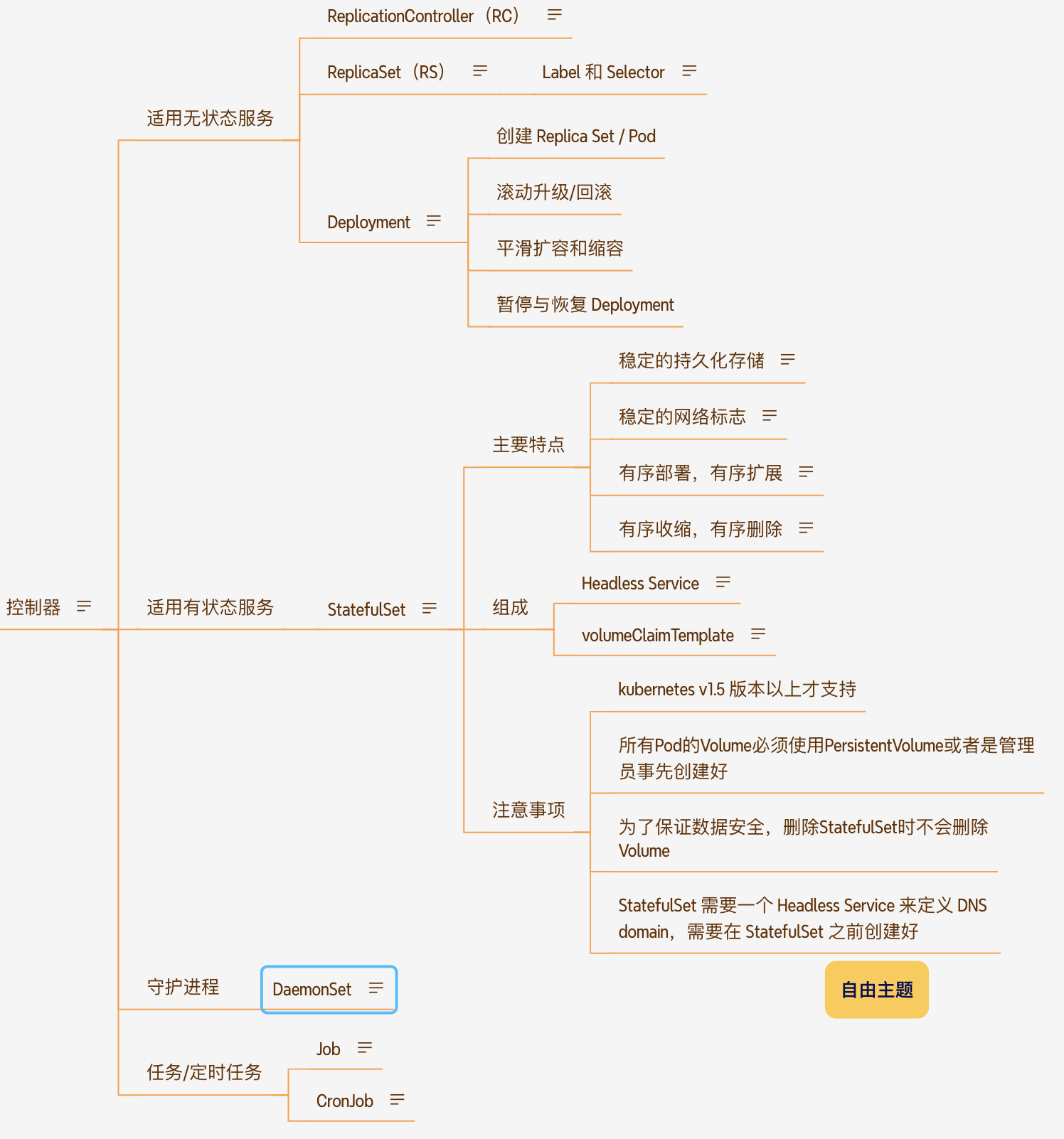
文章目录
- k8s-pod 控制器
- 无状态服务与有状态服务
- 无状态服务pod 控制器
- ReplicationController(RC)
- ReplicaSet(RS)
- Label 和 Selector
- Deployment
- 创建
- 滚动更新
- 回滚版本
- 扩容/缩容
- 暂停和恢复
- StatefulSet
- 创建
- 扩容/缩容
- 更新
- RollingUpdate->金丝雀发布
- OnDelete
- 删除
- DaemonSet
- 节点选择器
- 滚动更新
- HAP
- 开启指标服务
- 测试方案
k8s-pod 控制器
当 Pod 被创建出来,Pod 会被调度到集群中的节点上运行,Pod 会在该节点上一直保持运行状态,直到进程终止、Pod 对象被删除、Pod 因节点资源不足而被驱逐或者节点失效为止。Pod 并不会自愈,当节点失效,或者调度 Pod 的这一操作失败了,Pod 就该被删除。如此,单单用 Pod 来部署应用,是不稳定不安全的。
Kubernetes 使用更高级的资源对象 *“控制器”* 来实现对Pod的管理。控制器可以为您创建和管理多个 Pod,管理副本和上线,并在集群范围内提供自修复能力。 例如,如果一个节点失败,控制器可以在不同的节点上调度一样的替身来自动替换 Pod。
无状态服务与有状态服务
pod 控制器针对不同类型服务,有着更细致的划分。在k8s 中,会根据容器是需要在运行过程中存储数据到宿主机上将服务分为 无状态 和有状态两种
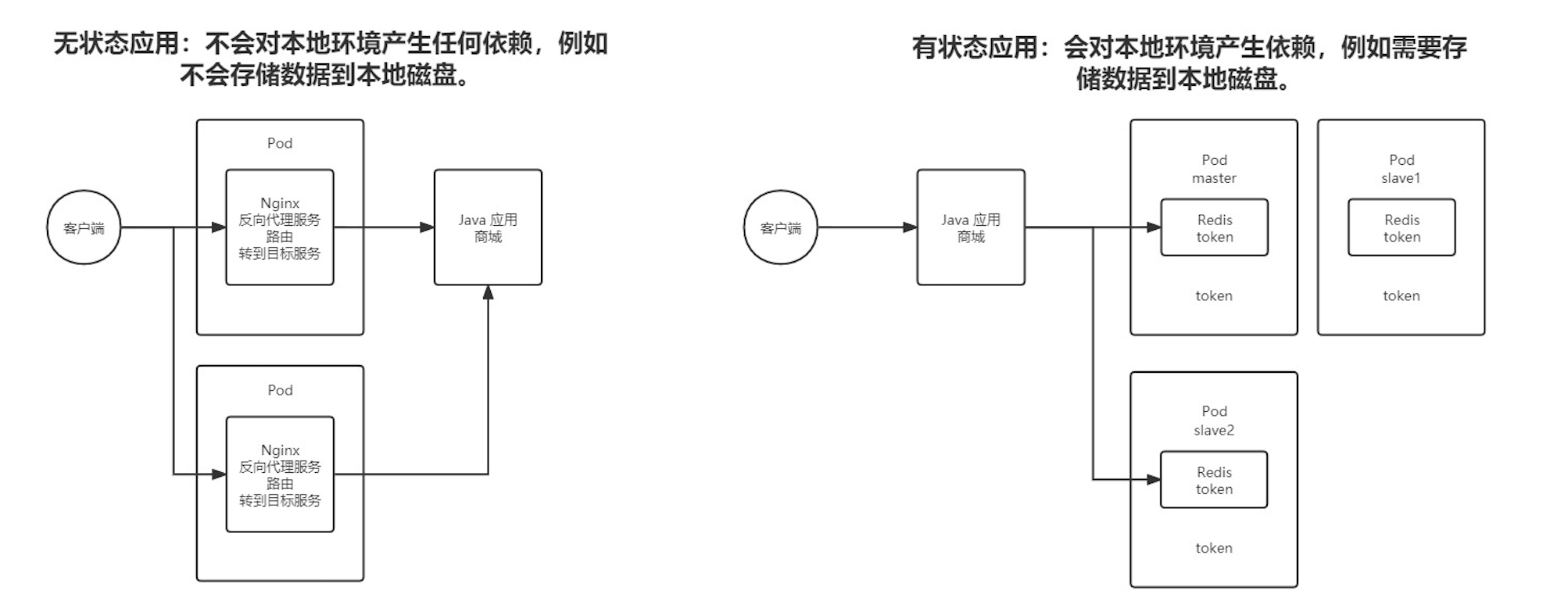
针对于这两种状态服务以及监控服务,k8s分别推出了不同的控制器来实现管理
无状态服务pod 控制器
ReplicationController(RC)
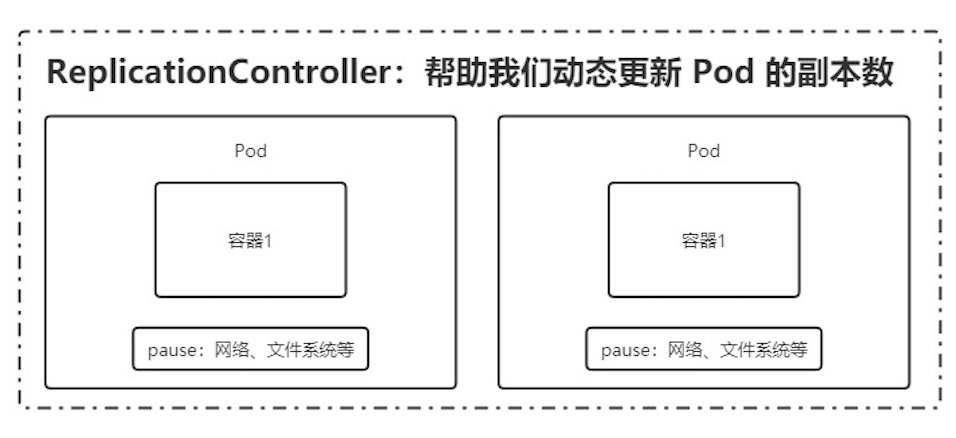
Replication Controller 简称 RC,RC 是 Kubernetes 系统中的核心概念之一,简单来说,RC 可以保证在任意时间运行 Pod 的副本数量,能够保证 Pod 总是可用的。如果实际 Pod 数量比指定的多那就结束掉多余的,如果实际数量比指定的少就新启动一些Pod,当 Pod 失败、被删除或者挂掉后,RC 都会去自动创建新的 Pod 来保证副本数量,所以即使只有一个 Pod,我们也应该使用 RC 来管理我们的 Pod。可以说,通过 ReplicationController,Kubernetes 实现了 Pod 的高可用性。
v1.11+ 已经弃用,了解即可
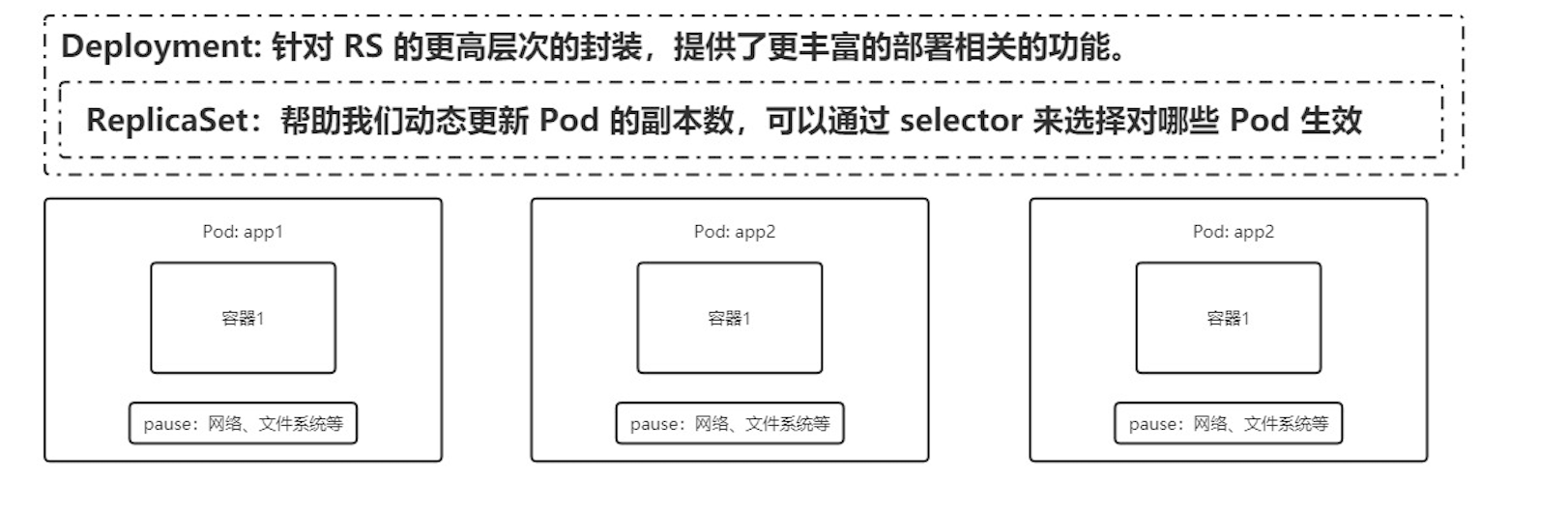
ReplicaSet(RS)
Kubernetes 官方建议使用 RS(ReplicaSet ) 替代 RC (ReplicationController ) 进行部署,RS 跟 RC 没有本质的不同,只是名字不一样,并且 RS 支持集合式的 selector, 对pod。功能强大了点
Label 和 Selector
label (标签)是附加到 Kubernetes 对象(比如 Pods)上的键值对,用于区分对象(比如Pod、Service)。 label 旨在用于指定对用户有意义且相关的对象的标识属性,但不直接对核心系统有语义含义。 label 可以用于组织和选择对象的子集。label 可以在创建时附加到对象,随后可以随时添加和修改。可以像 namespace 一样,使用 label 来获取某类对象,但 label 可以与 selector 一起配合使用,用表达式对条件加以限制,实现更精确、更灵活的资源查找。
label 与 selector 配合,可以实现对象的“关联”,“Pod 控制器” 与 Pod 是相关联的 —— “Pod 控制器”依赖于 Pod,可以给 Pod 设置 label,然后给“控制器”设置对应的 selector,这就实现了对象的关联。
- label 使用
1. 配置文件中
在各类资源的 metadata.labels 或者 sepc.metadata.labels中进行配置
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
labels: # 设置标签
type: app # 标签 k,v
test: 1.0.0 # label 的值需要使用字符串,如果是数字,需要加 '' 框起来
2. 通过临时创建修改
kubectl label po <资源名称> app=hello
3. 修改label
kubectl label po <资源名称> app=hello2 --overwrite
4. 查看label 信息
kubectl get po --show-labels
5. 根具label 值查找pod
kubectl get po -A -l app=hello
kubectl get po -A -l 'kind=nginx-demo, test=1.0.0' # 可以多条件查询 in 查询 !=
# 匹配单个值,查找 app=hello 的 pod
kubectl get po -A -l app=hello
# 匹配多个值
kubectl get po -A -l 'k8s-app in (metrics-server, kubernetes-dashboard)'
或
# 查找 version!=1 and app=nginx 的 pod 信息
kubectl get po -l version!=1,app=nginx
# 不等值 + 语句
kubectl get po -A -l version!=1,'app in (busybox, nginx)'
-
selector 使用
在各对象的配置 spec.selector 或其他可以写 selector 的属性中编写
selector 在 deployment 和 service 中配置有点去呗
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-app-deployment
spec:
replicas: 3
selector:
matchLabels:
app: web-app
template:
metadata:
labels:
app: web-app
env: production
spec:
containers:
- name: web-app
image: my-web-app-image
ports:
- containerPort: 8080
apiVersion: v1
kind: Service
metadata:
name: web-app-service
spec:
selector:
app: web-app # service 中配置 selector 不需要使用matchLabels
ports:
- protocol: TCP
port: 80
targetPort: 8080
至于 为啥 deployment 中的 selector 比 service 中多了一层的原因如下
Deployment中的
selector字段是用来指定如何识别Pod的,以确保Deployment控制器能够正确地管理这些Pod。selector字段内通常包含matchLabels或matchExpressions,它们定义了用来选择Pod的标签条件。当使用
matchLabels时,你需要提供一个或多个键值对,这些键值对必须与Pod模板中的标签完全匹配,这样Deployment才能正确地识别和管理这些Pod。通过定义这些匹配条件,Deployment控制器能够确保它所管理的Pod集合始终符合期望的状态。为什么
selector的使用需要加上matchLabels(或matchExpressions)呢?这主要有以下几个原因:
- 精确识别:通过
matchLabels,你可以精确地指定要由Deployment管理的Pod的标签。这有助于避免管理错误的Pod或遗漏应该管理的Pod。- 标签选择器灵活性:除了简单的键值对匹配外,你还可以使用
matchExpressions来执行更复杂的标签选择逻辑,如“存在某个标签”或“标签的值在某个集合中”等。- 状态一致性:当Deployment的期望状态与实际状态不一致时(例如,Pod数量不足或配置不匹配),控制器会使用
selector来识别需要创建、更新或删除的Pod,以确保集群中的Pod集合始终符合Deployment的期望状态。- 避免冲突:在Kubernetes集群中,可能同时存在多个Deployment和其他资源对象,它们可能都试图管理相同或不同的Pod。通过使用特定的
selector,每个Deployment都可以明确指定它应该管理哪些Pod,从而避免潜在的冲突。综上所述,
selector中的matchLabels(或matchExpressions)是确保Deployment能够正确、有效地识别和管理其目标Pod集合的关键组成部分。Service中不需要
matchLabels是因为它的职责是提供网络访问入口和流量路由,而不是直接管理Pod的生命周期。标签选择器用于在Service中识别需要暴露的Pod集合,而Pod的管理则由其他资源对象(如Deployment)通过matchLabels等方式来负责。
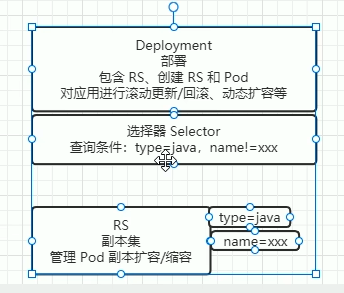
Deployment
Deployment 在 RS 的基础上,又包了一层,实现了更多的功能
创建
yaml文件
apiVersion: apps/v1 # deployment api 版本
kind: Deployment # 资源类型为 deployment
metadata: # 元信息
labels: # 标签
app: nginx-deploy # 具体的 key: value 配置形式
name: nginx-deploy # deployment 的名字
namespace: default # 所在的命名空间
spec:
replicas: 1 # 期望副本数
revisionHistoryLimit: 10 # 进行滚动更新后,保留的历史版本数
selector: # 选择器,用于找到匹配的 RS
matchLabels: # 按照标签匹配
app: nginx-deploy # 匹配的标签key/value
strategy: # 更新策略
rollingUpdate: # 滚动更新配置
maxSurge: 25% # 进行滚动更新时,更新的个数最多可以超过期望副本数的个数/比例
maxUnavailable: 25% # 进行滚动更新时,最大不可用比例更新比例,表示在所有副本数中,最多可以有多少个不更新成功
type: RollingUpdate # 更新类型,采用滚动更新
template: # pod 模板
metadata: # pod 的元信息
labels: # pod 的标签
app: nginx-deploy
spec: # pod 期望信息
containers: # pod 的容器
- image: nginx:1.7.9 # 镜像
imagePullPolicy: IfNotPresent # 拉取策略
name: nginx # 容器名称
restartPolicy: Always # 重启策略
terminationGracePeriodSeconds: 30 # 删除操作最多宽限多长时间
1. 通过命令创建一个 deployment
kubectl create deploy nginx-deploy --image=nginx:1.7.9
2. 通过 yaml 文件创建
kubectl create -f xxx.yaml --record
--record 会在 annotation 中记录当前命令创建或升级了资源,后续可以查看做过哪些变动操作。
#查看部署信息
kubectl get deployments
#查看 rs
kubectl get rs
#查看 pod 以及展示标签,可以看到是关联的那个 rs
kubectl get pods --show-labels
# 快速获取一个yaml 文件方案
1. 通过命令创建一个 deploy
2. kubectl get deploy <deploy_name> -o yaml # 去除不需要的,改一改就可以用了
滚动更新
只有修改了 deployment 配置文件中的 template 中的属性后,才会触发更新操作
#修改 nginx 版本号
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
#或者通过 kubectl edit deployment/nginx-deployment 进行修改
#查看滚动更新的过程
kubectl rollout status deploy <deployment_name>
#查看部署描述,最后展示发生的事件列表也可以看到滚动更新过程
kubectl describe deploy <deployment_name>
'''
通过 kubectl get deployments 获取部署信息,UP-TO-DATE 表示已经有多少副本达到了配置中要求的数目
通过 kubectl get rs 可以看到增加了一个新的 rs
通过 kubectl get pods 可以看到所有 pod 关联的 rs 变成了新的
'''
注:假设当前有 5 个 nginx:1.7.9 版本,你想将版本更新为 1.9.1,当更新成功第三个以后,你马上又将期望更新的版本改为 1.9.2,那么此时会立马删除之前的三个,并且立马开启更新 1.9.2 的任务
回滚版本
有时候你可能想回退一个Deployment,例如,当Deployment不稳定时,比如一直crash looping。
默认情况下,kubernetes会在系统中保存前两次的Deployment的rollout历史记录,以便你可以随时会退(你可以修改revision history limit来更改保存的revision数)。
#更新 deployment 时参数不小心写错,如 nginx:1.9.1 写成了 nginx:1.91
kubectl set image deployment/nginx-deploy nginx=nginx:1.91
#监控滚动升级状态,由于镜像名称错误,下载镜像失败,因此更新过程会卡住
kubectl rollout status deployments nginx-deploy
#结束监听后,获取 rs 信息,我们可以看到新增的 rs 副本数是 2 个
kubectl get rs
#通过 kubectl get pods 获取 pods 信息,我们可以看到关联到新的 rs 的 pod,状态处于 ImagePullBackOff 状态
#为了修复这个问题,我们需要找到需要回退的 revision 进行回退
#通过命令可以获取 revison 的列表
kubectl rollout history deployment/nginx-deploy
#通过可以查看详细信息
kubectl rollout history deployment/nginx-deploy --revision=2
#确认要回退的版本后,可以回退到上一个版本
kubectl rollout undo deployment/nginx-deploy
#也可以回退到指定的 revision
kubectl rollout undo deployment/nginx-deploy --to-revision=2
再次通过 kubectl get deployment 和 kubectl describe deployment 可以看到,我们的版本已经回退到对应的 revison 上了
可以通过设置 .spec.revisonHistoryLimit 来指定 deployment 保留多少 revison,如果设置为 0,则不允许 deployment 回退了。
扩容/缩容
通过 kube scale 命令可以进行自动扩容/缩容,以及通过 kube edit 编辑 replcas 也可以实现扩容/缩容
扩容与缩容只是直接创建副本数,没有更新 pod template 因此不会创建新的 rs
kubectl scale --replicas=3 deploy nginx-deploy
暂停和恢复
由于每次对 pod template 中的信息发生修改后,都会触发更新 deployment 操作,那么此时如果频繁修改信息,就会产生多次更新,而实际上只需要执行最后一次更新即可,当出现此类情况时我们就可以暂停 deployment 的 rollout
# 实现暂停,直到你下次恢复后才会继续进行滚动更新
kubectl rollout pause deployment <name>
# 恢复更新
kubectl rollout deploy <name>
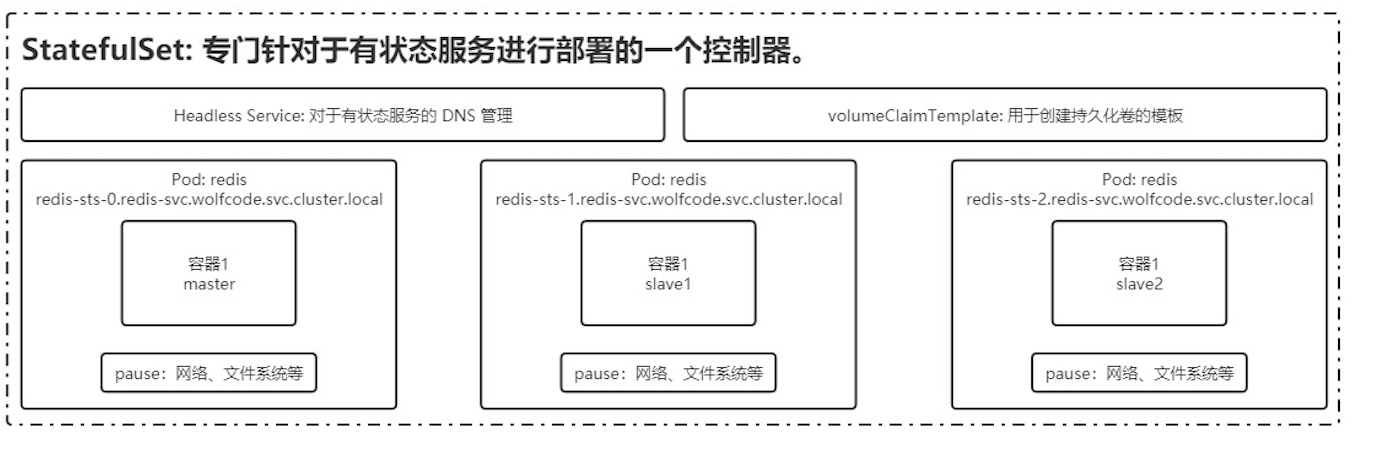
StatefulSet
用于有状态服务
StatefulSet 中每个 Pod 的 DNS 格式为 statefulSetName-{0…N-1}.serviceName.namespace.svc.cluster.local
- serviceName 为 Headless Service 的名字
- 0…N-1 为 Pod 所在的序号,从 0 开始到 N-1
- statefulSetName 为 StatefulSet 的名字
- namespace 为服务所在的 namespace,Headless Servic 和 StatefulSet 必须在相同的 namespace
- .cluster.local 为 Cluster Domain
特点:
- Pod 重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现
- 稳定的网络标志,即 Pod 重新调度后其 PodName 和 HostName 不变,基于 Headless Service(即没有 Cluster IP 的 Service)来实现
- 有序部署,有序扩展,即 Pod 是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从 0到 N-1,在下一个Pod 运行之前所有之前的 Pod 必须都是 Running 和 Ready 状态),基于 init containers 来实现
- 有序收缩,有序删除(即从 N-1 到 0)
注意事项:
kubernetes v1.5 版本以上才支持
所有pod 的vloume 必须使用PersistentVolume 或者是管理员提前建好
为了保证数据安全, 删除 StatefulSet时不会删除Volume
StatefulSet 需要一个 Headless Service 来定义DNS domain,需要在 StatefulSet之前创建好
创建
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
--- # 先创建上面的service
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web # statefulset 对象name
spec:
serviceName: "nginx" # 使用 name 为nginx 的service 来管理 dns
replicas: 2
selector:
matchLabels: # 匹配对应的标签
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports: # 对外暴露的端口
- containerPort: 80 # 具体端口号
name: web # 端口配置的name
volumeMounts: # 加载数据卷 使用pvc 需要提取创建 pv
- name: www # 数据卷的name
mountPath: /usr/share/nginx/html # 挂载容器内的目录
volumeClaimTemplates: # 数据卷模板
- metadata: # 数据卷描述
name: www # 数据卷name
annotations: # 数据卷的注解
volume.alpha.kubernetes.io/storage-class: anything # s
spec: # 数据卷的规约
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi # 需要的存储资源
# 查看 service 和 statefulset => sts
kubectl get service nginx
kubectl get statefulset web
# 查看 PVC 信息
kubectl get pvc
# 查看创建的 pod,这些 pod 是有序的
kubectl get pods -l app=nginx
# 查看这些 pod 的 dns
# 运行一个 pod,基础镜像为 busybox 工具包,利用里面的 nslookup 可以看到 dns 信息
kubectl run -i --tty --image busybox:1.28.4 dns-test --restart=Never --rm /bin/sh
nslookup web-0.nginx
扩容/缩容
$ kubectl scale sts web --replicas=5
# 缩容
$ kubectl patch statefulset web -p '{"spec":{"replicas":3}}'
更新
statefulset 有两种更新方式 RollingUpdate 和 OnDelete,默认采用RollingUpdate 方式
# 镜像更新(1.23版本还不支持直接更新 image,需要 patch 来间接实现) 也就是直接改sts yaml文件
kubectl patch sts web --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"nginx:1.9.1"}]'
RollingUpdate->金丝雀发布
statefulset 管理的pod 命令和deployment 不同, deploy 后缀是uuid,statefulset 管理的pod 后缀从0 开始递增,也是基于这个特性,可以通过设置 partition 的值来实现灰度发布
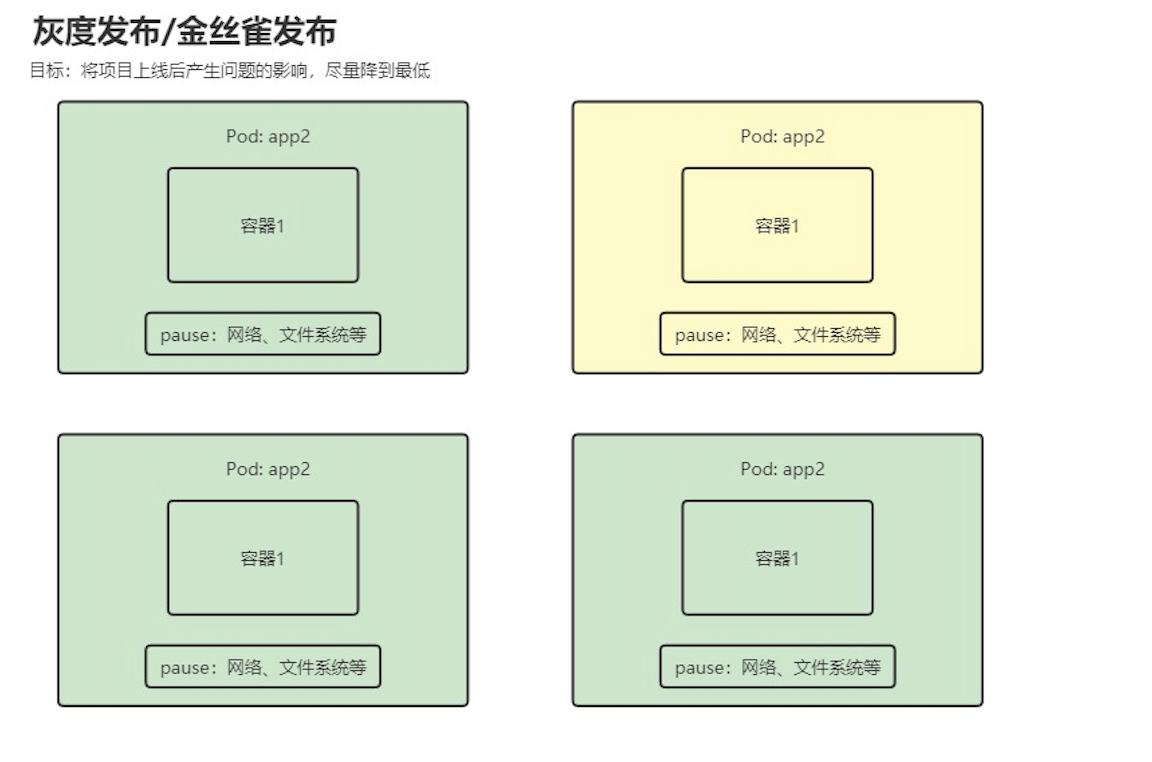
updateStrategy:
rollingUpdate:
partition: 0 # 这里设置值越高, 自动更新的容器越少,设置为0,有修改就全部更新
type: RollingUpdate
OnDelete
updateStrategy:
type: OnDelete # 设置为OnDelete后,有更新后,先删除原有容器,才会更新新的容器
删除
# 删除 StatefulSet 和 Headless Service
# 级联删除:删除 statefulset 时会同时删除 pods
kubectl delete statefulset web
# 非级联删除:删除 statefulset 时不会删除 pods,删除 sts 后,pods 就没人管了,此时再删除 pod 不会重建的
kubectl deelte sts web --cascade=false
# 删除 service
kubectl delete service nginx
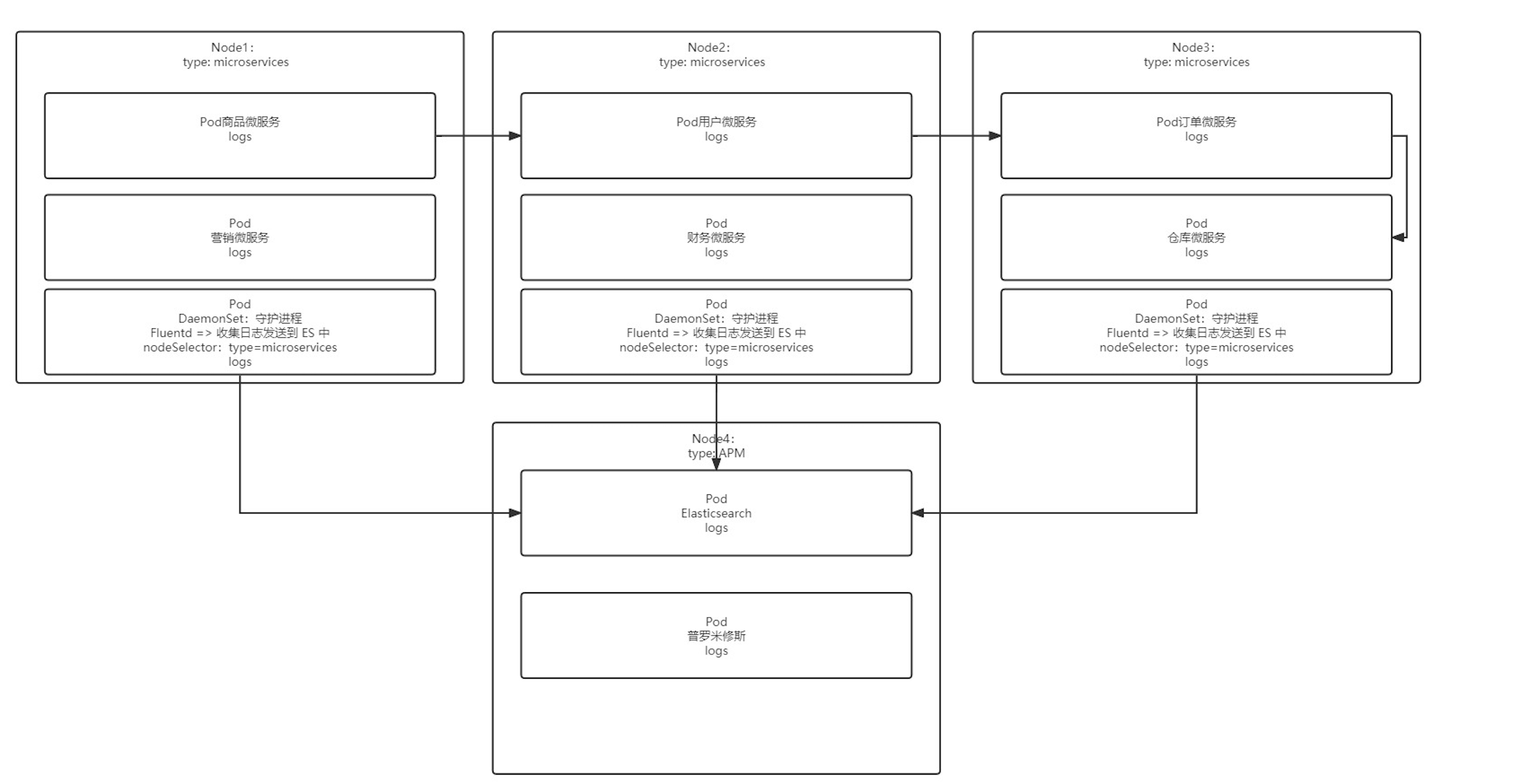
DaemonSet
DaemonSet 保证在每个 Node 上都运行一个容器副本,常用来部署一些集群的日志、监控或者其他系统管理应用。典型的应用包括:
- 日志收集,比如 fluentd,logstash 等
- 系统监控,比如 Prometheus Node Exporter,collectd,New Relic agent,Ganglia gmond 等
- 系统程序,比如 kube-proxy, kube-dns, glusterd, ceph 等
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
spec:
template:
metadata:
labels:
app: logging
id: fluentd
name: fluentd
spec:
containers:
- name: fluentd-es
image: agilestacks/fluentd-elasticsearch:v1.3.0
env:
- name: FLUENTD_ARGS
value: -qq
volumeMounts:
- name: containers
mountPath: /var/lib/docker/containers
- name: varlog
mountPath: /varlog
volumes:
- hostPath:
path: /var/lib/docker/containers
name: containers
- hostPath:
path: /var/log
name: varlog
其他命令和上面sts deploy 差不多
节点选择器
DaemonSet 会忽略 Node 的 unschedulable 状态,有两种方式来指定 Pod 只运行在指定的 Node 节点上:
- nodeSelector:只调度到匹配指定 label 的 Node 上
- nodeAffinity:功能更丰富的 Node 选择器,比如支持集合操作
- podAffinity:调度到满足条件的 Pod 所在的 Node 上
nodeSelector
#先为 Node 打上标签
# kubectl label nodes k8s-node1 svc_type=microsvc
# 配置后,可以通过给node 添加标签来自动添加删除 daemonset 服务
#然后再 daemonset 配置中设置 nodeSelector
spec:
template:
spec:
nodeSelector:
svc_type: microsvc
nodeAffinity
nodeAffinity 目前支持两种:requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution,分别代表必须满足条件和优选条件。
比如下面的例子代表调度到包含标签 wolfcode.cn/framework-name 并且值为 spring 或 springboot 的 Node 上,并且优选还带有标签 another-node-label-key=another-node-label-value 的Node。
podAffinity
podAffinity 基于 Pod 的标签来选择 Node,仅调度到满足条件Pod 所在的 Node 上,支持 podAffinity 和 podAntiAffinity。这个功能比较绕,以下面的例子为例:
如果一个 “Node 所在空间中包含至少一个带有 auth=oauth2 标签且运行中的 Pod”,那么可以调度到该 Node
不调度到 “包含至少一个带有 auth=jwt 标签且运行中 Pod”的 Node 上
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity: # 将相关pod放在一起
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制条件,必须满足才能调度到对应pod
- labelSelector:
matchExpressions:
- key: auth
operator: In
values:
- oauth2
topologyKey: failure-domain.beta.kubernetes.io/zone
podAntiAffinity: # 将相关标签的pod 分散开
preferredDuringSchedulingIgnoredDuringExecution: # 软限制权限, 没有满足的条件,就当这个配置不存在
- weight: 100
podAffinityTerm: # 定义具体反亲和性条件
labelSelector:
matchExpressions:
- key: auth
operator: In
values:
- jwt
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: pauseyyf/pause
滚动更新
ds 的默认滚动更新策略时RollingUpdate ,但是生产环境中不建议使用 RollingUpdate,建议使用 OnDelete 模式,这样避免频繁更新 ds
# 默认配置
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdate
# 建议配置
updateStrategy:
type: OnDelete
HAP
Pod 自动扩容:可以根据 CPU 使用率或自定义指标(metrics)自动对 Pod 进行扩/缩容。
- 控制管理器每隔30s(可以通过–horizontal-pod-autoscaler-sync-period修改)查询metrics的资源使用情况
- 支持三种metrics类型
- 预定义metrics(比如Pod的CPU)以利用率的方式计算
- 自定义的Pod metrics,以原始值(raw value)的方式计算
- 自定义的object metrics
- 支持两种metrics查询方式:Heapster和自定义的REST API
- 支持多metrics
通常用于 Deployment/StatefulSet,不适用于无法扩/缩容的对象,如 DaemonSet
开启指标服务
kubectl top pod 相关命令需要metrics-server 服务来支撑
# 下载 metrics-server 组件配置文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml -O metrics-server-components.yaml
# 修改镜像地址为国内的地址
sed -i 's/egistry.k8s.io\/metrics-server/registry.cn-hangzhou.aliyuncs.com\/google_containers/g' metrics-server-components.yaml
# 修改容器的 tls 配置,不验证 tls,在 containers 的 args 参数中增加 --kubelet-insecure-tls 参数
# 安装组件
kubectl apply -f metrics-server-components.yaml
# 查看 pod 状态
kubectl get pods --all-namespaces | grep metrics
测试方案
实现 cpu 或内存的监控,首先有个前提条件是该对象必须配置了 resources.requests.cpu 或 resources.requests.memory 才可以,可以配置当 cpu/memory 达到上述配置的百分比后进行扩容或缩容
创建一个 HPA:
1. 先准备一个好一个有做资源限制的 deployment
2. 执行命令 kubectl autoscale deploy nginx-deploy --cpu-percent=20 --min=2 --max=5
3. 通过 kubectl get hpa 可以ku获取 HPA 信息
测试:找到对应服务的 service,编写循环测试脚本提升内存与 cpu 负载
while true; do wget -q -O- http://<ip:port> > /dev/null ; done
可以通过多台机器执行上述命令,增加负载,当超过负载后可以查看 pods 的扩容情况 kubectl get pods
查看 pods 资源使用情况
kubectl top pods
扩容测试完成后,再关闭循环执行的指令,让 cpu 占用率降下来,然后过 5 分钟后查看自动缩容情况