
__stringify(jmp __x86_indirect_thunk_\reg), X86_FEATURE_RETPOLINE, \
__stringify(lfence; ANNOTATE_RETPOLINE_SAFE; jmp *%\reg), X86_FEATURE_RETPOLINE_AMD
#else
jmp *%\reg
#endif
.endm
.macro CALL_NOSPEC reg:req
#ifdef CONFIG_RETPOLINE
ALTERNATIVE_2 __stringify(ANNOTATE_RETPOLINE_SAFE; call *%\reg), \
__stringify(call __x86_indirect_thunk_\reg), X86_FEATURE_RETPOLINE, \
__stringify(lfence; ANNOTATE_RETPOLINE_SAFE; call *%\reg), X86_FEATURE_RETPOLINE_AMD
#else
call *%\reg
#endif
.endm
这段代码展示了一些宏定义,用于在间接跳转/调用之前进行注释和选择合适的指令序列。
(1)ANNOTATE_RETPOLINE_SAFE 宏用于在间接跳转/调用之前添加注释,告诉objtool这个后续的间接跳转/调用在retpoline构建中是安全的。它将在.discard.retpoline_safe节中添加一个指向.Lannotate_@标签的指针。
(2)JMP_NOSPEC 宏用于代替可能容易受到Spectre变种2攻击的简单间接jmp。它根据配置和处理器支持情况选择合适的指令序列。
如果配置了CONFIG_RETPOLINE且处理器支持Retpoline技术,将使用ANNOTATE_RETPOLINE_SAFE; jmp *%\reg序列进行间接jmp。
如果不满足上述条件,将使用简单的jmp *%\reg指令。
(3)CALL_NOSPEC 宏与JMP_NOSPEC类似,用于代替可能受到Spectre变种2攻击的简单间接call。它也根据配置和处理器支持情况选择合适的指令序列。
如果配置了CONFIG_RETPOLINE且处理器支持Retpoline技术,将使用ANNOTATE_RETPOLINE_SAFE; call *%\reg序列进行间接call。
如果不满足上述条件,将使用简单的call *%\reg指令。
这些宏的目的是在进行间接跳转/调用之前添加注释,并根据配置和处理器支持情况选择合适的指令序列,以提供对Spectre变种2攻击的防护。
5.2.4 eBPF retpolines
// linux-5.15/arch/x86/include/asm/nospec-branch.h
/*
* Below is used in the eBPF JIT compiler and emits the byte sequence
* for the following assembly:
*
* With retpolines configured:
*
* callq do_rop
* spec_trap:
* pause
* lfence
* jmp spec_trap
* do_rop:
* mov %rcx,(%rsp) for x86_64
* mov %edx,(%esp) for x86_32
* retq
*
* Without retpolines configured:
*
* jmp *%rcx for x86_64
* jmp *%edx for x86_32
*/
#ifdef CONFIG_RETPOLINE
# ifdef CONFIG_X86_64
# define RETPOLINE_RCX_BPF_JIT_SIZE 17
# define RETPOLINE_RCX_BPF_JIT() \
do { \
EMIT1_off32(0xE8, 7); /* callq do_rop */ \
/* spec_trap: */ \
EMIT2(0xF3, 0x90); /* pause */ \
EMIT3(0x0F, 0xAE, 0xE8); /* lfence */ \
EMIT2(0xEB, 0xF9); /* jmp spec_trap */ \
/* do_rop: */ \
EMIT4(0x48, 0x89, 0x0C, 0x24); /* mov %rcx,(%rsp) */ \
EMIT1(0xC3); /* retq */ \
} while (0)
5.2.5 Linux 示例
#ifdef CONFIG_X86_64
static __always_inline bool do_syscall_x64(struct pt_regs *regs, int nr)
{
/*
* Convert negative numbers to very high and thus out of range
* numbers for comparisons.
*/
unsigned int unr = nr;
if (likely(unr < NR_syscalls)) {
unr = array_index_nospec(unr, NR_syscalls);
regs->ax = sys_call_table[unr](regs);
return true;
}
return false;
}
......
__visible noinstr void do_syscall_64(struct pt_regs *regs, int nr)
{
nr = syscall_enter_from_user_mode(regs, nr);
......
do_syscall_x64(regs, nr)
......
syscall_exit_to_user_mode(regs);
}
#endif
do_syscall_64()
-->syscall_enter_from_user_mode()
-->do_syscall_x64()
-->sys_call_table[]
-->syscall_exit_to_user_mode()
# cat /boot/System.map-5.15.0-101-generic | grep do_syscall_64
ffffffff81d7c430 T do_syscall_64
ffffffff81d7c430: 55 push %rbp
......
ffffffff81d7c462: e8 89 47 00 00 call 0xffffffff81d80bf0
......
ffffffff81d7c487: e8 f4 5e 28 00 call 0xffffffff82002380
......
ffffffff81d7c494: e8 d7 47 00 00 call 0xffffffff81d80c70
do_syscall_x64用__always_inline修饰,因此call do_syscall_x64其实是call sys_call_table。
call sys_call_table对应:
ffffffff81d7c487: e8 f4 5e 28 00 call 0xffffffff82002380
# cat /boot/System.map-5.15.0-101-generic | grep ffffffff82002380
ffffffff82002380 T __x86_indirect_thunk_array
ffffffff82002380 T __x86_indirect_thunk_rax
5.2.6 Linux deal with Meltdown/Spectre
Linux 主线版本 4.15 处理了Meltdown/Spectre(这个版本只解决SpectreV2)。
这个版本包含了最新的代码来应对 Meltdown/Spectre,这是一种您可能从未听说过的安全问题。针对 Meltdown,支持了针对 x86/Intel CPU 的页面表隔离(可以通过内核引导选项 pti=off 来禁用);同时还引入了 retpoline 机制来缓解 Spectre v2(影响 Intel 和 AMD),它需要支持 -mindirect-branch=thunk-extern 功能的 GCC 版本,可以通过引导选项 spectre_v2=off 关闭该功能(如果您没有这样的编译器,内核代码中将存在一种最小的汇编级 retpoline 缓解措施)。PowerPC 架构的许多 CPU 型号也受到了 Meltdown 的影响,本版本包含了用于防止这些攻击的 “RFI flush of L1-D cache” 特性。ARM 也受到 Meltdown 的影响,但相关补丁未包含在此版本中。此版本中没有解决 Spectre v1。
在 /sys/devices/system/cpu/vulnerabilities/ 目录下新增了一个功能,它将显示影响您的 CPU 的漏洞以及当前应用的缓解措施。
retpoline commit:
(1)x86/retpoline: Add initial retpoline support:
在更新的GCC中启用-mindirectbranch=thunk-extern,并提供相应的thunk。提供汇编程序宏,以与GCC相同的方式从本机和内联汇编程序调用thunks。
这会添加X86_FEATURE_RETOLINE,并在所有CPU上默认设置它。在某些情况下,可以使用IBRS微码功能,并且可以禁用retpoline。
在AMD CPU上,如果lfence是串行的,则可以将retpoline显著简化为简单的“lfence;jmp*\reg”。在验证lfence在所有情况下都是串行的之后,未来的补丁可以通过另外设置X86_FEATURE_RETOLINE_AMD功能位来启用此功能
到X86_FEATURE_REPOLINE。
不要对齐altinstr部分中的retpoline,因为在替代修补过程中,无法保证在oldinstr上复制时保持对齐。
(2)x86/spectre: Add boot time option to select Spectre v2 mitigation:
添加spectre_v2=选项以选择用于间接分支推测漏洞的缓解措施。
目前,唯一可用的选项是各种形式的retpoline。这将扩展到包括新的IBRS/IBPB微码功能。
RETPOLINE_AMD功能依赖于用于推测控制的序列化LFENCE。对于AMD硬件,仅当LFENCE是由LFENCE_RDTSC功能指示的串行化指令时,才设置RETPOLINE_AMD。
六、Correctness Details
6.1 Return stack underflow
在函数返回过程中,函数返回本身就是一种间接分支。具体而言,在这里我们指的不是上述构造的返回小工具,而是在受保护的应用程序中仍然存在的自然函数返回。虽然上述转换可以用于保护其他间接分支,但我们还必须确保返回不会导致推测执行。
例如,在x86架构中,RSB2或RAS3定义了固定的容量。当返回栈预测器耗尽时的行为没有明确定义,这意味着我们必须潜在地避免栈下溢。例如,在硬件选择转向另一个预测器的情况下。为了防止这种情况,有时可能需要“重新填充”返回栈,以确保不会发生栈下溢。(请参阅附录中的示例。)
适用于此情况的情况包括:
(1)当我们将控制转移到受保护执行中时(以便不影响其为保持硬件返回预测完整性所采取的步骤)。
从客户机转换到超级处理器、切换到受保护进程的上下文,中断传递(和返回)。
(2)从硬件睡眠状态恢复时,该状态可能未保留此缓存(例如,mwait)。
(3)当自然执行在受保护应用程序中潜在地耗尽返回栈时。(请注意,这是一个特定的边界情况,具有更有限的可利用性 - 我们预计大多数应用了retpoline保护的二进制文件不需要这种具体的缓解措施。)
6.2 Binaries with shared linkage
我们最初的重点是保护操作系统和虚拟化类型的目标,但也有一些用户应用程序类别可以从这种保护中受益。在这些情况下,需要特别指出共享链接和运行时环境会导致与间接分支的频繁交互。常见的例子包括程序链接表(PLT)和动态加载的标准库。针对这些情况,我们将发布额外的优化说明和技术。
七、Performance Details
7.1 Overhead
自然地,保护一个间接分支意味着不能进行预测。这是有意为之,因为我们正在"隔离"上述的预测,以防止其被滥用。在Intel x86架构上进行的微基准测试显示,我们转换后的指令序列与本机的间接分支(显式禁用分支预测硬件)的执行时间相差不多。
对于优化高性能二进制文件的性能,一种常见的现有技术是提供手动的直接分支提示。也就是说,将间接目标与已知的可能目标进行比较,并在找到匹配时使用直接分支。
Example of an indirect jump with manual prediction:
cmp %r11, known_indirect_target
jne retpoline_r11_trampoline
jmp known_indirect_target
一个现有的实现示例是基于配置文件的优化(Profile Guided Optimization,简称PGO),它使用运行时信息来生成等效的直接分支提示。
PGO是一种编译器优化技术,它通过收集程序在实际运行中的执行数据来指导优化过程。在PGO的流程中,首先通过一次或多次的训练运行来收集执行数据,然后将这些数据用于指导编译器的优化决策。
在执行数据收集阶段,程序在运行时会记录分支和函数调用的信息,包括目标地址和频率等。这些信息被用于生成一个配置文件,其中包含了在不同执行路径上的分支和函数调用的频率信息。
在优化阶段,编译器使用配置文件中的运行时信息来指导优化决策。对于频繁执行的间接分支,编译器可以将其转换为等效的直接分支,并根据配置文件中的频率信息来决定最有可能的目标。
通过使用PGO,编译器可以根据真实的运行时行为做出更准确的优化决策,从而提高程序的性能。将间接分支转换为直接分支提示是PGO中的一项常见优化技术,它可以减少分支预测错误,并提高程序的执行效率。
需要注意的是,PGO的效果取决于收集的运行时数据的准确性和代表性。因此,在使用PGO进行优化时,需要进行充分的训练运行,并保证收集到的数据能够充分覆盖程序的各种执行路径和情况。
总结而言,基于配置文件的优化(PGO)是一种利用运行时信息生成等效直接分支提示的编译器优化技术。通过使用PGO,编译器可以根据真实的运行时行为进行优化,包括将间接分支转换为直接分支提示。
7.2 Pause usage in support loop
在我们上面的推测循环中,暂停指令并不是必需的以确保正确性。但这意味着非生产性的推测执行占用了处理器上较少的功能单元。
暂停指令的包含在推测循环中,并非出于确保正确性的需要,而是为了优化处理器的利用率。通过包含暂停指令,非生产性的推测执行占用了处理器上较少的功能单元。
推测执行是处理器使用的一种技术,通过对程序控制流的假设,提前预测和执行指令,以提高性能。然而,在推测错误的情况下,处理器需要丢弃推测结果并回归到正确的执行路径。
在某些情况下,推测循环可能遇到阻止立即进展的指令或条件。在这种情况下,包含暂停指令允许处理器“暂停”或延迟执行非生产性的推测指令。这有助于释放处理器上的功能单元,使其可以用于其他生产性的工作或任务。
暂停指令的具体行为和影响可能因处理器架构和实现而异。它们通常被用作给处理器的提示,以优化资源分配和执行效率,特别是在推测执行普遍存在的情况下。
7.3 Alignment
上述所有序列受益于将其内部目标对齐到处理器架构的首选对齐方式(在x86架构上为16字节)。请参考附录中的示例序列,其中标注了对齐改进的部分。
八、Available Implementations
An implementation for LLVM is is under review for official merge here.
An implementation for GCC is available here.
Appendix
Return stack refill (x86)
在重新填充返回栈(return stack)时,我们必须遵守两个核心要求。
(1)为了确保返回栈(return stack)中有一个有效的入口,我们使用的函数调用应具有非零的位移(displacement)。这是因为存在类似于"call &next_instruction"的结构,常用于通过可重定位代码确定当前指令指针。这些结构通常会被优化掉,并被返回栈预测机制所忽略。
(2)我们必须确保如果我们的入口被使用(由于栈下溢),它本身也能够安全地避免推测执行。为了确保安全性,这些入口使用与上述构造相当的陷阱(trap)。
我们的重新填充构造是发出生成返回栈(return stack)的调用指令,然后重置栈,而不实际展开我们的填充调用。这确保了存在新的返回栈条目,同时不干扰程序的控制流程。
Example x86 refill sequence:
mov $8, %rax;
.align 16;
3: call 4f;
3p: pause; call 3p;
.align 16;
4: call 5f;
4p: pause; call 4p;
.align 16;
5: dec %rax;
jnz 3b;
add $(16*8), %rsp;
该实现使用了8个循环,每次迭代有2个调用。相较于每次迭代只有一个调用,这略微更快一些。我们没有观察到进一步展开循环对性能有明显的好处(尤其是相对于代码大小而言)。这个实现可能还可以分成更小的段(例如4个或8个调用),在这些段中我们可以与其他操作有用地进行流水线处理。
Example construction with alignment prefixes
call *%r11:
jmp set_up_return;
.align 16;
inner_indirect_branch:
call set_up_target;
capture_spec:
pause;
jmp capture_spec;
.align 16;
set_up_target:
mov %r11, (%rsp);
Ret
.align 16;
set_up_return:
call inner_indirect_branch;
Shared Trampoline:
.align 16;
retpoline_r11_trampoline:
call set_up_target;
capture_spec:
pause;
jmp capture_spec;
.align 16;
set_up_target:
mov %r11, (%rsp);
ret;
(在这些示例中,我们不会从对齐capture_spec分支目标中获益,因为它只是潜在的推测性执行。)
参考资料
https://zhuanlan.zhihu.com/p/82302233
https://zhuanlan.zhihu.com/p/438616789
https://zhuanlan.zhihu.com/p/393449780
https://zhuanlan.zhihu.com/p/394841431
https://bbs.kanxue.com/thread-254288.htm
https://blog.csdn.net/diamond_biu/article/details/123478139
https://cloud.tencent.com/developer/article/1087370
https://support.google.com/faqs/answer/7625886
https://spectreattack.com/spectre.pdf
https://www.usenix.org/sites/default/files/conference/protected-files/lisa18_slides_masters.pdf
https://www.intel.com/content/dam/develop/external/us/en/documents/retpoline-a-branch-target-injection-mitigation.pdf